Download to read offline




![Probabilistic Latent Semantic Analysis (PLSA)
t1
t2
tj
tn
D1
D2
Di
DN
TK
Tk
T2
T1
P(T |D )
k i
P(t |T )
j k
Di: documents Tk: latent topics tj: terms
𝑃(𝑤 𝑧)
𝑃(𝑧 𝑑)
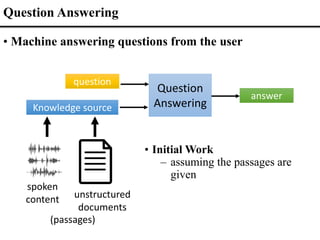
• Unsupervised Topic Analysis from text corpus
d: document z: topic w: word
[Hofmann 1999]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-6-320.jpg)
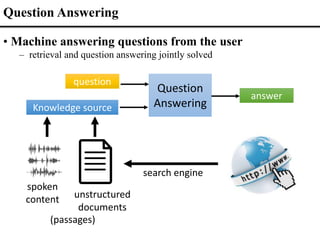
![Latent Dirichlet Allocation (LDA)
𝑃(𝜑𝑘 𝛽): Dirichlet Distribution
𝑃(𝜃 𝛼): Dirichlet Distribution
𝑃(𝑤𝑚,𝑛 𝑧𝑚,𝑛, 𝜑𝑘)
𝑃(𝑧𝑚,𝑛 𝜃𝑚)
[Blei 2003]
• Unsupervised Topic Analysis from text corpus](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-7-320.jpg)
![Clustering and Structuring the Spoken Content
Segments (Spoken Documents) Based on Topics
[Interspeech 2006]
• Global Semantic Structuring
• Local Semantic Structuring
Chinese Broadcast
News Archive
Semantic Analysis
Global Semantic
Structuring
Query-based
Local Semantic
Structuring
Automatic
Generation of
Key terms, Titles
and Summaries
Information
Retrieval
User’s query
– fine local structure
around the user
query on top of the
global structure](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-8-320.jpg)
![• Example Approach : Spoken Documents categorized by
Layered Topics and organized in a Two-dimensional Tree
– topics nearby on the map are more related semantically
– each topic expanded into another map in the next layer
Global Semantic Structure of Spoken Content
[Eurospeech 2005]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-9-320.jpg)
![• Broadcast News Browser (2006)
– each topic labeled by a set of key terms
An Example Screenshot of Global Semantic Structure
in a Two-dimensional Tree
[Interspeech 2006]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-10-320.jpg)
![Clustering and Structuring the Segments of Spoken
Content (Spoken Documents) Based on Topics
[Interspeech 2006]
• Global Semantic Structuring
• Local Semantic Structuring
Chinese Broadcast
News Archive
Semantic Analysis
Global Semantic
Structuring
Query-based
Local Semantic
Structuring
Automatic
Generation of
Key terms, Titles
and Summaries
Information
Retrieval
User’s query
– fine local structure
around the user
query on top of the
global structure](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-11-320.jpg)
![• Fine structure based on a user query
• Example Approach : Topic Hierarchy constructed with
key terms (Example Query: George Bush)
Local Semantic Structure of Spoken Content
[Interspeech 2006]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-12-320.jpg)
![An Example Screenshot of Local Semantic Structure
in a Topic Hierarchy
[Interspeech 2006]
• Query: “White House of United States”
– some key terms under another key term on a higher level](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-13-320.jpg)
![• Spoken Knowledge in courses: in sequential form
– an individual user may need only a small part
– not understandable without listening to previous lectures
• Example Approach: Key Term Graph (2009)
– each spoken slide labeled by a set of key terms (topics)
– relationships between key terms represented by a graph
Online Courses : A Well Organized Spoken Knowledge
Treasury
[ICASSP 2009][IEEE Trans ASL 2014]
spoken slides
(plus audio/video)
key term
graph
Acoustic
Modeling
Viterbi
search
HMM
Language
Modeling
Perplexity
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-14-320.jpg)
![• Temporal Structure
– chapters, sections, slides
