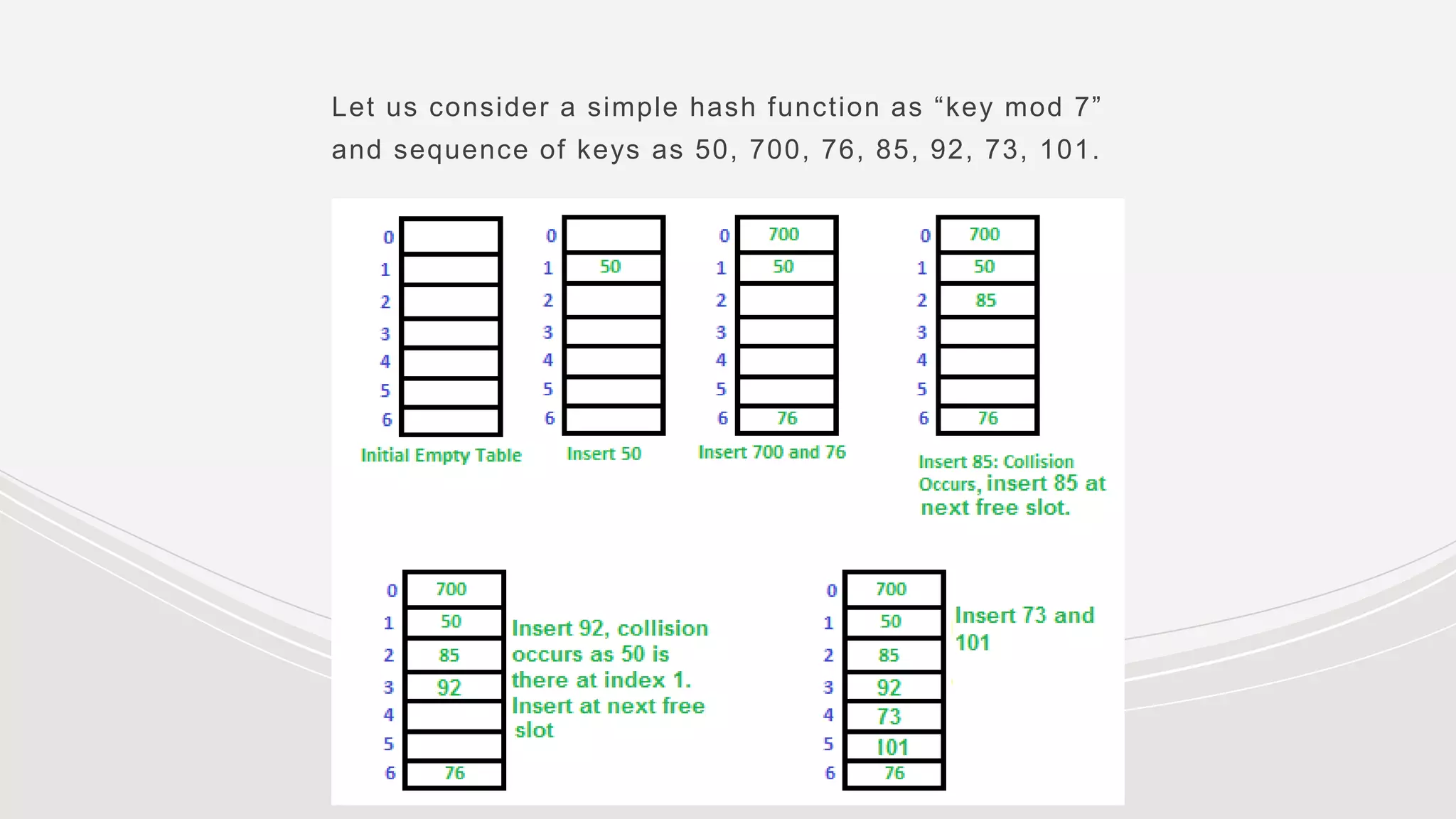
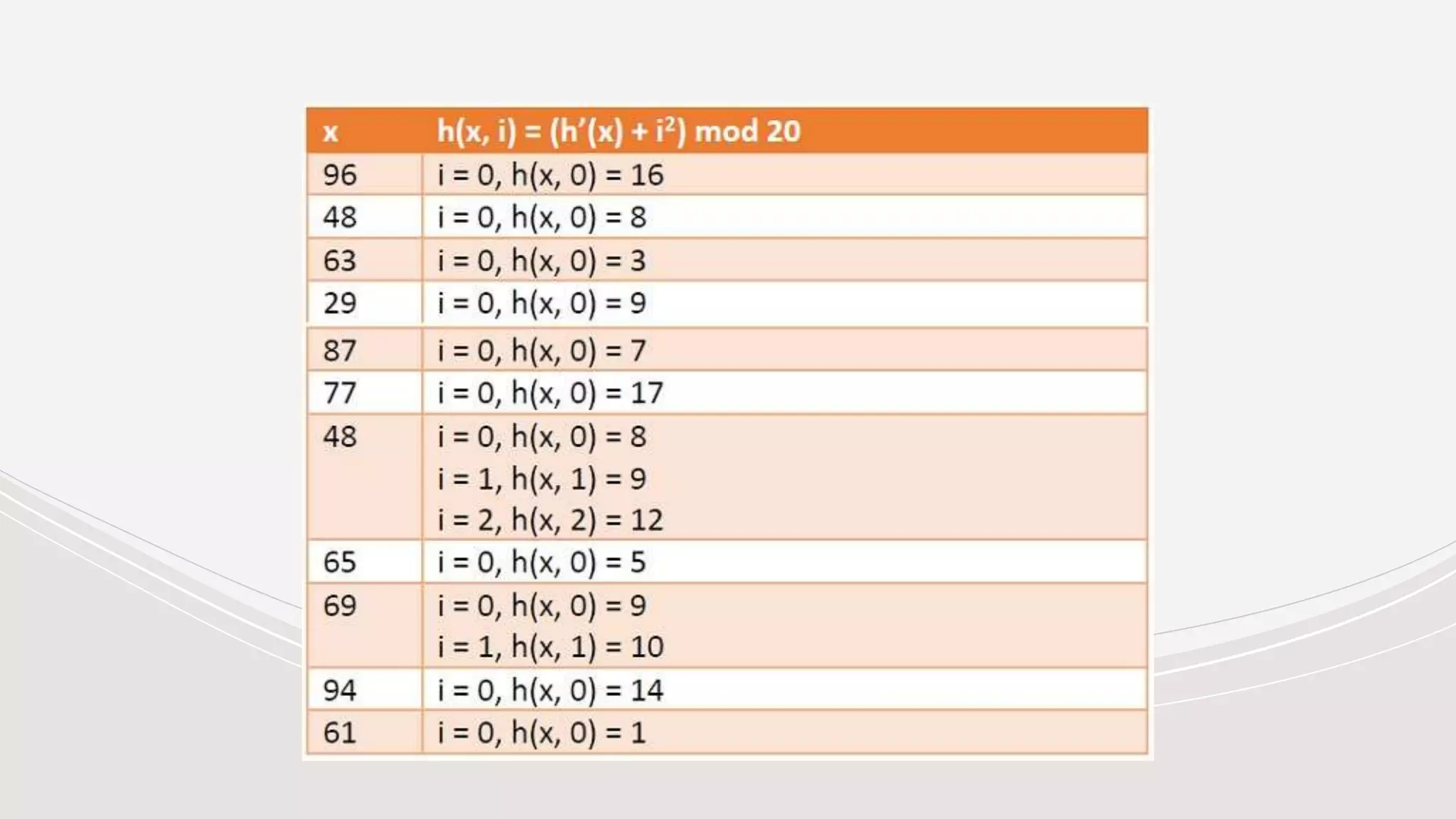
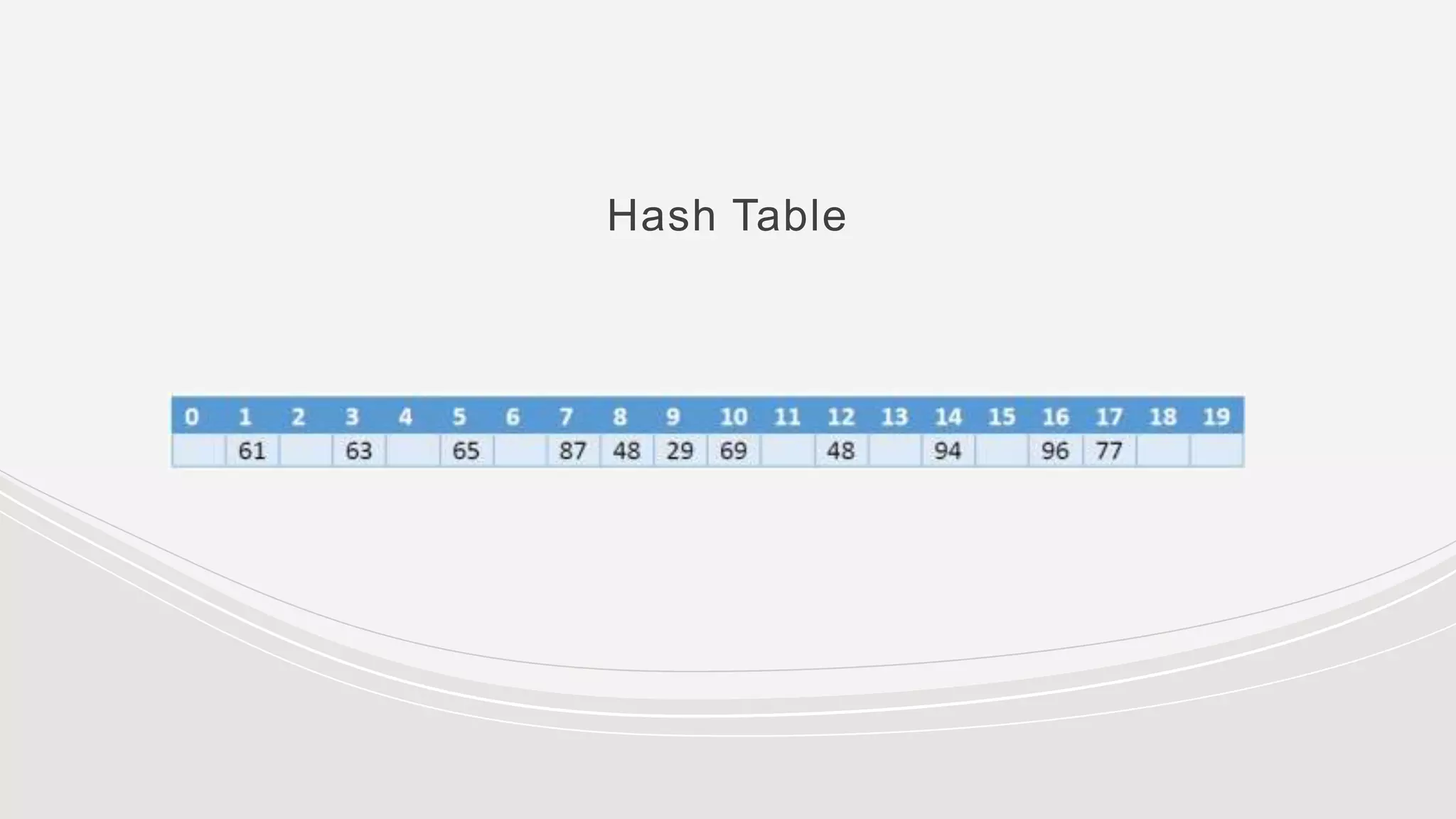
