
Download as PPS, PPTX





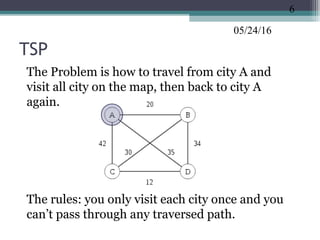
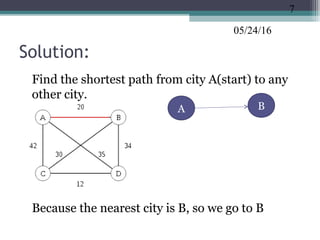
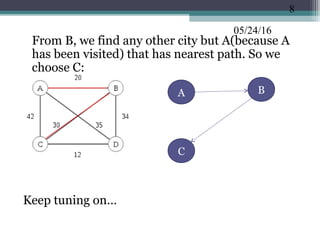
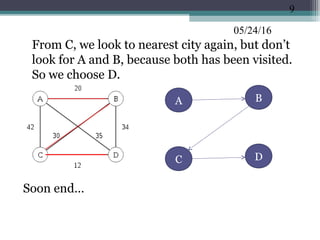


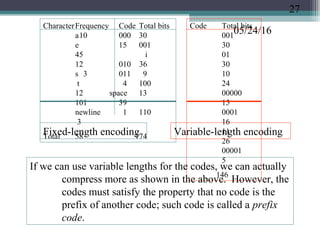
![05/24/16
Breadth-First Search (BFS):
BFS(v) // visit all nodes reachable from node v
(1) create an empty FIFO queue
Q, add node v to Q (2) create a
boolean array visited[1..n], initialize all values
to false except for visited[v] to true
(3) while Q is not empty
(3.1) delete a node w from Q
(3.2) for each node z adjacent from
node w if
visited[z] is false then
add node z to Q and set visited[z] to
true
1
2 4
3
5
6
Node search order
starting
with node
1,
including
two nodes
not
reached
The time complexity is O(n+e)
with n nodes and e
edges, if the
adjacency lists are
used. This is because
in the worst case,
each node is added
once to the queue
(O(n) part), and each
of its neighbors gets
14](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-14-320.jpg)
![05/24/16
Depth-First Search (DFS):
(1) create a boolean array visited[1..n], initialize all
values to false except for visited[v] to true
(2) call DFS(v) to visit all nodes
reachable via a path
DFS(v)
for each neighboring nodes w of
v do if
visited[w] is false then
set visited[w] to true; call
DFS(w) // recursive call
1
2 5
3 6
4
Node search order
starting with
node 1,
including two
nodes not
reached
The algorithm’s time
complexity is
also O(n+e) using
the same
reasoning as in
the BFS
algorithm.
15](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-15-320.jpg)



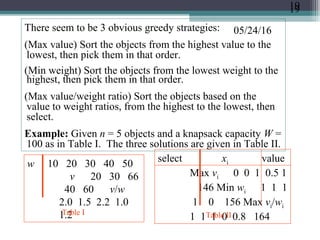
![05/24/16The Optimal Knapsack Algorithm:
Input: an integer n, positive values wi and vi , for 1
≤ i ≤ n, and another positive value W.
Output: n values xi such that 0 ≤ xi ≤ 1 and
Algorithm (of time complexity O(n lgn))
(1) Sort the n objects from large to small based on
the ratios vi/wi . We assume the arrays w[1..n]
and v[1..n] store the respective weights and
values after sorting. (2) initialize array x[1..n] to
zeros. (3) weight = 0; i = 1
(4) while (i ≤ n and
weight < W) do (4.1)
if weight + w[i] ≤ W then x[i] = 1
(4.2) else x[i] = (W – weight) / w[i]
(4.3) weight = weight + x[i]
* w[i] (4.4) i++
∑∑ ≤
==
n
i
ii
n
i
ii vxWwx
11
maximized.isand
20](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-20-320.jpg)


