Downloaded 28 times








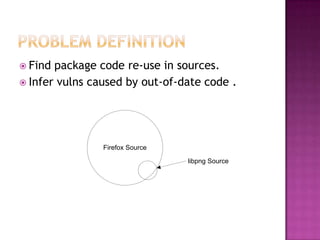


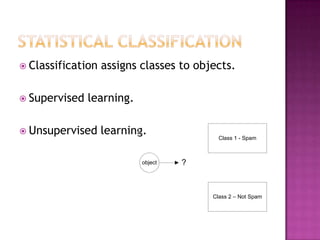





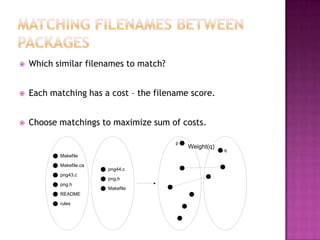


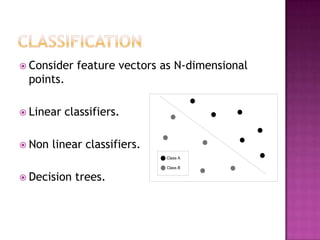

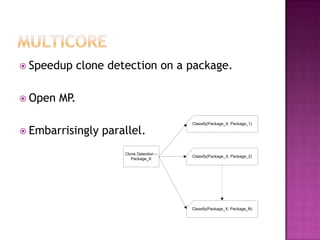
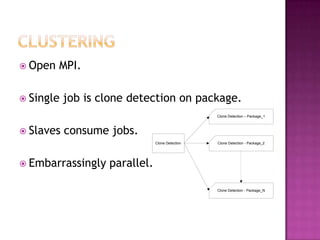












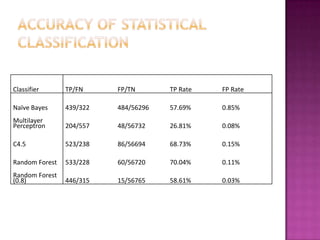

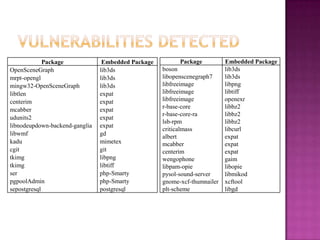









This document discusses automatically detecting package clones and inferring security vulnerabilities. It proposes using statistical classification techniques to identify cloned code between software packages. Features like common filenames, hashes, and fuzzy content would be used for classification. Packages found to share code could then be checked against known vulnerabilities to see if any vulnerabilities may affect the cloned code. The approach aims to scale the analysis to thousands of packages and help identify vulnerabilities in packages with cloned code that may not otherwise be tracked.








































![[Dagstuhl Seminar 17281] Similarity Calculation Method for Binary Executables](https://cdn.slidesharecdn.com/ss_thumbnails/dagstuhlseminar17281-200531030542-thumbnail.jpg?width=640&height=640&fit=bounds)
![Similarity of Source Code in the Presence of Pervasive Modifications [SCAM'16]](https://cdn.slidesharecdn.com/ss_thumbnails/scam2016short-161017154943-thumbnail.jpg?width=640&height=640&fit=bounds)






































