





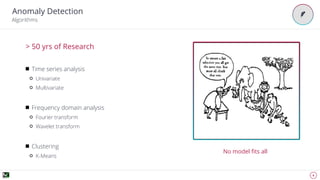
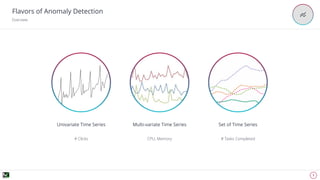

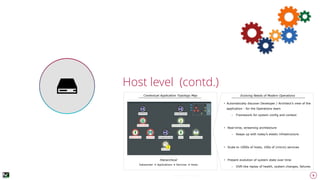




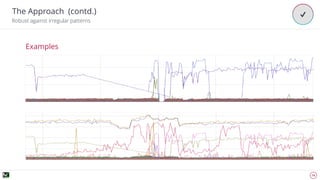





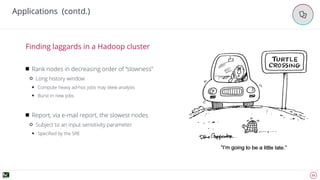
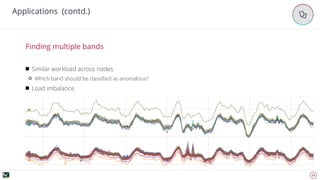
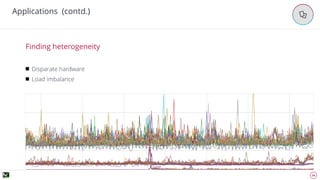
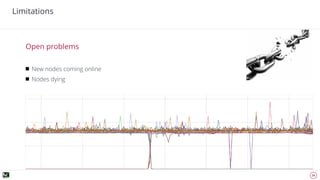
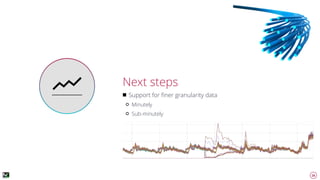



The document discusses advanced techniques for anomaly detection in high-volume data environments, specifically focusing on real-time information consumption and performance monitoring across microservices and clusters. It outlines a scalable, algorithmic approach for identifying performance regressions and discrepancies in system behavior, leveraging historical time series analysis. The presentation also details applications in production environments, challenges in data consistency, and plans for future enhancements in data granularity and classification.




























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






