































The document outlines the new features and enhancements in Splunk Enterprise and Cloud 6.4, focusing on improved storage efficiency, security, and interactive visualizations. Key features include a significant reduction in historical data storage costs through tsidx file management, various improvements to platform management, and the introduction of custom visualizations for data analysis. Additionally, it highlights essential search commands that facilitate better data handling and insights.
Overview of new features and enhancements introduced in the Splunk framework, including personal background of Mike Walker.
Outline of the presentation discussing new features in version 6.4, TCO, platform security, and search command improvements.
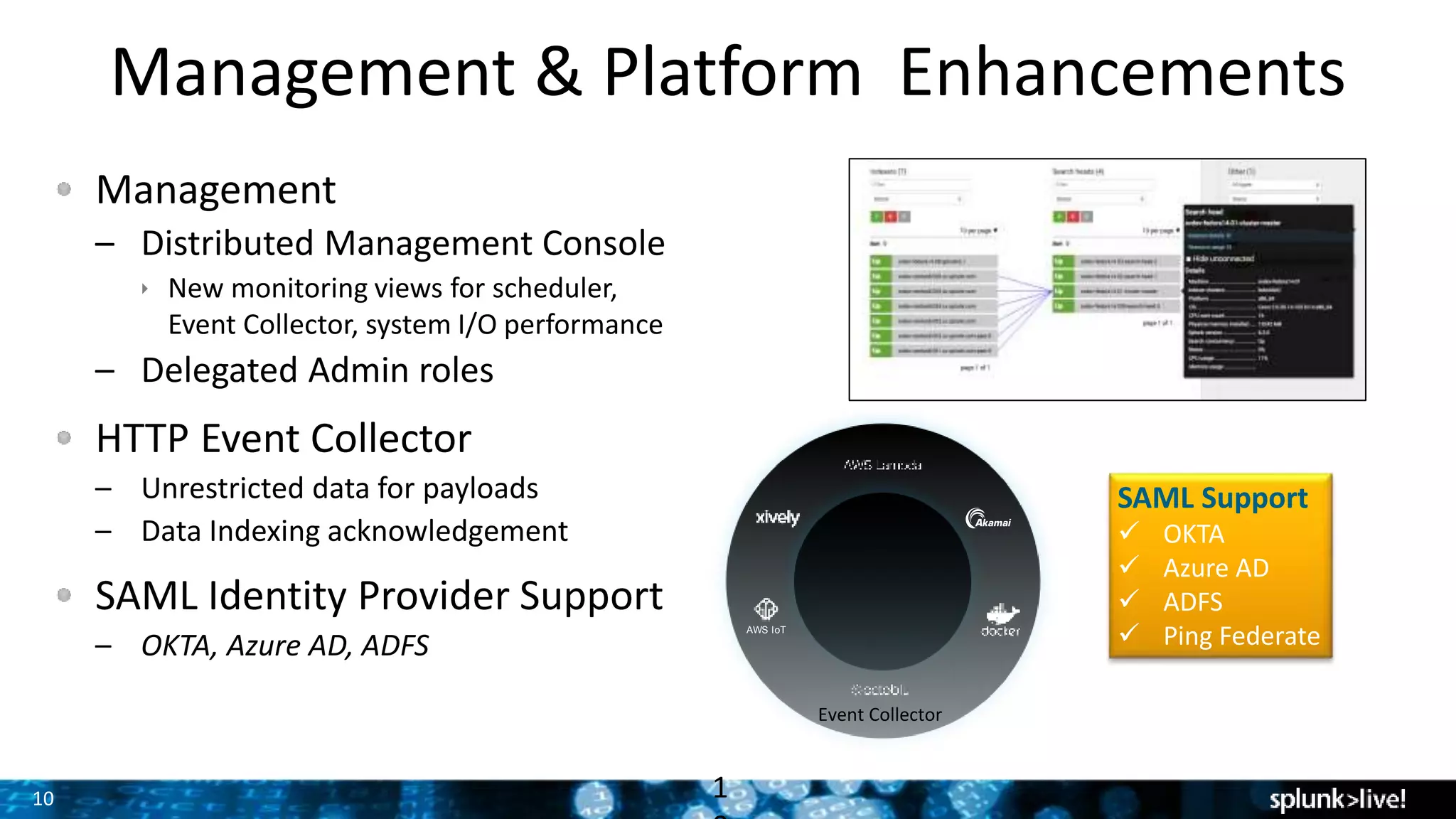
Introduction to Splunk Enterprise & Cloud 6.4 features focusing on storage cost reduction (up to 40%) and security enhancements, including DMC and SSO options.
