Downloaded 107 times



















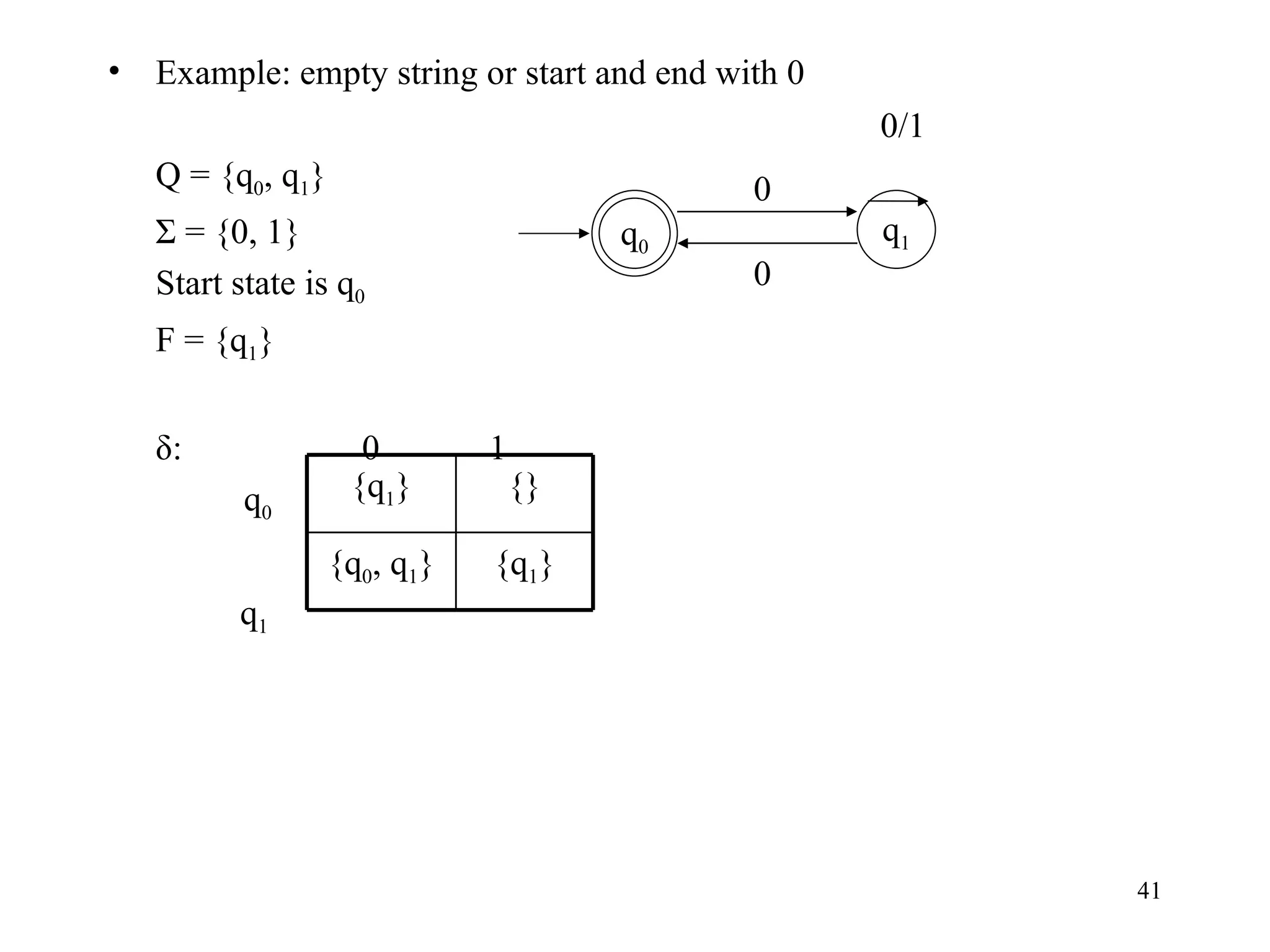
![Lemma 2: Let M be an NFA. Then there exists a DFA M’ such that L(M) = L(M’). Proof: (sketch) Let M = (Q, Σ, δ,q 0 ,F). Define a DFA M’ = (Q’, Σ, δ’,q ’ 0 ,F’) as: Q’ = 2 Q Each state in M’ corresponds to a = {Q 0 , Q 1 ,…,} subset of states from M where Q u = [q i0 , q i1 ,…q ij ] F’ = {Q u | Q u contains at least one