More Related Content

PPTX

PPTX

PPTX

PDF
FluentdやNorikraを使った データ集約基盤への取り組み紹介 
PPTX

PPTX
Hadoop / Elastic MapReduceつまみ食い 
PPTX

PDF
What's hot

PPTX
Hadoopソースコードリーディング8/MapRを使ってみた 
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~ 
PDF
ちょっと理解に自信がないな�という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料) 
PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119) 
PDF

PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント 
PDF
Hadoop ecosystem NTTDATA osc15tk 
PDF

ODP

PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall 
PDF

PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014) 
PDF

PPTX
大規模分散システムの現在 -- GFS, MapReduce, BigTableはどう変化したか? 
PPTX
ビッグデータ処理データベースの全体像と使い分け
2018年version 
PPTX
Hadoop -ResourceManager HAの仕組み- 
PDF
Cloudera World Tokyo 2015 Oracleセッション資料 「ビッグデータ/IoTの最新事例とHadoop活用の勘所」 
PPTX

PDF
並列分散処理基盤Hadoopの紹介と、開発者が語るHadoopの使いどころ (Silicon Valley x 日本 / Tech x Business ... 
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~ Similar to Hadoopカンファレンス2013

PDF
Hadoop Conference Japan 2011 Fall: マーケティング向け大規模ログ解析事例紹介 
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築 
PPT
Hadoop ~Yahoo! JAPANの活用について~ 
PDF

PPTX
Jenkinsとhadoopを利用した継続的データ解析環境の構築 
PDF
Hadoopによるリクルートでの技術調査とその活用 
PDF

PPTX

PPT
Hadoop~Yahoo! JAPANの活用について~ 
PPT

PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み 
PPTX
Windows Azure 基盤を支えるテクノロジー 
PPTX

PDF

PDF
Hadoop~Yahoo! JAPANの活用について~ 
PDF
20111130 10 aws-meister-emr_long-public 
PDF
20100520 【qpstudy01】 チームでトライ!インフラ構築のススメ 
PDF

PDF
ビッグデータはバズワードか? (Cloudian Summit 2012) 
PDF
Intalio japan special cloud workshop More from Recruit Technologies

PDF

PDF
カーセンサーで深層学習を使ってUX改善を行った事例とそこからの学び 
PDF
Rancherを活用した開発事例の紹介 ~Rancherのメリットと辛いところ~ 
PDF

PDF

PDF

PDF
リクルートグループの現場事例から見る AI/ディープラーニング ビジネス活用の勘所 
PDF
Company Recommendation for New Graduates via Implicit Feedback Multiple Matri... 
PDF

PDF

PDF
リクルートにおけるマルチモーダル Deep Learning Web API 開発事例 
PDF

PDF
ユーザーからみたre:Inventのこれまでと今後 
PDF
Struggling with BIGDATA -リクルートおけるデータサイエンス/エンジニアリング- 
PDF
EMRでスポットインスタンスの自動入札ツールを作成する 
PDF