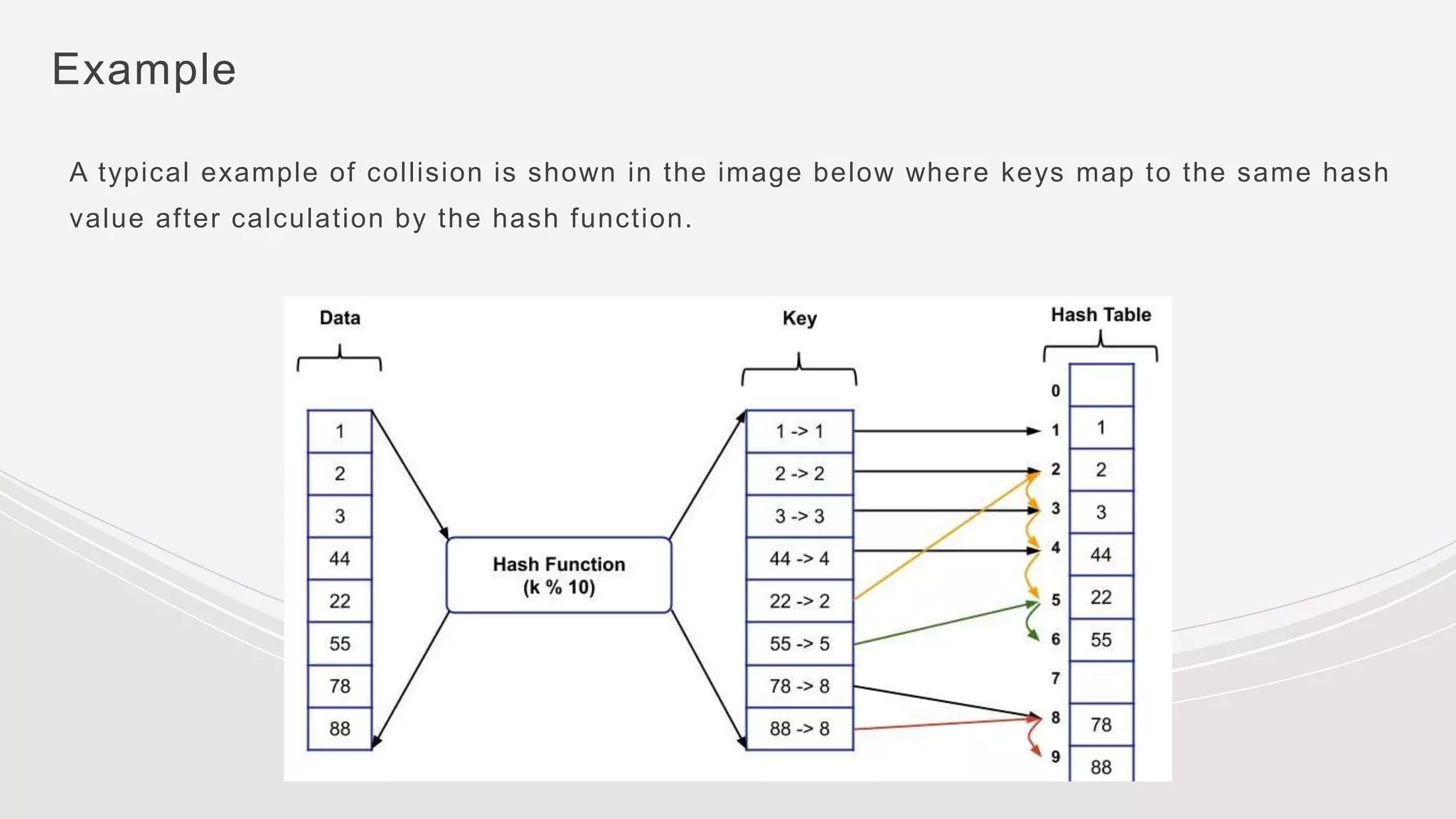
The document discusses hashing techniques and collision resolution methods for hash tables. It covers:
- Hashing maps keys of variable length to smaller fixed-length values using a hash function. Hash tables use hashing to efficiently store and retrieve key-value pairs.