state in F} q ’ 0 = [q 0 ] δ’(Q u , a) = Q v iff δ(Q u , a) = Q v](https://image.slidesharecdn.com/finiteautomata-120210203506-phpapp02/75/Finite-automata-40-2048.jpg)
![Construct DFA M’ as follows: δ({q 0 }, 0) = {q 1 } => δ’([q 0 ], 0) = [q 1 ] δ({q 0 }, 1) = {} => δ’([q 0 ], 1) = [ ] δ({q 1 }, 0) = {q 0 , q 1 } => δ’([q 1 ], 0) = [q 0 , q 1 ] δ({q 1 }, 1) = {q 1 } => δ’([q 1 ], 1) = [q 1 ] δ({q 0 , q 1 }, 0) = {q 0 , q 1 } => δ’([q 0 , q 1 ], 0) = [q 0 , q 1 ] δ({q 0 , q 1 }, 1) = {q 1 } => δ’([q 0 , q 1 ], 1) = [q 1 ] δ({}, 0) = {} => δ’([ ], 0) = [ ] δ({}, 1) = {} => δ’([ ], 1) = [ ] [ ] 1 0 1 [q 1 ] 0 0/1 1 0 [q 0 , q 1 ] [q 0 ]](https://image.slidesharecdn.com/finiteautomata-120210203506-phpapp02/75/Finite-automata-42-2048.jpg)



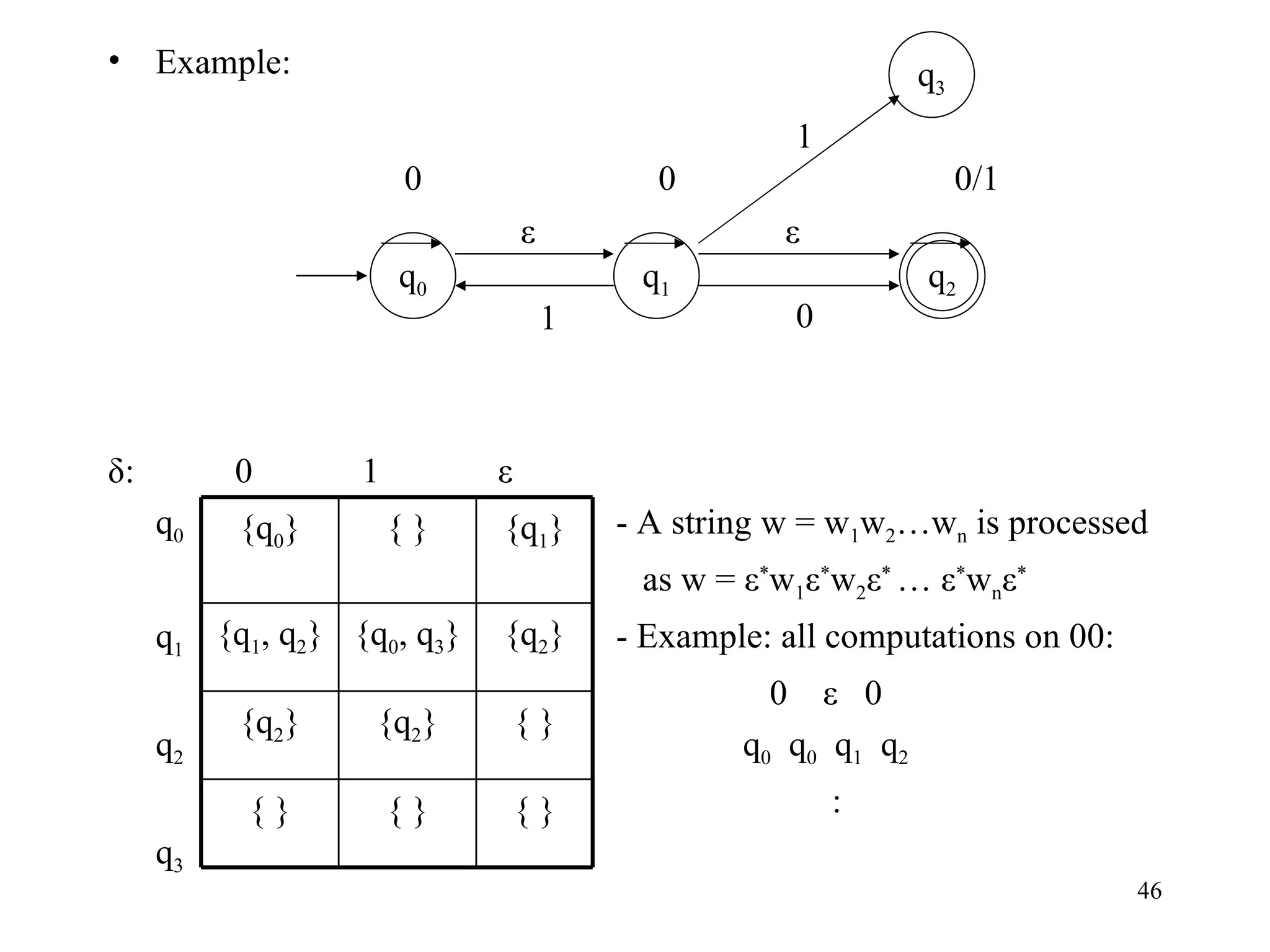