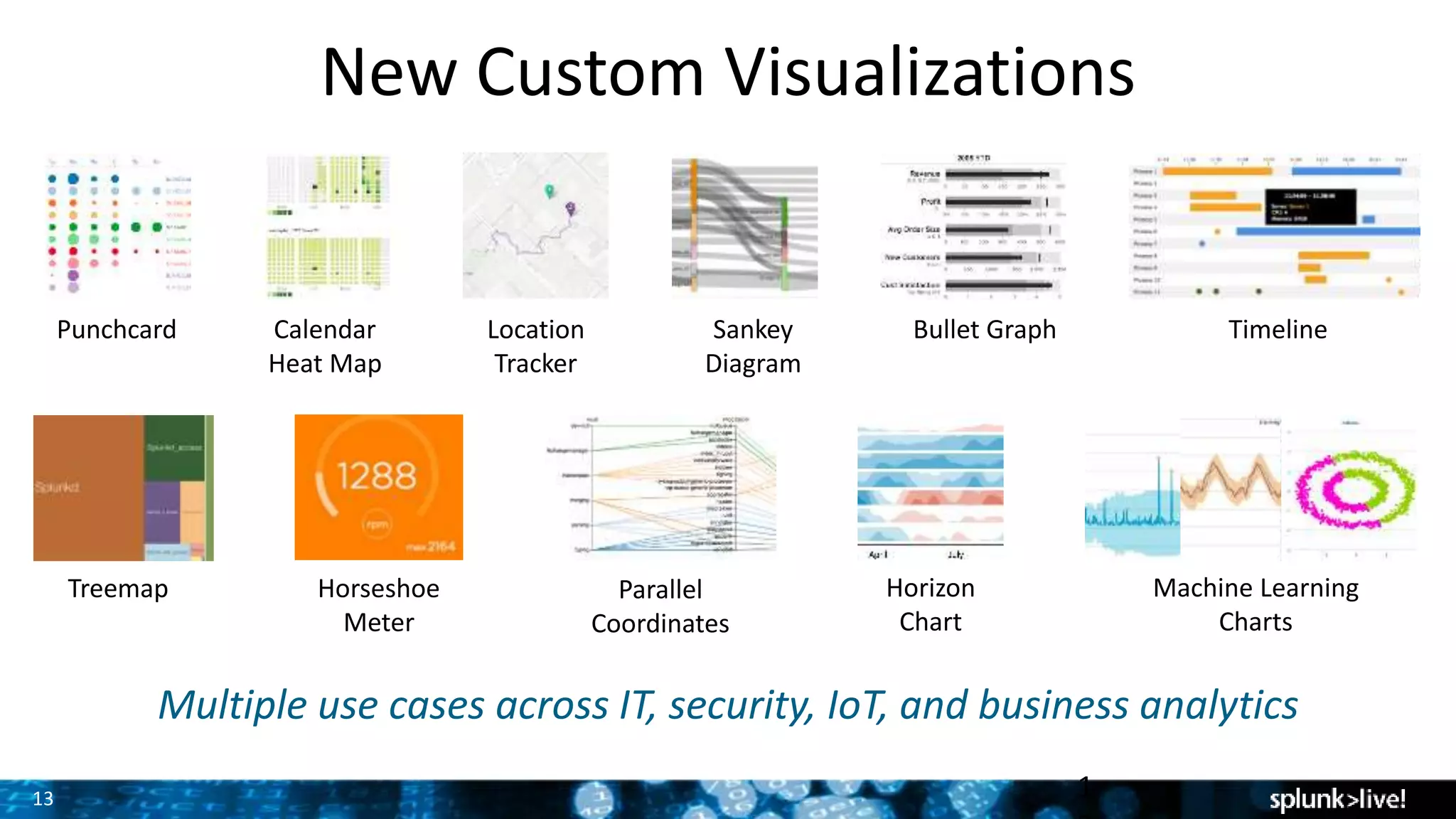
Introduction of 15 new interactive visualizations for various applications such as IT and business analysis.
Event sampling optimizations and enhancements to the predict command that improves