Downloaded 16 times









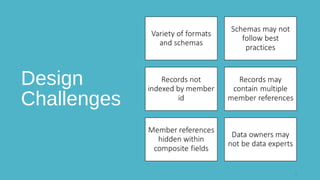








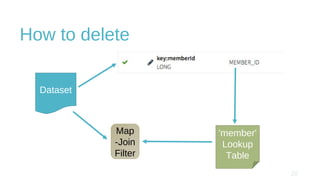



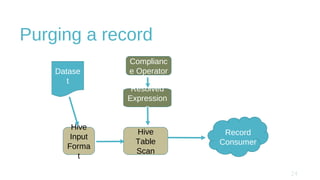
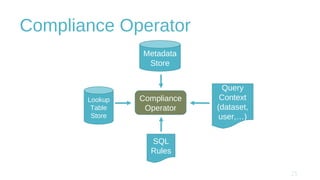
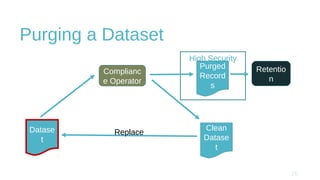


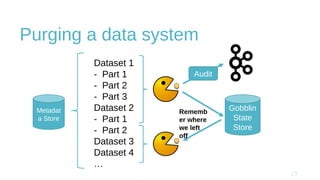



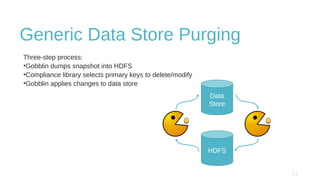

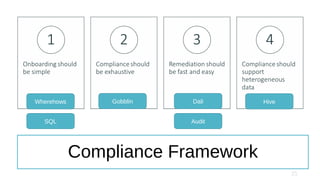




The document discusses design and implementation challenges faced by LinkedIn in building a data privacy system for handling large-scale data across multiple datasets. It highlights the need for compliance frameworks, effective data purging mechanisms, and the use of various technologies like Apache Gobblin and Hive. The emphasis is on ensuring data privacy while matching user needs and maintaining system efficiency in a complex infrastructure.






















































