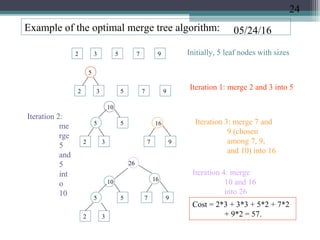
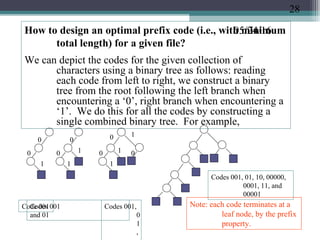
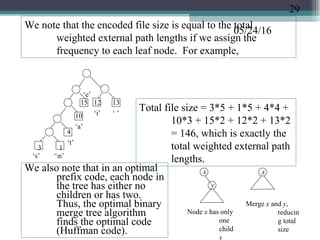
![05/24/16Optimal Binary Merge Tree Algorithm:
Input: n leaf nodes each have an integer size, n ≥ 2.
Output: a binary tree with the given leaf nodes
which has a minimum total weighted
external path lengths
Algorithm:
(1) create a min-heap T[1..n ] based on the n initial
sizes. (2) while (the heap size ≥ 2) do
(2.1) delete from the
heap two smallest values, call
them a and b, create a parent node of size a + b
for the nodes corresponding to these
two values (2.2) insert the value (a
+ b) into the heap which
corresponds to the node created in Step (2.1)
When the algorithm terminates, there is a single value left in
the heap whose corresponding node is the root of the
optimal binary merge tree. The algorithm’s time
complexity is O(n lgn) because Step (1) takes O(n)
23](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-23-320.jpg)




![05/24/16Both directed and undirected graphs appear often and naturally
in many scientific (call graphs in program analysis),
business (query trees, entity-relation diagrams in
databases), and engineering (CAD design) applications.
The simplest data structure for representing graphs and
digraphs is using 2-dimensional arrays. Suppose G =
(V, E), and |V| = n. Declare an array T[1..n][1..n] so that
T[i][j] = 1 if there is an edge (i, j) ∈ E; 0 otherwise.
(Note that in an undirected graph, edges (i, j) and (j, i)
refer to the same edge.)
1
4
2 3
0010
0101
1000
0010
1 2 3 4
1
2
3
4
A 2-dimensional
array for the
digraph,
called the
adjacency
matrix.
i
j
32](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-32-320.jpg)
![05/24/16Sometimes, edges of a graph or digraph are given a
positive weight or cost value. In that case, the
adjacency matrix can easily modified so that T[i]
[j] = the weight of edge (i, j); 0 if there is no edge
(i, j). Since the adjacency matrix may contain
many zeros (when the graph has few edges,
known as sparse), a space-efficient representation
uses linked lists representing the edges, known as
the adjacency list representation.
1
4
2 3
1
2
3
4
2
4
3 1
2
The adjacency lists for the digraph, which
can store edge weights by adding
another field in the list nodes.
33](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-33-320.jpg)

