Downloaded 75 times


![(Michael Hunger)-[:WORKS_FOR]->(Neo4j)
michael@neo4j.com | @mesirii | github.com/jexp | jexp.de/blog
Michael Hunger - Head of Developer Relations @Neo4j](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-2-320.jpg)

























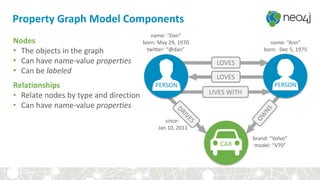
![Cypher: Powerful and Expressive Query Language
MATCH (:Person { name:“Dan”} ) -[:LOVES]-> (:Person { name:“Ann”} )
LOVES
Dan Ann
LABEL PROPERTY
NODE NODE
LABEL PROPERTY](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-37-320.jpg)

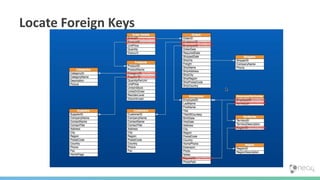
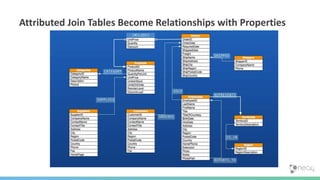
![(FKs)-[:BECOME]->(Relationships) & Correct Directions](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-43-320.jpg)
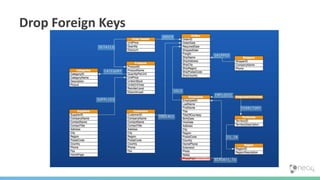
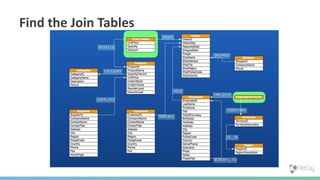
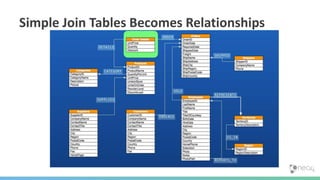
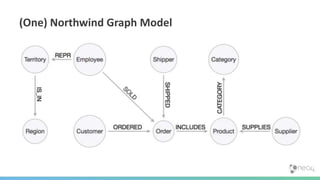
![(:You)-[:QUERY]->(:Data)
in a graph](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-49-320.jpg)



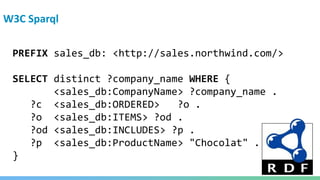
![openCypher
MATCH (c:Customer)-[:ORDERED]->(o)
-[:INCLUDES]->(p:Product)
WHERE p.productName = 'Chocolat'
RETURN distinct p.companyName](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-54-320.jpg)
![Basic Pattern: Customers Orders?
MATCH (:Customer {custName:"Delicatessen"} ) -[:ORDERED]-> (order:Order) RETURN order
VAR LABEL
NODE NODE
LABEL PROPERTY
ORDERED
Customer OrderOrder
REL](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-55-320.jpg)
![Basic Query: Customer's Orders?
MATCH (c:Customer)-[:ORDERED]->(order)
WHERE c.customerName = 'Delicatessen'
RETURN *](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-56-320.jpg)
![Basic Query: Customer's Frequent Purchases?
MATCH (c:Customer)-[:ORDERED]->
()-[:INCLUDES]->(p:Product)
WHERE c.customerName = 'Delicatessen'
RETURN p.productName, count(*) AS freq
ORDER BY freq DESC LIMIT 10;](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-57-320.jpg)
![openCypher - Recommendation
MATCH
(c:Customer)-[:ORDERED]->(o1)-[:INCLUDES]->(p),
(peer)-[:ORDERED]->(o2)-[:INCLUDES]->(p),
(peer)-[:ORDERED]->(o3)-[:INCLUDES]->(reco)
WHERE c.customerId = $customerId
AND NOT (c)-[:ORDERED]->()-[:INCLUDES]->(reco)
RETURN reco.productName, count(*) AS freq
ORDER BY freq DESC LIMIT 10](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-58-320.jpg)
![Product Cross-Sell
MATCH
(:Product {productName: 'Chocolat'})<-[:INCLUDES]-(:Order)
<-[:SOLD]-(employee)-[:SOLD]->()-[:INCLUDES]->(cross:Product)
RETURN
employee.firstName, cross.productName,
count(distinct o2) AS freq
ORDER BY freq DESC LIMIT 5;](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-59-320.jpg)




