Download as PDF, PPTX



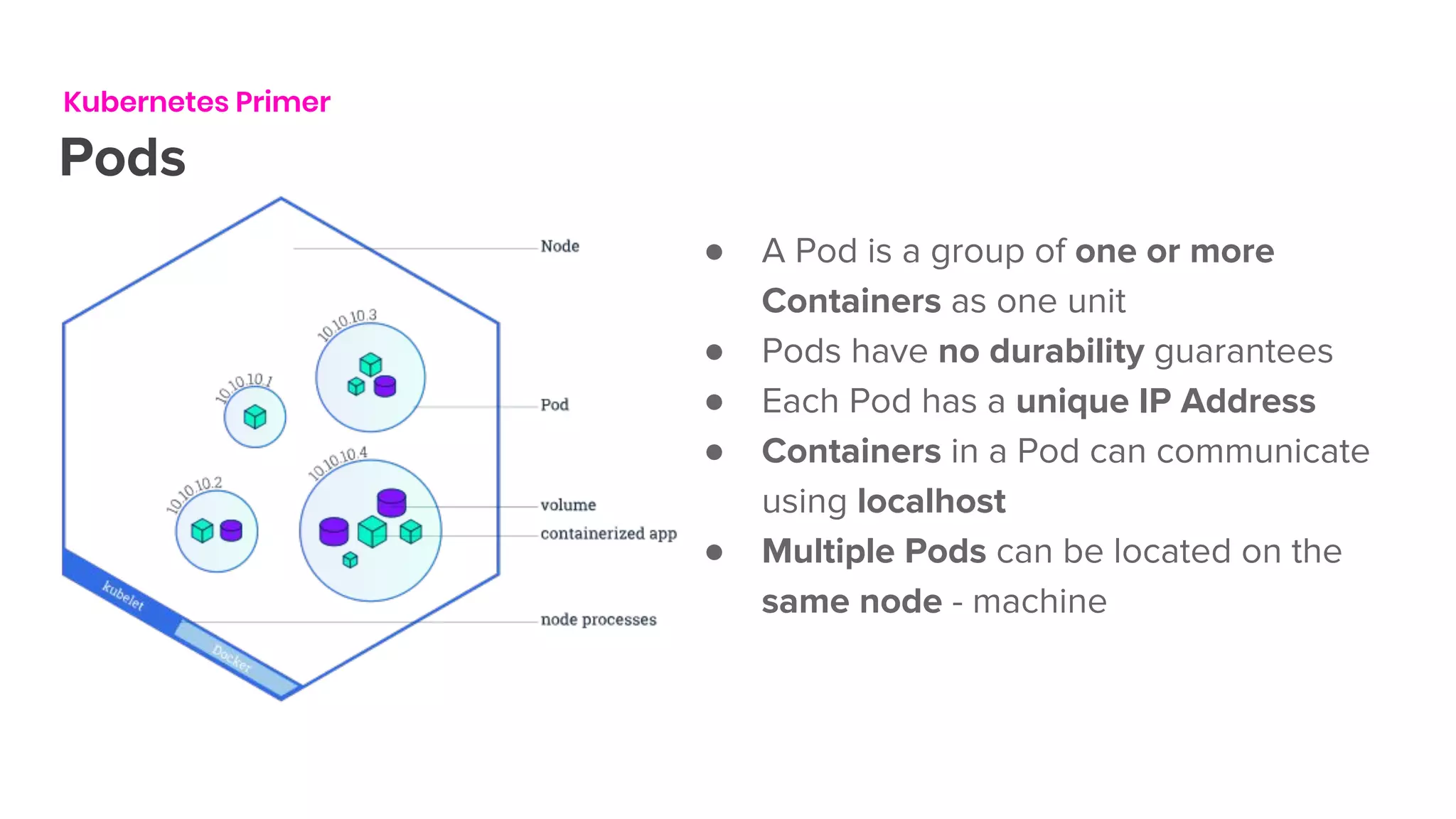

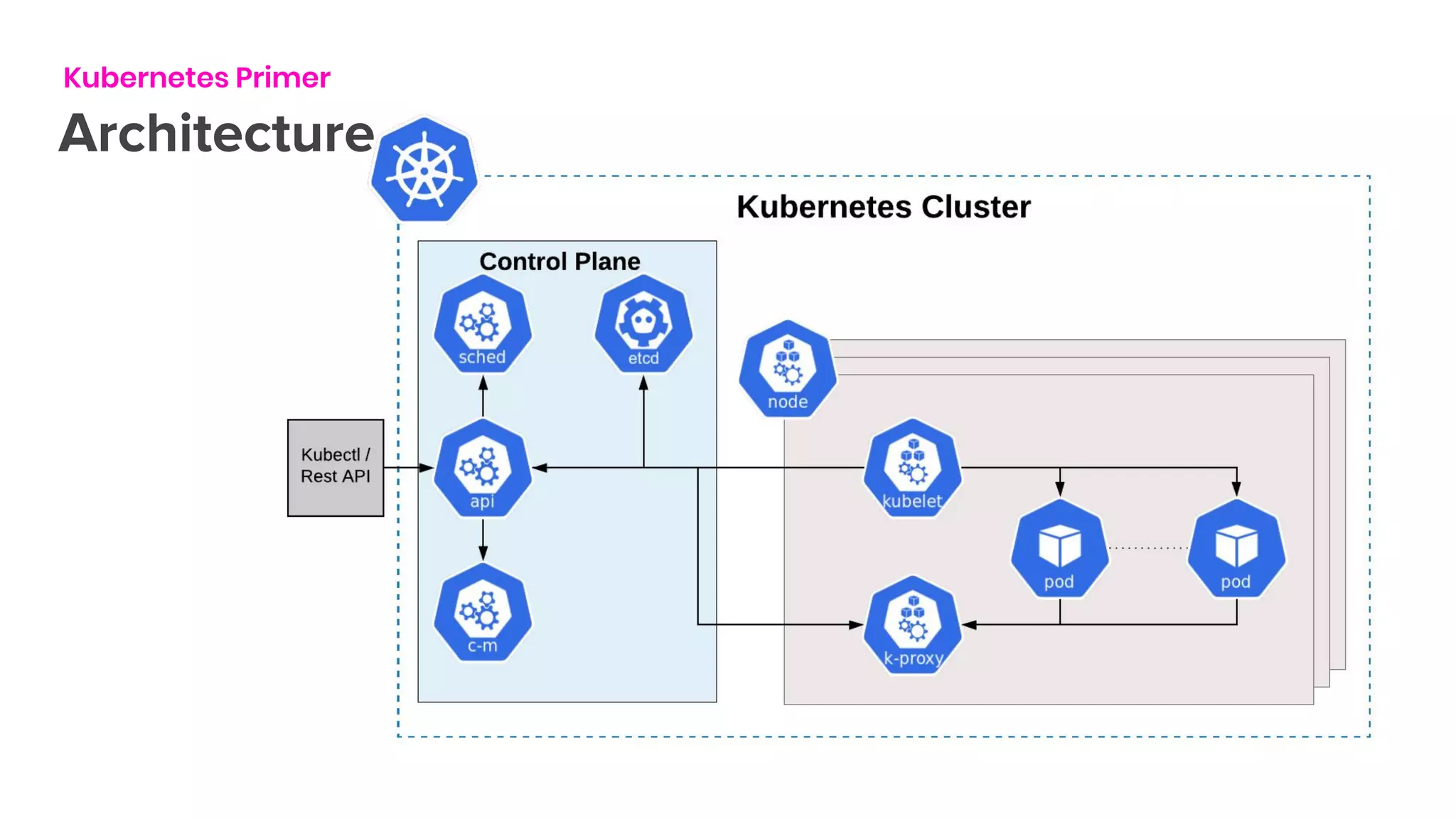
