This document discusses techniques for efficiently finding similar items in large datasets, including near-neighbor search, entity resolution, and document similarity. It introduces the concept of minhashing as a method to represent datasets in a way that allows efficient comparison of similarities. Minhashing works by using hash functions to map items to signatures in a way that preserves estimates of Jaccard similarity between items.






![Multidimensional Indexes Don’t Work New face: [6,14,…] 0-4 5-9 10-14 . . . Dimension 1 = Surely we’d better look here. Maybe look here too, in case of a slight error. But the first dimension could be one of those that is not close. So we’d better look everywhere!](https://image.slidesharecdn.com/nn-100826153718-phpapp02/85/Nn-6-320.jpg)













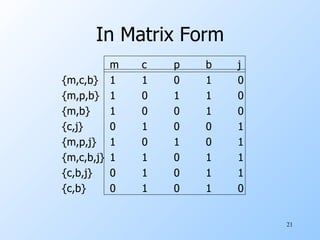











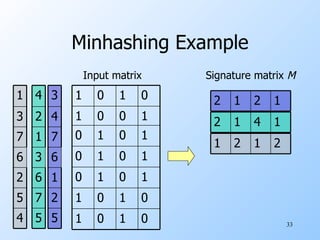


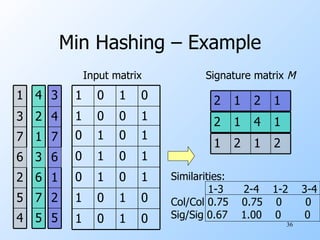
![Minhash Signatures Pick (say) 100 random permutations of the rows. Think of Sig (C) as a column vector. Let Sig (C)[i] = according to the i th permutation, the number of the first row that has a 1 in column C .](https://image.slidesharecdn.com/nn-100826153718-phpapp02/85/Nn-37-320.jpg)



































































