Download to read offline









![Regular expressions to the rescue!
● “Whenever a field ends in an HTML entity
minus the semicolon and is followed by an
identical field, join those into a single field and
fix the entity. Any line can begin with an
unknown number of tabs or spaces”
/^s*<([^>]+>)(.*)(&[a-z]+)</1ns*<1/<123;/](https://image.slidesharecdn.com/ala2015datanormalization-150622121102-lva1-app6891/85/Normalizing-Data-for-Migrations-9-320.jpg)


![Regular Expression Analysis
/^s*<([^>]+>)(.*)(&[a-z]+)</1ns*<1/<123;/
^ Beginning of line
s*< Zero or more whitespace characters followed by “<”
([^>]+>) One or more characters that are not “>” followed by “>” (i.e.
a tag). Store in 1
(.*) Any characters to next part of pattern. Store in 2
(&[a-z]+) Ampersand followed by letters (HTML entities). Store in 3
</1n “</ followed by 1 (i.e. the closing tag) followed by a newline
s*<1 Any number of whitespace characters followed by tag 1
/<123;/ Replace everything up to this point with “<” followed by 1
(opening tag), 2 (field contents), 3, and “;” (fix HTML
entity). This effectively joins the fields](https://image.slidesharecdn.com/ala2015datanormalization-150622121102-lva1-app6891/85/Normalizing-Data-for-Migrations-12-320.jpg)
![A simpler example
● Find a line that contains 1 to 5 fields in a
tab delimited file (because you expect 6)
^([^t]*t){0,4}[^t]*$
● To automatically join it with the next line with a
space
/^(([^t]*t){0,4}[^t]*)n/1 /
However, it would be much safer and easier to use
syntax that detects the first or last field](https://image.slidesharecdn.com/ala2015datanormalization-150622121102-lva1-app6891/85/Normalizing-Data-for-Migrations-13-320.jpg)

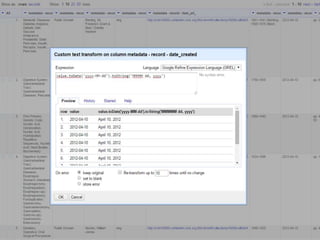



The document discusses best practices for normalizing data during migration processes, highlighting issues such as carriage returns, missing values, and complex data patterns. It recommends using tools like OpenRefine over Excel for data manipulation and emphasizes the importance of understanding differences between old and new systems, manual record examination, and regular expressions. Practical examples illustrate how to fix common data issues efficiently while noting that normalization is context-dependent and requires collaborative efforts with technical experts.





















![[Mas 500] Data Basics](https://cdn.slidesharecdn.com/ss_thumbnails/mas-500-4-data-basics-131120205428-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































