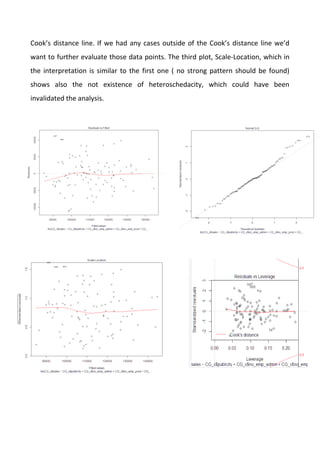
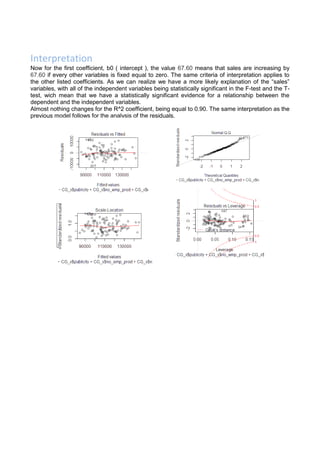
The document describes a multiple regression model that was constructed to best explain sales using data from a file. The model's formal equation shows sales as a function of several independent variables including publicity, number of employees in administration and production, expenditure on research and development, income, seniority, number of products, training start time, and training period. The results of the analysis show that publicity, number of employees in production, expenditure on R&D, and training period are significant predictors of sales in the model.


![T
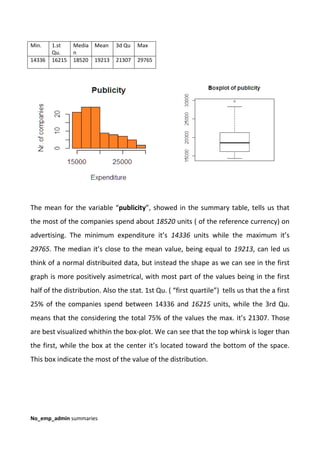
The variable “no_emp_admin” the mean is located around the 15.29 value, which
correspond to an average of 15 administrator working in the company. As the
previous min. and max. value tells us only the extreme points. The median it’s close
to the mean value, being equal to 15. Looking at the histogram and also with the
help of these basical statistics we note, by the way, that the shape of the
distribution is normal but we can’t say this variable is normally distributed because
the mode, which is 14 here [<- table(CG_x$no_emp_admin)], don’t correspond to
the mean and the median. The interpretation of the stat. 1st
Qu. and the 3rd
Qu. it’s
similar to the previous variable, but being more centered to the middle of the space.
We still note an outlier ( a very high or very low value) after the top whisker.
No_emp_prod summaries
Min. 1.st
Qu.
Media
n
Mean 3d Qu Max
9.00 13.00 15.00 15.29 17.00 24.00](https://image.slidesharecdn.com/finalprojectstudentcarminegelorminiwithcosminimbrisca-200927110543/85/Final-project-student-carmine-gelormini-3-320.jpg)


![We will start now to look at the coefficients of correlation to see. These tells us
about the association between two variables. Remembering that association doesn’t
mean causation, one should look for the high scores on these coefficients for the
starting point for find pattern of relationships. This coefficient goes by -1 to +1. A
score of 0 or around 0 indicate no correlation, while from the 0 towards the two
extreme, a firstly weak and then high correlation.
Placed side by side are also the scatter-plot showing the distribution of the
points/unit on the two dimentional space of the correlated variables.
> cor(CG_x$sales,CG_x$publ
icity)
[1] 0.7163831
There is a strong positive
correlation between the tw
o variables, that means th
at when publicity increase
also sales are lifting up.
> cor(CG_x$sales,CG_x$no_emp_
admin)
[1] 0.1124151
There is no correlation. This means
that when sales increase the other
variables don’t have a unique way of
changing.](https://image.slidesharecdn.com/finalprojectstudentcarminegelorminiwithcosminimbrisca-200927110543/85/Final-project-student-carmine-gelormini-11-320.jpg)
![cor(CG_x$sales,CG_x$no_emp_
prod)
[1] -0.07883389
There is no correlation. Even looking
at the plot, every point is spread
almost randomly and there are not
graphically recognising patterns.
> cor(CG_x$sales,CG_x$rd)
[1] 0.5212227
This value indicated a weak positive
correlation, meaning that when rd
increases sales also increase with a
slightly slope.
cor(CG_x$sales,CG_x$seniority
)
[1] -0.06973496
The variables are not correlated.](https://image.slidesharecdn.com/finalprojectstudentcarminegelorminiwithcosminimbrisca-200927110543/85/Final-project-student-carmine-gelormini-12-320.jpg)
![Interpretation of the results:
Call:
lm(formula = CG_x$sales ~ CG_x$publicity + CG_x$no_emp_admin +
CG_x$no_emp_prod + CG_x$rd + CG_x$income + CG_x$seniority +
CG_x$nr_prod + CG_x$train_start + CG_x$train_per)
Residuals:
Min 1Q Median 3Q Max
-10585.3 -2816.7 -25.5 2267.0 11254.3
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4349.1361 6630.2751 -0.656 0.51355
CG_x$publicity 3.1180 0.1284 24.291 < 2e-16 ***
CG_x$no_emp_admin -8.2732 143.4006 -0.058 0.95412
CG_x$no_emp_prod 272.3962 101.3058 2.689 0.00856 **
CG_x$rd 37.8190 2.2820 16.572 < 2e-16 ***
CG_x$income 0.3549 0.5139 0.691 0.49160
CG_x$seniority 50.6372 47.5523 1.065 0.28981
CG_x$nr_prod 14.1881 170.2947 0.083 0.93379
CG_x$train_startYes 647.1205 1108.5769 0.584 0.56087
CG_x$train_perMonthly 13861.3285 1941.1590 7.141 2.42e-10 ***
CG_x$train_perTwice yearly 6253.4470 1135.3762 5.508 3.48e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4509 on 89 degrees of freedom
Multiple R-squared: 0.9075, Adjusted R-squared: 0.8971
F-statistic: 87.33 on 10 and 89 DF, p-value: < 2.2e-16
2.1 results of the analysis (from R output)
> cor(CG_x$sales,CG_x$nr_pr
od)
[1] -0.2052322
Not correlated.](https://image.slidesharecdn.com/finalprojectstudentcarminegelorminiwithcosminimbrisca-200927110543/85/Final-project-student-carmine-gelormini-13-320.jpg)