forecasting with performance enhancements by 80-100X.
Capabilities of Splunk's Search Processing Language, including searching, filtering, and statistical analysis using five essential commands.
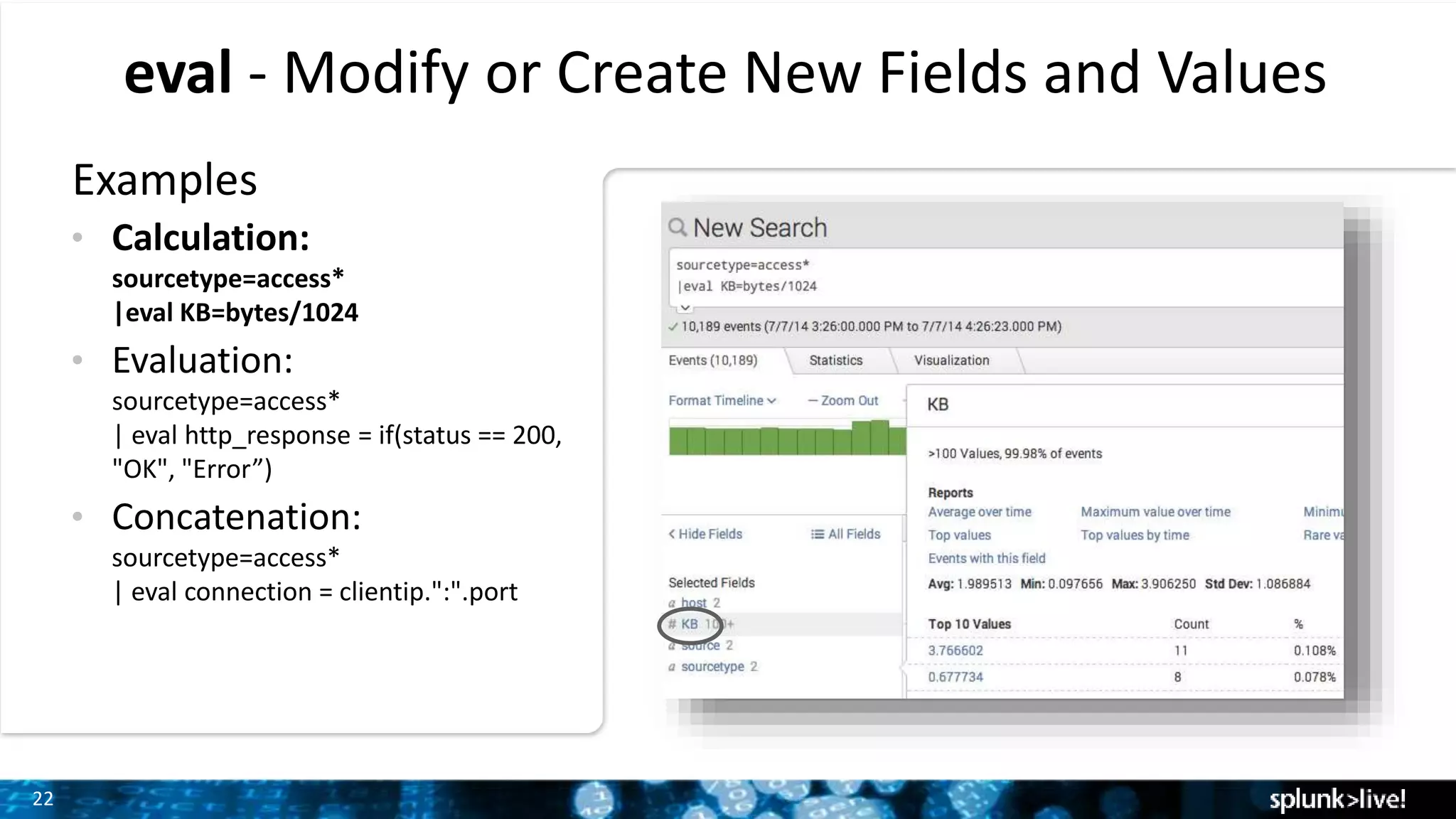
