Download as PDF, PPTX



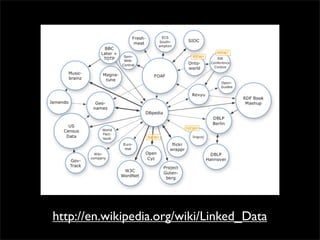












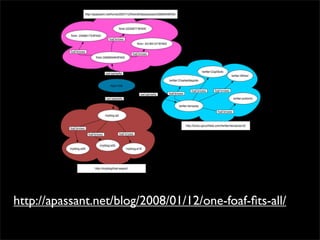



This document discusses the Friend of a Friend (FOAF) framework for social network portability, highlighting the importance of rich data integration across various platforms using RDF. It details components for identifying individuals and describing social networks, and presents a workflow for comparing FOAF data between different sites. The talk also raises questions about data ownership and privacy in the context of social network information sharing.

























































