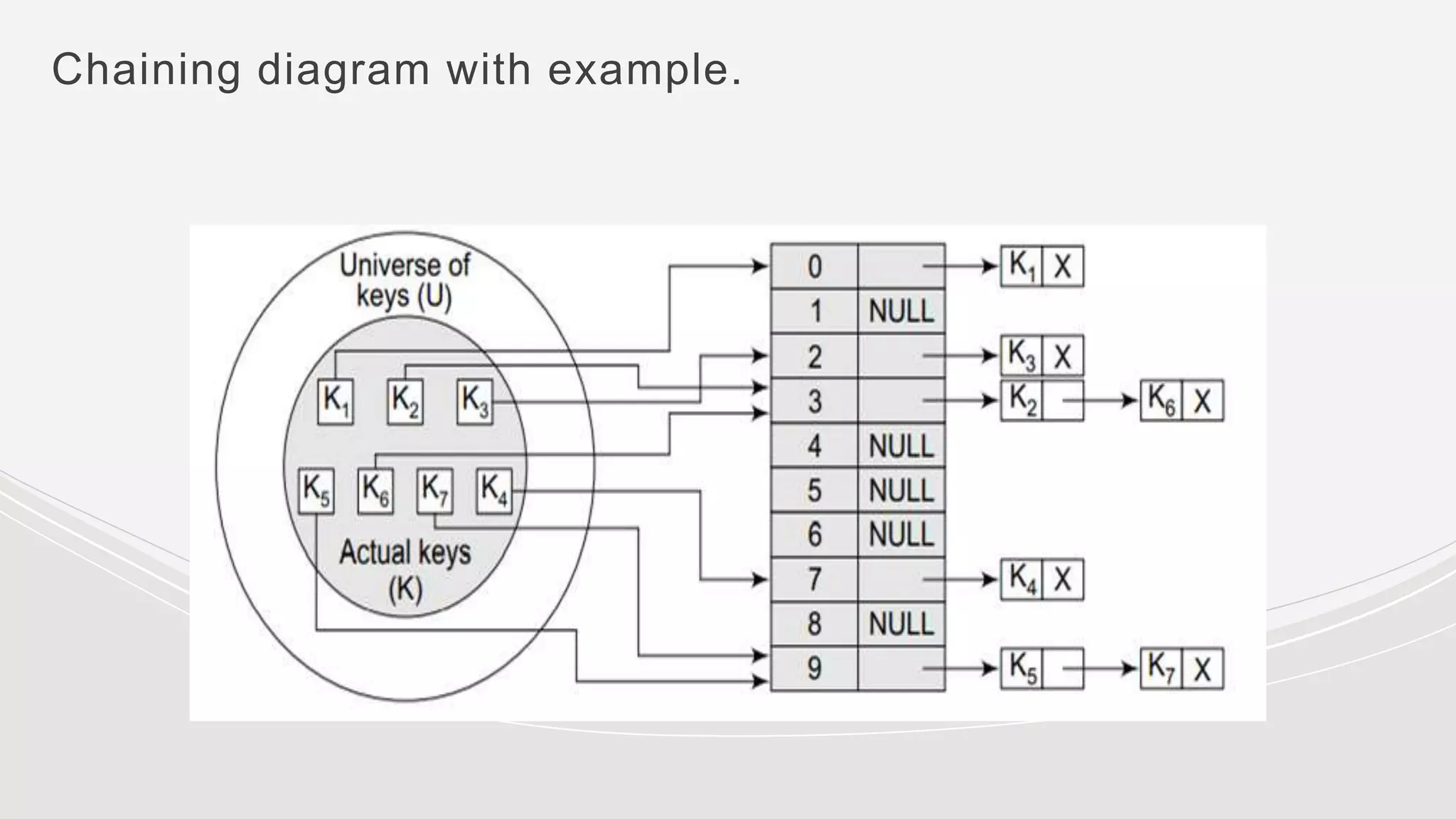
- Collisions occur when two keys hash to the same value. Common collision resolution methods are separate chaining, where each slot points to a linked list, and open addressing techniques like linear probing and double hashing.