PDF
リクルートにおけるセキュリティ施策方針とCSIRT組織運営のポイント 
PDF

PDF
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル 
PDF
「リクルートデータセット」 ~公開までの道のりとこれから~ Hadoopカンファレンス2013
- 1.
- 2.
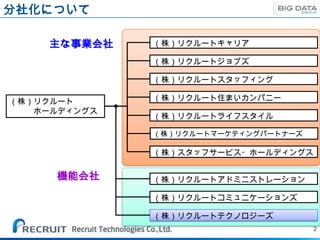
分社化について
主な事業会社 (株)リクルートキャリア
(株)リクルートジョブズ
(株)リクルートスタッフィング
(株)リクルート (株)リクルート住まいカンパニー
ホールディングス
(株)リクルートライフスタイル
(株)リクルートマーケティングパートナーズ
(株)スタッフサービス・ホールディングス
機能会社 (株)リクルートアドミニストレーション
(株)リクルートコミュニケーションズ
(株)リクルートテクノロジーズ
2
- 3.
- 4.
- 5.
自己紹介
□名前
石川 信行
( ground_beetle)
□出身
福島県 いわき市
大学時代は、害虫制御学、生物統計学、
進化生態学専攻
□経歴
・2009年リクルート新卒入社
・営業支援システムのコーダー(java)、DBAとして参加。
・2010年~Hadoop推進担当
・現Hadoop案件推進・新用途開発チームリーダー
□ 趣味
・外国産カブト虫飼育
・スキューバダイビング
・海水魚・サンゴ飼育
- 6.
- 7.
アジェンダ
1
• 体制と環境の進化
2
• 利活用事例紹介
3
• 新しい技術・用途開発
4
• 誰もが利用できるHadoopへ
5
• まとめ
- 8.
- 9.
- 10.
- 11.
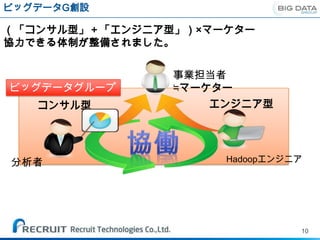
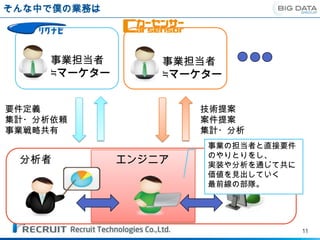
そんな中で僕の業務は
事業担当者 事業担当者
≒マーケター ≒マーケター
要件定義 技術提案
集計・分析依頼 案件提案
事業戦略共有 集計・分析
事業の担当者と直接要件
のやりとりをし、
分析者 エンジニア 構築・運用
実装や分析を通じて共に
価値を見出していく
最前線の部隊。
11
- 12.
- 13.
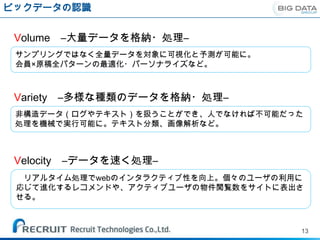
ビックデータの認識
Volume –大量データを格納・処理–
サンプリングではなく全量データを対象に可視化と予測が可能に。
会員×原稿全パターンの最適化・パーソナライズなど。
Variety –多様な種類のデータを格納・処理–
非構造データ(ログやテキスト)を扱うことができ、人でなければ不可能だった
処理を機械で実行可能に。テキスト分類、画像解析など。
Velocity –データを速く処理–
リアルタイム処理でwebのインタラクティブ性を向上。個々のユーザの利用に
応じて進化するレコメンドや、アクティブユーザの物件閲覧数をサイトに表出さ
せる。
13
- 14.
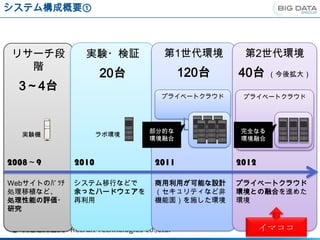
システム構成概要①
リサーチ段 実験・検証 第1世代環境 第2世代環境
階
20台 120台 40台 (今後拡大)
3~4台
プライベートクラウド プライベートクラウド
部分的な 完全なる
実験機 ラボ環境
環境融合 環境融合
2008~9 2010 2011 2012
Webサイトのバッチ システム移行などで 商用利用が可能な設計 プライベートクラウド
処理移植など、 余ったハードウェアを (セキュリティなど非 環境との融合を進めた
処理性能の評価・ 再利用 機能面)を施した環境 環境
研究
イマココ
- 15.
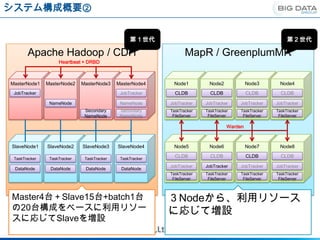