Interconnection between Temporal and Semantic
Structures
[IEEE Trans ASL 2014]
• Semantic Structure
– key term graph
• Interconnection between the Two Structures](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-15-320.jpg)
![An Example Automatically Generated Key Term
Graph
[IEEE Trans ASL 2014]
• Relationship scores evaluated between each pair of key
terms
– an edge if exceeding a threshold](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-16-320.jpg)
![• User clicks a key term “entropy”
– possible learning path through the selected spoken slides
– related key terms via the key term graph
[ICASSP 2009][IEEE Trans ASL 2014]
An Example Screenshot from a Online Course
Browser](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-17-320.jpg)
![Spoken Knowledge Structuring for an Example Online
Course
• Based on a course recorded in 2006
[ICASSP 2009] [IEEE Trans ASL 2014]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-18-320.jpg)
![Thousands of Online Courses over the Internet
Lectures with very
similar content
[Interspeech 2015]
• Machines listen to all online courses
three courses on some
similar topic](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-19-320.jpg)
![sequential order for
learning (prerequisite
conditions)
three courses on some
similar topic
[Interspeech 2015]
Thousands of Online Courses over the Internet
• Machines listen to all online courses
• Learning map for a given query
• More precise semantic analysis for speech needed](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-20-320.jpg)

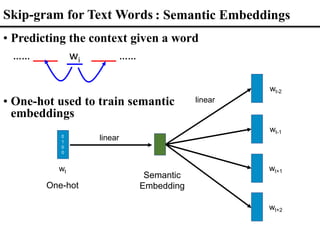
![…… ____ wi ____ ……
Word Embeddings (Word2Vec) as Vector
Representations for Words
• Continuous bag of words (CBOW)
…… wi-1 ____ wi+1 …… Neural
Network
wi
wi-1
wi+1
Neural
Network
wi-1
wi
wi+1
predicting the word given its context
predicting the context given a word
[Mikolov 2013]
• Skip-gram
• Prediction based on some hidden structure within the
language](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-22-320.jpg)
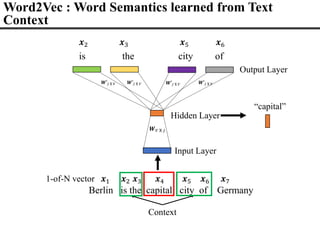
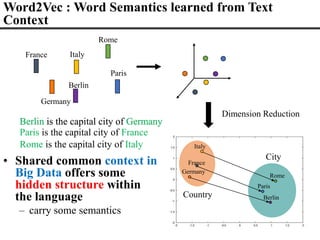
![V(Berlin) – V(Germany) + V(France) V(Paris)
Word Embeddings (Word2Vec)
Berlin
Germany
France
Paris
• Carry some Semantic Structure among Words
– semantic relationship is kind of “additive” or “parellel”
[Mikolov 2013]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-23-320.jpg)
![RNN Decoder
x1 x2 x3 x4
y1 y2 y3 y4
x1 x2 x3
x4
RNN Encoder
audio segment (a segmented spoken word)
acoustic features
• RNN encoder and
decoder
– learn some hidden structure
within signals
Input acoustic features
Audio Word2Vec : Sequence-to-sequence Autoencoder
[Interspeech 2016]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-26-320.jpg)
![x1 x2 x3 x4
RNN Encoder
audio segment (a segmented spoken word)
acoustic features
• RNN encoder and
decoder
– learn some hidden structure
within signals
Audio Word2Vec : Sequence-to-sequence Autoencoder
[Interspeech 2016]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-27-320.jpg)
![x1 x2 x3 x4
RNN Encoder
audio segment (a segmented spoken word)
acoustic features
• RNN encoder and
decoder
– learn some hidden structure
within signals
Audio Word2Vec : Sequence-to-sequence Autoencoder
[Interspeech 2016]
vector
The vector representation
• Unsupervised
• Self-supervised
– model learns from data itself](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-28-320.jpg)
![What was learned ?
[Interspeech 2016]
• Sequential Phonetic
structure !