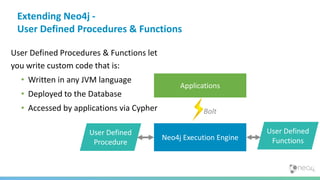





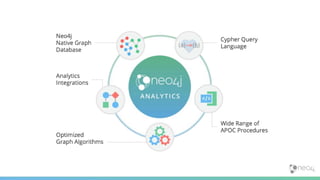

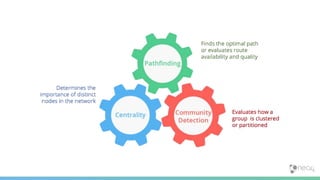

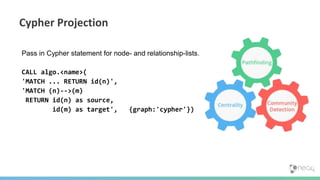




![Spring Data Neo4j Neo4j OGM
interface TalkRepository extends Neo4jRepository<Talk, Long> {
@Query("MATCH (t:Talk)<-[rating:RATED]-(user)
WHERE t.id = {talkId} RETURN rating")
List<Rating> getRatings(@Param("talkId") Long talkId);
List<Talk> findByTitleContaining(String title);
}](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-83-320.jpg)

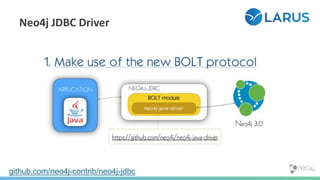





















![MATCH (sub)-[:REPORTS_TO*0..3]->(boss),
(report)-[:REPORTS_TO*1..3]->(sub)
WHERE boss.name = "Andrew K."
RETURN sub.name AS Subordinate,
count(report) AS Total
Express Complex Queries Easily with Cypher
Find all direct reports and how
many people they manage,
up to 3 levels down
Cypher Query
SQL Query](https://image.slidesharecdn.com/oopgraphdatabases-180219195548/85/A-whirlwind-tour-of-graph-databases-132-320.jpg)

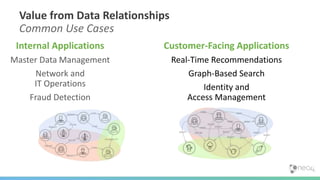
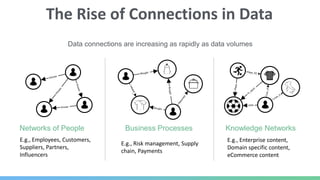
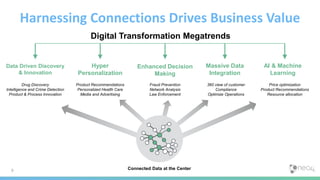
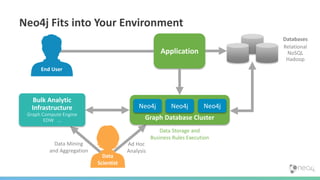
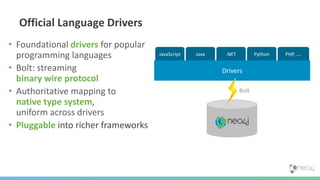
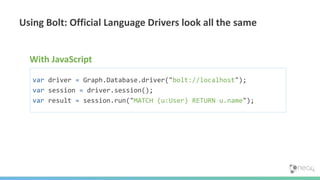
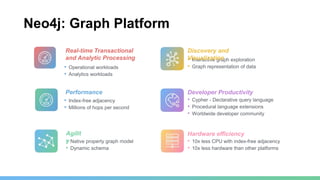
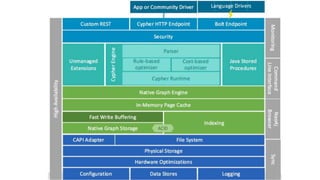
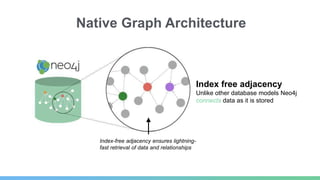
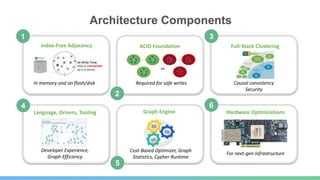
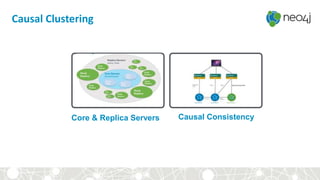
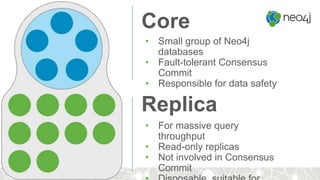
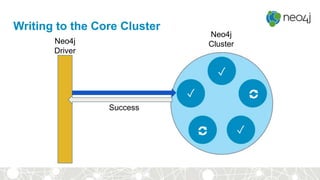
This document provides an overview of GraphDB and Neo4j. It discusses why graphs are useful for modeling connected data and common use cases. It also summarizes Neo4j's transactional graph database capabilities, performance advantages, and deployment options. Key topics covered include causal clustering, query planning, and driver and tooling support for developers.























































