システム構成概要②
第1世代 第2世代
Apache Hadoop / CDH MapR / GreenplumMR
Heartbeat + DRBD
MasterNode1 MasterNode2 MasterNode3 MasterNode4 Node1 Node2 Node3 Node4
JobTracker JobTracker CLDB CLDB CLDB CLDB
NameNode NameNode JobTracker JobTracker JobTracker JobTracker
Secondary Secondary TaskTracker TaskTracker TaskTracker TaskTracker
NameNode NameNode FileServer FileServer FileServer FileServer
Warden
SlaveNode1 SlaveNode2 SlaveNode3 SlaveNode4 Node5 Node6 Node7 Node8
TaskTracker TaskTracker TaskTracker TaskTracker
CLDB CLDB CLDB CLDB
JobTracker JobTracker JobTracker JobTracker
DataNode DataNode DataNode DataNode
TaskTracker TaskTracker TaskTracker TaskTracker
FileServer FileServer FileServer FileServer
Master4台+Slave15台+batch1台 3Nodeから、利用リソース
の20台構成をベースに利用リソー に応じて増設
スに応じてSlaveを増設
- 16.
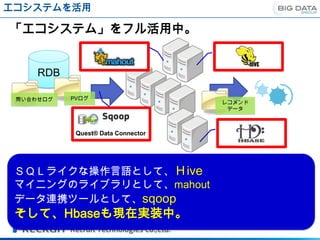
エコシステムを活用
「エコシステム」をフル活用中。
RDB
問い合わせログ PVログ
レコメンド
データ
Quest® Data Connector
SQLライクな操作言語として、Hive
マイニングのライブラリとして、mahout
データ連携ツールとして、sqoop
そして、Hbaseも現在実装中。
- 17.
- 18.
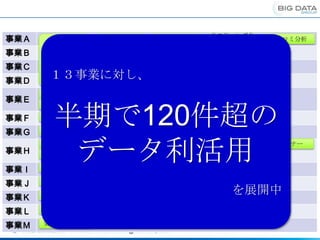
リスティング分
事業A 施策シェア分析
析
クチコミ分析
サイト横断
事業B サイト間 モニタリング レコメンド KWD×LP分析
クロスUU 指標
事業C 調査 予約分析
事業D
13事業に対し、
メルマガ施策 BI
KPIモニタリン
メール通数分析 現行応募相関 ステータス分析
事業E グ
半期で120件超の
自然語解析 行動ターゲティング LPO
事業F レコメンド ログ分析
メールレコメン
事業G 自然語解析
ド
需要予測 クレンジング
データ利活用
領域間クロス 集客モニタリン
需要予測 レコメンド 共通バナー
グ
事業H UU
カスタマープロファイル 商材分析 クライアントHP分析 カスタマートラッキング
KPIモニタリン アクション数予
事業I グ 測
効果集計
事業J 価格分析 レコメンド クラスタリング クチコミ分析
を展開中
事業K レコメンド
事業L レコメンド
事業M 効果見立て分析
18
- 19.
- 20.
- 21.
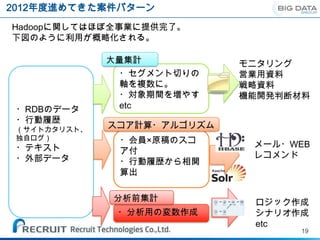
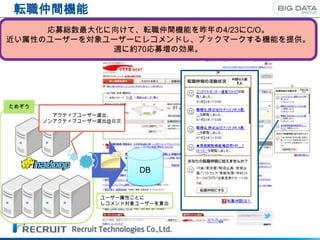
転職仲間機能
応募総数最大化に向けて、転職仲間機能を昨年の4/23にC/O。
近い属性のユーザーを対象ユーザーにレコメンドし、ブックマークする機能を提供。
週に約70応募増の効果。
ためぞう