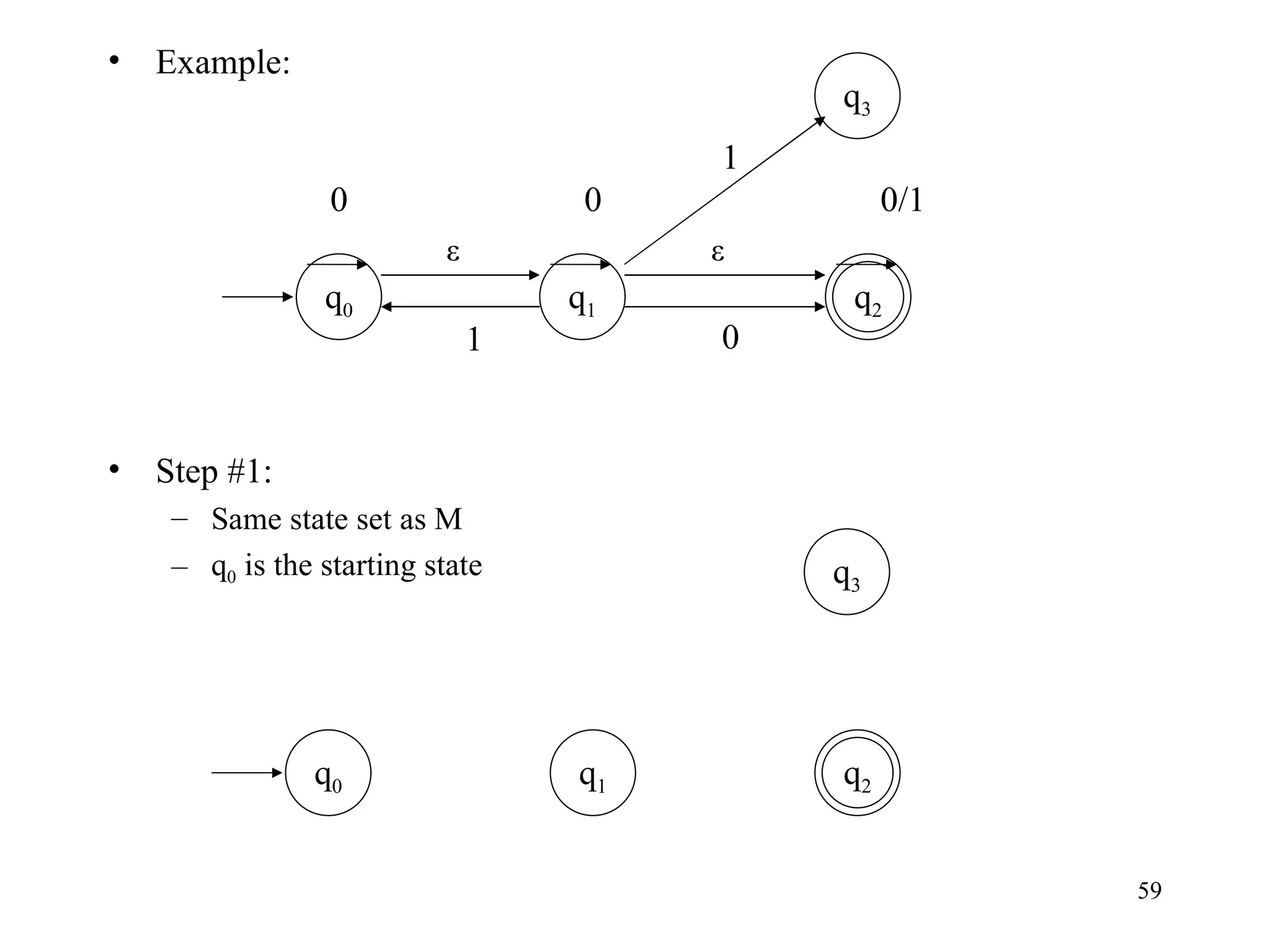
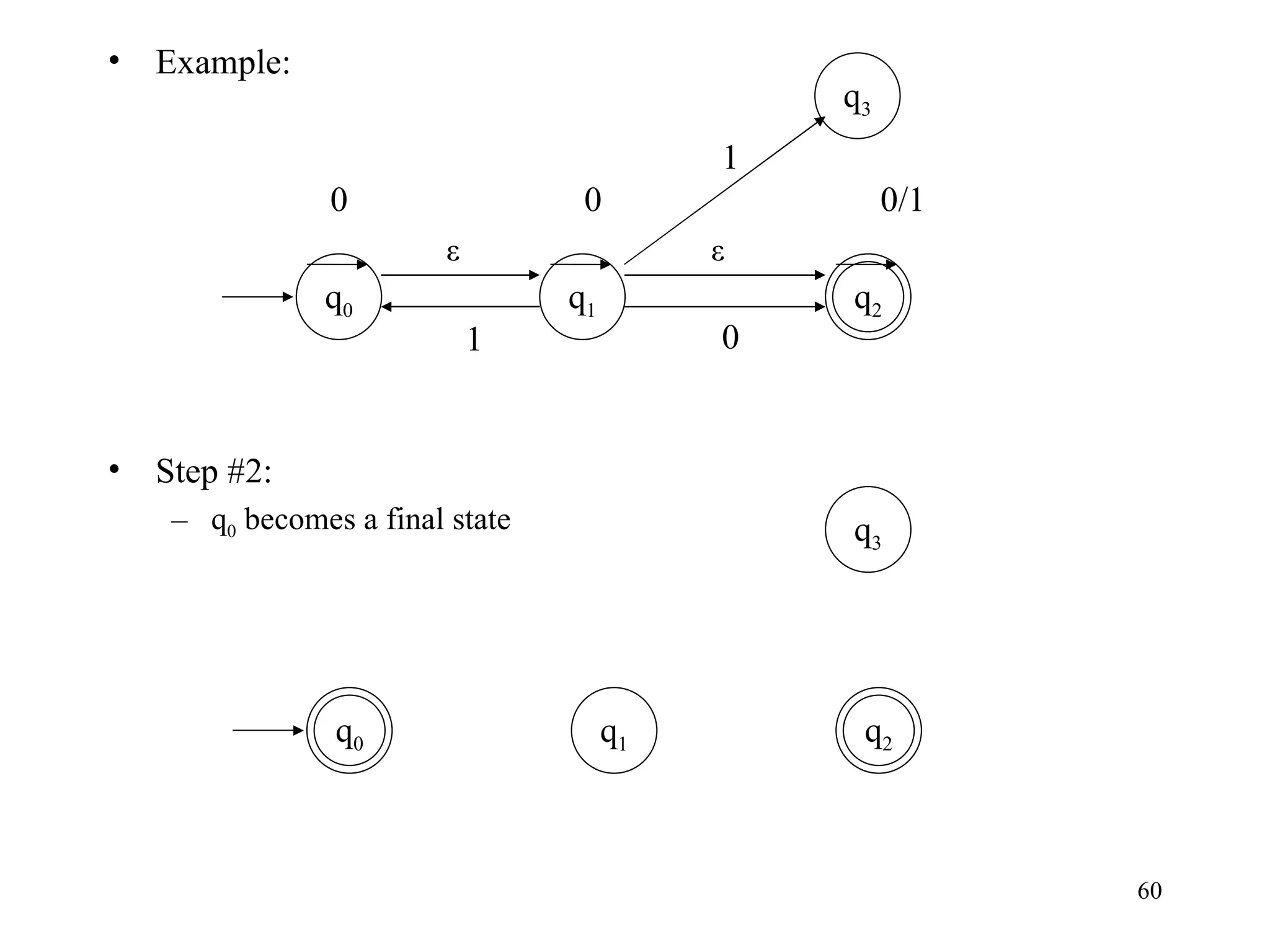
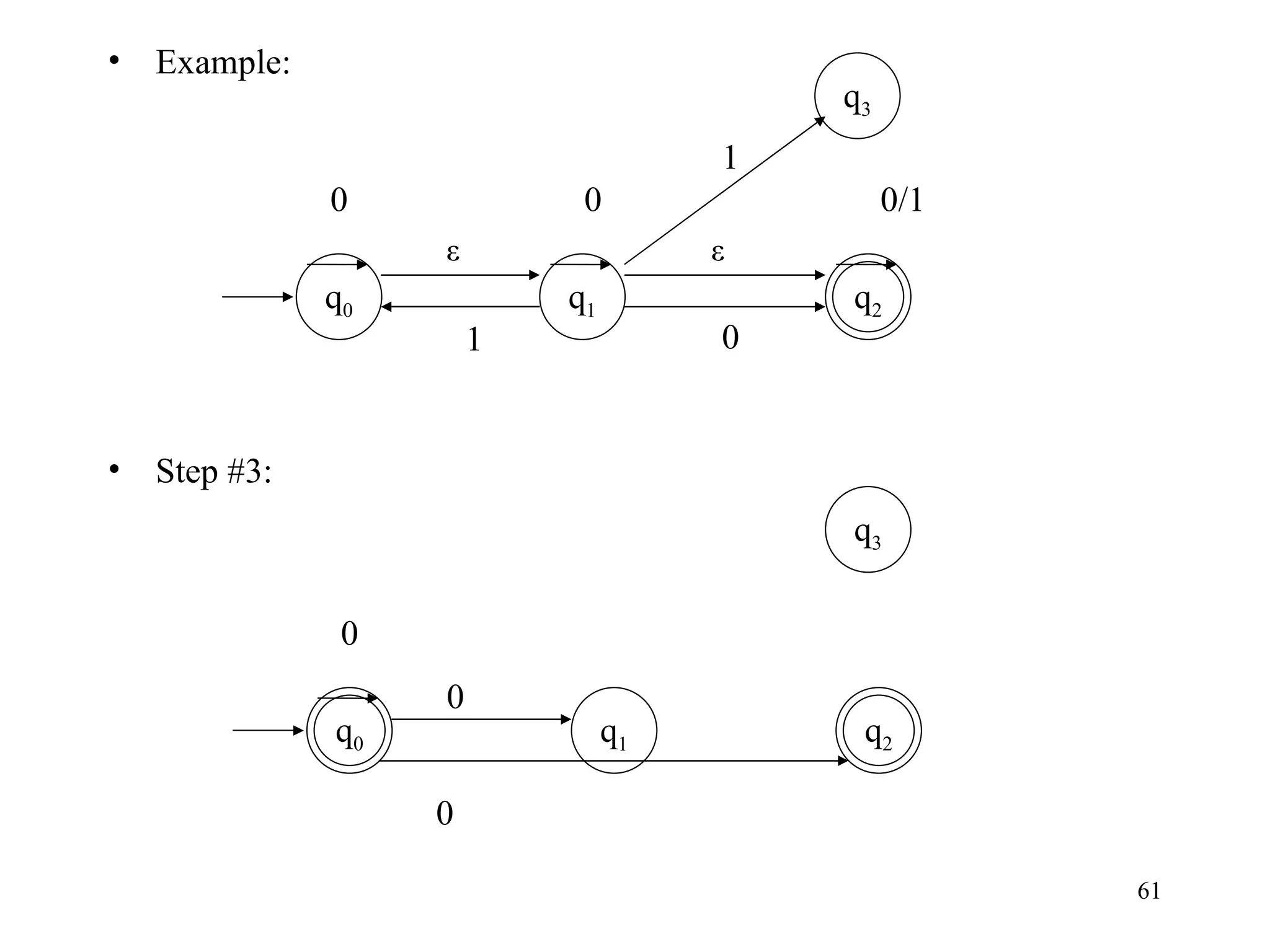
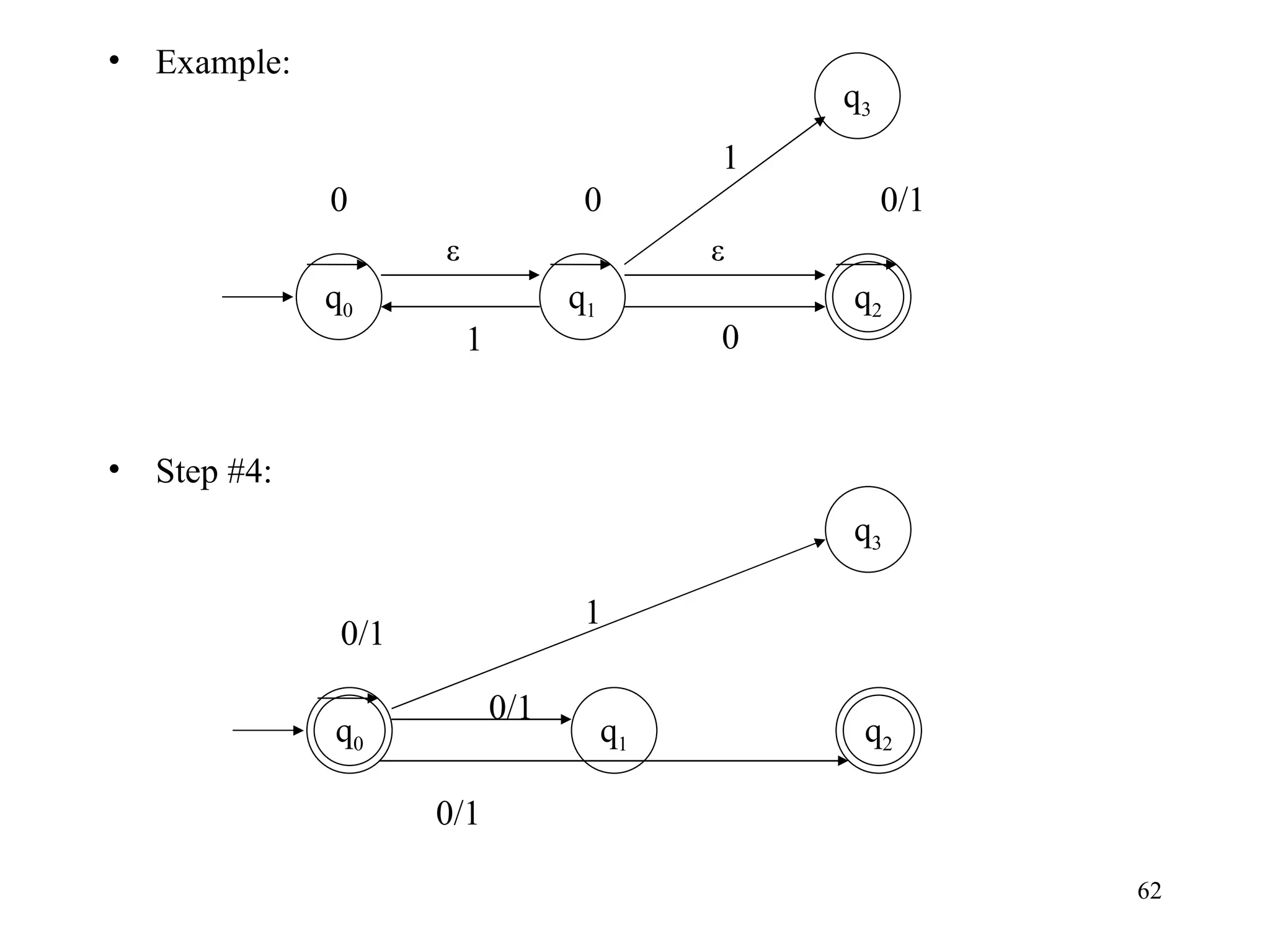
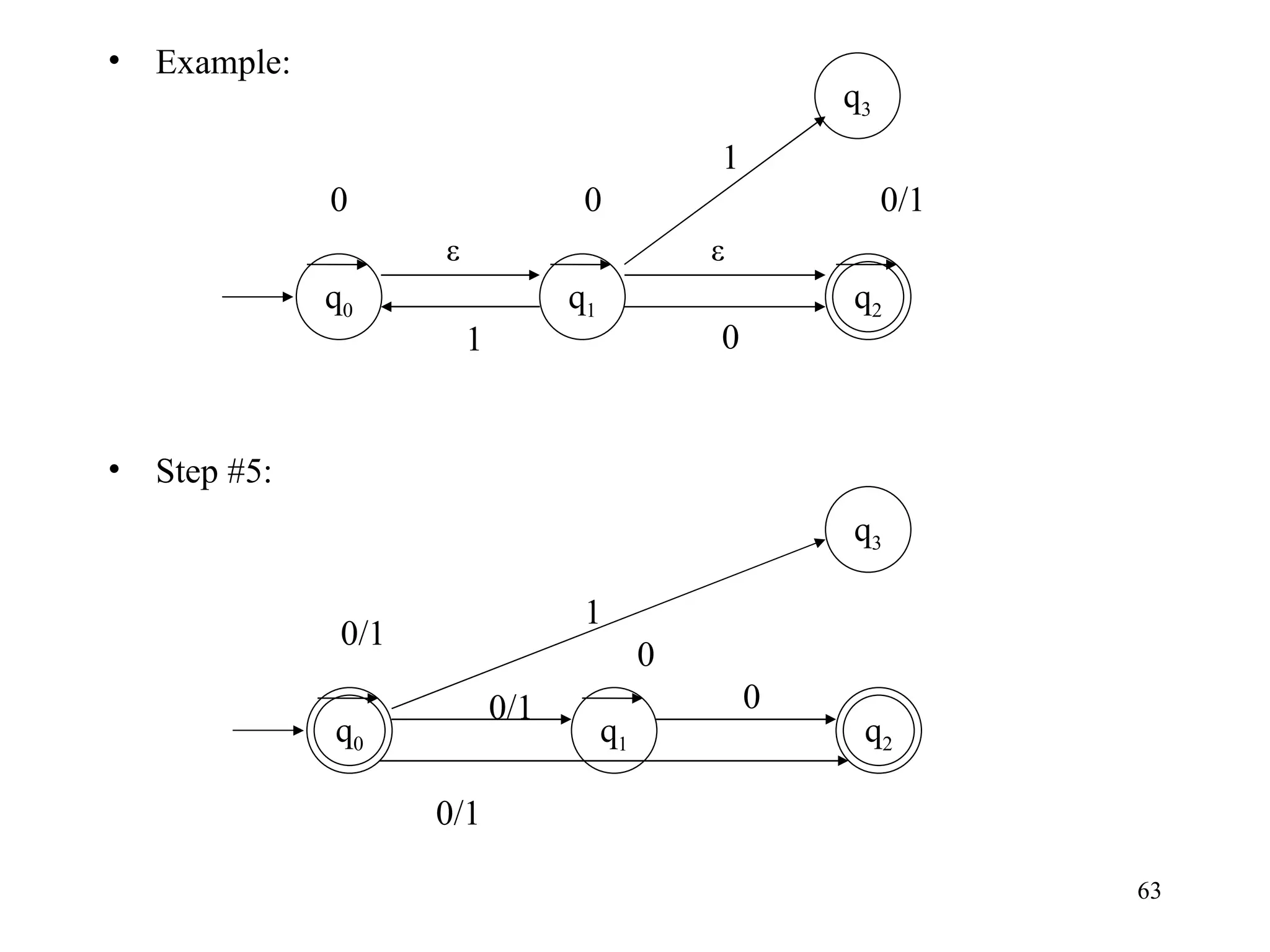
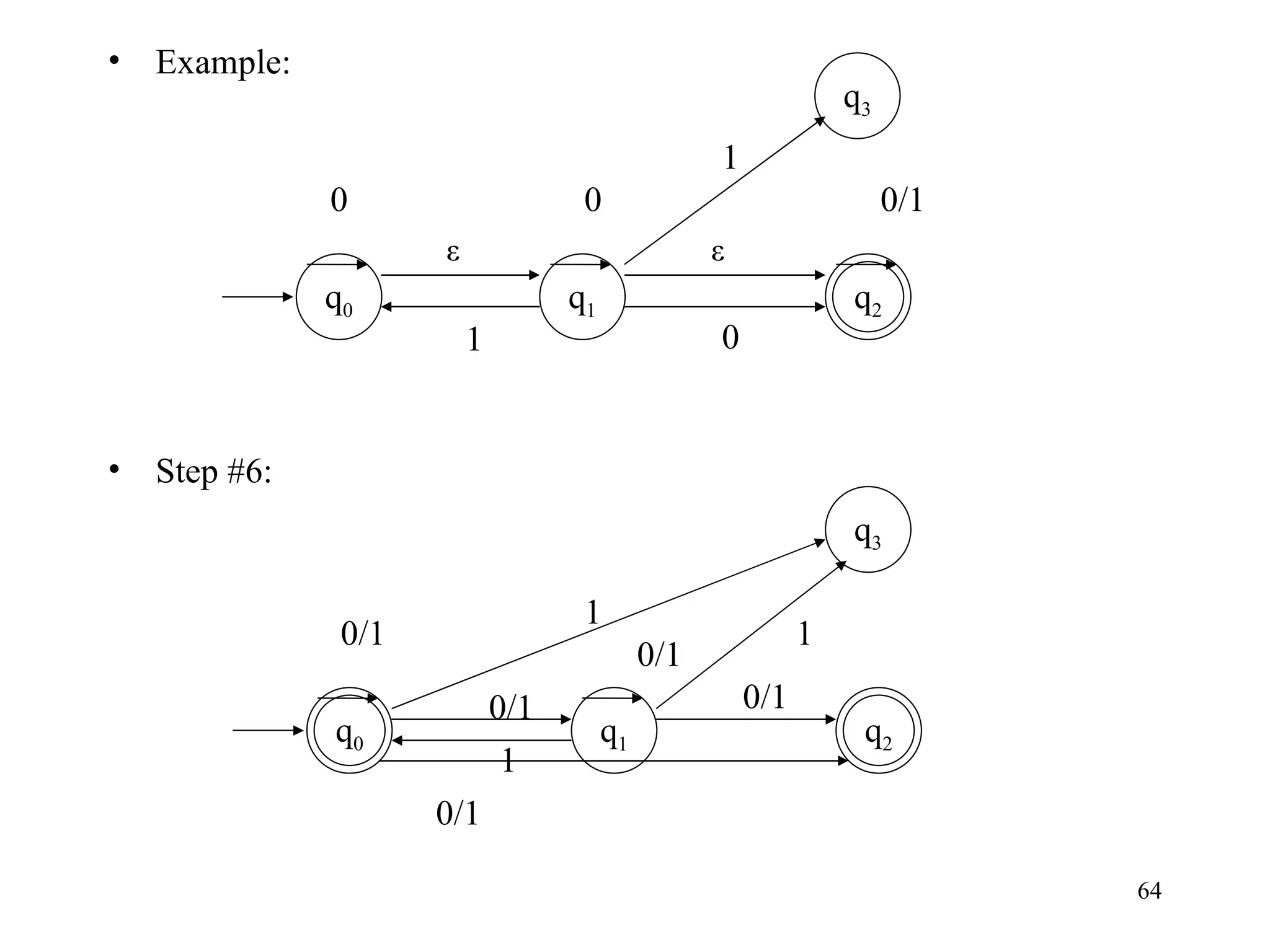


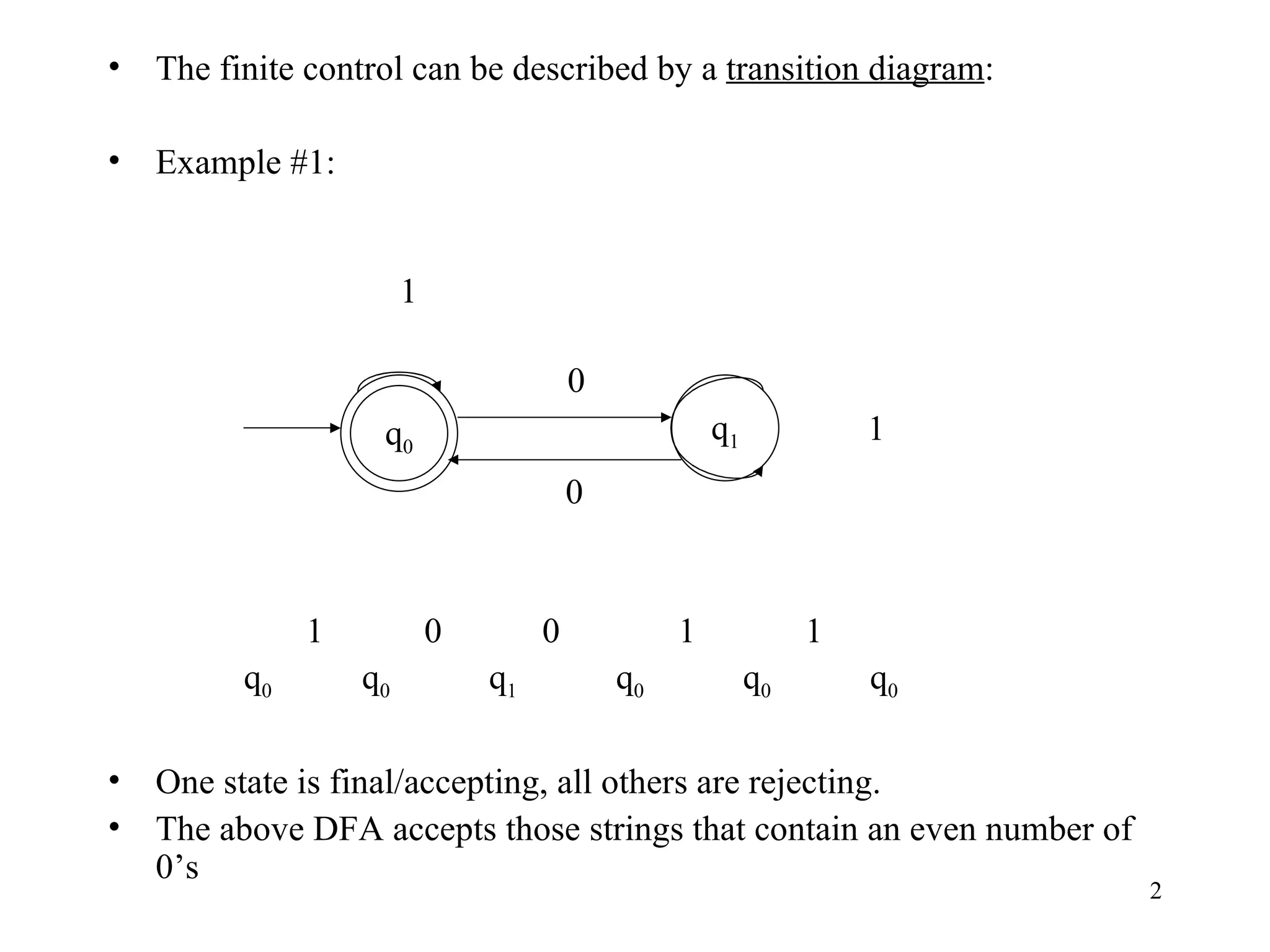
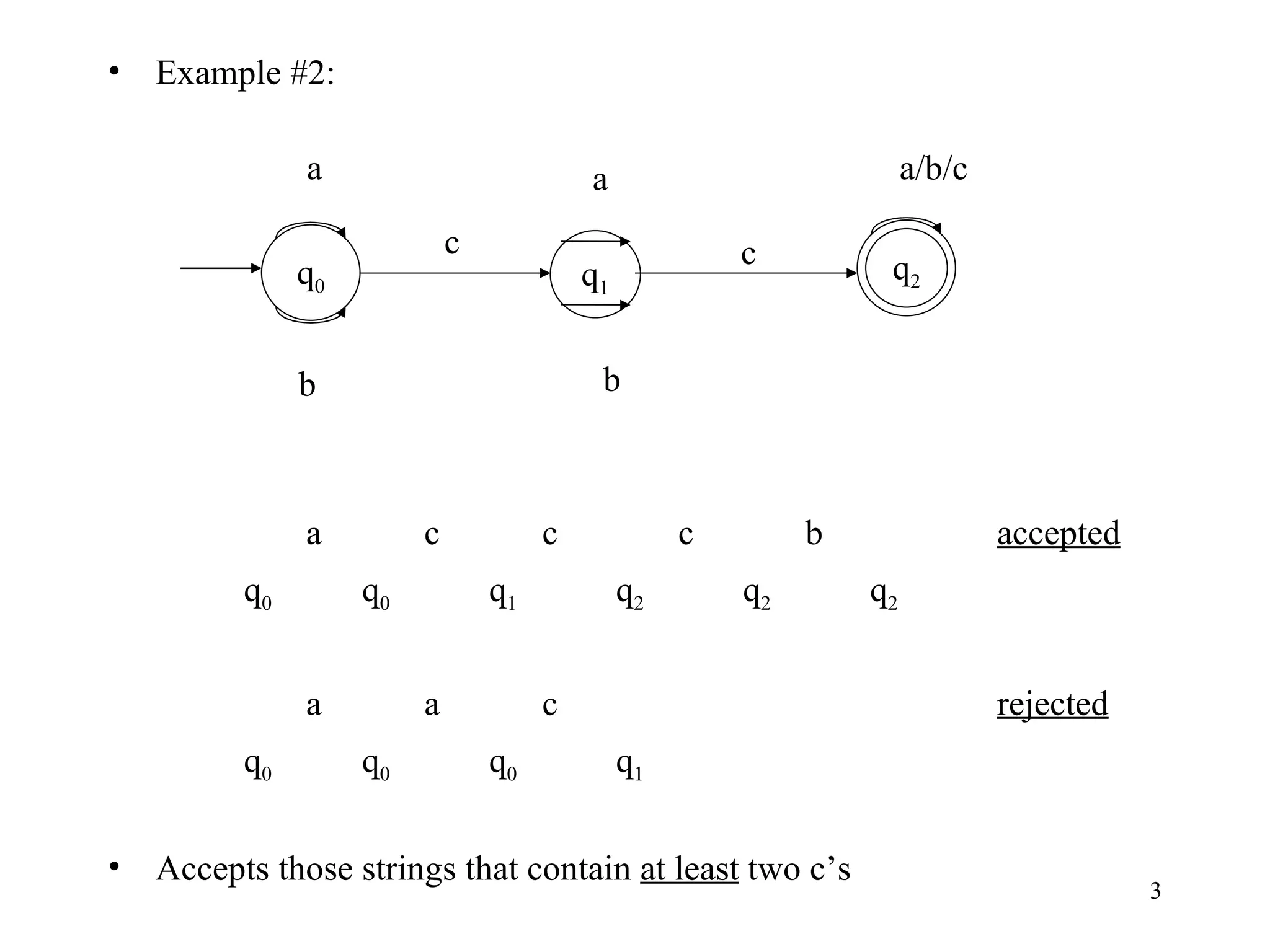
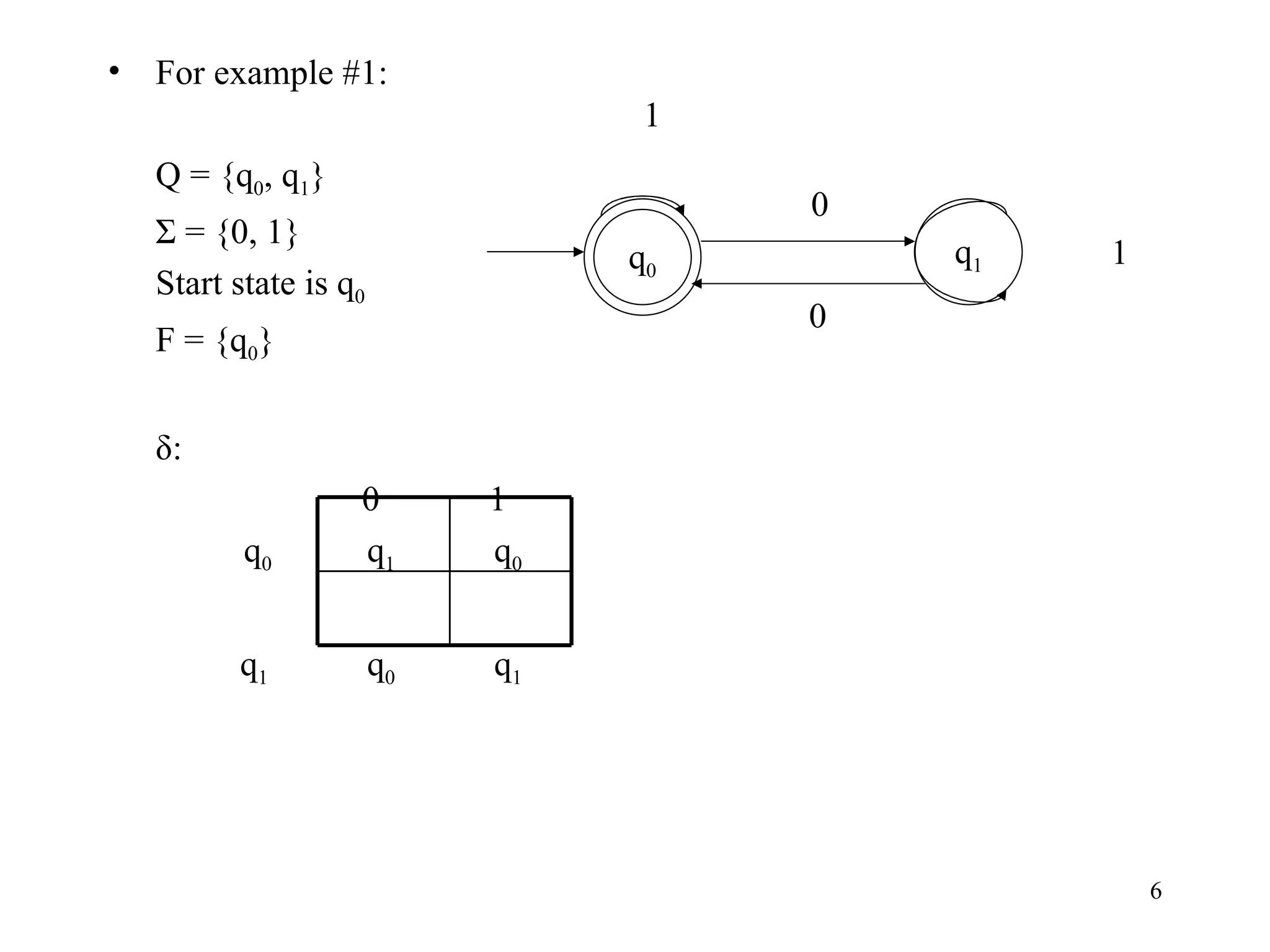
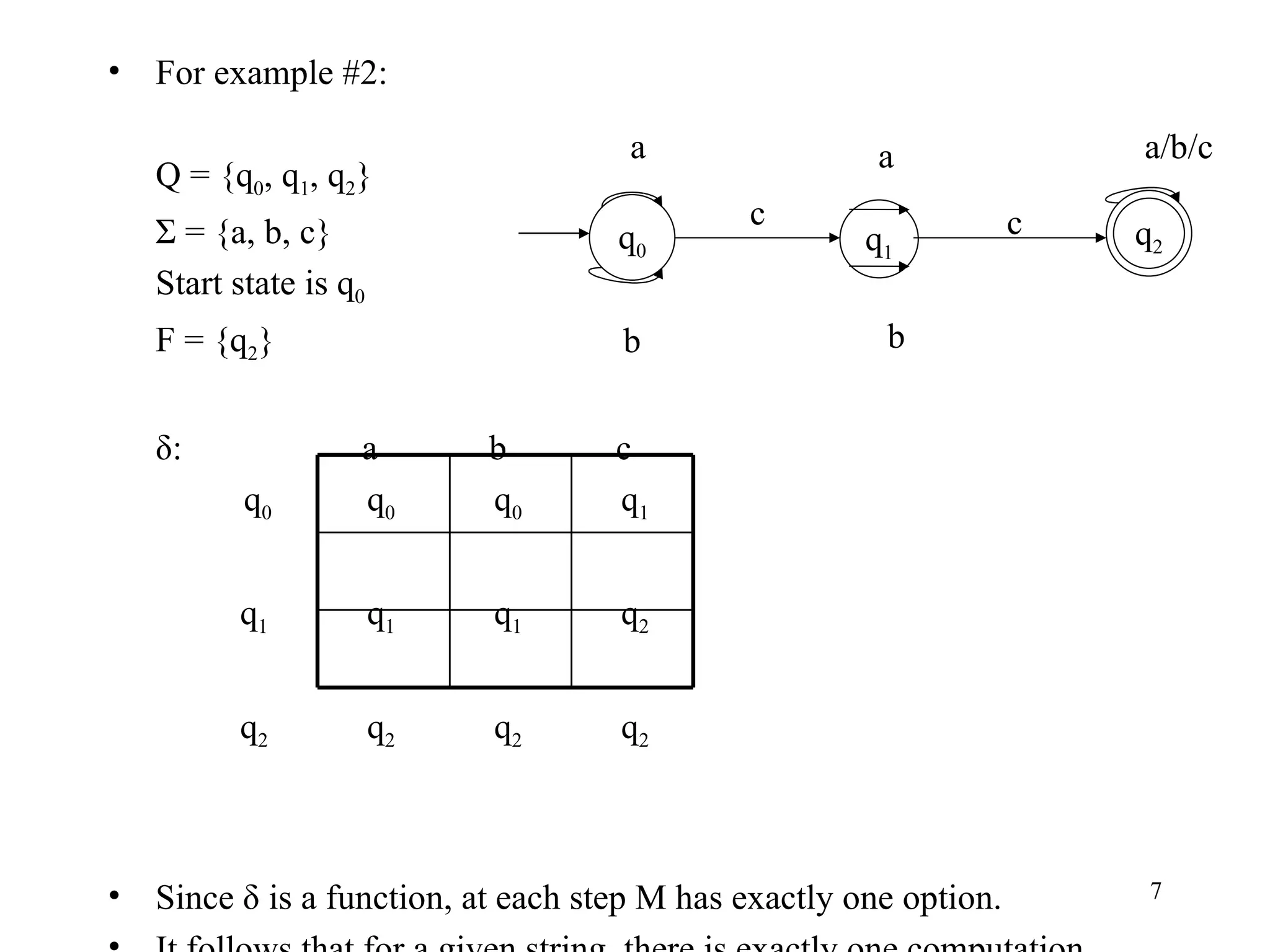
