Downloaded 53 times


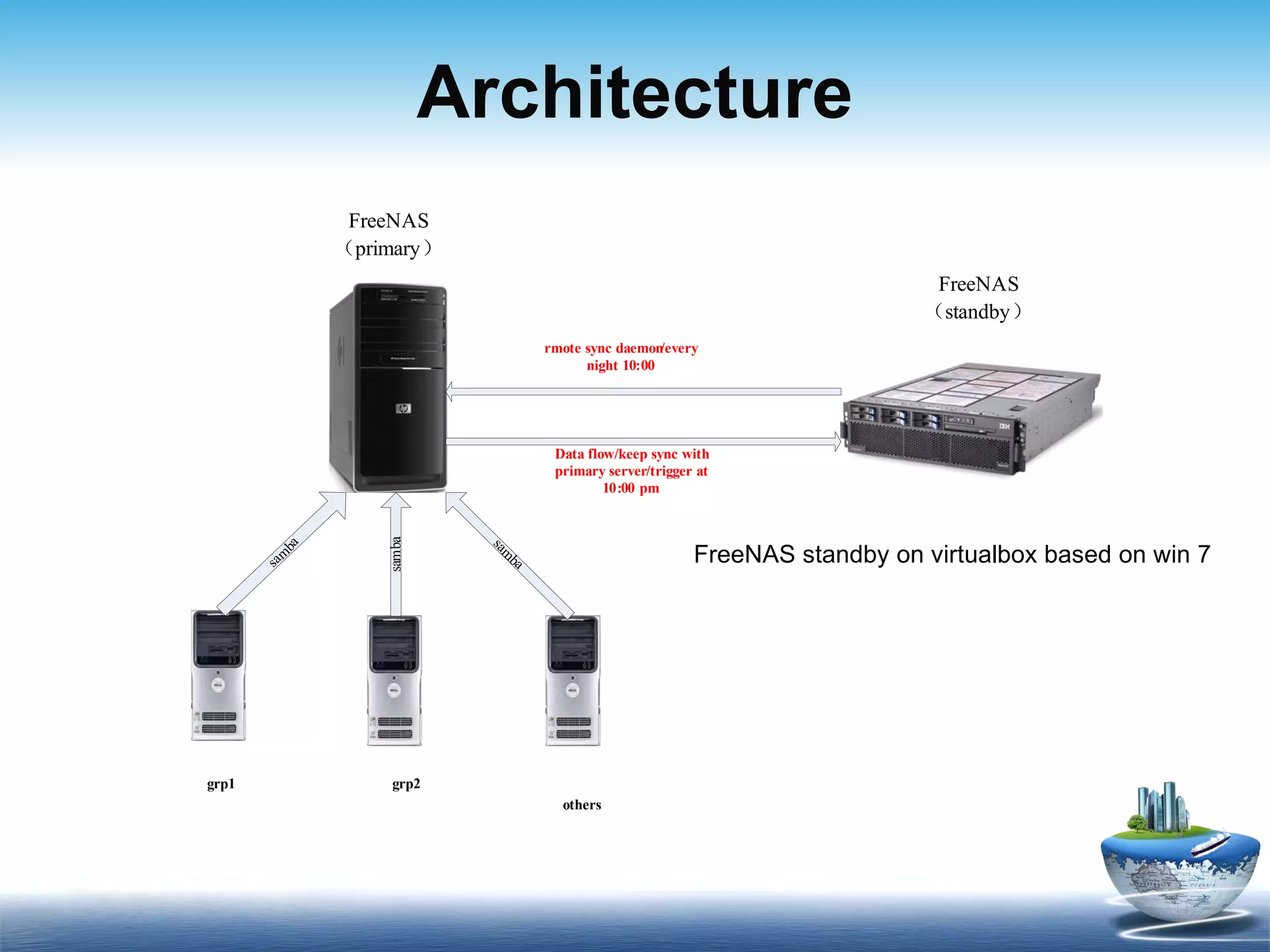







The document discusses FreeNAS, an open-source Network Attached Storage server based on FreeBSD, and describes its benefits including being free, secure, low-cost, and stable. It then provides information about the current primary and backup servers being used, noting issues with the backup server having insufficient storage space. A proposed solution is to replace the old backup server with a desktop PC that has a larger disk to better meet storage needs over the next 5 years.
















































































