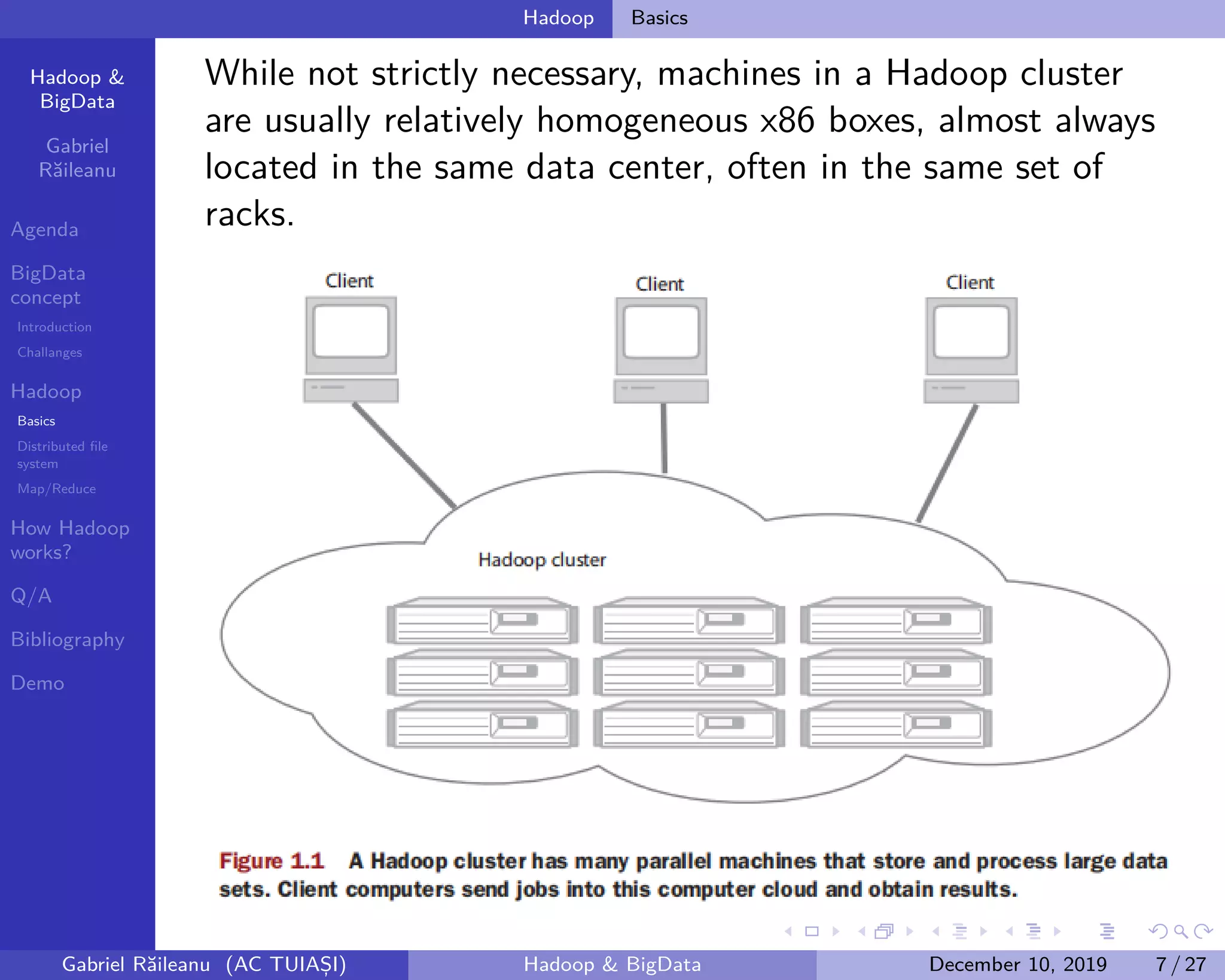
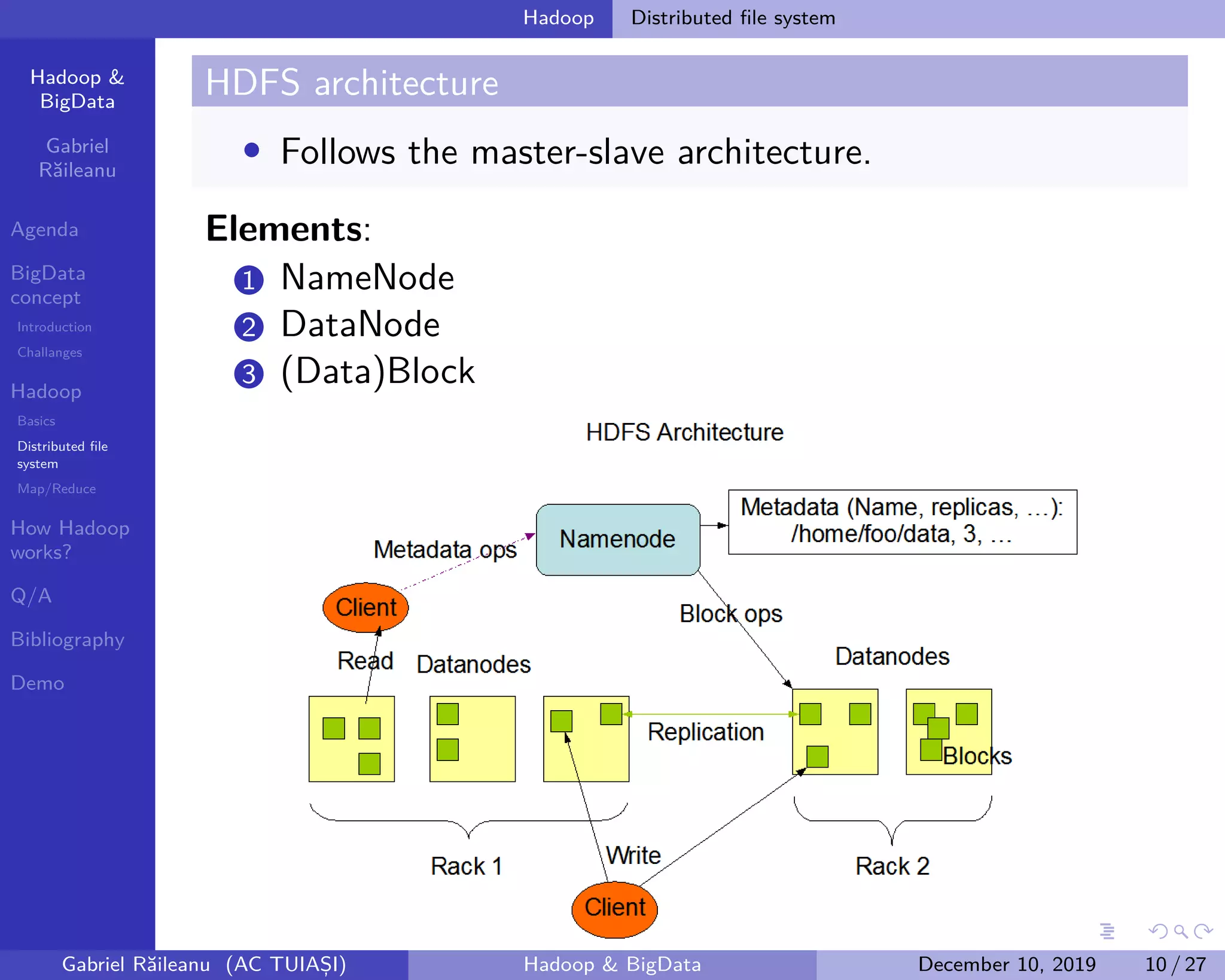
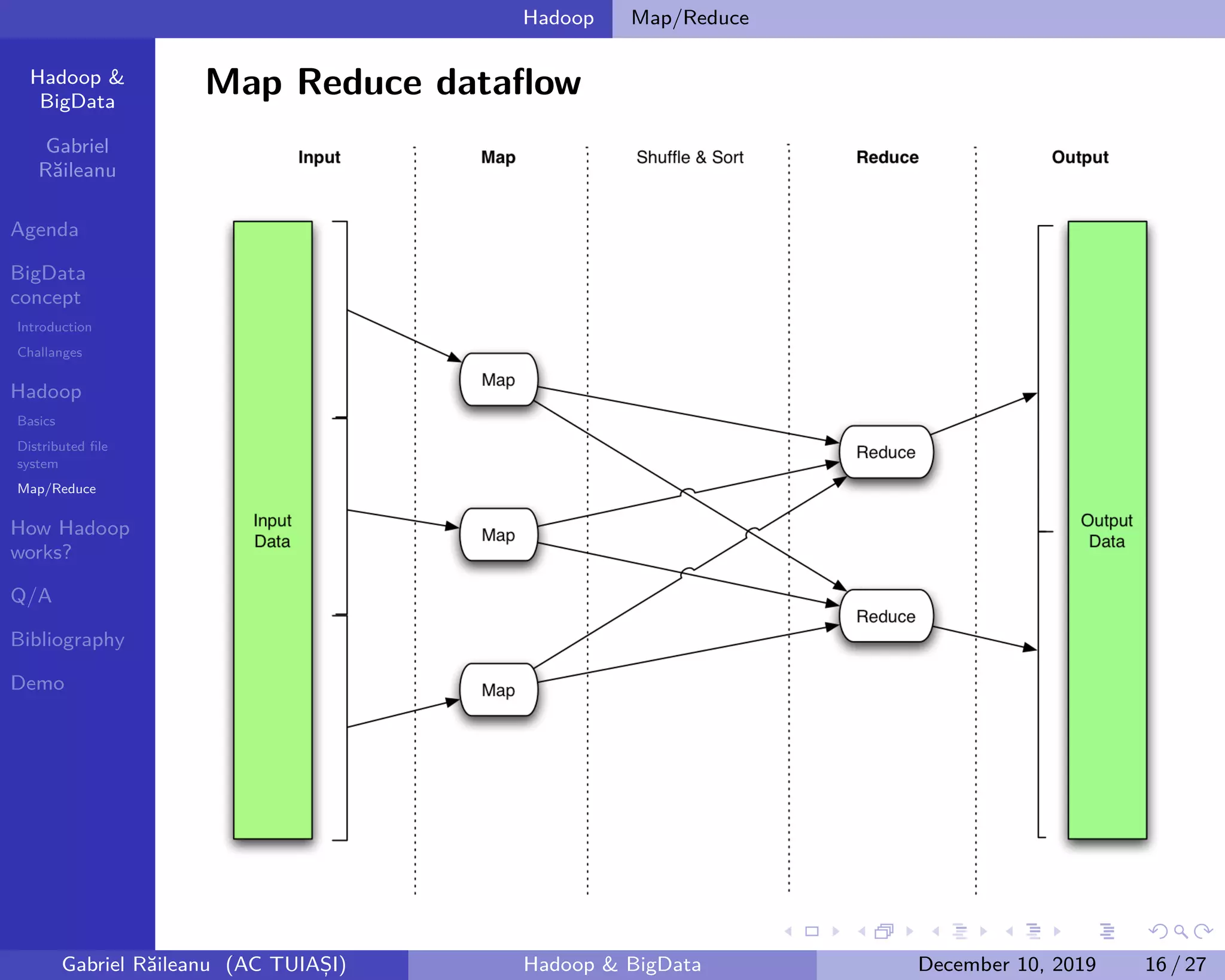
