Presented By
G.RAJASEKARAN
Frequent ItemSet Extraction Using
Generalized Item Set Mining Algorithms
PONDICHERRY ENGINEERING COLLEGE
(Promoted and fully funded by Govt. of Puducherry, Affiliated to Pondicherry University)
Department of Computer Science and Engineering
Research Proposal Presentation
3.
A promisingapproach to Bayesian classification is based on exploiting
frequent patterns, i.e., patterns that frequently occur in the training data
set, to estimate the Bayesian probability. Entropy-based Bayesian
classifier, namely EnBay. This work will address the domain of noisy
data, for which the reliability of the probability estimate becomes
particularly relevant, and the integration of generalized item set mining
algorithms to further enhance classification accuracy.
This proposal is to extended to use Boosting method to give more
accuracy than the previous approach.
Objective
4.
GenIO (GeNeralized ItemsetDiscOverer) to support data analysis by
automatically extracting higher level, more abstract correlations
from data. GenIO extends the concept of multi-level itemsets (Han
and Kamber, 2006) by performing an opportunistic extraction of
generalized itemsets.
GenIO is implemented by customizing the Apriori algorithm (Agrawal
and Srikant, 1994) to efficiently extract generalized itemsets, with
variable support thresholds, from structured data.
Literature Survey
5.
A promising approachto Bayesian classification is based on exploiting
frequent patterns, i.e., patterns that frequently occur in the training data set, to
estimate the Bayesian probability. Entropy-based Bayesian classifier, namely
EnBay used. This work will address the domain of noisy data, for which the
reliability of the probability estimate becomes particularly relevant, and the
integration of generalized item set mining algorithms to further enhance
classification accuracy.
Problem Statement
6.
Classification:
predicts categorical classlabels
classifies data (constructs a model) based on the training set and the
values (class labels) in a classifying attribute and uses it in classifying