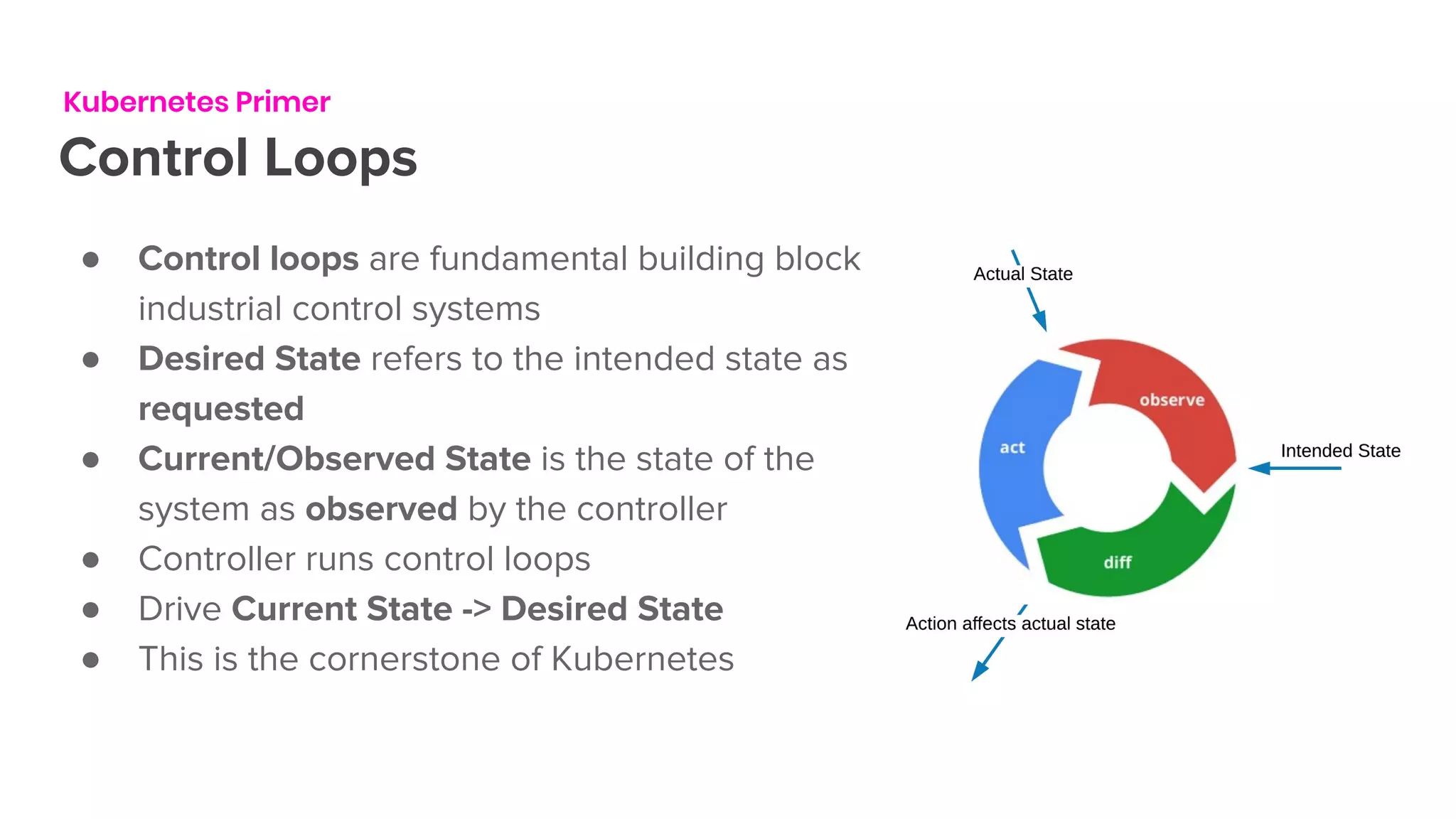






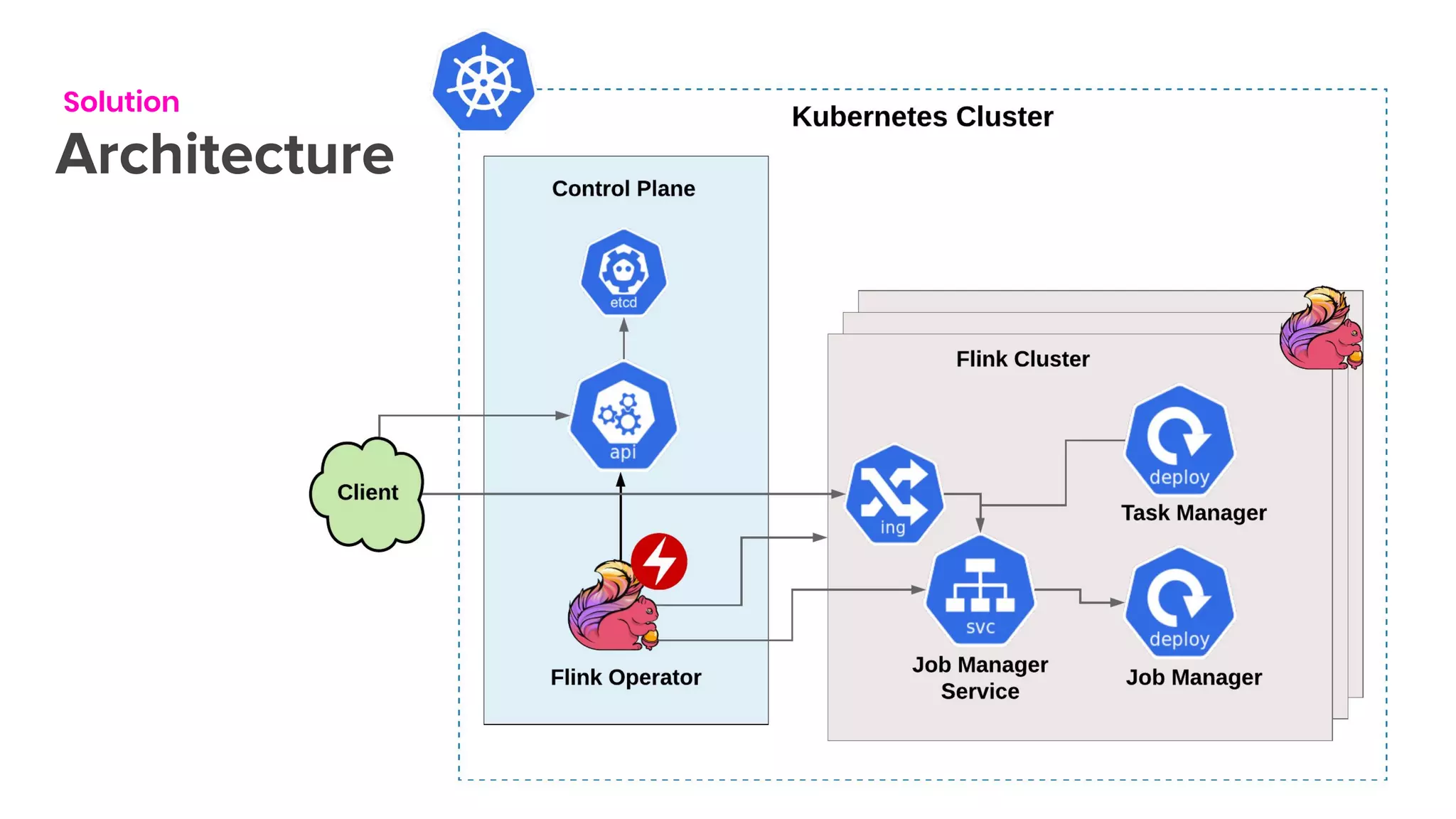
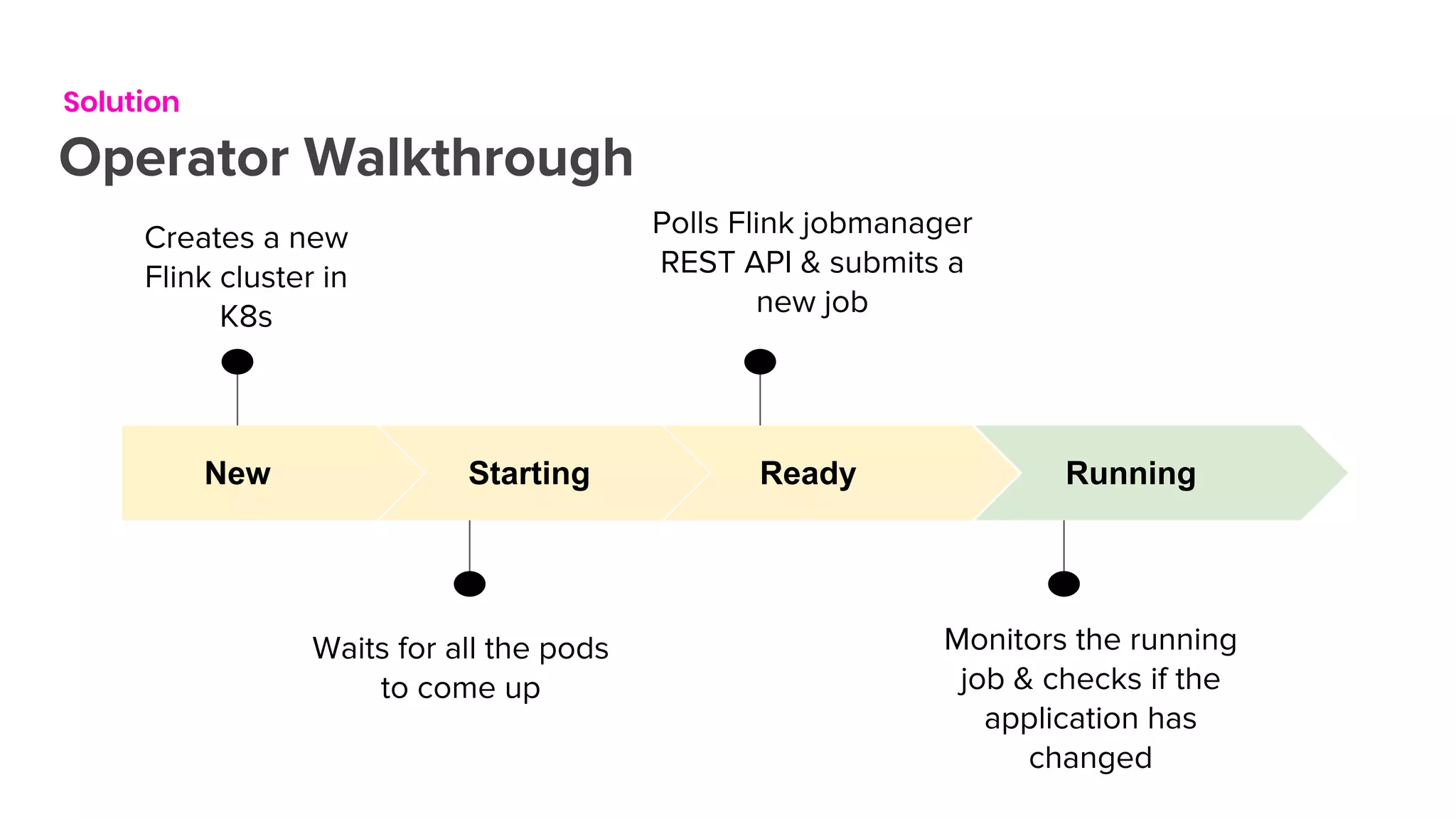