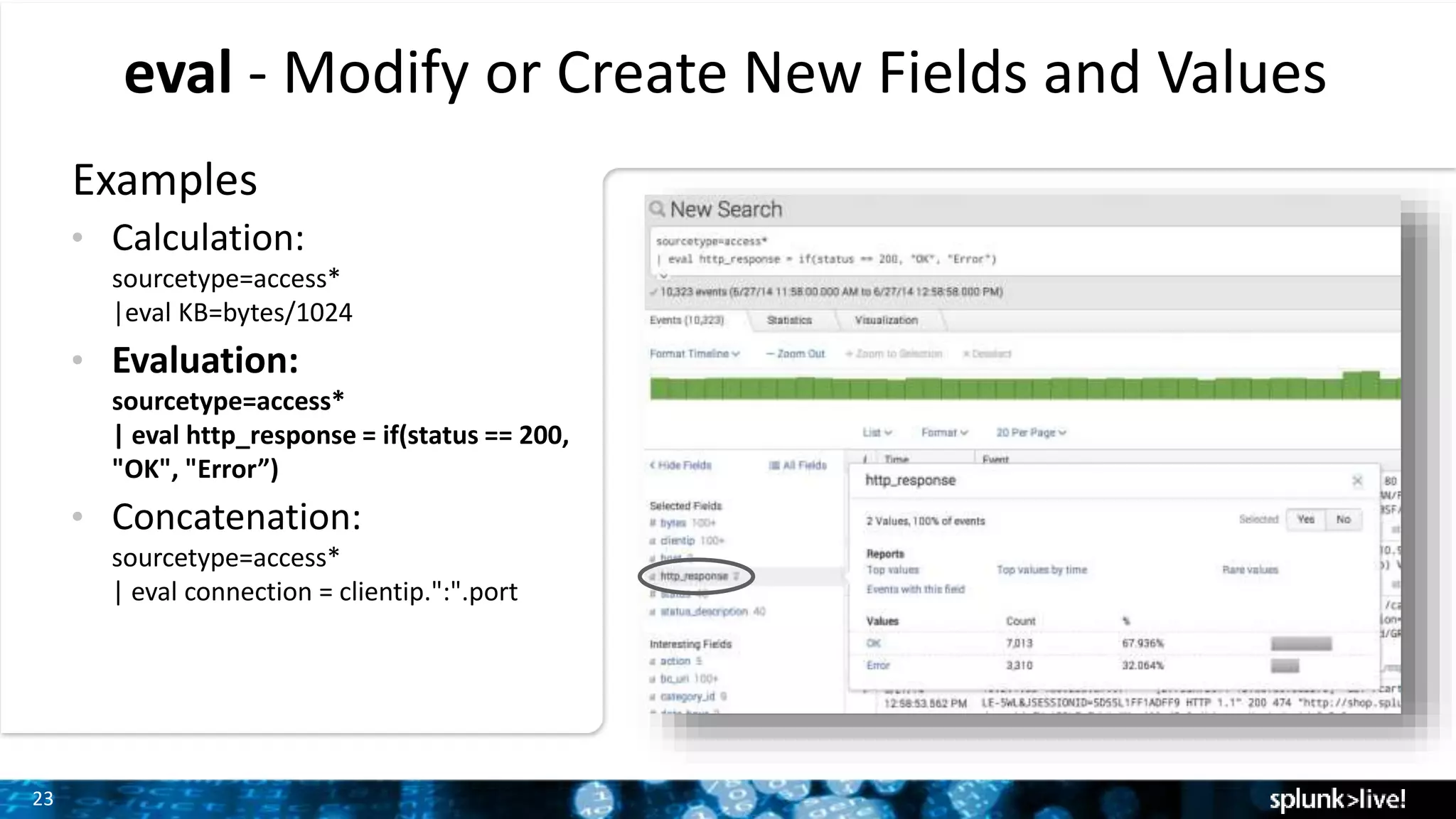
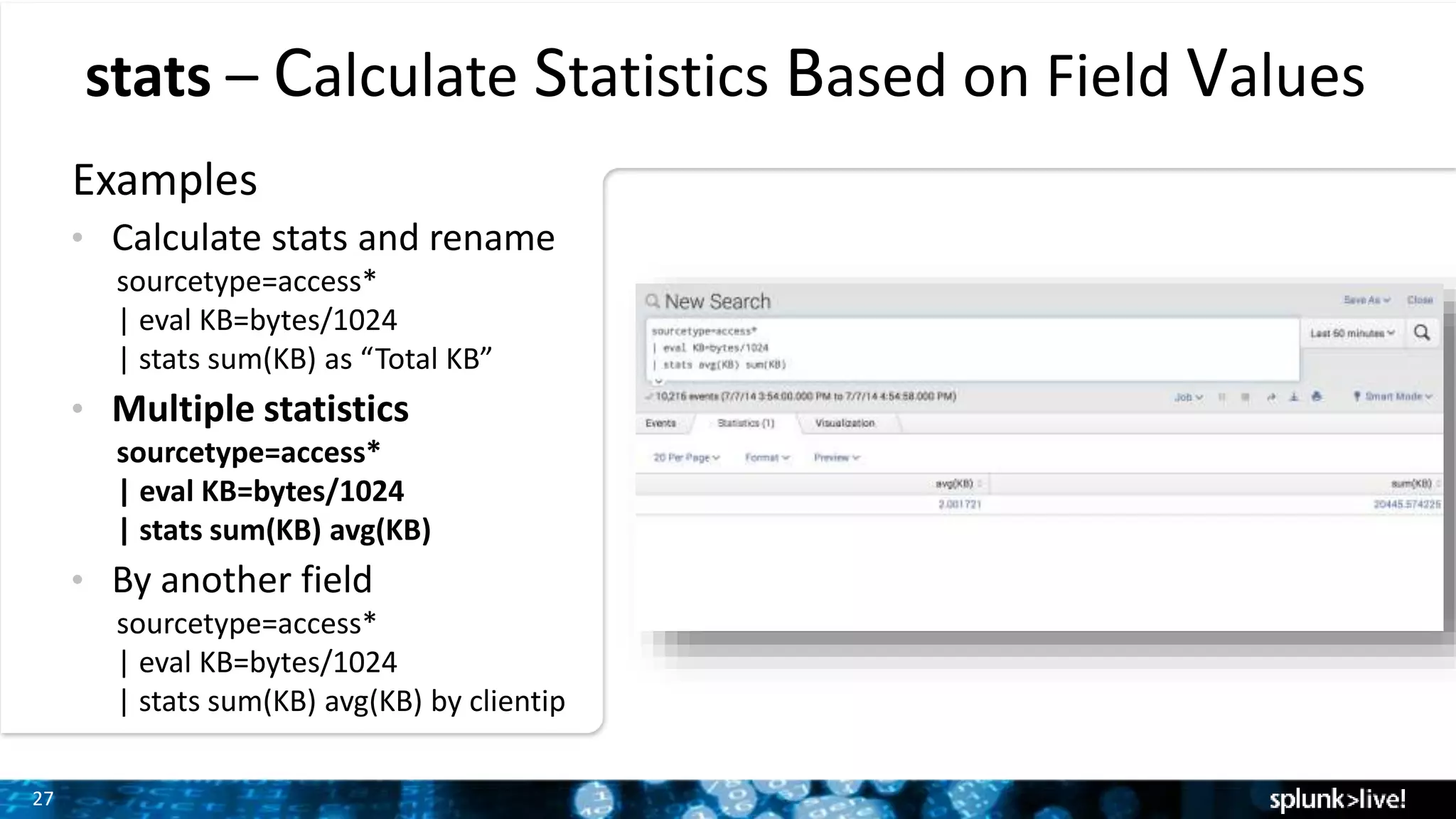
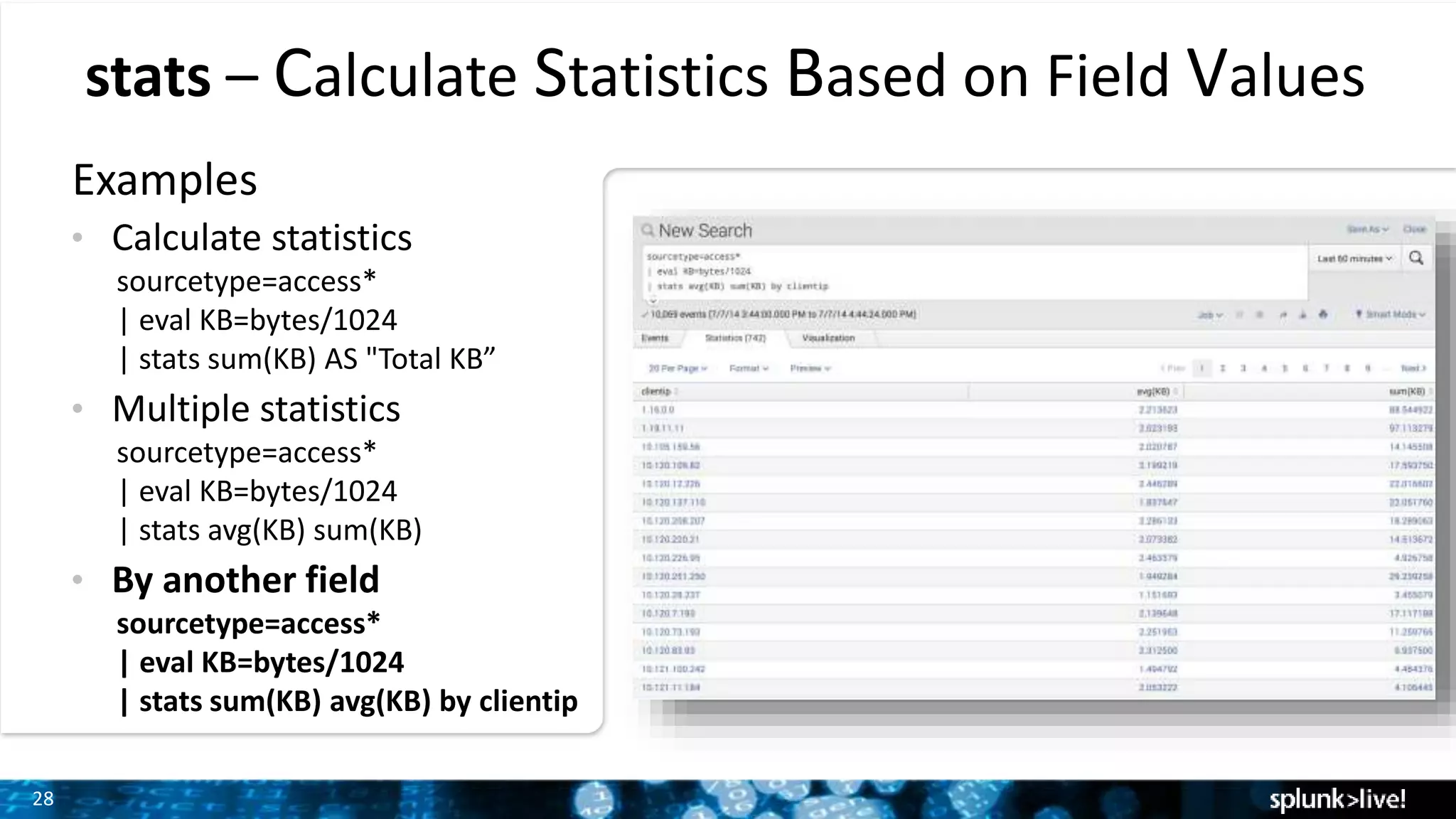
Demonstration of how to modify fields and calculate statistics using eval and stats commands with various examples.