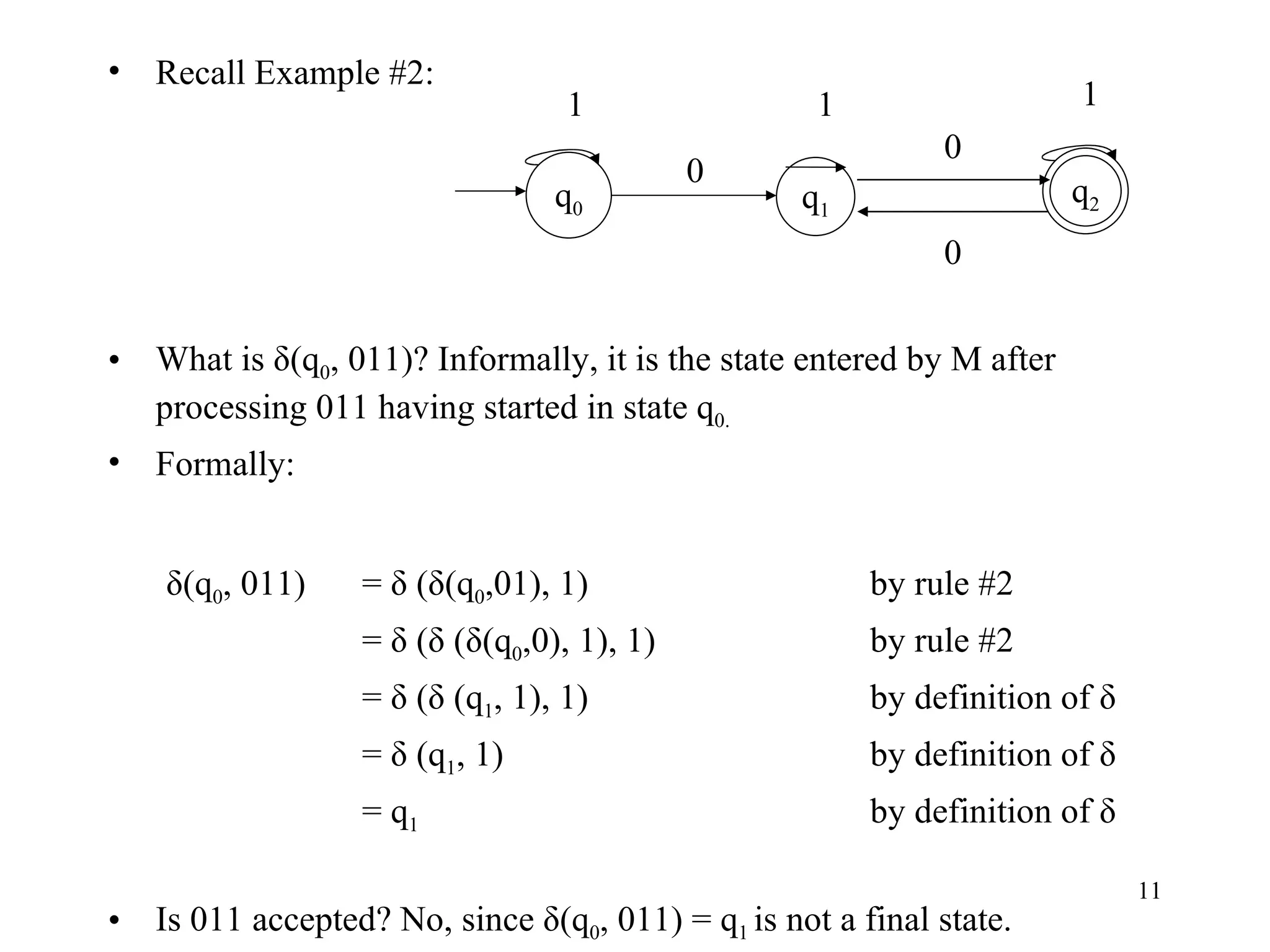
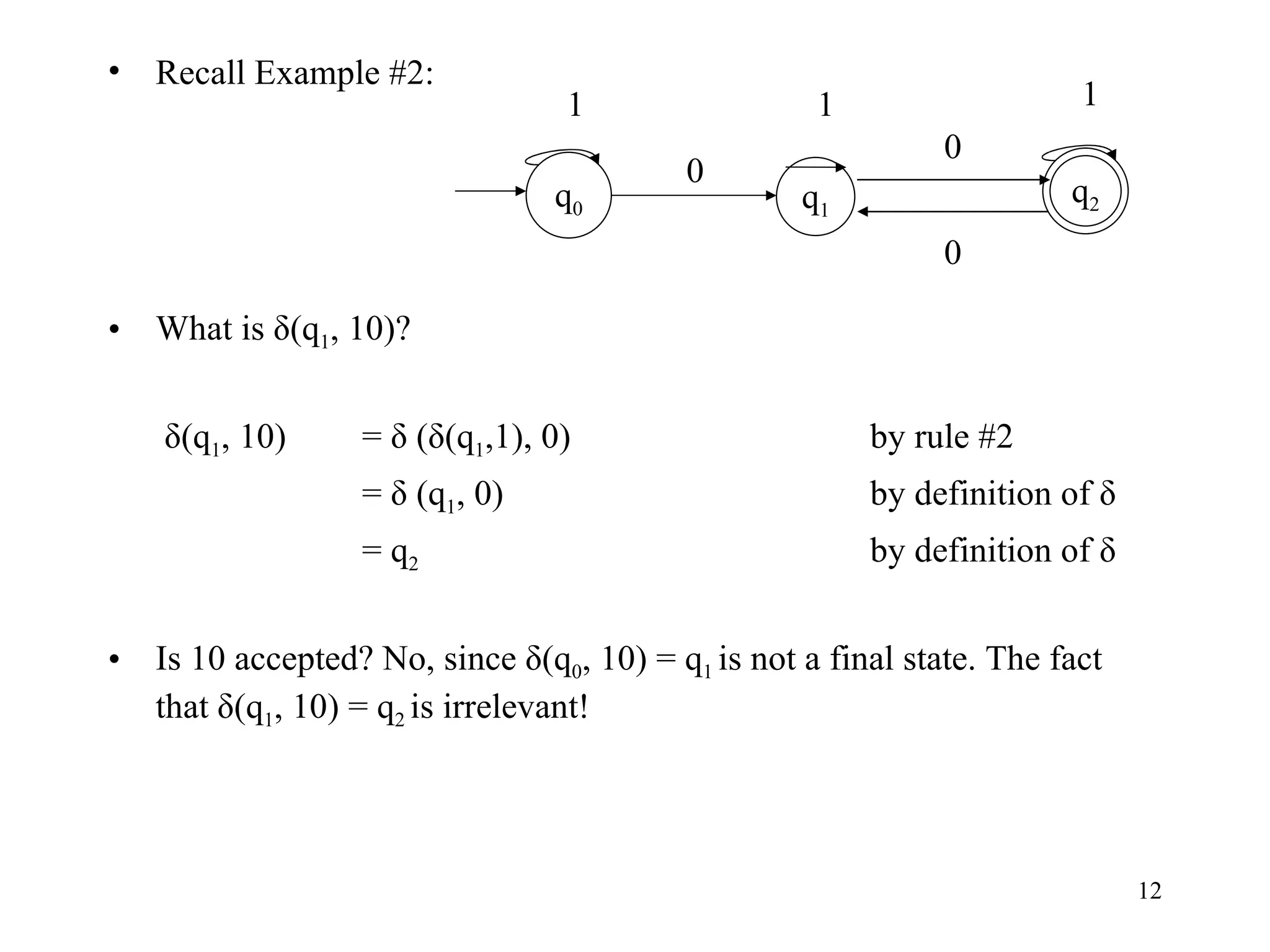
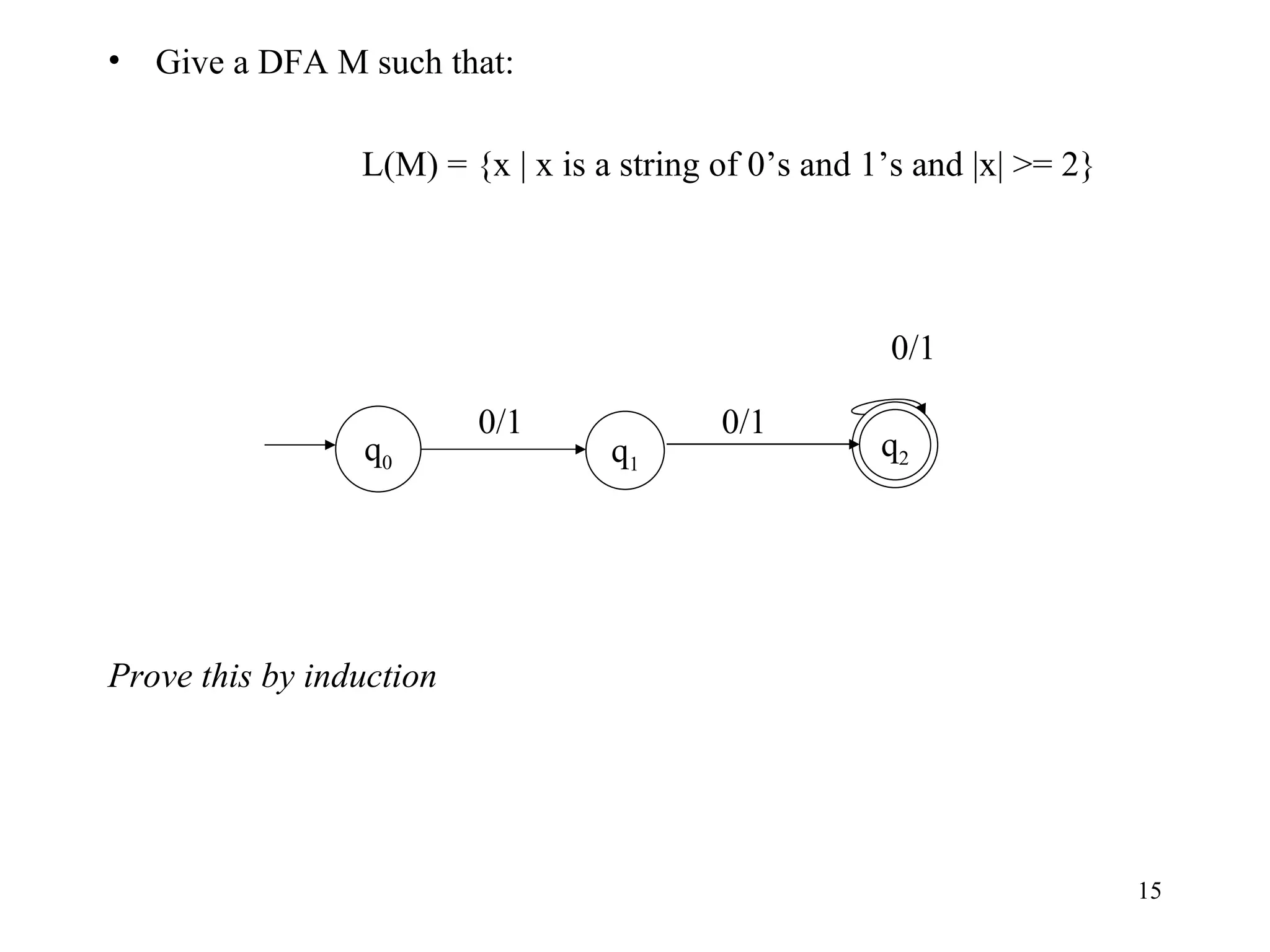
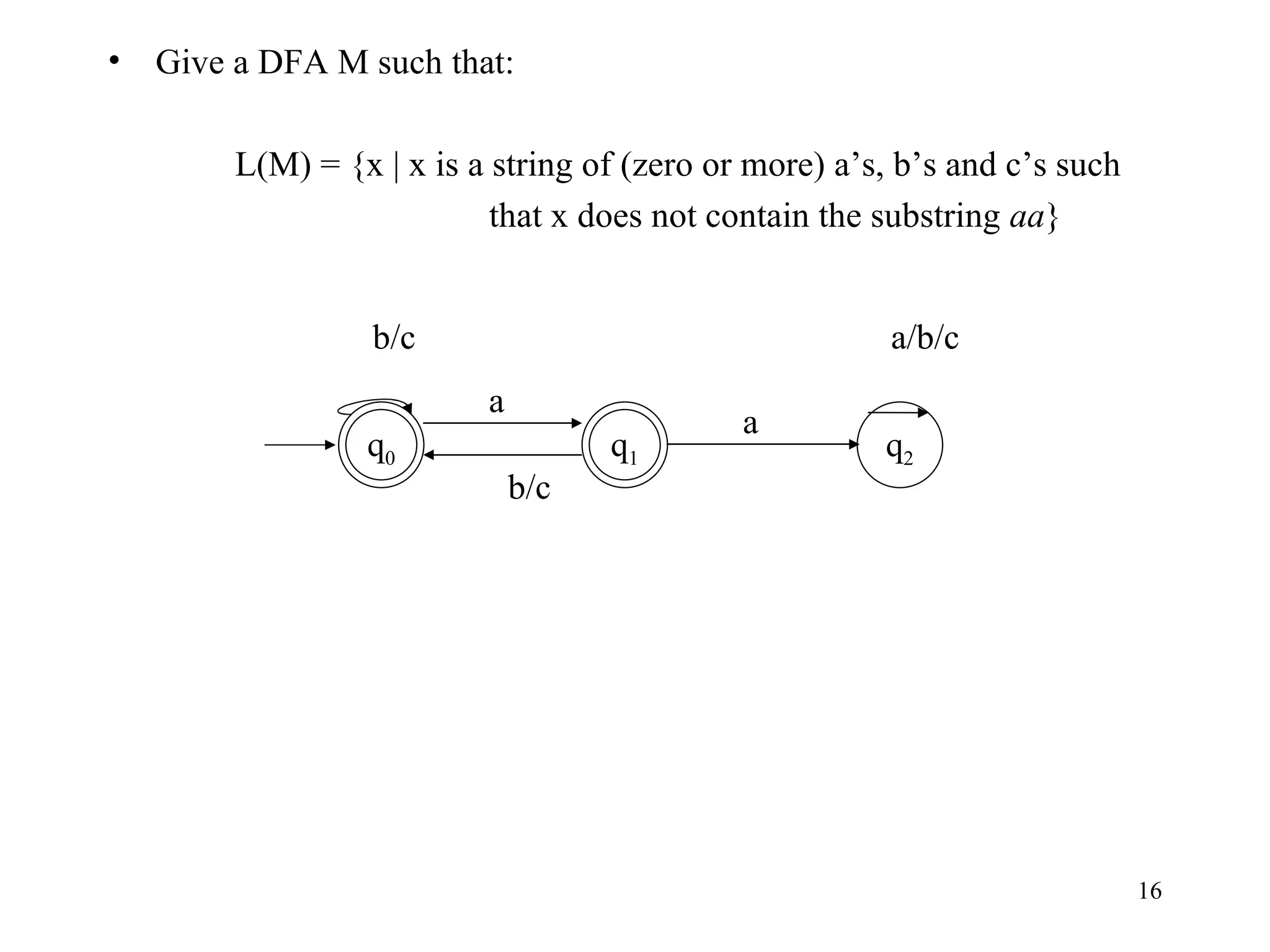
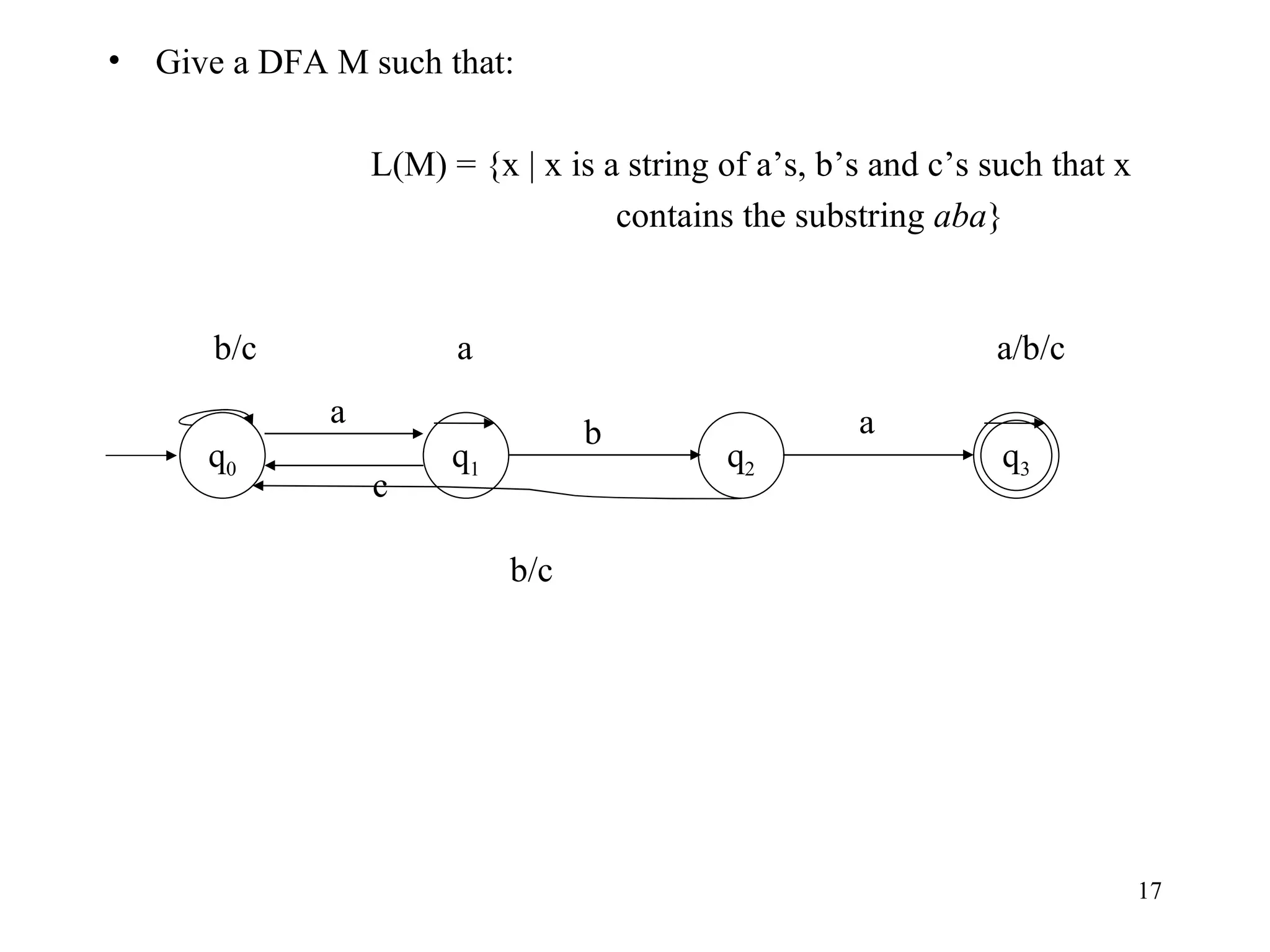
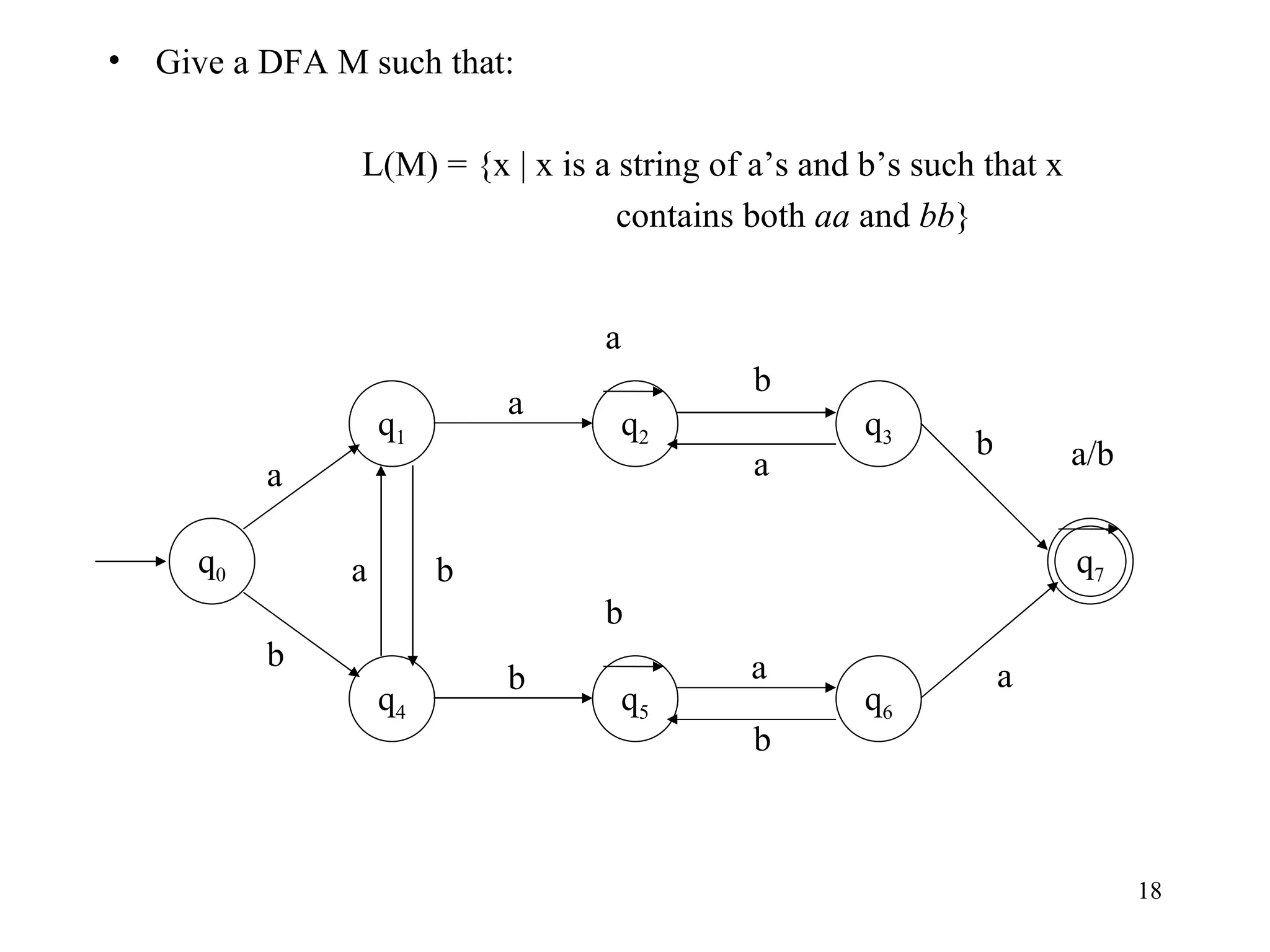
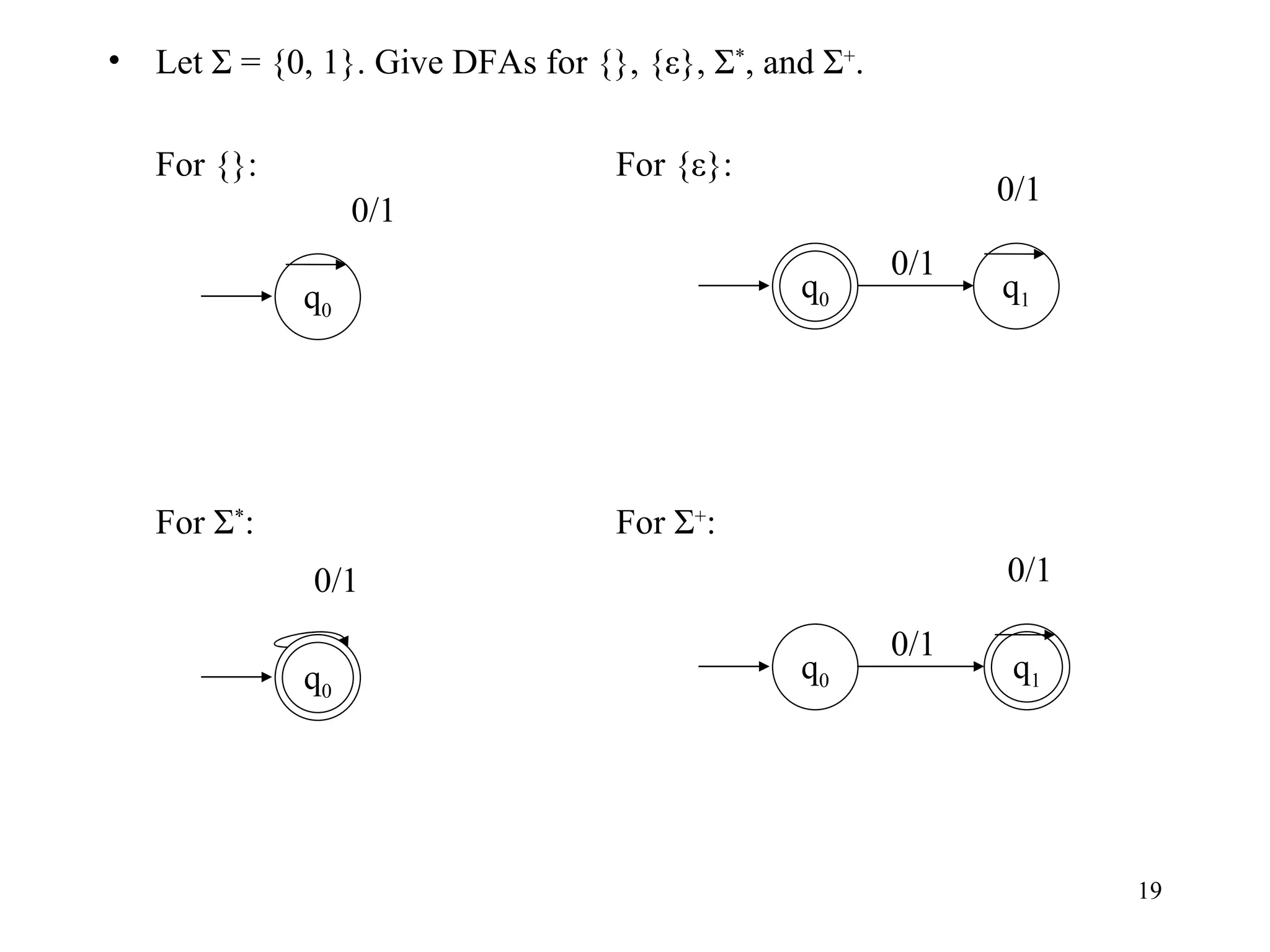
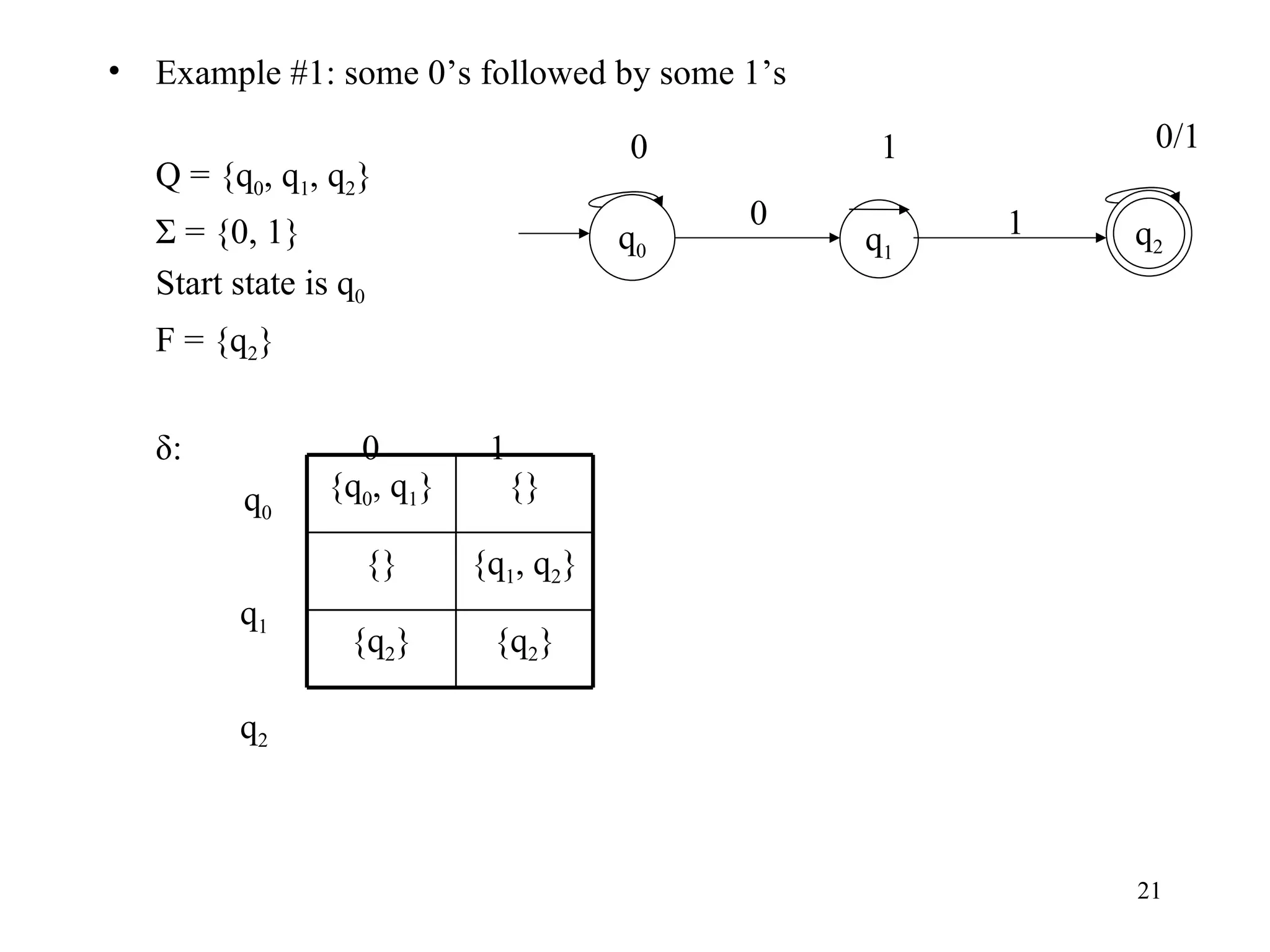
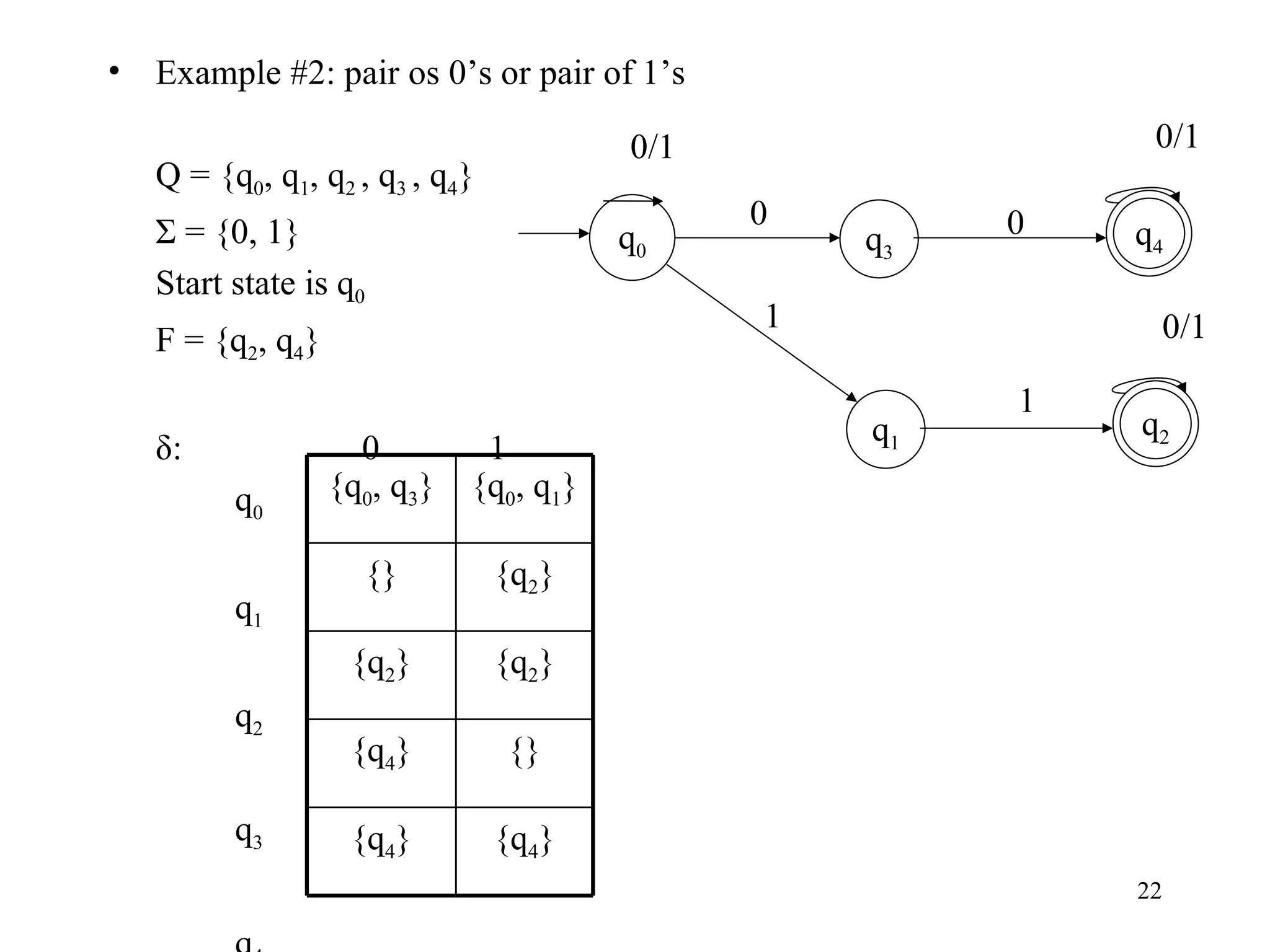
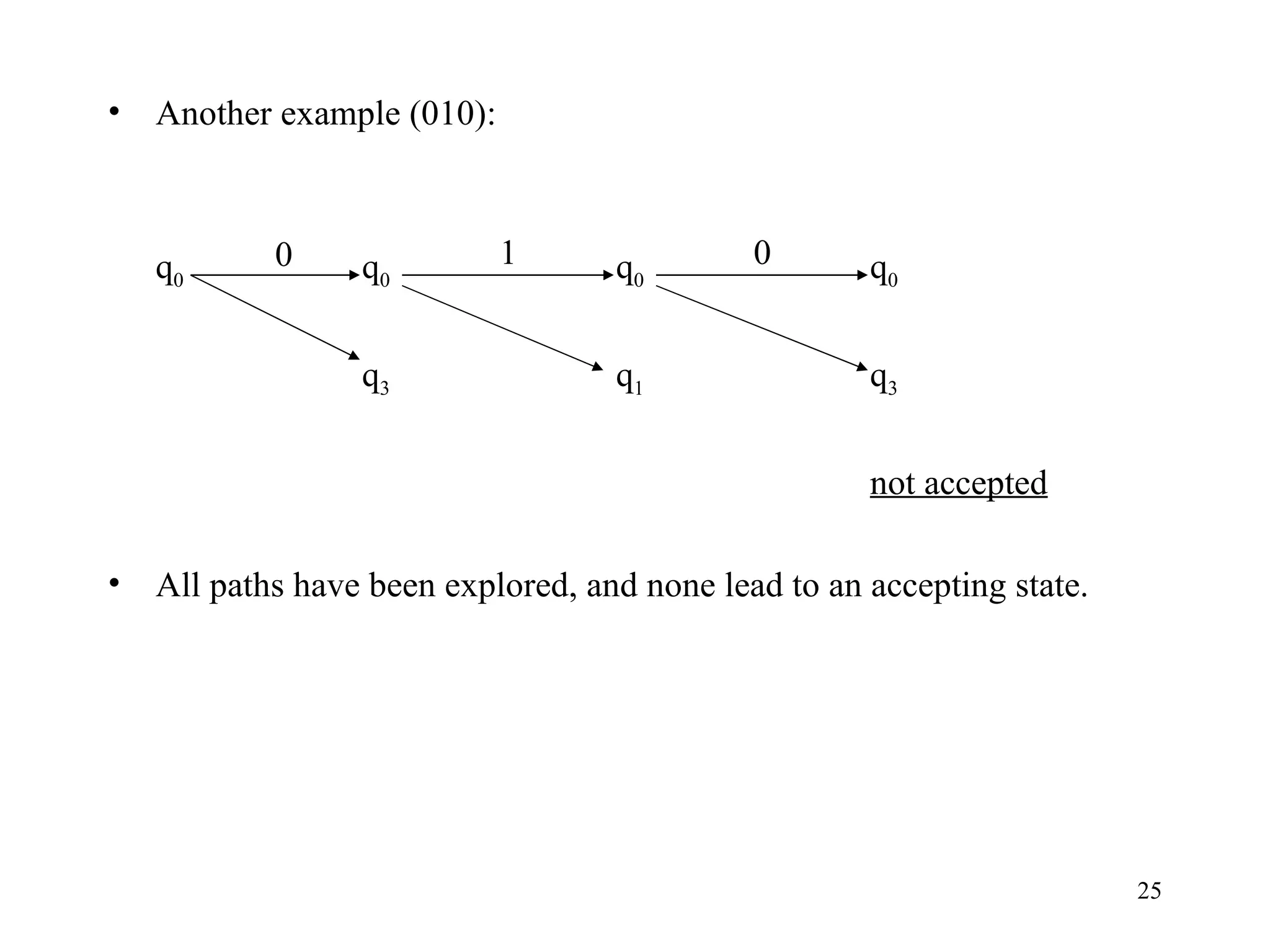
