Download to read offline









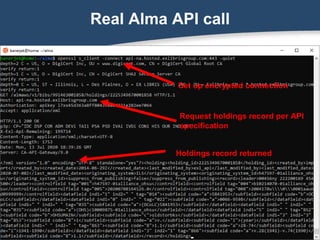








![curl examples
curl -s -H "Authorization: apikey [your API key]"
-H "Accept: application/xml"
GET https://api-na.hosted.exlibrisgroup.com/[api call]
curl -s -H "Authorization: apikey [your API key]"
-d "$DATA" # data stored in variable
-H "Content-Type: application/xml"
PUT https://api-na.hosted.exlibrisgroup.com/[api call]
curl -s -H "Authorization: apikey [your API key]"
-d "@datafile" # data stored in file
-H "Content-Type: application/xml"
PUT https://api-na.hosted.exlibrisgroup.com/[api call]](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-19-320.jpg)
![curl examples
Reading records
curl -s -H "Authorization: apikey [your API key]"
-H "Accept: application/xml"
GET https://api-na.hosted.exlibrisgroup.com/[api call]
Updating records
curl -s -H "Authorization: apikey [your API key]"
-H "Content-Type: application/xml" -d "$DATA"
PUT https://api-na.hosted.exlibrisgroup.com/[api call]
Creating records
curl -s -H "Authorization: apikey [your API key]"
-H "Content-Type: application/xml" -d "@datafile"
POST https://api-na.hosted.exlibrisgroup.com/[api call]](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-20-320.jpg)



![Extract a value and store in a variable
holdingid=$(echo $record |xmlstarlet sel -t -m
"item/holding_data/holding_id" -v . )
Update a node within an XML document
holdings=$(echo $holdings | xmlstarlet ed -u
'/holding/record/datafield[@tag="852"]/subfield[@code="c"]
' -v 'oldstorbks')
Xmlstarlet examples](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-24-320.jpg)

![● Strip everything except numbers from
barcode variable
barcode=$(sed 's/[^0-9]//g' <<< "$barcode")
● Strip all nonnumeric data from file1 with
results sent to file2
cat file1 | sed 's/[^0-9]//g' > file2
sed examples](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-26-320.jpg)
![Quick Regular Expression Guide
^ Match the start of the line
$ Match the end of the line
. Match any single character
* Match zero or more of the previous character
[A-D,G-J,0-5]* [A-D,G-J,0-5]* = match zero or more of ABCDGHIJ012345
[^A-C] Match any one character that is NOT A,B, or C
(dog)
Match the word "dog", including case, and remember that text
to be used later in the match or replacement
1
Insert the first remembered text as if it were typed here (2 for
second, 3 for 3rd, etc.)
Use to match special characters. matches a backslash, *
matches an asterisk, $ matches dollar sign, etc.](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-27-320.jpg)

![Read and process file
# Read file named “barcodes” one line at a time
cat barcodes | while read line
do
# Clean barcode
barcode=$(sed 's/[^0-9]//g' <<< "$line")
# print barcode
echo barcode
done](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-29-320.jpg)


![cat barcodes| while read barcode # Read input file named “barcodes” one line at a time
do
barcode=$(sed 's/[^0-9]//g' <<< "$barcode") # Clean barcode
# Get record and extract record ids
recinfo=$(curl -s -X GET -L -H "Authorization: apikey $(cat apikey.txt)" "https://api-
na.hosted.exlibrisgroup.com/almaws/v1/items?item_barcode=${barcode}")
mmsid=$(echo $recinfo |xmlstarlet sel -t -m "item/bib_data/mms_id" -v . )
holdingid=$(echo $recinfo |xmlstarlet sel -t -m "item/holding_data/holding_id" -v . )
# Retrieve holdings record
url="https://api-na.hosted.exlibrisgroup.com/almaws/v1/bibs/${mmsid}/holdings/${holdingid}"
holdings=$(curl -s -X GET -L -H "Authorization: apikey $(cat apikey.txt)" "${url}")
# Edit location in holdings record
holdings=$(echo $holdings | xmlstarlet ed -u
'/holding/record/datafield[@tag="852"]/subfield[@code="c"]' -v 'oldstorbks')
# Replace holdings record
newloc=$(curl -s -H "Authorization: apikey $(cat apikey.txt)" -H "Content-Type: application/xml" -
X PUT --data "${holdings}" "${url}")
done
A lot of work in just a few lines!](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-32-320.jpg)

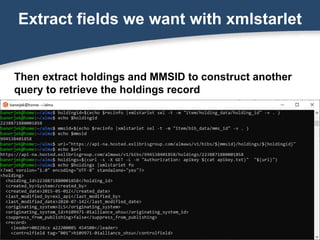
![Fix the XML
holdings=$(echo $holdings | xmlstarlet ed -u
'/holding/record/datafield[@tag="852"]/subfield[@code="c"]' -v 'oldstorbks')](https://image.slidesharecdn.com/banerjeegetting-started-with-the-alma-api-200731165158/85/Getting-Started-with-the-Alma-API-35-320.jpg)





The document provides an overview of using the Alma API for managing various library records, including user, item, and holdings modifications. It emphasizes the use of command-line tools like curl and xmlstarlet for interacting with the API and automation through scripting. Additionally, it offers guidance on getting started with command line usage and includes practical examples for extracting and updating records within Alma’s system.















![[drupalday2017] - REST in pieces](https://cdn.slidesharecdn.com/ss_thumbnails/paolo-pustorinorestinpieces-170306112824-170315150716-thumbnail.jpg?width=640&height=640&fit=bounds)







