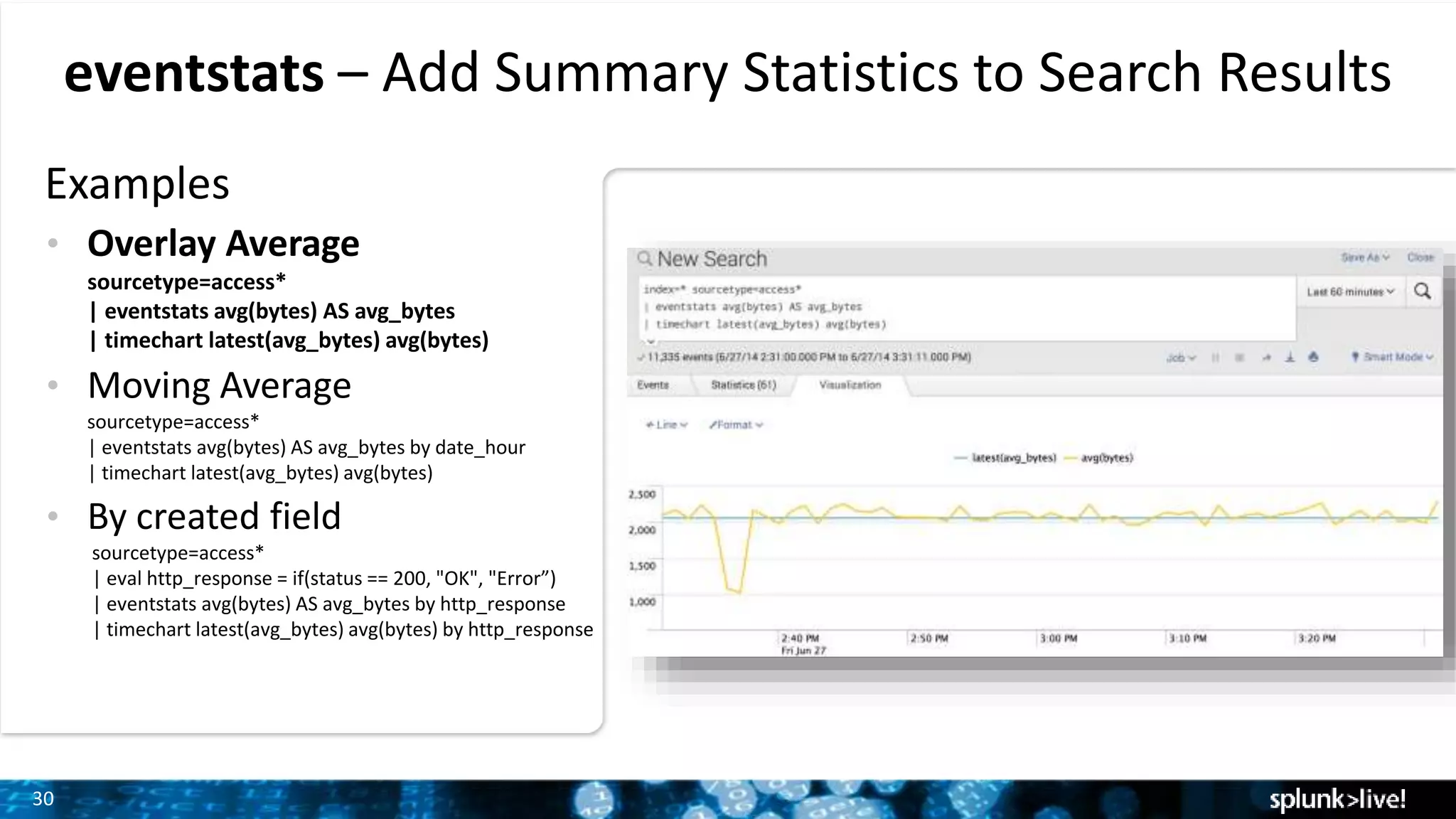
Explains how to add summary statistics to search results using eventstats command with practical examples.
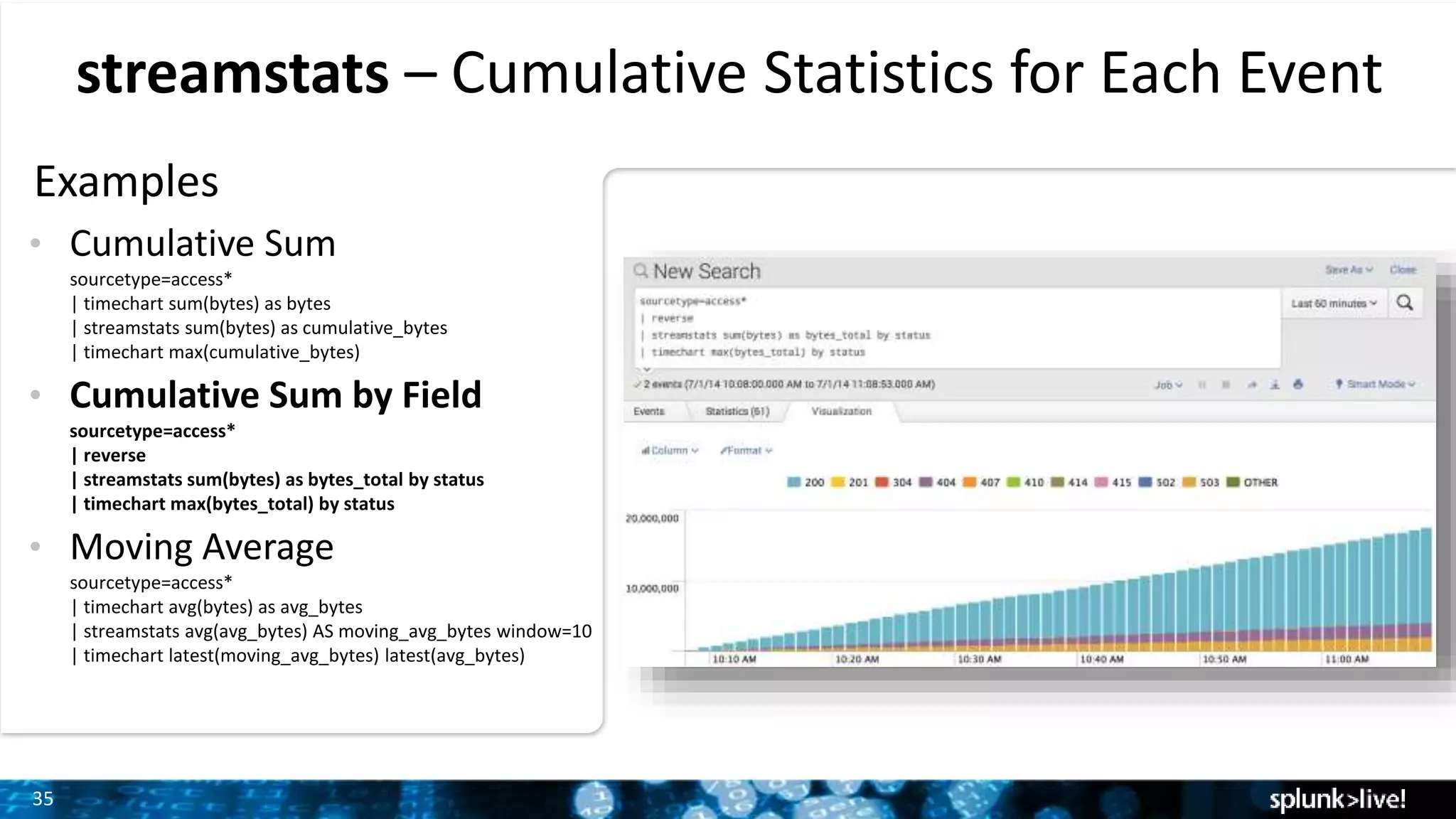
Cumulative statistics generation for each event using streamstats command with multiple examples provided.