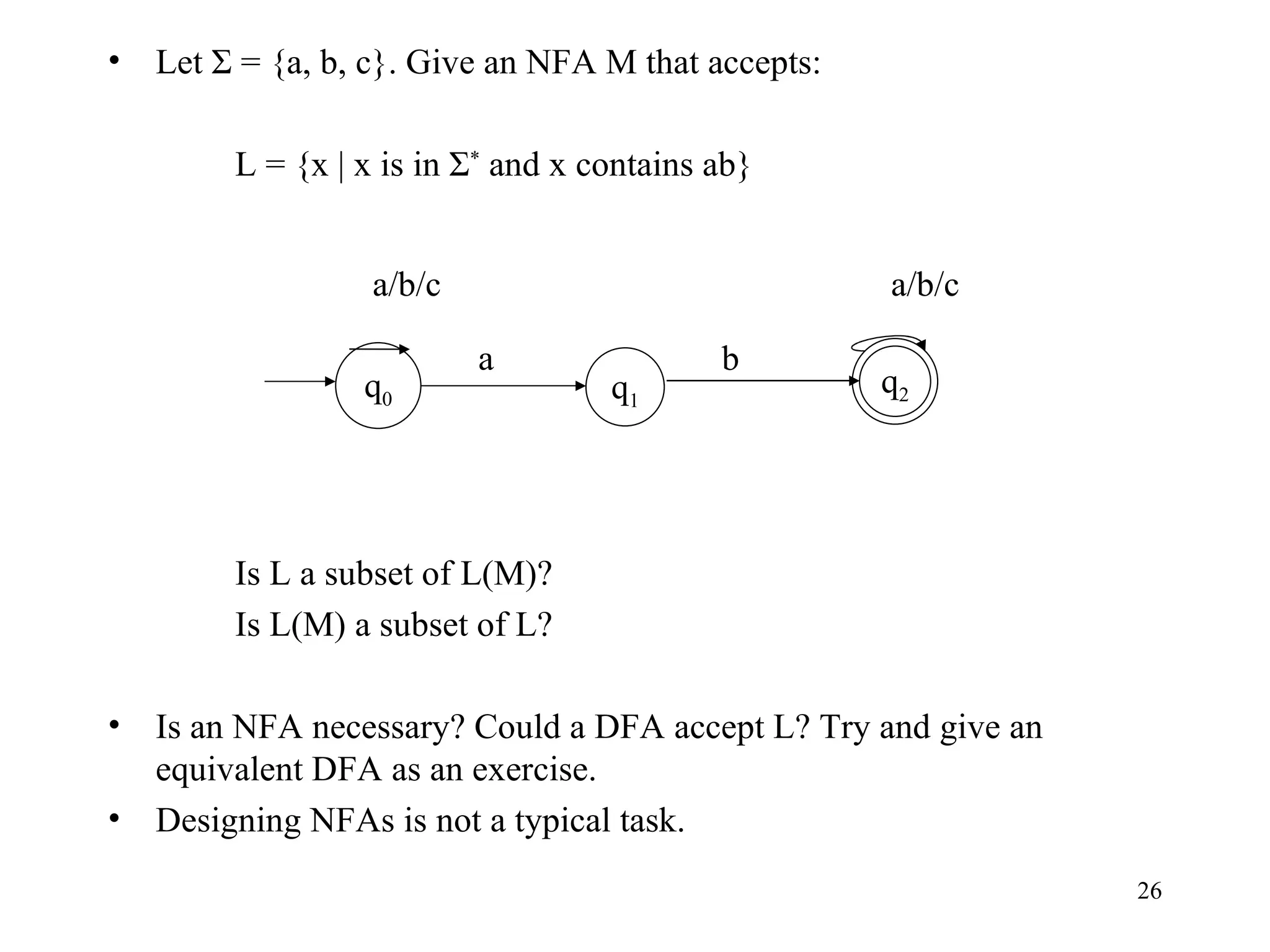
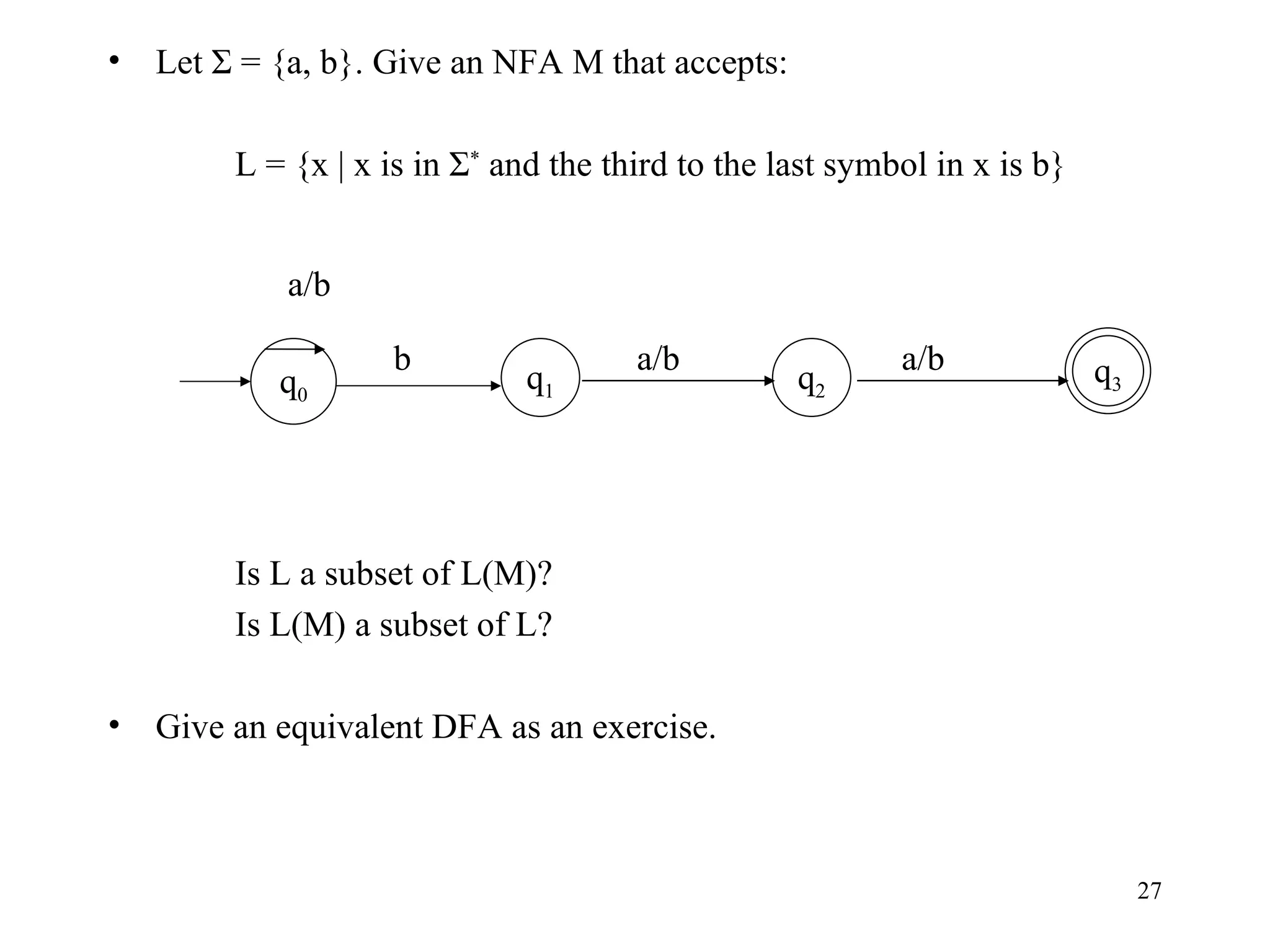
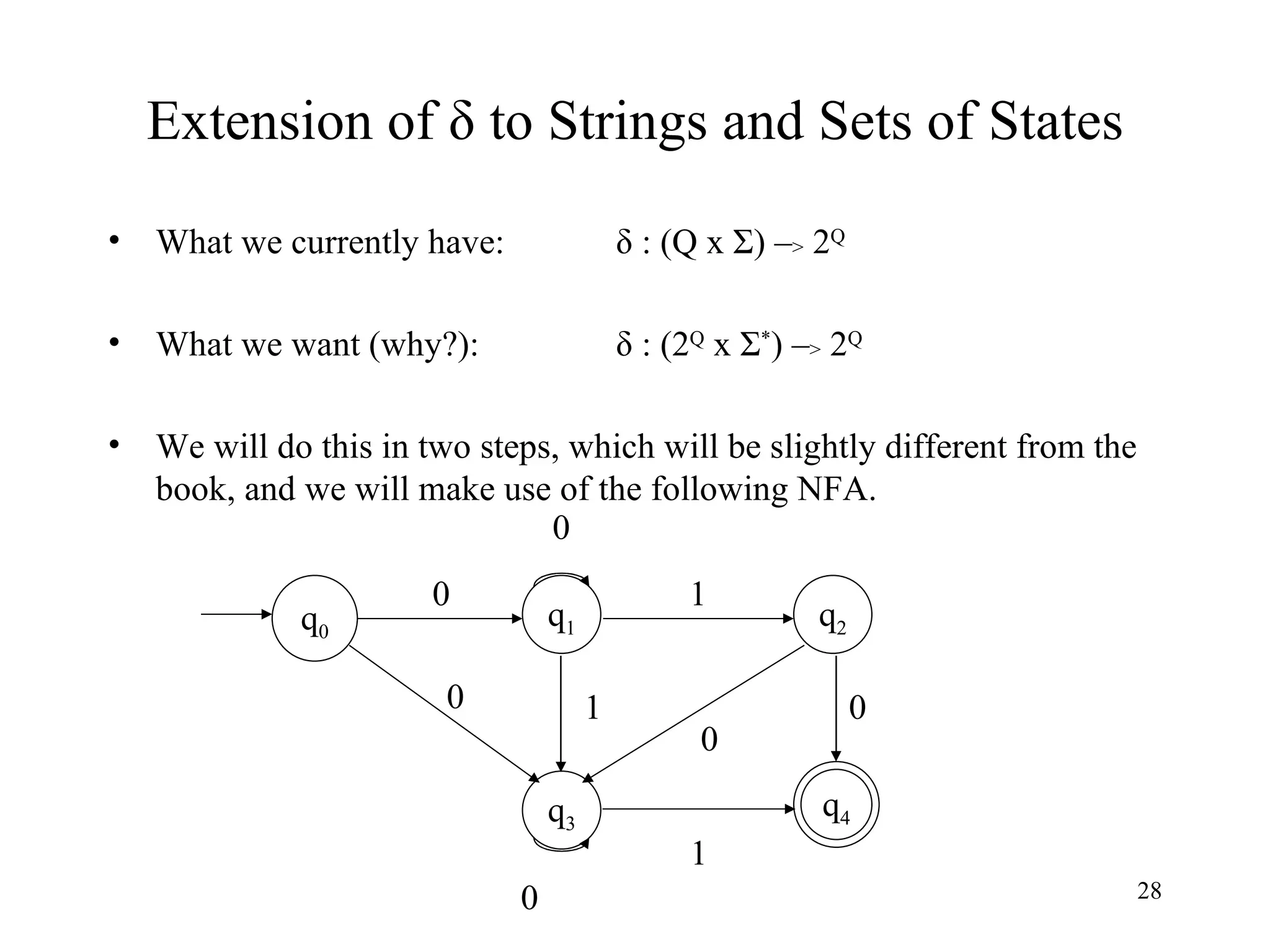
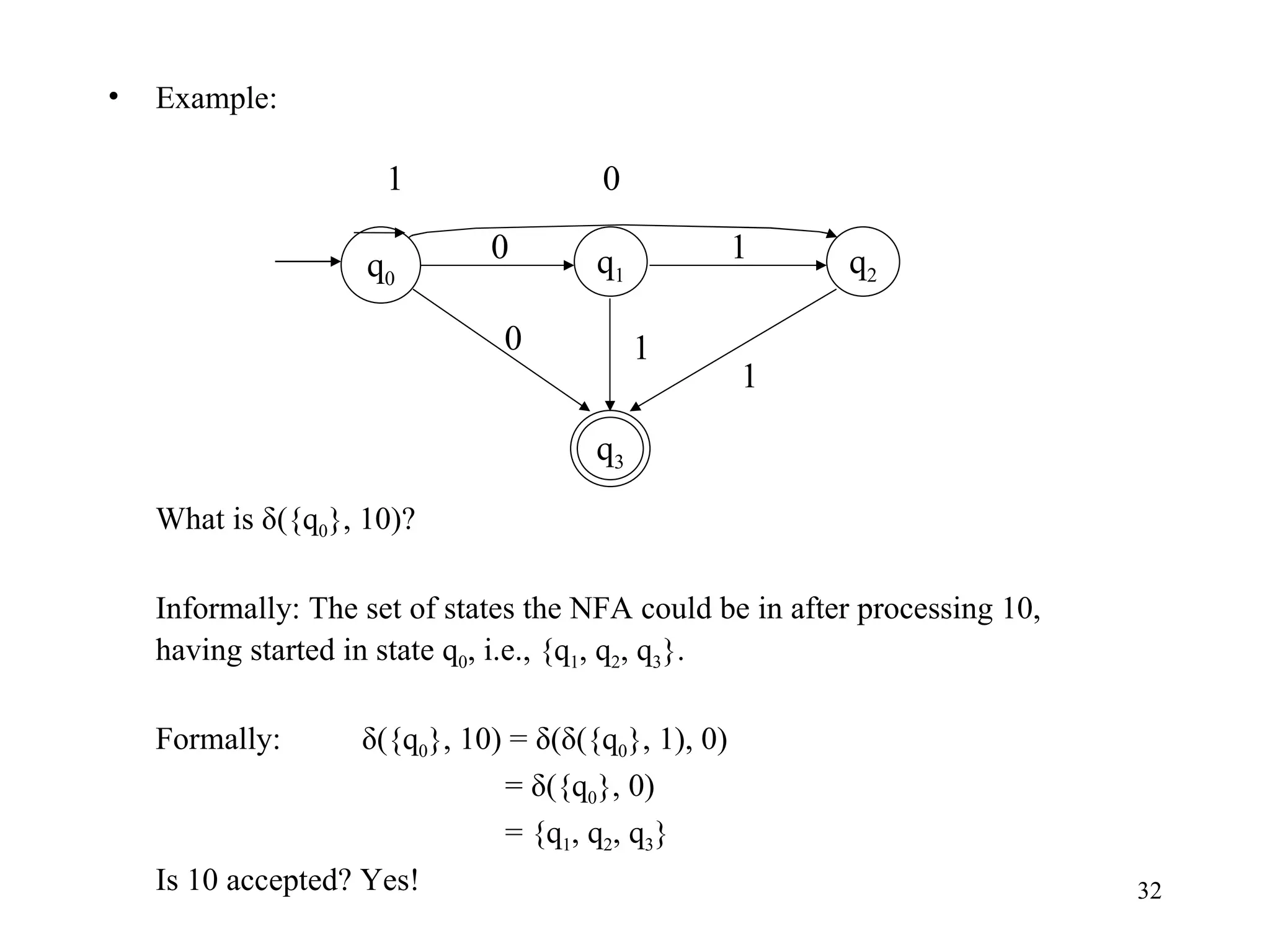
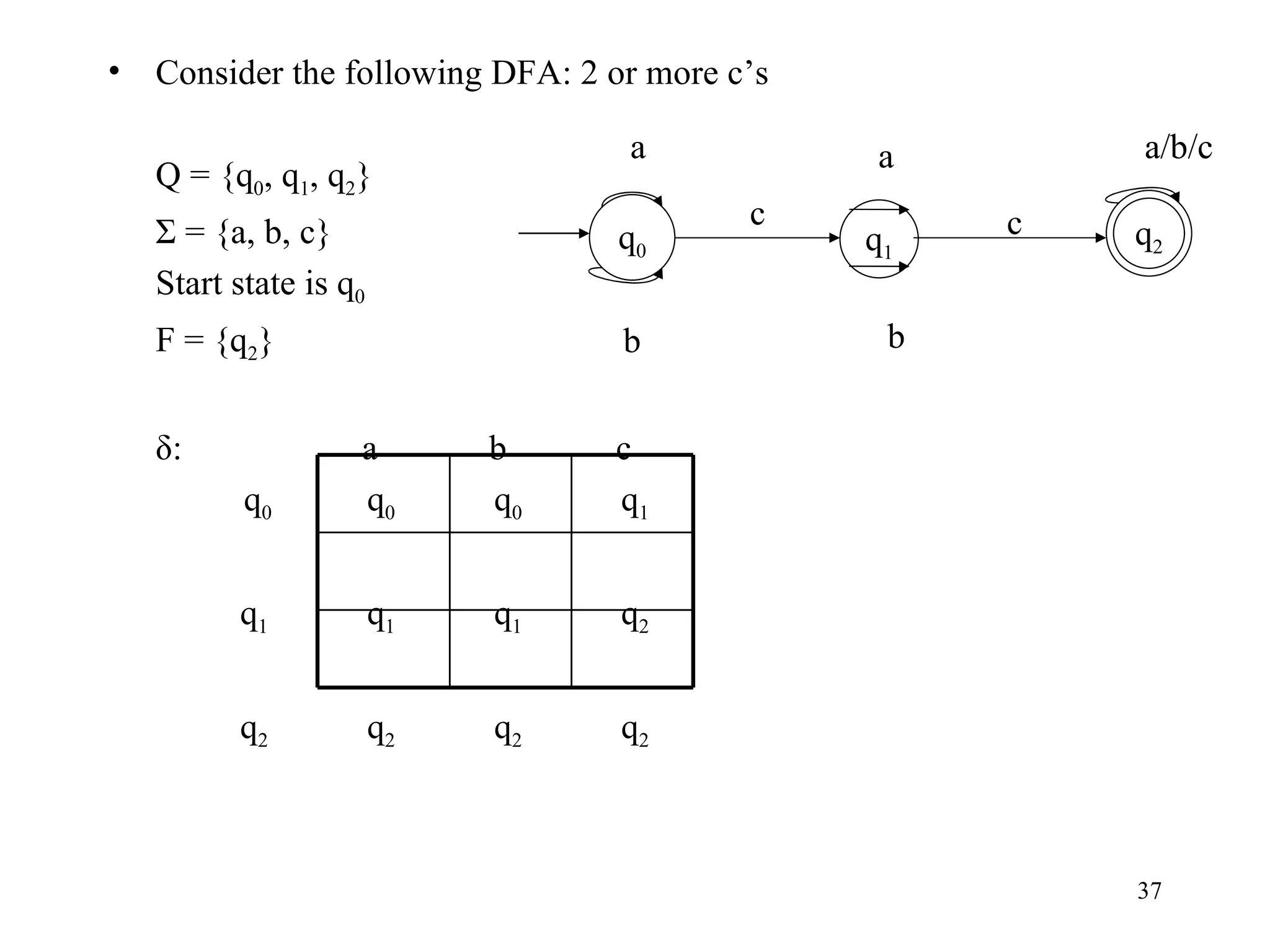
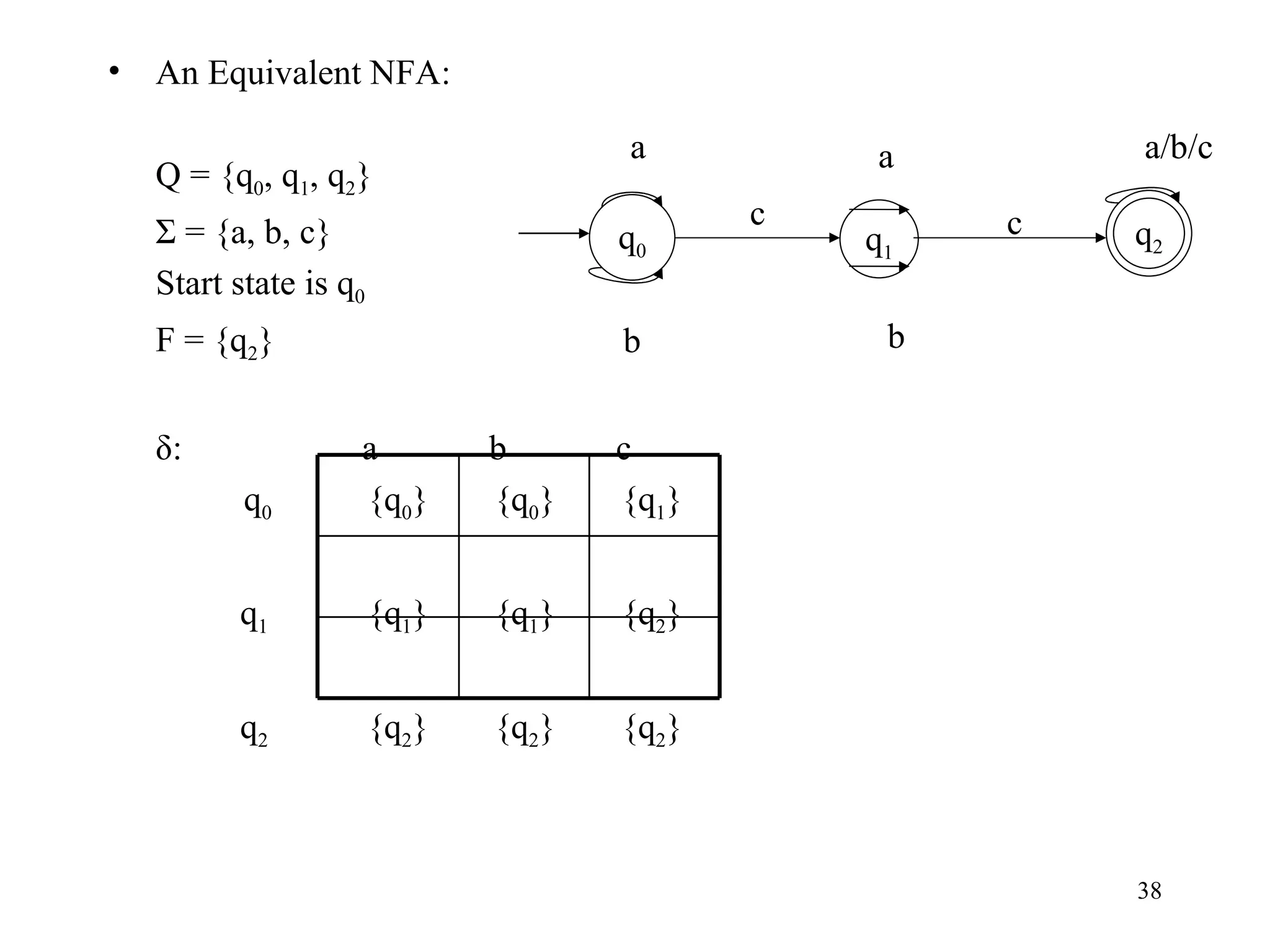
The document discusses Deterministic Finite Automata (DFAs) and Nondeterministic Finite Automata (NFAs). It defines the key components of a DFA/NFA including states, alphabet, transition function, initial state, and accepting states. It provides examples of DFAs and NFAs and their transition diagrams. It also discusses how to determine if a string is accepted by a DFA/NFA and the language recognized by a DFA/NFA.

























































![Flat [ www.uandi star.org]](https://cdn.slidesharecdn.com/ss_thumbnails/flatwww-uandistar-org-120210203512-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![Co [uandi star.org]](https://cdn.slidesharecdn.com/ss_thumbnails/couandistar-org-120210203418-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![Dbms[uandi star.org]](https://cdn.slidesharecdn.com/ss_thumbnails/dbmsuandistar-org-120210203457-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















