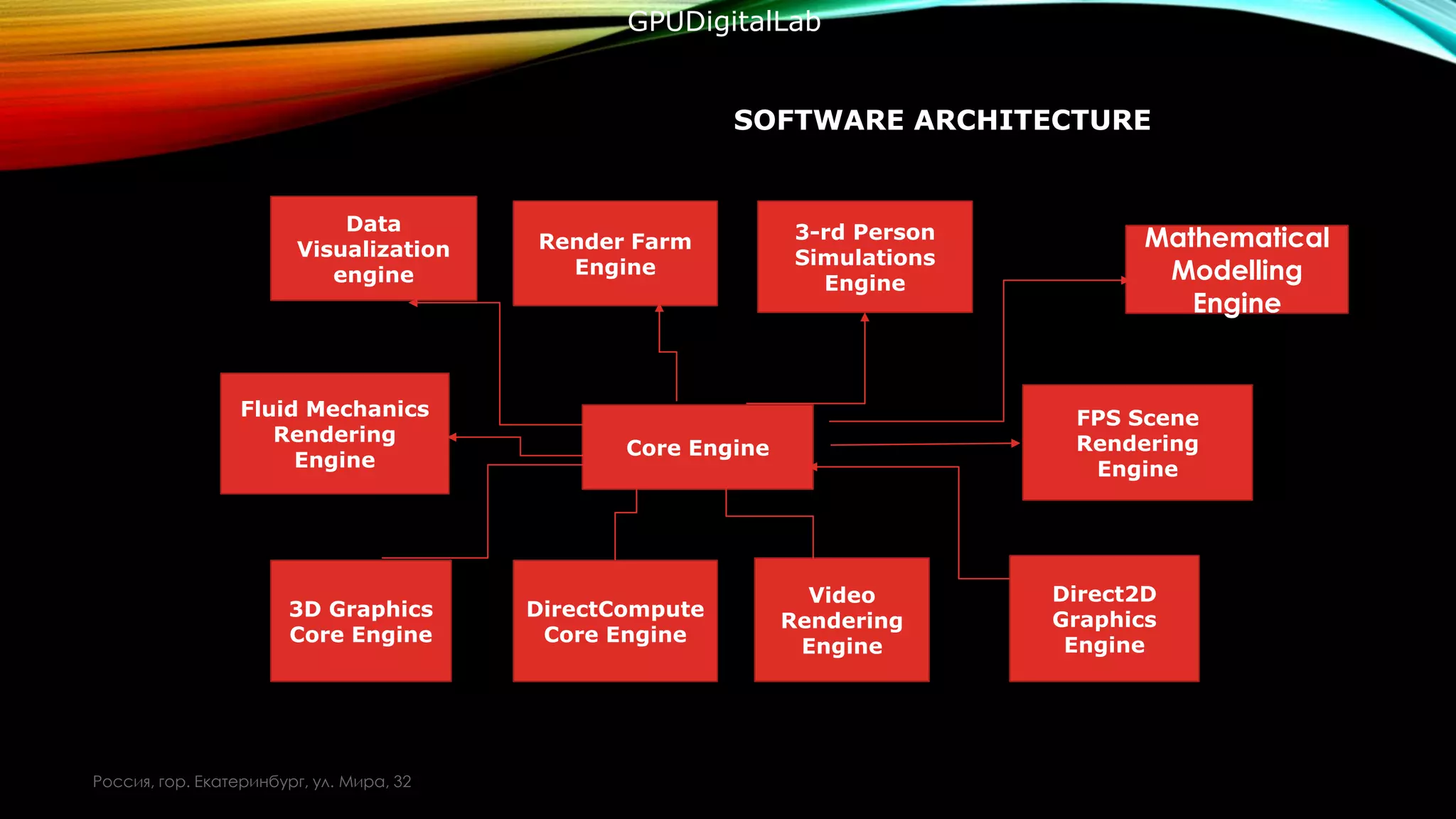
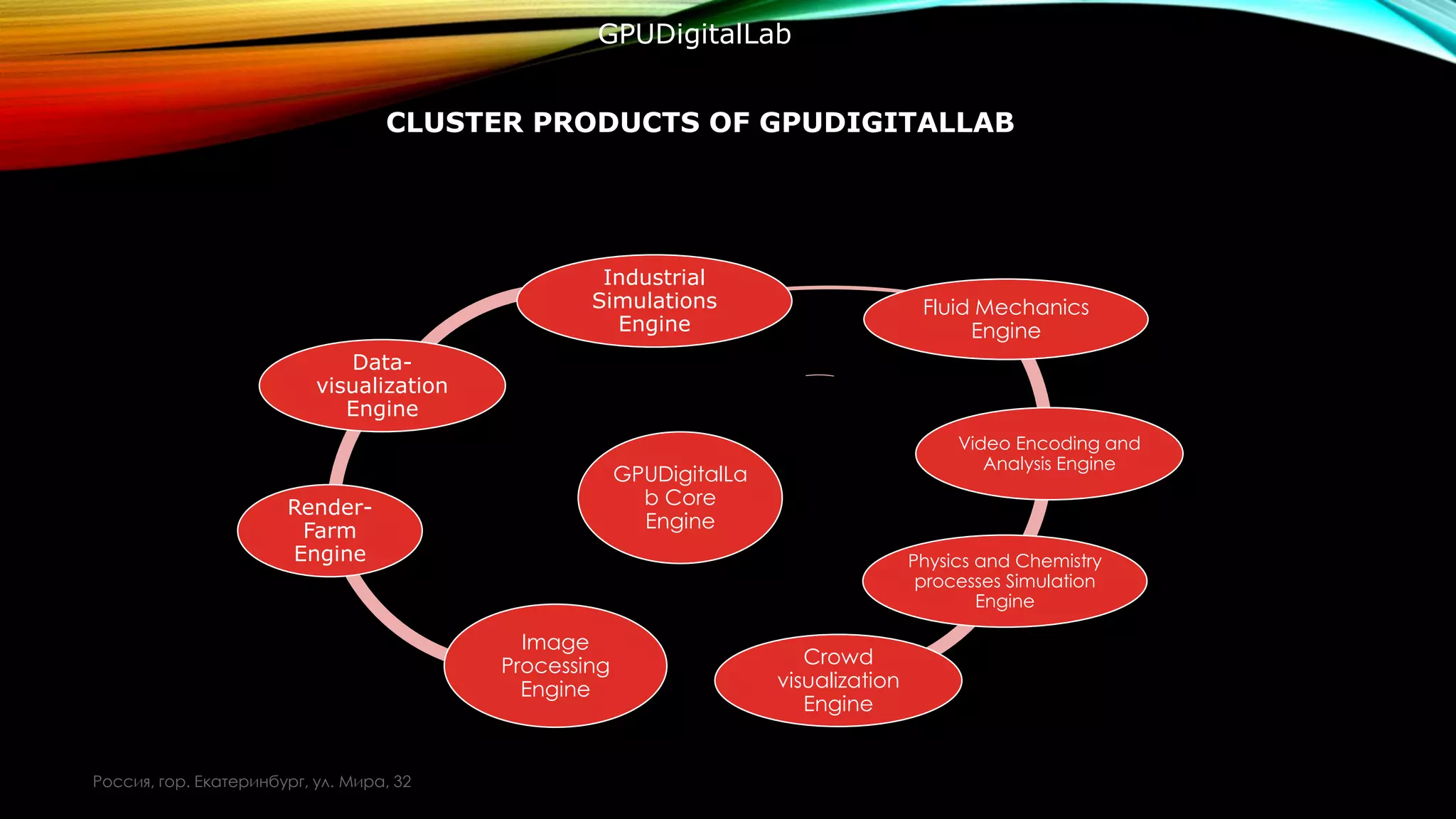
- This project consists of a GPU processing core engine that has a set of connected client applications working in allocated domains.
- The aim of the project is to provide the scientific community with a powerful computational platform at a reasonable price.
- The architecture allows users to leverage the power of GPUs for parallel computing despite having relatively inexpensive local hardware.