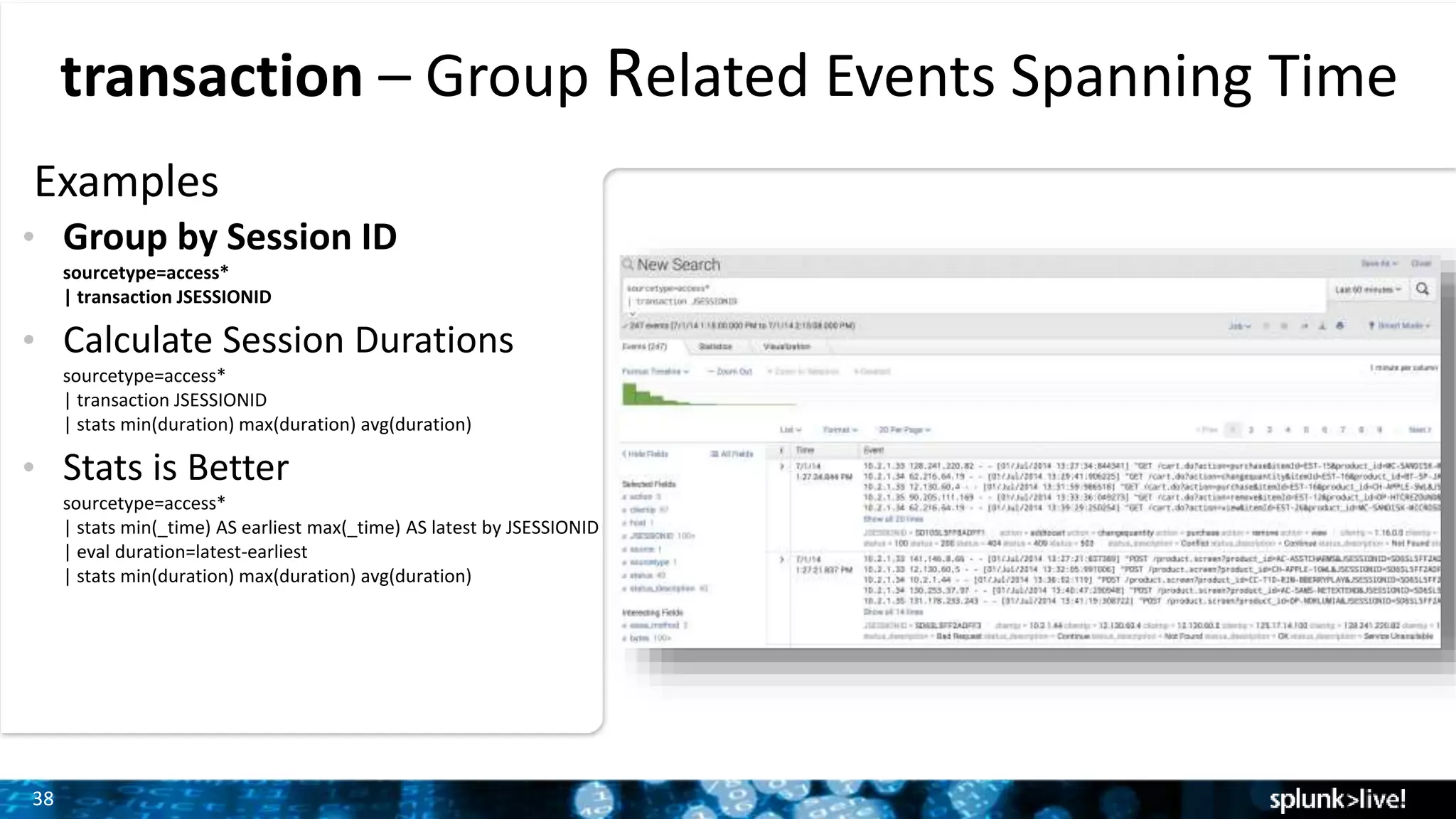
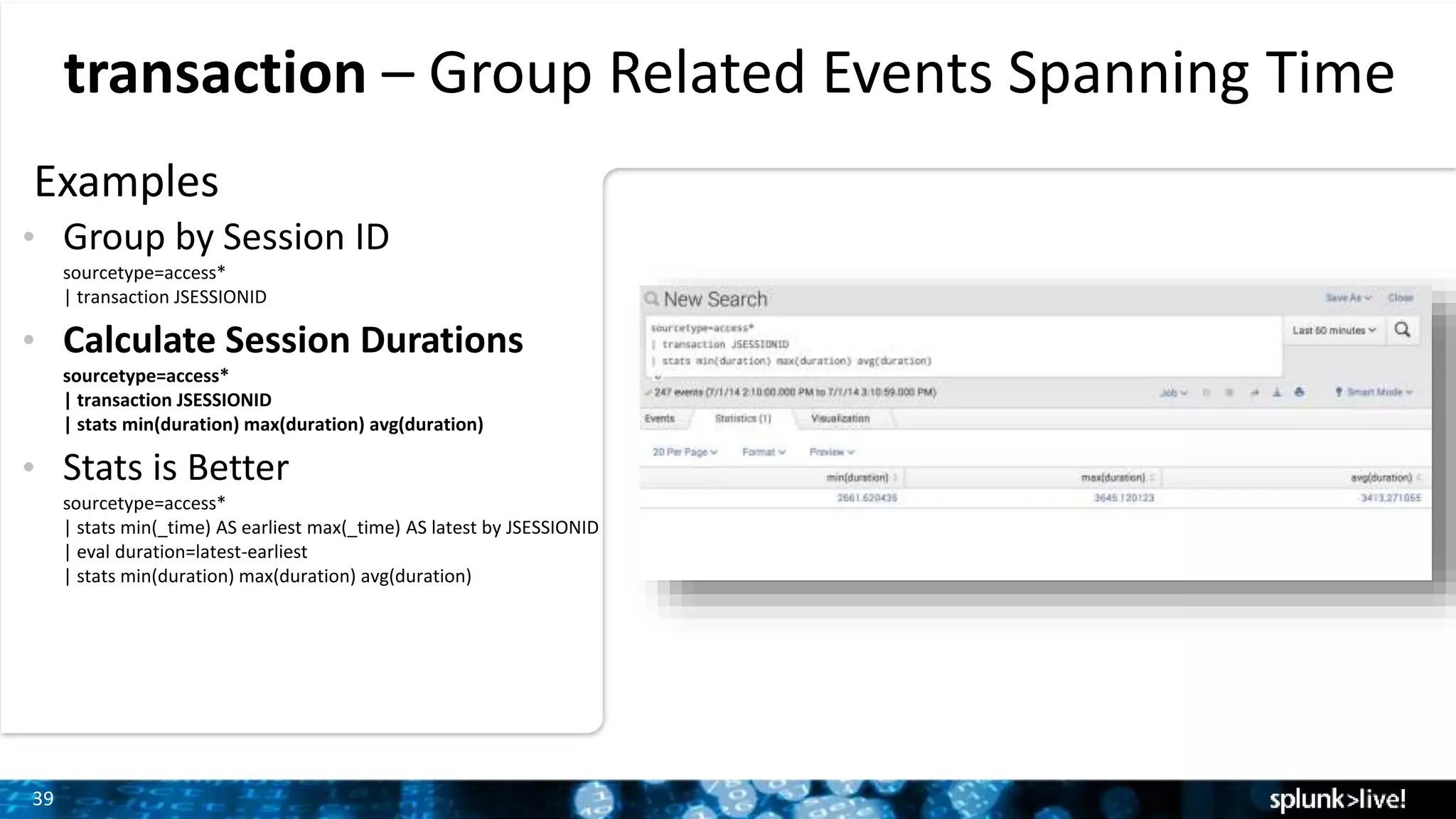
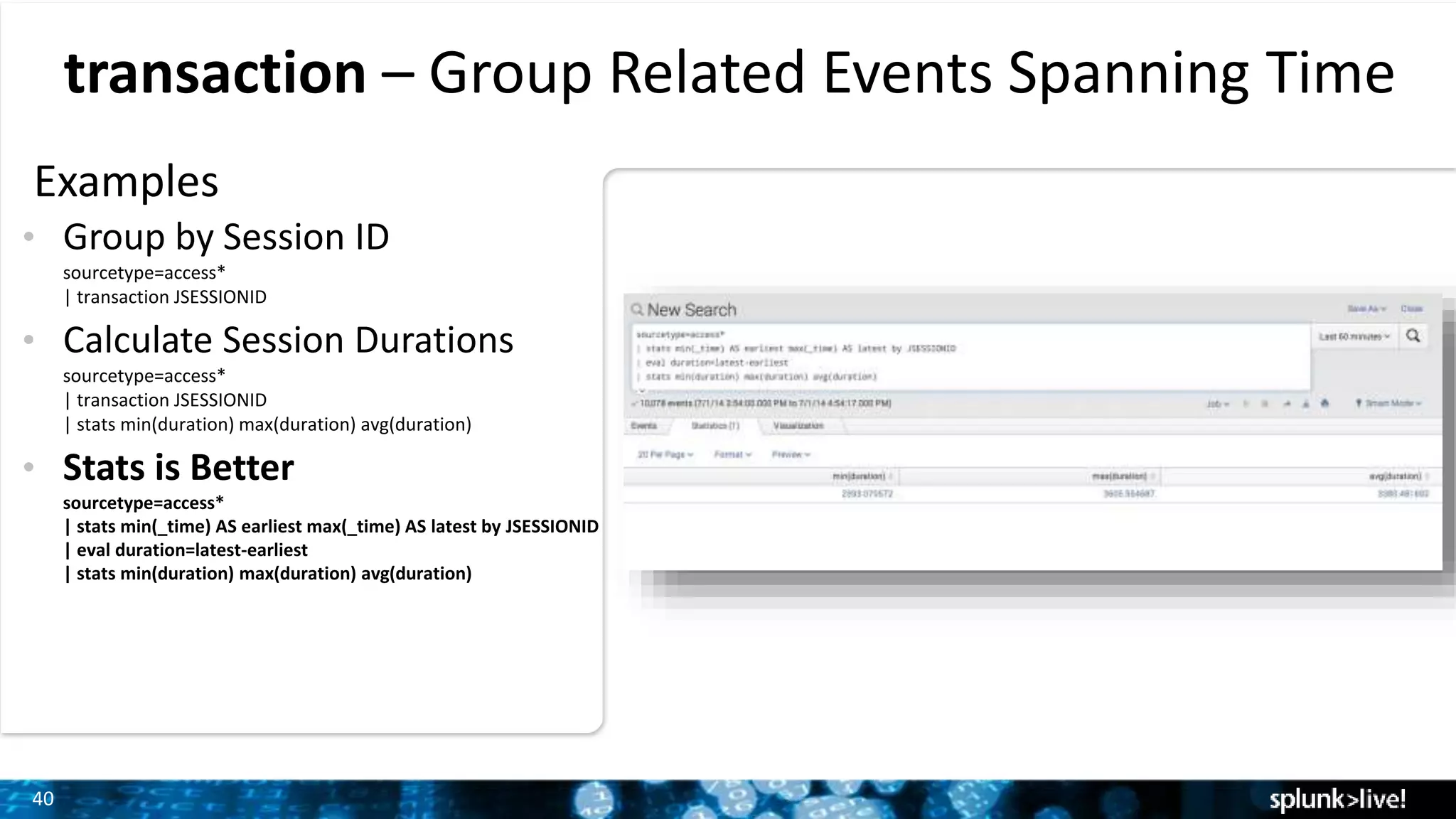
Grouping related events over time with transaction command and demonstrating how to calculate session durations.
Encouragement to become proficient with Splunk's search commands through practice and reference to online resources.