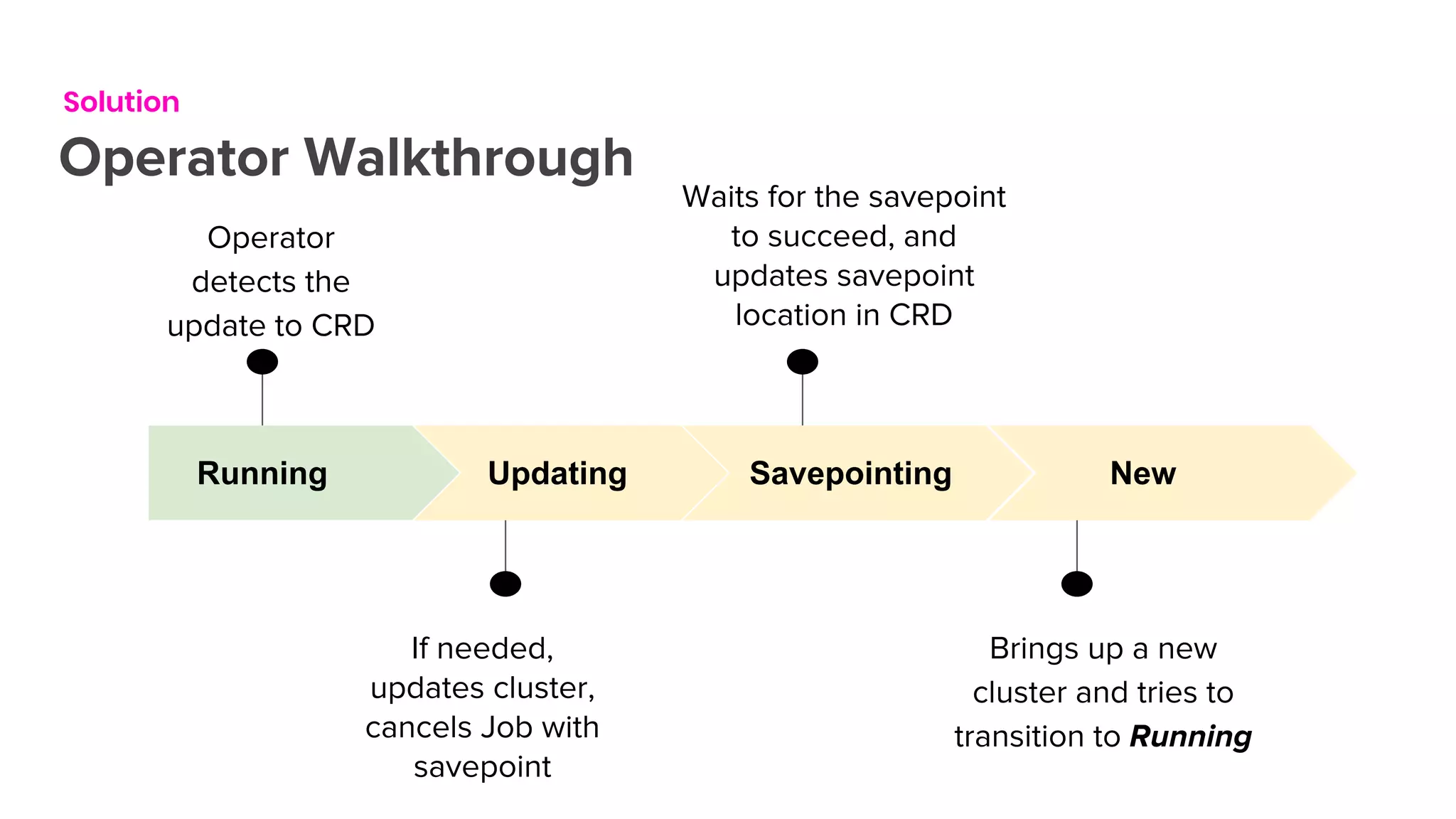


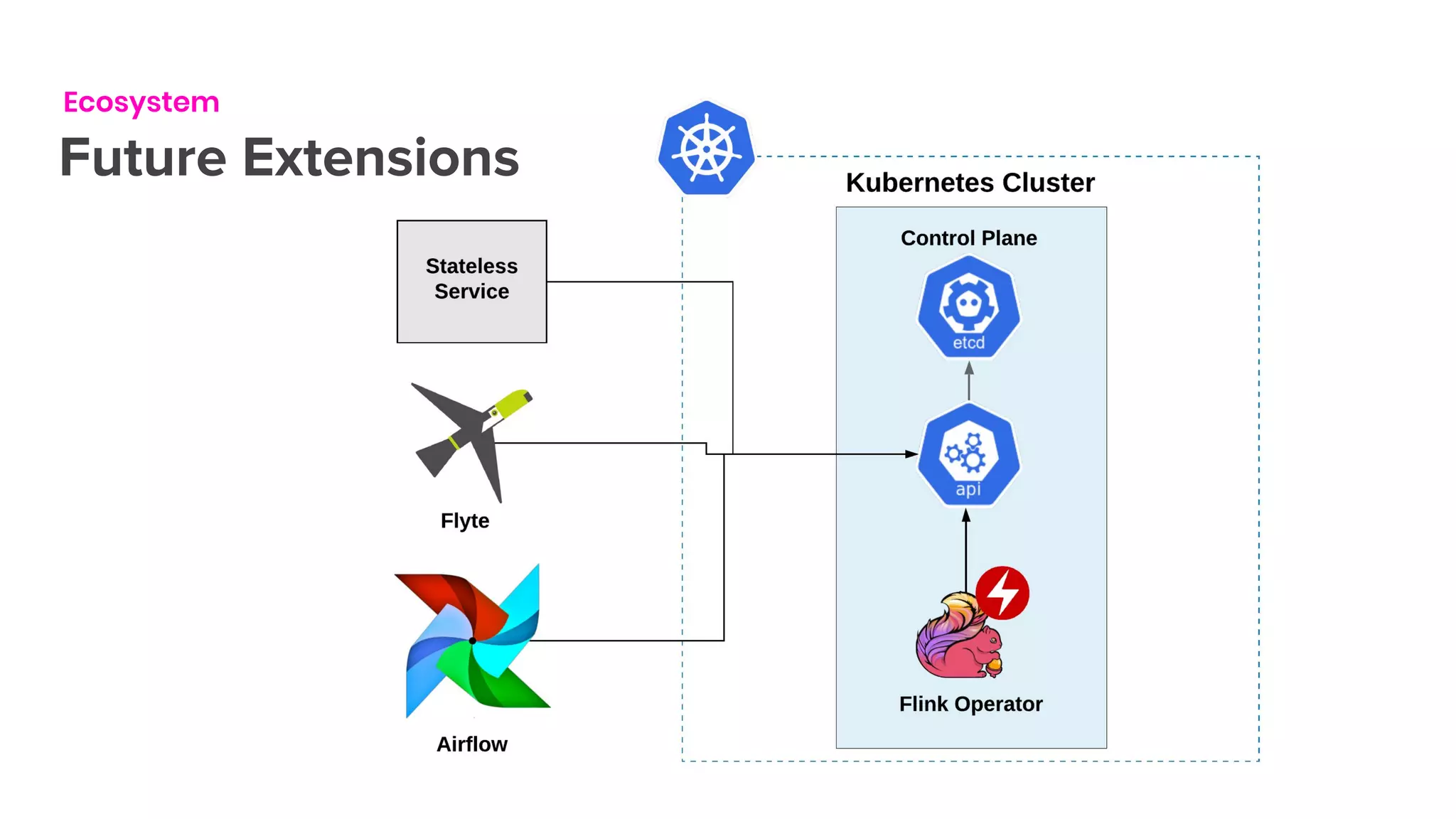



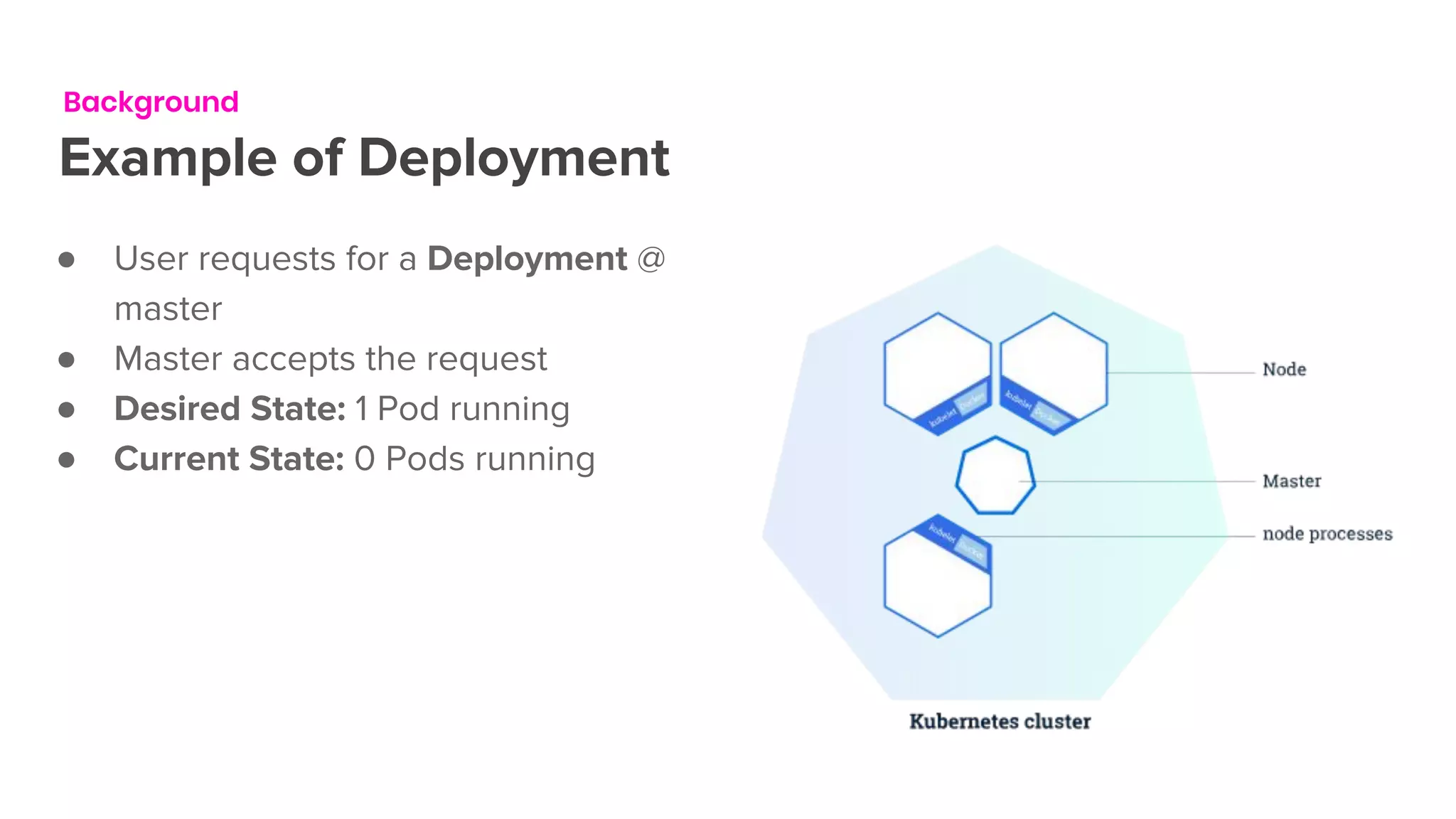