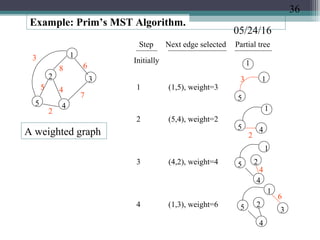
![05/24/16
Prim’s Algorithm for the Minimum Spanning Tree problem:
Create an array B[1..n] to store the nodes of the MST, and an
array T[1..n –1] to store the edges of the MST. Starting
with node 1 (actually, any node can be the starting node),
put node 1 in B[1], find a node that is the closest (i.e., an
edge connected to node 1 that has the minimum weight,
ties broken arbitrarily). Put this node as B[2], and the
edge as T[1]. Next look for a node connected from either
B[1] or B[2] that is the closest, store the node as B[3],
and the corresponding edge as T[2]. In general, in the kth
iteration, look for a node not already in B[1..k] that is the
closest to any node in B[1..k]. Put this node as B[k+1],
the corresponding edge as T[k]. Repeat this process for n
–1 iterations (k = 1 to n –1). This is a greedy strategy
because in each iteration, the algorithm looks for the
minimum weight edge to include next while maintaining
the tree property (i.e., avoiding cycles). At the end there
are exactly n –1 edges without cycles, which must be a
35](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-35-320.jpg)
![05/24/16An adjacency matrix implementation of Prim’s algorithm:
Input: W[1..n][1..n] with W[i, j] = weight of edge (i, j); set W[i, j] = ∞ if
no edge Output: an MST with tree edges stored in T[1..n –1]
Algorithm:
(1) declare nearest[2..n], minDist[2..n] such that minDistt[i] = the
minimum edge weight connecting node i to any node in partial tree T, and
nearest[i]=the node in T that gives minimum distance for node i.
(2) for i = 2 to n do
nearest[i]=1; minDist[i]=W[i, 1]
(3) for p = 1 to (n –1) do
(3.1) min = ∞
(3.2) for j = 2 to n do
if 0 ≤ minDist[j] < min then
min = minDist[j]; k = j
(3.3) T[p] = edge (nearest[k], k) // selected the
nest edge (3.4) minDist[k] = –1 // a negative
value means node k is “in” (3.5) for j = 2 to n
do // update minDist and nearest values
if W[j, k] < minDist[j] then
minDist[j] = W[j, k]; nearest[j] = k
The time complexity is O(n2
) because Step (3) runs O(n) iterations, each iteration
Tree T
i
nearest[i]
minDist[i]
37](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-37-320.jpg)

![05/24/16Example (Dijkstra’s shortest paths algorithm):
1
2
34
5
A weighted directed
graph,
source node
= 1
10 50
100
10
30
20
50
5
Remaining nodes
and the distances
step tree of shortest
paths from the source
Initially 1 C = [ 2, 3, 4, 5]
D =
[50,30,10
0,10]
Choose
n
o
d
e
5
1
5
[ 2, 3, 4]
[50,
30,
20]
Changed
f
r
o
m
1
0
0
Choose
n
o
d
e
4
1
5
4
[ 2, 3]
[4
0,
30
]
Changed
f
r
o
m
5
0
Choose
n
o
d
e
3
5
4
1
3
[ 2]
[
3
5
]
Changed
f
r
o
m
4
0
Choose
n
o
d
3
1
5
4
2
∅
Shortest paths:
To Path
Distance
5 (1,5) 10
4 (1,5,4)
20
39](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-39-320.jpg)
![05/24/16Implementation of Dijkstra’s algorithm:
Input: W[1..n][1..n] with W[i, j] = weight of edge (i, j); set W[i, j] = ∞ if no
edge Output: an array D[2..n] of distances of shortest paths to each
node in [2..n] Algorithm:
(1) C = {2,3,…,n} // the set of remaining nodes
(2) for i = 2 to n do D[i] = W[1,i] // initialize
distance from node 1 to node i (3) repeat the following n
– 2 times // determine the shortest distances
(3.1) select node v of set C that has the minimum value in array D
(3.2) C = C – {v} // delete node v
from set C (3.3)
for each node w in C do
if (D[v] + W[v, w] < D[w]) then
D[w]
= D[v] + W[v, w] // update D[w] if found shorter path to w1
v
w
W[v,w]
D[v]
D[w]
Tree of
short
est
The algorithm’s time complexity
is O(n2
) because Steps
(1) and (2) each take
O(n) time; Step (3)
runs in O(n) iterations
in which each iteration
runs in O(n) time.
40](https://image.slidesharecdn.com/greedyalgorithms-160524172956/85/Greedy-Algorithms-with-examples-b-18298-40-320.jpg)
The document discusses greedy algorithms and provides examples. It begins with an overview of greedy algorithms and their properties. It then provides a sample problem (traveling salesman) and shows how a greedy approach can provide an iterative solution. The document notes advantages and disadvantages of greedy algorithms and provides additional examples, including optimal binary tree merging and the knapsack problem. It concludes with describing algorithms for optimal solutions to these problems.



















































































