Download as PDF, PPTX










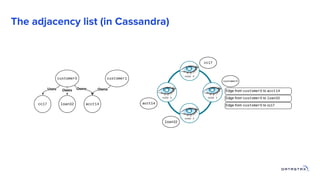


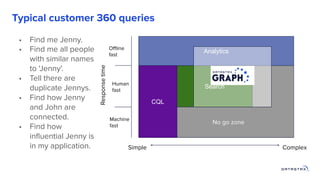
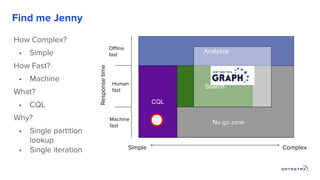

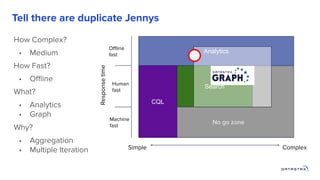
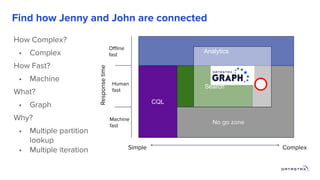
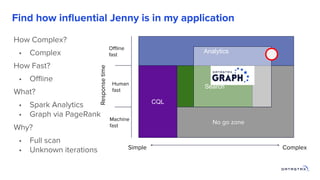
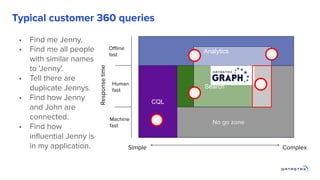





1. Building a graph database requires modeling the data, choosing a query language, and providing storage. 2. Existing distributed databases like Cassandra can be used for storage due to their scalability and reliability, though a native graph database provides more functionality. 3. Solving complex graph problems requires capabilities beyond basic queries, including search, analytics, and integration with machine learning, which graph databases are designed to support at scale.























































