new data
Typical Applications
credit approval
target marketing
medical diagnosis
treatment effectiveness analysis
Large data sets: disk-resident rather than memory-resident data
Introduction
7.
Model construction: describinga set of predetermined classes
Each tuple is assumed to belong to a predefined class, as determined
by the class label attribute (supervised learning)
The set of tuples used for model construction: training set
Model usage: for classifying previously unseen objects
Estimate accuracy of the model using a test set
The known label of test sample is compared with the classified result
from the model
Accuracy rate is the percentage of test set samples that are correctly
classified by the model
Test set is independent of training set, otherwise over-fitting will occur
Classification - A Two – Step Process
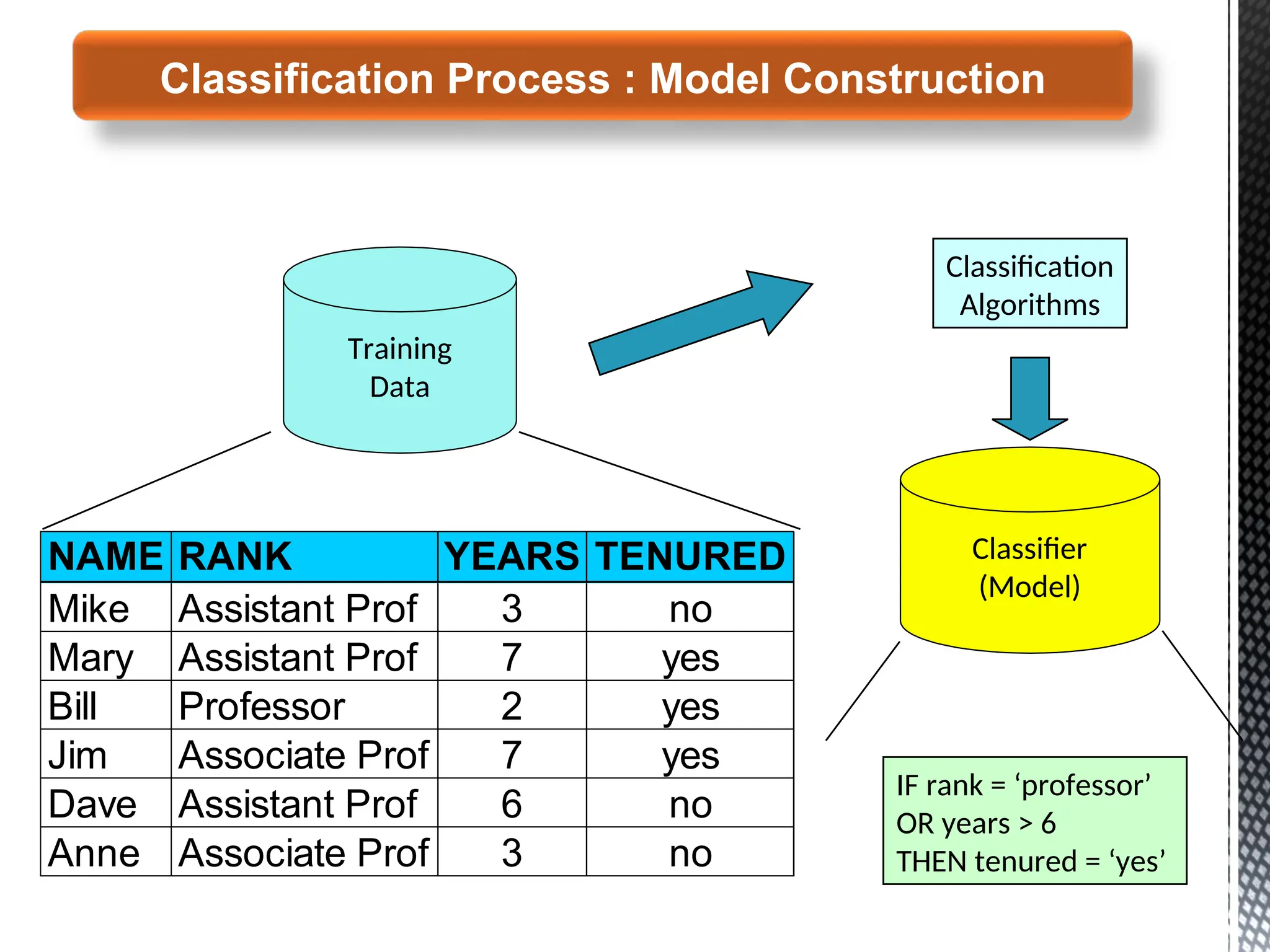
8.
Training
Data
NAME RANK YEARSTENURED
Mike Assistant Prof 3 no
Mary Assistant Prof 7 yes
Bill Professor 2 yes
Jim Associate Prof 7 yes
Dave Assistant Prof 6 no
Anne Associate Prof 3 no
Classification
Algorithms
IF rank = ‘professor’
OR years > 6
THEN tenured = ‘yes’
Classifier
(Model)
Classification Process : Model Construction
9.
Entropy Based BayesianClassification
Boosting Method
Product Approximation
Proposed Methodology
10.
Agrawal, R.,Imielinski, T., and Swami, A. (1993). Mining association rules between
sets of items in large databases. ACM SIGMOD Record, 22(2):207–216.
Agrawal, R. and Srikant, R. (1994). Fast algorithm for mining association rules. In
VLDB’94, Santiago, Chile.
Agrawal, R. and Srikant, R. (1997). Mining generalized association rules. FGCS.
Future generations computer systems, 13(23):161–180.
Antonie, M. L., Zaiane, O. R., and Coman, A. (2001). Application of data mining
techniqeus for medical image classification. In MDM/KDD 2001.
Han, J. and Fu, Y. (1995). Discovery of multiple-level association rules from large
databases. Proceedings of the 21th International Conference on Very Large Data
Bases, pages 420–431
•References