– not semantics
– learned hidden structure
within speech signals is
from isolated segmented
spoken words only
– learning semantics from
context of word sequences
may be easier
new
fear
fame
name
few
new
near
night
fight
hands
hand
words
word
things
thing
days
says
day
say](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-29-320.jpg)
![e1
S
DR
𝑥1
DR
𝑥2
DR
𝑥3
…
DR
𝑥4
DR
𝑥𝑡
…
DR
𝑥𝑡+1
DR
𝑥𝑇
0
Segmental Audio Word2Vec — extended to an utterance
ER
…
en
xt
S
…
ER
xt+1
0
S …
ER
…
eN
xT
S
ER
x1
ER
x2
0
S
ER
x4
0
S
x3
ER
S
word
boundary
Segmentation Gate
Reset to
initial state
Segment 1 Segment 2 Segment n Segment N
Each color block performs seq2seq training individually [Interspeech 2018]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-30-320.jpg)
![Encoder Decoder
input audio reconstructed
Encoder
1
Decoder
reconstructed
speaker vector
phonetic vector
Encoder
2
Feature Disentanglement for Audio Word2Vec
[SLT 2018]
• Audio Signals includes information irrelevant to
semantics
– Speaker and other acoustic information](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-31-320.jpg)
![speaker 1
Phonetic
Encoder
Decoder
Speaker
Encoder
similar speaker vectors for the same
speaker
speaker 1
Phonetic
Encoder
Decoder
Speaker
Encoder
Disentanglement of Speaker Information
[SLT 2018]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-32-320.jpg)
![Disentanglement of Speaker Information
speaker vectors far apart enough for
different speakers
speaker 1
Phonetic
Encoder
Decoder
Speaker
Encoder
speaker 2
Phonetic
Encoder
Decoder
Speaker
Encoder
[SLT 2018]
• Phonetic Vectors without Speaker Information](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-33-320.jpg)
![Phonetic-and-Semantic
Embedding
phonetic vectors
2 hidden layer
2 hidden layer
wt
wt-2
wt-1
wt+1
wt+2
Phonetic
Encoder
wt-1 wt wt+1
[SLT 2018]
Audio Skip-gram
• Predicting the context given an audio segment
• Phonetic Vectors used
Phonetic Vectors
: Phonetic-and-semantic Embeddings](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-35-320.jpg)
![Phonetic-and-Semantic Embedding
Brother
Sister
Bother
Brother
Bother
Sister
• Two types of information sometimes disturb each other
– aligning the word embeddings in the two spaces is challenging
• A unique ID for a text word in training
– unlimited number of audio realizations for a given text word
• Phonetic Space • Semantic Space
[SLT 2018]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-36-320.jpg)
![BERT (Bidirectional Encoder Representations from
Transformers)
• Some hidden structure within the language learned in an
unsupervised way
– by estimating masked token from unlabeled text data
– the representations carry the context information
[Devlin 2018]
• Useful in many different downstream tasks achievable with
much simpler models, smaller labeled datasets and faster
convergence
A B C D E
BERT
R
R
R R R
How are [M]
toda
y
?
[M] = you
Representatio
ns
Transform
er
Encoders
“you”masked
Estimating the
masked token
: Pre-training
:Downstream
• Self-supervised
learning: learns some
hidden structure
within the language
from the dataset itself
without labels](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-37-320.jpg)
![A B C D E
BERT
R
R
R R R
Unlabeled text
data
unsupervised
Pre-training
BERT
[CLS] w1 w2 w3
Linear
Cls
class
sentence
Linear
Cls
class
Linear
Cls
class
arrive Taipei on November 2nd
other dest other time time
Input
output
• Example downstream task (1): slot filling
• Semantics considered
Self-supervised Learning for Text : BERT
• Classifiers may have simpler models trained with smaller
labeled datasets](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-38-320.jpg)
![BERT
It’s a nice day
[CLS]
unlabeled text data
positive negative
Downstream Model
Positive
Self-supervised Learning for Text : BERT
• Example downstream task (2): sentiment classification
• Semantics considered
• Simpler models trained with smaller labeled datasets](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-39-320.jpg)
![Pre-trained Model
Unlabeled Data
Phase 1: Pre-training
representations
• Mask the input signals and then
reconstruct them (generative)
• Predictive
• Contrastive
Self-supervised Learning for Speech
• To learn the hidden structure within speech signals without
considering any specific downstream task [IEEE JSTSP 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-40-320.jpg)
![Pre-trained Model
Phase 2: Downstream
For a given downstream
task (e.g., ASR) Downstream Model
“How are you?”
Labelled data
Self-supervised Learning for Speech
• With the hidden structure learned from the signals, the given
task becomes easier [IEEE JSTSP 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-41-320.jpg)
![Masked
Frames
Mockingjay
Mockingjay
[ICASSP 2020]
• Speech version of BERT
(text token → signal frame)
– frame level
– no segmentation problem
any more (same as ASR)
Mel-spectrogram](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-42-320.jpg)
![Repr.