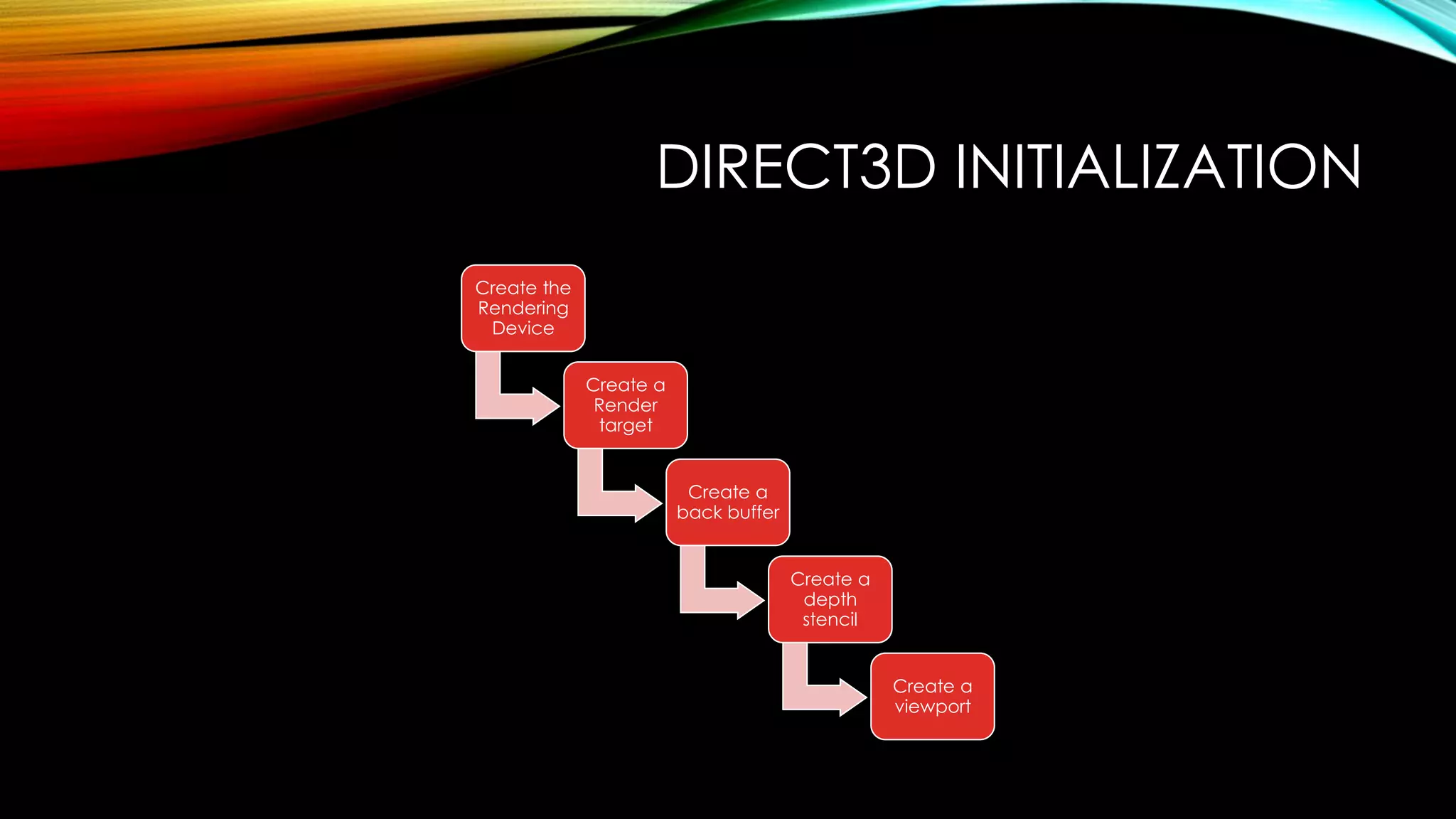
![PROGRAM STARTUP
Create
main
window
•Program
Startup
Launch
Direct3D11
Engine
•Direct3
D11
Initialize
DirectCompu
te
Manager
Create GPU
Core
Object
•]
Initialize
Rendering
Engine](https://image.slidesharecdn.com/gpudigitallabenglishversion-150727134450-lva1-app6891/75/Gpu-digital-lab-english-version-10-2048.jpg)





















































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