アクティブユーザー選出、
ノンアクティブユーザー選出@日次
DB
ユーザー属性ごとに
レコメンド対象ユーザーを算出
- 22.
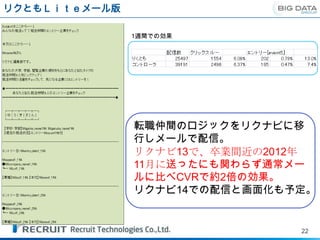
リクともLiteメール版
1週間での効果
転職仲間のロジックをリクナビに移
行しメールで配信。
リクナビ13で、卒業間近の2012年
11月に送ったにも関わらず通常メー
ルに比べCVRで約2倍の効果。
リクナビ14での配信と画面化も予定。
22
- 23.
- 24.
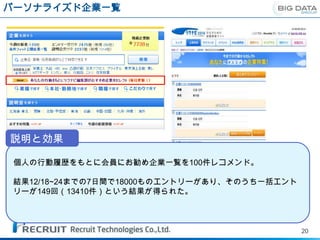
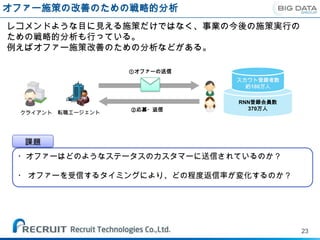
オファー施策の改善のための戦略的分析
・最新のステータス 1月1日のDB
・離脱のタイミングや
RDBMS レジュメの変更比較が
(会員離脱状況や原稿
掲載状況など)の保存 可能に。
1月2日のDB
・行動履歴の部分取得 ・種々の行動履歴を
1月3日のDB 長期間保存可能に。
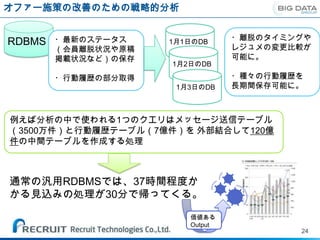
例えば分析の中で使われる1つのクエリはメッセージ送信テーブル
(3500万件)と行動履歴テーブル(7億件)を 外部結合して120億
件の中間テーブルを作成する処理
通常の汎用RDBMSでは、37時間程度か
かる見込みの処理が30分で帰ってくる。
価値ある
Output
24
- 25.
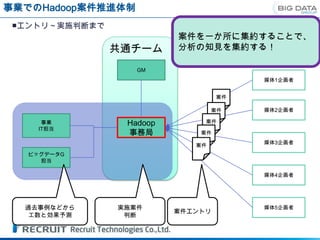
事業でのHadoop案件推進体制
■エントリ~実施判断まで
案件を一か所に集約することで、
共通チーム 分析の知見を集約する!
GM
媒体1企画者
案件
案件 媒体2企画者
事業 Hadoop 案件
IT担当
事務局 案件
媒体3企画者
案件
ビッグデータG
担当
媒体4企画者
過去事例などから 実施案件 媒体5企画者
案件エントリ
工数と効果予測 判断
- 26.
- 27.
- 28.
- 29.
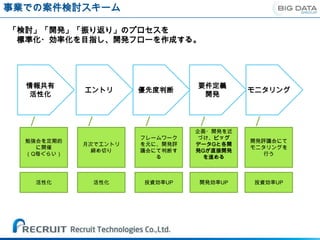
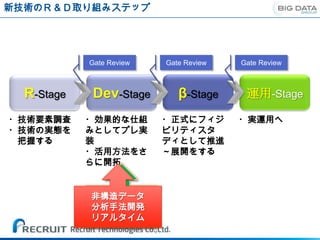
新技術のR&D取り組みステップ
Gate Review Gate Review Gate Review
R-Stage Dev-Stage β-Stage 運用-Stage
・技術要素調査 ・効果的な仕組 ・正式にフィジ ・実運用へ
・技術の実態を みとしてプレ実 ビリティスタ
把握する 装 ディとして推進
・活用方法をさ ~展開をする
らに開拓
非構造データ
ビッグデータ
分析手法開発
(Hadoop)
リアルタイム
- 30.
- 31.
- 32.
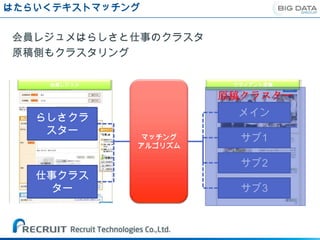
Tryの数だけ成果があがる
• 以下のような技術要素について、トライ&エラー・・・!
・150文字以下のレジュメは除外
①データの定義 ・レジュメフォーマット使用疑い者を除外
※クラスタリングが ・原稿側で、複数回掲載原稿でコピペしたような原稿
適切になされるように について修正
・原稿タイトル部分のウエイトを重くする
するために検討が必要
・単語の重要度を定義し、使用用語を選定
・階層クラスタリング(KH-Coderによる)
・K-Means(Mahoutによる)
②クラスタリング手法 ・Fuzzy K-Means(Mahoutによる)
・LatentDiricletAllocation(Mahoutによる)
・アソシエーション
・ロジスティック回帰(SPSS-Modelerによる)
③クラスタ間の関係の表現手法 ・SGD手法(Mahoutによる)
・RandomForest(Mahoutによる)