Masked
Frames
Mockingjay
[ICASSP 2020]
Mockingjay
Mel-spectrogram
• Speech version of BERT
(text token → signal frame)
– frame level
– no segmentation problem
any more (same as ASR)](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-43-320.jpg)
![Pred
Real
Repr.
The model was able to
reconstruct spectrogram form
hidden representations
Masked
Frames
Mockingjay
[ICASSP 2020]
Mockingjay
Mel-spectrogram](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-44-320.jpg)
![[IEEE JSTSP 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-45-320.jpg)
![More data
Larger model
Word-level Frame-level
More
objectives
[IEEE JSTSP 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-46-320.jpg)
![Presented at INTERSPEECH 2021
https://arxiv.org/abs/2105.01051
Presented at ACL 2022
https://arxiv.org/abs/2203.06849
[Interspeech 2021] [ACL 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-47-320.jpg)
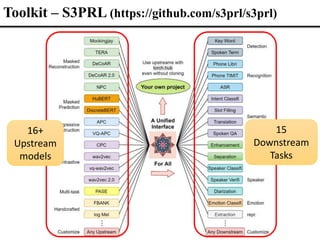
![https://superbbenchmark.org/
IS 2021
ACL 2022
Phonetic Paralinguistic
Speaker Semantic Synthesis
Speech processing Universal PERformance
Benchmark (SUPERB)
[Interspeech 2021] [ACL 2022]
• Five categories of downstream tasks: phonetic, speaker,
paralinguistic, semantic, and synthesis](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-48-320.jpg)
![PR KS ASR QbE SID ASV SD IC SF ER
fbank 82.01 8.63 15.21 0.0058 8.50E-04 9.56 10.05 9.1 69.64 35.39
PASE+ 58.87 82.54 16.62 0.0072 37.99 11.61 8.68 29.82 62.14 57.86
APC 41.98 91.01 14.74 0.0310 60.42 8.56 10.53 74.69 70.46 59.33
VQ-APC 41.08 91.11 15.21 0.0251 60.15 8.72 10.45 74.48 68.53 59.66
NPC 43.81 88.96 13.91 0.0246 55.92 9.40 9.34 69.44 72.79 59.08
Mockingjay 70.19 83.67 15.48 6.60E-04 32.29 11.66 10.54 34.33 61.59 50.28
TERA 49.17 89.48 12.16 0.0013 57.57 15.89 9.96 58.42 67.50 56.27
DeCoAR 2.0 14.93 94.48 9.07 0.0406 74.42 7.16 6.59 90.80 83.28 62.47
modified CPC 42.54 91.88 13.53 0.0326 39.63 12.86 10.38 64.09 71.19 60.96
wav2vec 31.58 95.59 11.00 0.0485 56.56 7.99 9.90 84.92 76.37 59.79
vq-wav2vec 33.48 93.38 12.80 0.0410 38.80 10.38 9.93 85.68 77.68 58.24
wav2vec 2.0 base 5.74 96.23 4.79 0.0233 75.18 6.02 6.08 92.35 88.30 63.43
wav2vec 2.0 large 4.75 96.66 3.10 0.0489 86.14 5.65 5.62 95.28 87.11 65.64
HuBERT base 5.41 96.30 4.79 0.0736 81.42 5.11 5.88 98.34 88.53 64.92
HuBERT large 3.53 95.29 2.94 0.0353 90.33 5.98 5.75 98.76 89.81 67.62
Phonetic Semantic
Speaker Emotion
Initial Test Results of Round 2
[Interspeech 2021]
• fbank as the baseline](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-49-320.jpg)
![PR KS ASR QbE SID ASV SD IC SF ER
fbank 82.01 8.63 15.21 0.0058 8.50E-04 9.56 10.05 9.1 69.64 35.39
PASE+ 58.87 82.54 16.62 0.0072 37.99 11.61 8.68 29.82 62.14 57.86