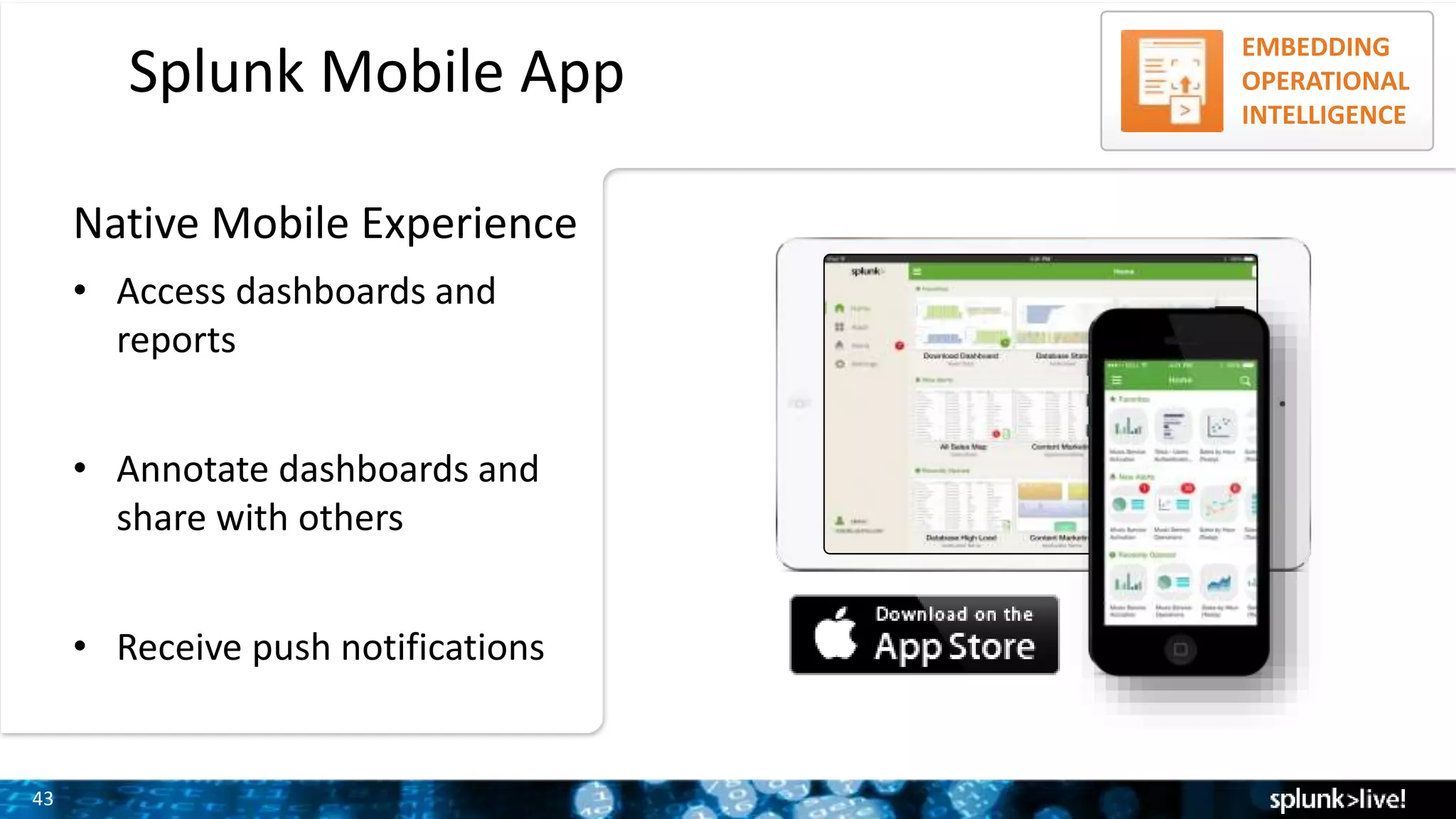
Overview of the capabilities offered by the Splunk Mobile App, including dashboard access and annotation features.
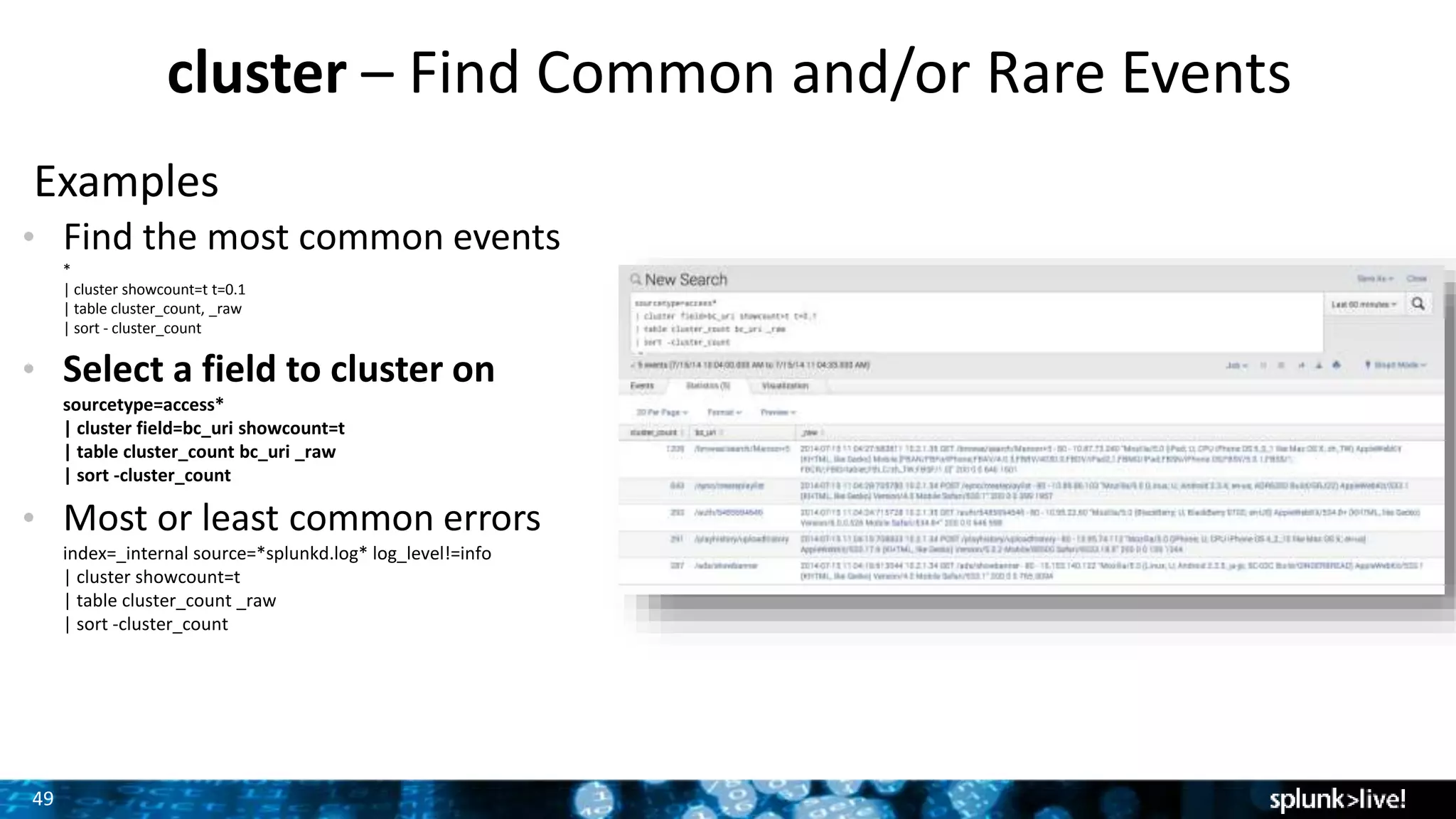
Implementation of the cluster command to identify common and rare events with various operational examples.










































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