・Tree-Net(SLFDによる)
④評価指標 ・各種論文やモデリング指標を参考
- 33.
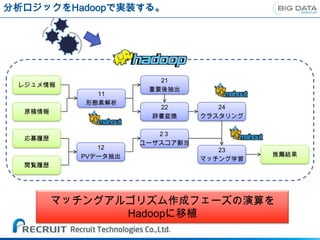
分析ロジックをHadoopで実装する。
21
レジュメ情報
重要後抽出
11
形態素解析
22 24
原稿情報
辞書変換 クラスタリング
23
応募履歴
ユーザスコア割当
12 23
PVデータ抽出 推薦結果
マッチング学習
閲覧履歴
マッチングアルゴリズム作成フェーズの演算を
Hadoopに移植
- 34.
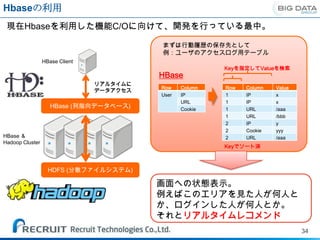
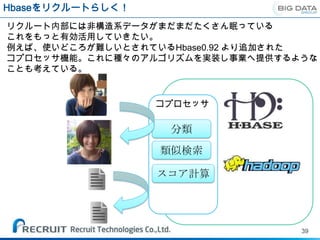
Hbaseの利用
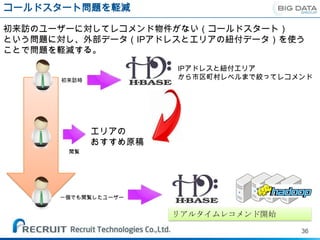
現在Hbaseを利用した機能C/Oに向けて、開発を行っている最中。
まずは行動履歴の保存先として
例:ユーザのアクセスログ用テーブル
HBase Client
Keyを指定してValueを検索
HBase
リアルタイムに
Row Column Row Column Value
データアクセス
User IP 1 IP x
URL 1 IP x
HBase (列指向データベース) Cookie 1 URL /aaa
1 URL /bbb
2 IP y
2 Cookie yyy
HBase & 2 URL /aaa
Hadoop Cluster
Keyでソート済
HDFS (分散ファイルシステム)
画面への状態表示。
例えばこのエリアを見た人が何人と
か、ログインした人が何人とか。
それとリアルタイムレコメンド
34
- 35.
- 36.
- 37.
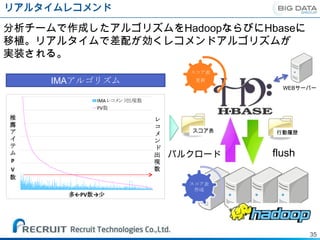
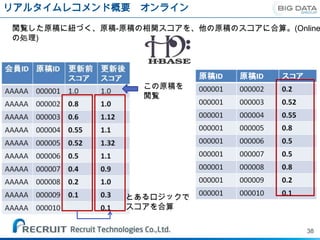
リアルタイムレコメンド概要 バッチ
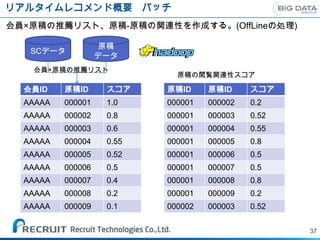
会員×原稿の推薦リスト、原稿-原稿の関連性を作成する。(OffLineの処理)
原稿
SCデータ
データ
会員×原稿の推薦リスト
原稿の閲覧関連性スコア
会員ID 原稿ID スコア 原稿ID 原稿ID スコア
AAAAA 000001 1.0 000001 000002 0.2
AAAAA 000002 0.8 000001 000003 0.52
AAAAA 000003 0.6 000001 000004 0.55
AAAAA 000004 0.55 000001 000005 0.8
AAAAA 000005 0.52 000001 000006 0.5
AAAAA 000006 0.5 000001 000007 0.5
AAAAA 000007 0.4 000001 000008 0.8
AAAAA 000008 0.2 000001 000009 0.2
AAAAA 000009 0.1 000002 000003 0.52
37
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
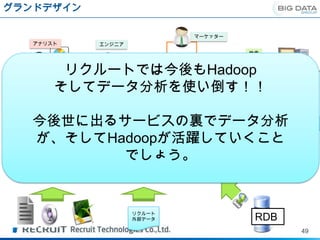
グランドデザイン
マーケッター
アナリスト エンジニア
検索
リクルートでは今後もHadoop 画面表示
BIツール
そしてデータ分析を使い倒す!!
連携
Storm
Apache drill 行動ログ
リアルタイ
今後世に出るサービスの裏でデータ分析
ム蓄積
ログ
日次蓄積
Solr 高速
が、そしてHadoopが活躍していくこと オンライン処理
でしょう。 ・高速バッチ処理
・データストア
リクルート
外部データ RDB
49