APC 41.98 91.01 14.74 0.0310 60.42 8.56 10.53 74.69 70.46 59.33
VQ-APC 41.08 91.11 15.21 0.0251 60.15 8.72 10.45 74.48 68.53 59.66
NPC 43.81 88.96 13.91 0.0246 55.92 9.40 9.34 69.44 72.79 59.08
Mockingjay 70.19 83.67 15.48 6.60E-04 32.29 11.66 10.54 34.33 61.59 50.28
TERA 49.17 89.48 12.16 0.0013 57.57 15.89 9.96 58.42 67.50 56.27
DeCoAR 2.0 14.93 94.48 9.07 0.0406 74.42 7.16 6.59 90.80 83.28 62.47
modified CPC 42.54 91.88 13.53 0.0326 39.63 12.86 10.38 64.09 71.19 60.96
wav2vec 31.58 95.59 11.00 0.0485 56.56 7.99 9.90 84.92 76.37 59.79
vq-wav2vec 33.48 93.38 12.80 0.0410 38.80 10.38 9.93 85.68 77.68 58.24
wav2vec 2.0 base 5.74 96.23 4.79 0.0233 75.18 6.02 6.08 92.35 88.30 63.43
wav2vec 2.0 large 4.75 96.66 3.10 0.0489 86.14 5.65 5.62 95.28 87.11 65.64
HuBERT base 5.41 96.30 4.79 0.0736 81.42 5.11 5.88 98.34 88.53 64.92
HuBERT large 3.53 95.29 2.94 0.0353 90.33 5.98 5.75 98.76 89.81 67.62
Phonetic Semantic
Speaker Emotion
• Self-supervised representations outperformed fbank in most
cases
Initial Test Results of Round 2
[Interspeech 2021]
• Black blocks: worse than fbank baseline](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-50-320.jpg)
![PR KS ASR QbE SID ASV SD IC SF ER
fbank 82.01 8.63 15.21 0.0058 8.50E-04 9.56 10.05 9.1 69.64 35.39
PASE+ 58.87 82.54 16.62 0.0072 37.99 11.61 8.68 29.82 62.14 57.86
APC 41.98 91.01 14.74 0.0310 60.42 8.56 10.53 74.69 70.46 59.33
VQ-APC 41.08 91.11 15.21 0.0251 60.15 8.72 10.45 74.48 68.53 59.66
NPC 43.81 88.96 13.91 0.0246 55.92 9.40 9.34 69.44 72.79 59.08
Mockingjay 70.19 83.67 15.48 6.60E-04 32.29 11.66 10.54 34.33 61.59 50.28
TERA 49.17 89.48 12.16 0.0013 57.57 15.89 9.96 58.42 67.50 56.27
DeCoAR 2.0 14.93 94.48 9.07 0.0406 74.42 7.16 6.59 90.80 83.28 62.47
modified CPC 42.54 91.88 13.53 0.0326 39.63 12.86 10.38 64.09 71.19 60.96
wav2vec 31.58 95.59 11.00 0.0485 56.56 7.99 9.90 84.92 76.37 59.79
vq-wav2vec 33.48 93.38 12.80 0.0410 38.80 10.38 9.93 85.68 77.68 58.24
wav2vec 2.0 base 5.74 96.23 4.79 0.0233 75.18 6.02 6.08 92.35 88.30 63.43
wav2vec 2.0 large 4.75 96.66 3.10 0.0489 86.14 5.65 5.62 95.28 87.11 65.64
HuBERT base 5.41 96.30 4.79 0.0736 81.42 5.11 5.88 98.34 88.53 64.92
HuBERT large 3.53 95.29 2.94 0.0353 90.33 5.98 5.75 98.76 89.81 67.62
Phonetic Semantic
Speaker Emotion
• Several self-supervised models are all-around
– good hidden structure generalizable to all tasks
Initial Test Results of Round 2
[Interspeech 2021]
• Any one good in all tasks?](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-51-320.jpg)
![WER
100 hours
labeled data
10 minutes
labeled data
6-layer LSTM
2-layer LSTM
• LibriSpeech
(Lüscher, et al.) (Yang, et al.)
(Yang, et al.) (Baevski, et al.) (Hsu, et al.)