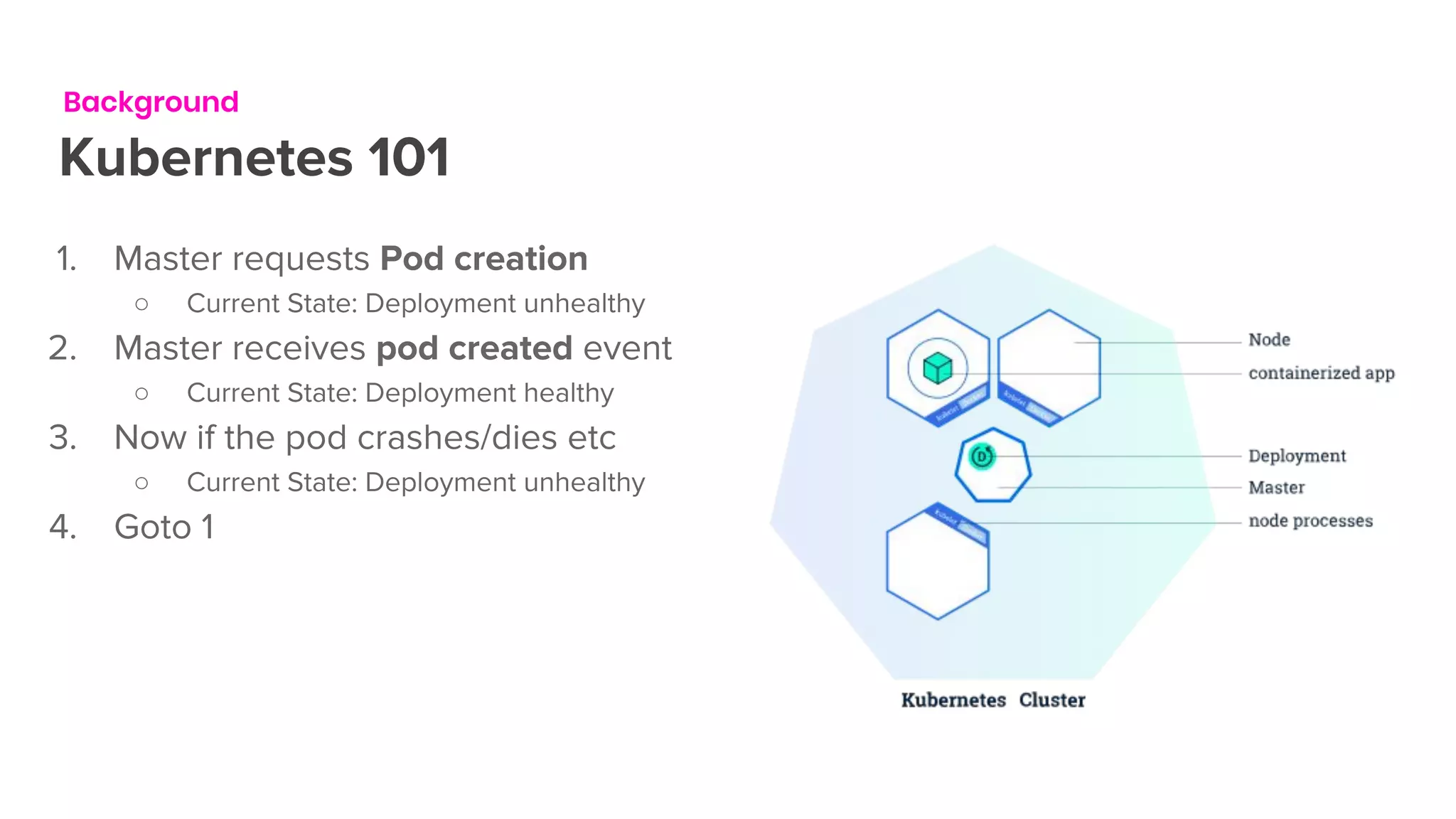

The document outlines the integration of Flink on Kubernetes, detailing its background, architecture, and the implementation of the Flink Kubernetes operator to address deployment challenges. It introduces key Kubernetes concepts like pods, control loops, and custom resources, and describes the evolution of Lyft's legacy Flink deployment to a more scalable and manageable system. The future roadmap includes open-source development and improvements for Flink job handling while advertising job opportunities at Lyft.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



