Download as PDF, PPTX



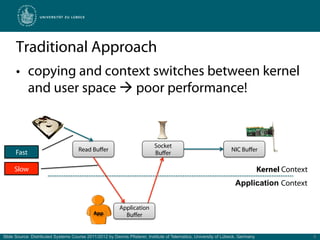
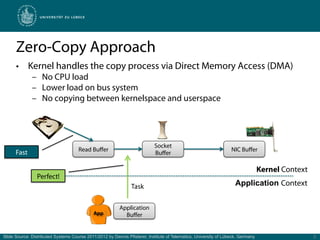
![Simple Benchmark: Copy vs. Zero-Copy
Duration [ms]
Data [Mbyte]
Slide Source: Distributed Systems Course 2011/2012 by Dennis Pfisterer, Institute of Telematics, University of Lübeck, Germany 6](https://image.slidesharecdn.com/zero-copyevent-drivenserverswithnetty-111216061658-phpapp01/85/Zero-Copy-Event-Driven-Servers-with-Netty-6-320.jpg)









![Introduction to Netty - Buffers
• Netty uses a zero-copy strategy for efficiency
• Primitive byte[] are wrapped in a ChannelBuffer
• Simple read/write operations, e.g.:
– writeByte()
– writeLong()
– readByte()
– readLong()
– …
• Hides complexities such as byte order
• Uses low overhead index pointers for realization:
17](https://image.slidesharecdn.com/zero-copyevent-drivenserverswithnetty-111216061658-phpapp01/85/Zero-Copy-Event-Driven-Servers-with-Netty-17-320.jpg)






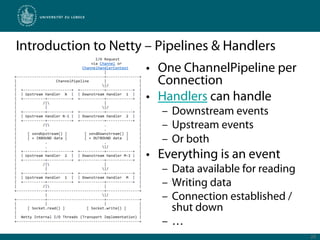


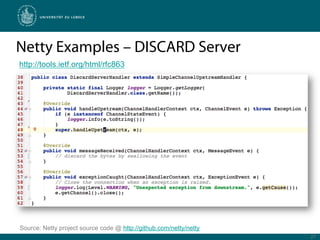
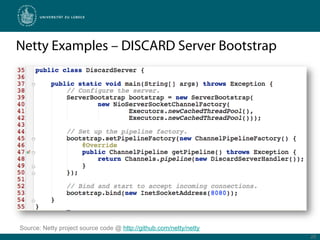
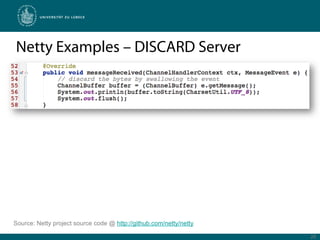
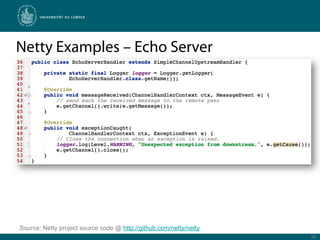


Netty is a Java framework that provides tools for developing high performance and event-driven network applications. It uses non-blocking I/O and zero-copy techniques to minimize overhead and maximize throughput and scalability. Netty provides buffers, codecs, pipelines and handlers that allow building applications as a stack of processing layers. Example applications include a discard server and an HTTP file server that demonstrate Netty's core features and event-driven architecture.












![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)















































