- Bucket hashing groups hash table slots into buckets to improve performance. Records are hashed to buckets and stored sequentially within buckets or in an overflow bucket if a bucket is full. This reduces disk accesses when the hash table is stored























![Code to initialise chained hash table:
typedef struct node_HashTable {
int value;
struct node *next;
}node;
void initialiseHashTable (node *hash_table[], int m)
{ int i;
for(i=0i<=m;i++)
hash_table[i]=NULL;
}
Time complexity: O(m)](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-29-2048.jpg)
![Code to insert a value
/* The element is inserted at the beginning of the linked list whose pointer to its head is
stored in the location given by h(k). The running time of the insert operation is O(1), as the
new key value is always added as the first element of the list .*/
node *insert_value( node *hash_table[], int val)
{ node *new_node;
new_node = (node *)malloc(sizeof(node));
new_node value = val;
new_node next = hash_ table[h(x)];
hash_table[h(x)] = new_node;
}](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-30-2048.jpg)

![Code to search a value
node *search_value(node *hash_table[], int val)
{
node *ptr; ptr = hash_table[h(x)];
while ( (ptr!=NULL) && (ptr –> value != val)){
ptr = ptr –> next;
}
if (ptr–>value == val) return ptr;
else return NULL;
}](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-32-2048.jpg)

![Code to delete a value
void delete_value (node *hash_table[], int val)
{
node *save, *ptr;
save = NULL;
ptr = hash_table[h(x)];
while ((ptr != NULL) && (ptr value != val))
{
save = ptr; ptr = ptr next;
}
if (ptr != NULL)
{ save next = ptr next;
free (ptr);
} else
printf("n VALUE NOT FOUND"); }](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-34-2048.jpg)



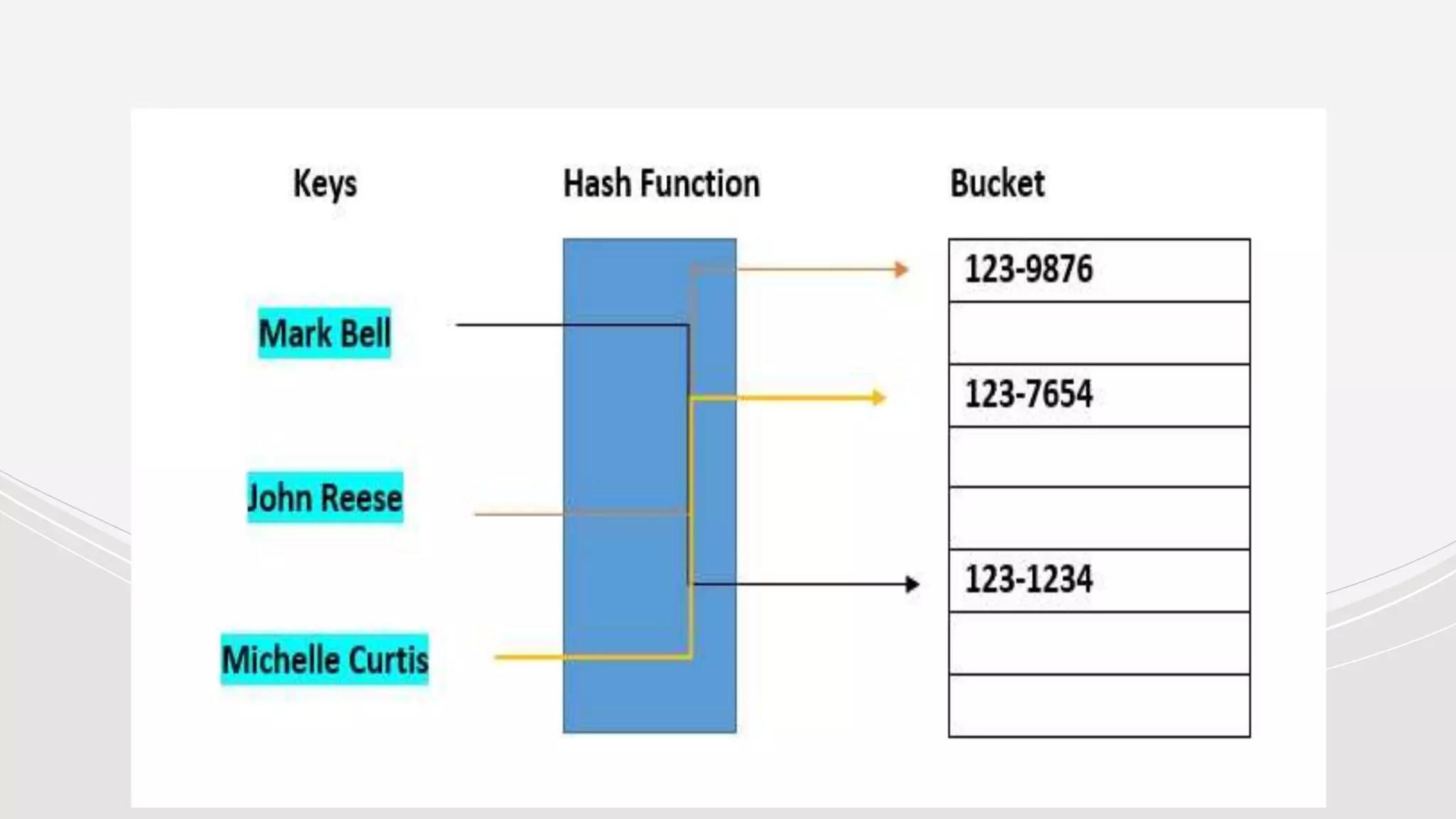
![Hash Buckets:
In computing, a hash table [hash map] is a data structure that provides virtually direct
access to objects based on a key [a unique String or Integer]. A hash table uses a hash
function to compute an index into an array of buckets or slots, from which the desired
value can be found. Here are the main features of the key used:
● The key used can be your SSN, your telephone number, account number, etc
● Must have unique keys
● Each key is associated with–mapped to–a value
● Hash buckets are used to apportion data items for sorting or lookup purposes. The aim of this
work is to weaken the linked lists so that searching for a specific item can be accessed within a
shorter time frame](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-38-2048.jpg)







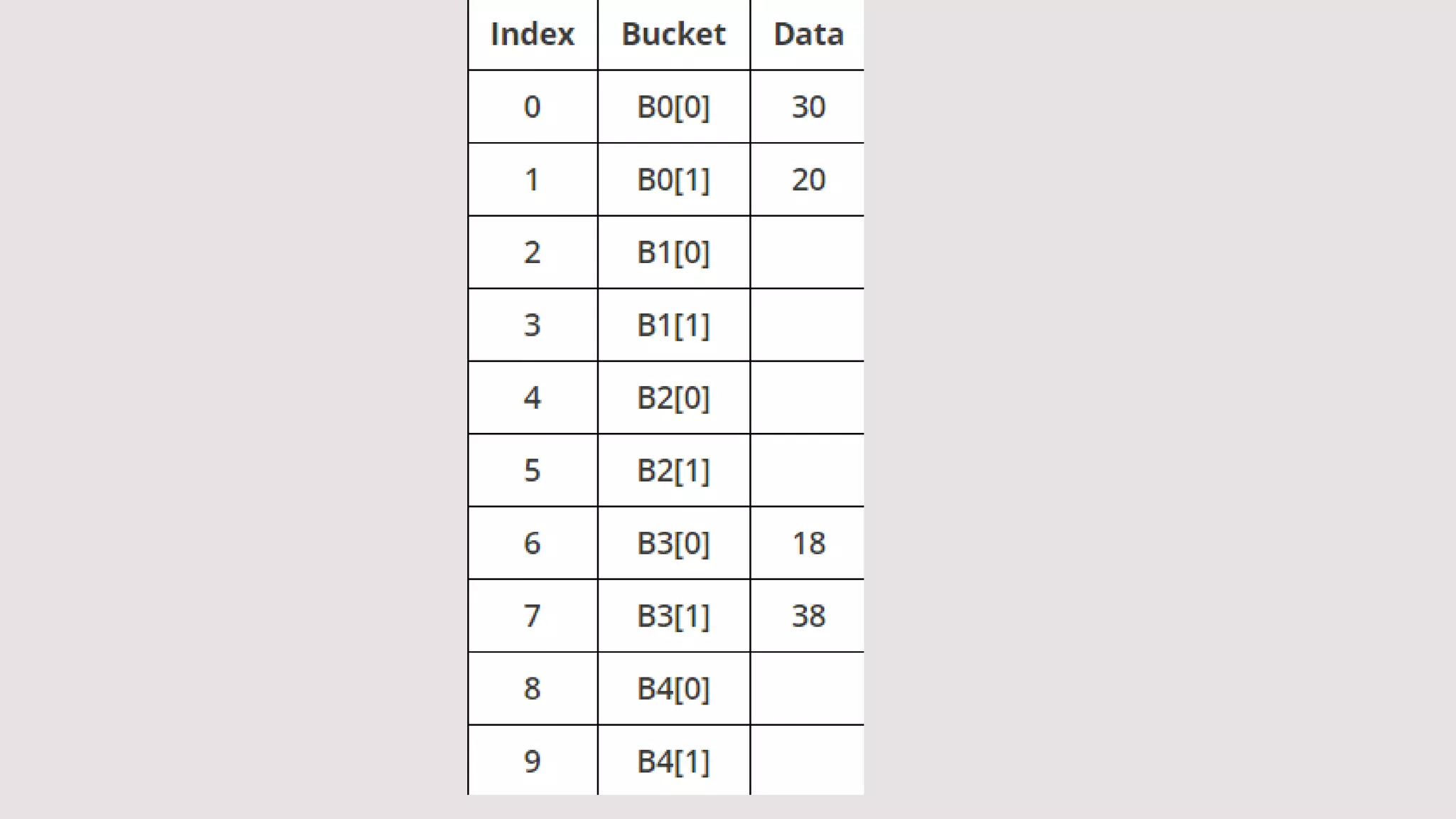
![Collision Resolution
. Let us start by inserting the number 18 as our first record. Since we
have 5 buckets, we take mod 5. 18 % 5 is 3. We put this into the top of
B3, which is slot 6 of the hash table.
Now inserting a record for 30. 30 % 5 is 0. 30 goes into B0[0].
Next we insert a record for 38; 38 % 5 is 3 so it will be placed in B3[1].
Next up we have 48. 48 % 5 is 3, but the B3 is already full, hence we
store 48 in the first available slot of our overflow bucket.
We can now try with 20. 20 % 5 is 0; B0[0] is occupied hence it will be
stored in B0[1].
Now if we insert 25, 25 % 5 is 0 and we know both slots of B0 are
occupied now, hence it will end up in our overflow bucket.
.](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-47-2048.jpg)
![When looking for a record, we first take its hash value and search the resulting bucket.
If we search for key value 20, we search in B0, first checking B0[0] which holds a
different value, so we check B0[1] and we find our key.
When searching for the key value 25, we look in B0 sequentially. We see it doesn't hold
our key value and it is full, hence we look through the overflow bucket. First checking
OB[0], then OB[1] and we have found it.
Note that if there are many records in the overflow bucket, this will be an expensive
process.](https://image.slidesharecdn.com/presentation-230109153902-e6a4ddf2/75/Presentation-pptx-49-2048.jpg)
















