Supervised vs. Self-supervised: ASR
[Lüscher 2019] [Baevski 2020] [Hsu 2021] [Interspeech 2021]
5.8
2.9
3.1
4.8
4.6](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-52-320.jpg)

![…
…
Audio word2vec
𝑋1
𝑋2 𝑋3
𝑋𝑀
𝑧1 𝑧2 𝑧3 𝑧𝑀
…
Acoustic Feature
Audio embedding sequence
Model 1 (2018)
• Waveform segmentation and embedding
– divide the features into acoustically similar segments of different lengths
– transform each segment into a fixed-length vector (audio embedding)
[Interspeech 2018]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-58-320.jpg)
![Cluster index 16
Cluster index 25
Cluster index 1
…
Audio embedding sequence
2 …
16 25 2
𝑧1 𝑧2 𝑧3 𝑧𝑀
Cluster index sequence
K-means
…
Cluster index 2
Model 1 (2018)
• Cluster the embeddings into groups
[Interspeech 2018]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-59-320.jpg)
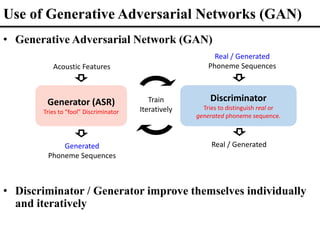
![Generator
Lookup Table
Real phoneme sequence
Real / Generated
Discriminator
CNN network
2 … 2
Cluster index sequence
16 25
Model 1 (2018)
• Learning the mapping between cluster indices and
phonemes with a GAN
– embedding clustering followed by (cascaded with) a GAN
[Interspeech 2018]
𝑠𝑖𝑙 …
ℎℎ 𝑖ℎ 𝒔𝒊𝒍
Generated phoneme sequence](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-60-320.jpg)
![• Generator consists of two
parts
(a) Phoneme Classifier (DNN)
(b) Sampling Process
• Discriminator is a two layer 1-D
CNN.
Data (Text)
Data
(Audio)
Model 2 (2019)
• A GAN (Generator and Discriminator) trained
End-to-end
– DNN trained in an unsupervised way
[Interspeech 2019]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-61-320.jpg)
![Accuracy
Unsupervised learning (Model 2, 2019) is as
good as supervised learning (HMM) 30 years
ago.
The Progress of Supervised Learning on TIMIT
• Milestones in phone recognition accuracy
[Phone recognition on the TIMIT database, Lopes, C. and Perdigão, F., 2011. Speech
Technologies, Vol 1, pp. 285--302.]
– Will it take another 30 years for unsupervised learning to achieve the
performance of supervised learning today ?
[Keynote, Interspeech 2020]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-62-320.jpg)
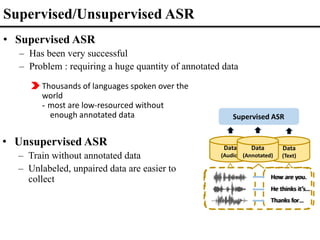
![Unsupervised Speech Recognition
• Librispeech (2021)
https://ai.facebook.com/blog/wav2vec-unsupervised-speech-recognition-without-supervision/
– Word Error Rate as low as 5.9% with zero hr of annotated
data !
[facebook 2021]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-63-320.jpg)
![Unsupervised Speech Recognition
SwitchBoard
(Telephone conversation)
TED-LIUM
(Live talk)
Librispeech
(Read literature)
LibriLM
(Literature)
Wiki
(Encyclopedia)
NewsCrawl
(News)
ImageC
(Image Caption)
[ICASSP 2022]
• Audio/Text unlabeled corpora respectively extended to
different styles/domains](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-64-320.jpg)
![Unsupervised Speech Recognition
[ICASSP 2022]
• Reasonable (relatively high) Error Rate achievable if
– good acoustics conditions (Libri) with reasonably
different linguistic styles
– relatively poor acoustic conditions (SB) but with same
linguistic styles
– will be lowered sooner or later…
4gram JSD
PER
Libri960
SB300_w2v2](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-65-320.jpg)

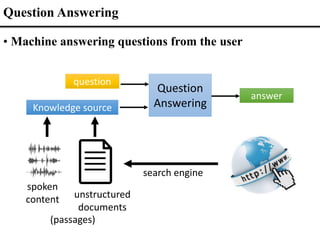
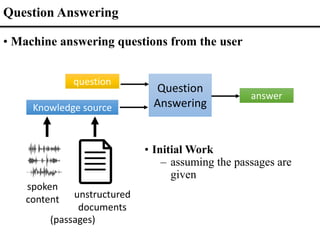
![Speech
Recognition
(ASR)
Question
Answering
Answer
Question
Question
Answering
