Download as PDF, PPTX







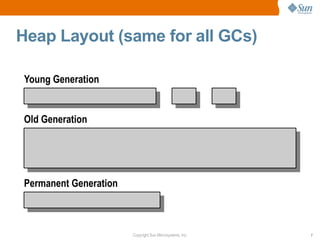














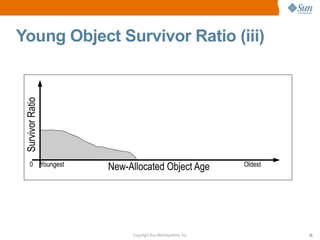






















![CMS Cycle Initiation Example
• This is good:
[ParNew 640710K->546360K(773376K), 0.1839508 secs]
[CMS-initial-mark 548460K(773376K), 0.0883685 secs]
[ParNew 651320K->556690K(773376K), 0.2052309 secs]
[CMS-concurrent-mark: 0.832/1.038 secs]
[CMS-concurrent-preclean: 0.146/0.151 secs]
[CMS-concurrent-abortable-preclean: 0.181/0.181 secs]
[CMS-remark 623877K(773376K), 0.0328863 secs]
[ParNew 655656K->561336K(773376K), 0.2088224 secs]
[ParNew 648882K->554390K(773376K), 0.2053158 secs]
...
[ParNew 489586K->395012K(773376K), 0.2050494 secs]
[ParNew 463096K->368901K(773376K), 0.2137257 secs]
[CMS-concurrent-sweep: 4.873/6.745 secs]
[CMS-concurrent-reset: 0.010/0.010 secs]
[ParNew 445124K->350518K(773376K), 0.1800791 secs]
[ParNew 455478K->361141K(773376K), 0.1849950 secs]
Copyright Sun Microsystems, Inc. 48](https://image.slidesharecdn.com/gctuningpresentationfisl10-100907105234-phpapp01/85/GC-Tuning-in-the-HotSpot-Java-VM-a-FISL-10-Presentation-48-320.jpg)
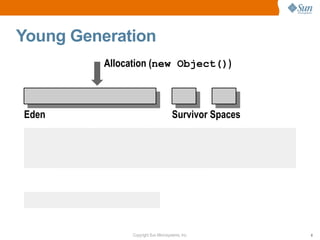
![CMS Cycle Initiation Example (ii)
• Cycle started too early:
[ParNew 390868K->296358K(773376K), 0.1882258 secs]
[CMS-initial-mark 298458K(773376K), 0.0847541 secs]
[ParNew 401318K->306863K(773376K), 0.1933159 secs]
[CMS-concurrent-mark: 0.787/0.981 secs]
[CMS-concurrent-preclean: 0.149/0.152 secs]
[CMS-concurrent-abortable-preclean: 0.105/0.183 secs]
[CMS-remark 374049K(773376K), 0.0353394 secs]
[ParNew 407285K->312829K(773376K), 0.1969370 secs]
[ParNew 405554K->311100K(773376K), 0.1922082 secs]
[ParNew 404913K->310361K(773376K), 0.1909849 secs]
[ParNew 406005K->311878K(773376K), 0.2012884 secs]
[CMS-concurrent-sweep: 2.179/2.963 secs]
[CMS-concurrent-reset: 0.010/0.010 secs]
[ParNew 387767K->292925K(773376K), 0.1843175 secs]
[CMS-initial-mark 295026K(773376K), 0.0865858 secs]
[ParNew 397885K->303822K(773376K), 0.1995878 secs]
Copyright Sun Microsystems, Inc. 49](https://image.slidesharecdn.com/gctuningpresentationfisl10-100907105234-phpapp01/85/GC-Tuning-in-the-HotSpot-Java-VM-a-FISL-10-Presentation-49-320.jpg)
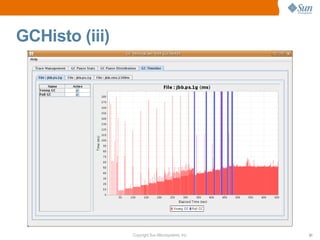
![CMS Cycle Initiation Example (iii)
• Cycle started too late:
[ParNew 742993K->648506K(773376K), 0.1688876 secs]
[ParNew 753466K->659042K(773376K), 0.1695921 secs]
[CMS-initial-mark 661142K(773376K), 0.0861029 secs]
[Full GC 645986K->234335K(655360K), 8.9112629 secs]
[ParNew 339295K->247490K(773376K), 0.0230993 secs]
[ParNew 352450K->259959K(773376K), 0.1933945 secs]
Copyright Sun Microsystems, Inc. 50](https://image.slidesharecdn.com/gctuningpresentationfisl10-100907105234-phpapp01/85/GC-Tuning-in-the-HotSpot-Java-VM-a-FISL-10-Presentation-50-320.jpg)






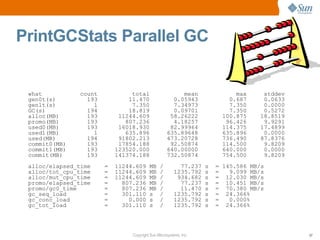
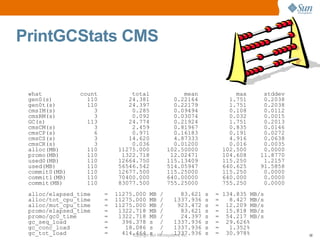

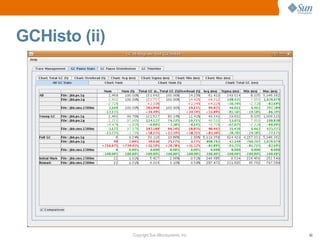




This document provides a summary of a presentation on garbage collection tuning in the Java HotSpot Virtual Machine. It introduces the presenters and their backgrounds in GC and Java performance. The main points covered are that GC tuning is an art that requires experience, and tuning advice is provided for the young generation, Parallel GC, and Concurrent Mark Sweep GC. Monitoring GC performance and avoiding fragmentation are also discussed.








































![[BGOUG] Java GC - Friend or Foe](https://cdn.slidesharecdn.com/ss_thumbnails/javagcfriendorfoe-101125015602-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































