
























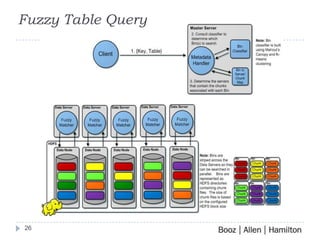
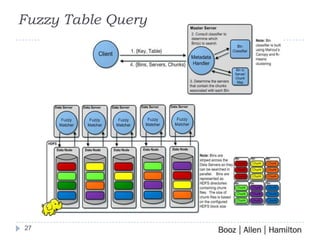





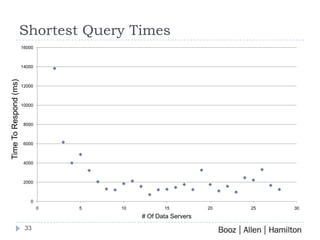











Fuzzy matching is a technique used to find similar items that are not exactly the same. It is used for applications like image search, biometrics, and audio/video search. The growth of multimedia and biometric databases has created a big data problem for fuzzy matching. A scalable solution presented uses Hadoop and MapReduce to process large amounts of data in parallel across clusters. It introduces a Fuzzy Table distributed database that uses clustering and low latency searching to enable fast fuzzy matching across petabytes of data. Performance testing showed the system can scale to handle large query volumes on large datasets.











































































