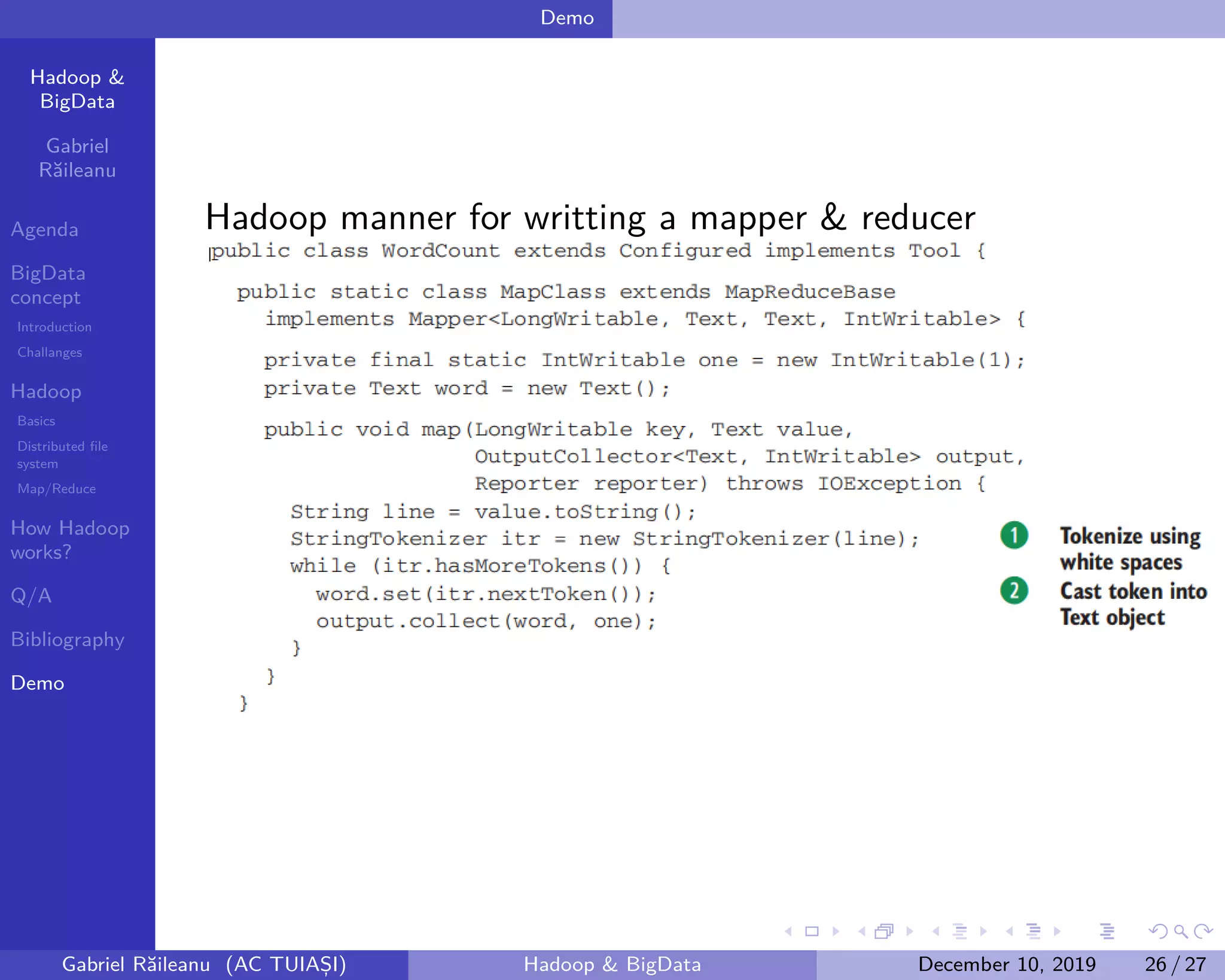
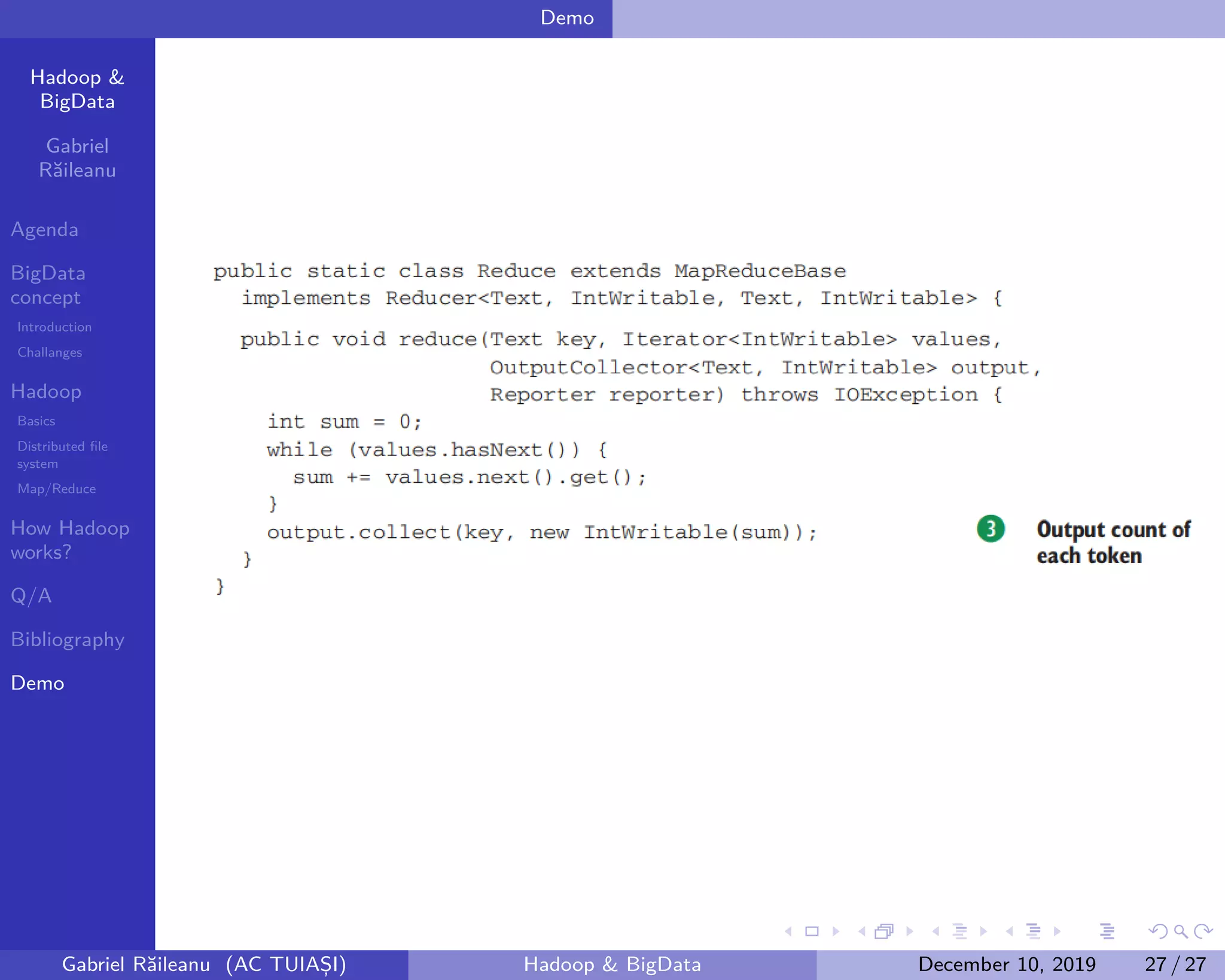
The document presents an overview of Big Data concepts and the Hadoop framework, detailing its distributed file system and the MapReduce programming model. It identifies challenges related to Big Data, such as data growth and integration, and explains how Hadoop processes large data volumes efficiently across clusters. Key components of Hadoop, including the namenode and datanodes, are described, along with their roles in managing data storage and processing tasks.