Answer
Question
Spoken Content
Retrieved
Text
Retrieved
Text v.s. Spoken QA (Cascading v.s. End-to-end)
• Text QA
End-to-end Spoken
Question Answering
Answer
Question [Interspeech 2020]
Cascading
End-to-end
• Spoken QA
Errors](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-70-320.jpg)
![End-to-end Spoken QA : DUAL
• Pre-trained with unlabled audio/text corpora
– audio represented in HuBERT units (frame level)
– fine-tuned in downstream by (question, passage, answer) sets
• Not limited by ASR Errors or OOV
– no ASR here [Interspeech 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-71-320.jpg)
![End-to-end Spoken QA: DUAL
• HuBERT-based speech encoder
• BERT pre-trained on text
[Interspeech 2022]
question passage
Pre-trained Speech Encoder
3
9 11 31 31
clustered
units
start
Find Ans Span
BERT (pre-trained on text)
end](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-72-320.jpg)
![End-to-end Spoken QA: DUAL
• ASR cascaded with Text QA: Baseline
– performance directly limited by WER (many errors due to OOV)
• End-to-end Spoken QA (DUAL)
– performance independent of WER, because semantics extracted from
audio
• No ASR here
– many answer spans include OOV
ASR + Text QA
End-to-end DUAL
[Interspeech 2022]
Word Error Rate (WER)
Frame-level
F1
score
(FF1)](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-73-320.jpg)
![Textless Spoken QA with Speech Discrete Units: TlDu
• Audio represented in HuBERT units
• Retrieving relevant passages and identifying answers joinyly
handled
[submitted to SLT 2022]
• No ASR transcriptions or errors
Spoken Archive
Spoken Question
(a)
Speech
Signal
Encoder
Discrete
unit
sequences
(b)
Spoken
Content
Retriever
(c)
Spoken
Content
Reader
Top-K
passages
Answer
span](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-76-320.jpg)
![Preliminary Results for TlDu
• Retrieval Accuracy • SQA: Accury
• Performance not limited by ASR errors or OOV
– No ASR here
– semantics extracted directly from audio (not words)
[submitted to SLT 2022]](https://image.slidesharecdn.com/fromsemanticstoself-supervisedlearningforspeechandbeyondp16-102-230713123834-a37aaa9f/85/From-Semantics-to-Self-supervised-Learning-for-Speech-and-Beyond-Opening-Keynote-Interspeech-2022-77-320.jpg)



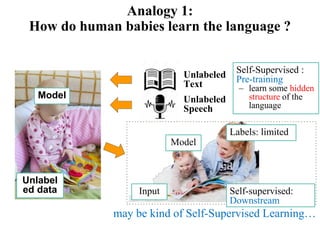





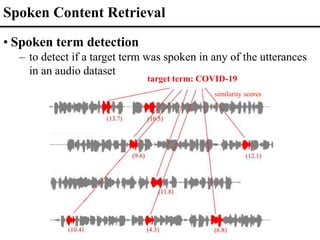
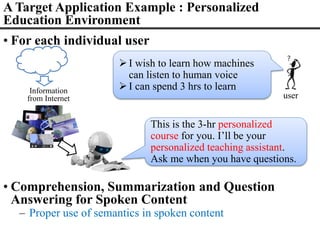
The document discusses advancements in spoken content retrieval and self-supervised learning techniques for audio and speech processing. It highlights the potential to use machines for personalized education by leveraging vast multimedia knowledge, as well as summarization and analysis of spoken documents via various semantic structuring methods. The document also touches on models like word2vec and BERT, demonstrating their role in improving language understanding and context learning without extensive labels.



![[PR12] categorical reparameterization with gumbel softmax](https://cdn.slidesharecdn.com/ss_thumbnails/pr12categoricalreparameterizationwithgumbel-softmax-180304131005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]representation learning via invariant causal mechanisms](https://cdn.slidesharecdn.com/ss_thumbnails/2021910representationlearningviainvariantcausalmechanisms-210910032836-thumbnail.jpg?width=640&height=640&fit=bounds)






































































