Downloaded 22 times





![Formal Text Informal Text
Closed Domain
Open Domain [Roitman et al. 2012][Kumaran and Allan 2004]
[Lampos and Cristianini 2012]
[Becker et al. 2011]
[Wang et al. 2012]
[Ritter et al. 2012]
Related Work on Event Extraction](https://image.slidesharecdn.com/extracting-city-traffic-events-from-social-streams-151209195518-lva1-app6891/75/Extracting-City-Traffic-Events-from-Social-Streams-9-2048.jpg)




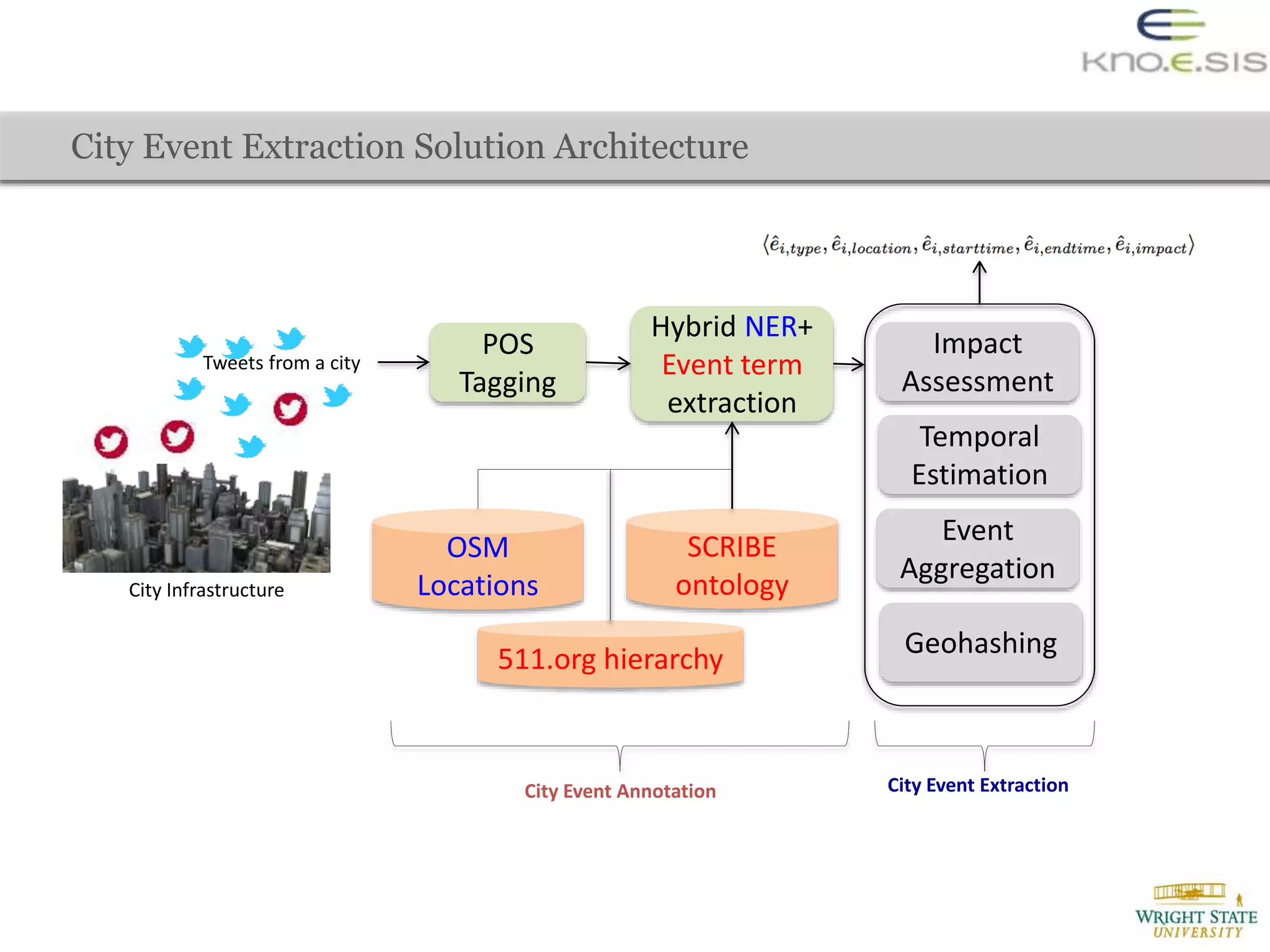
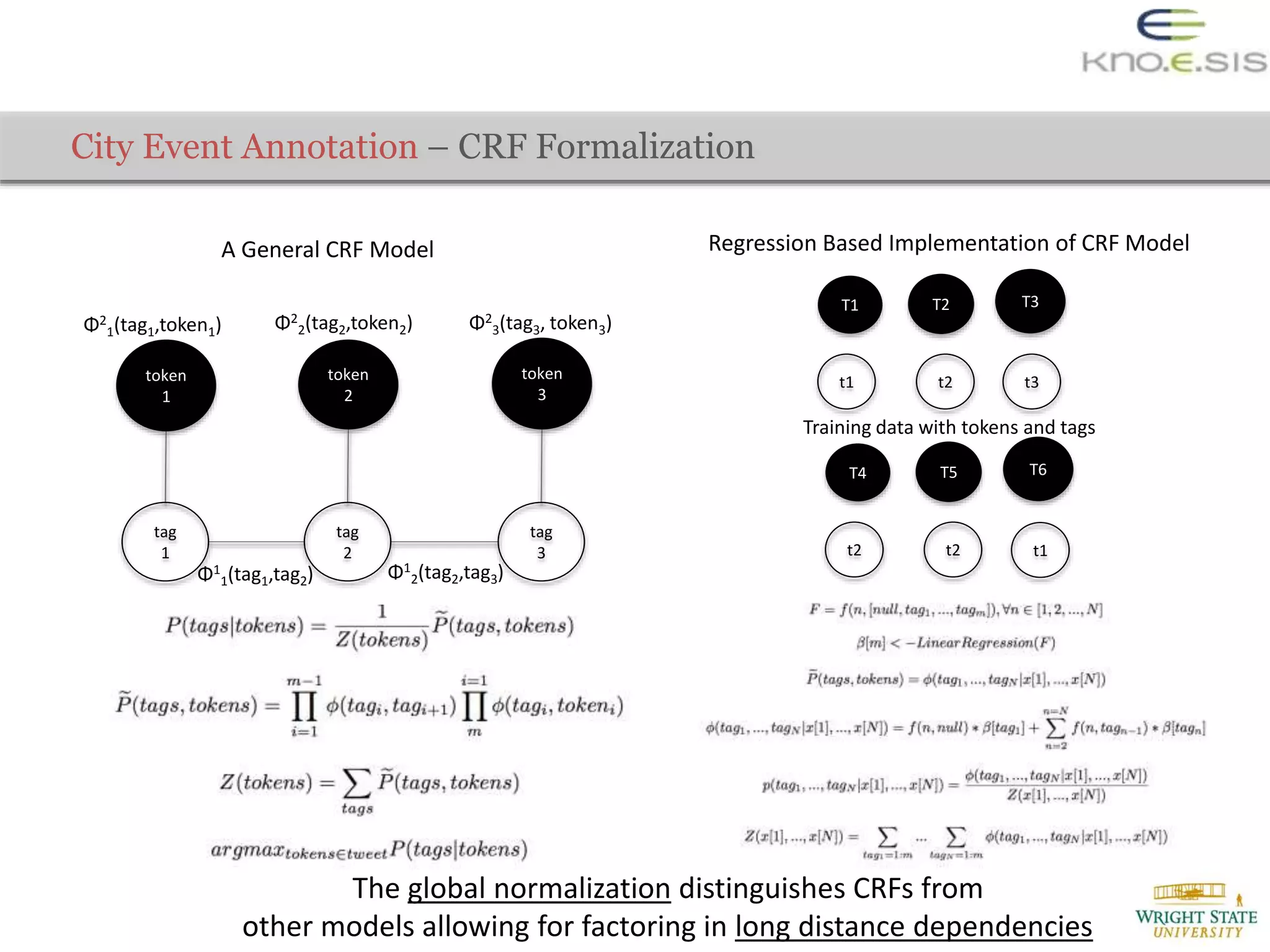

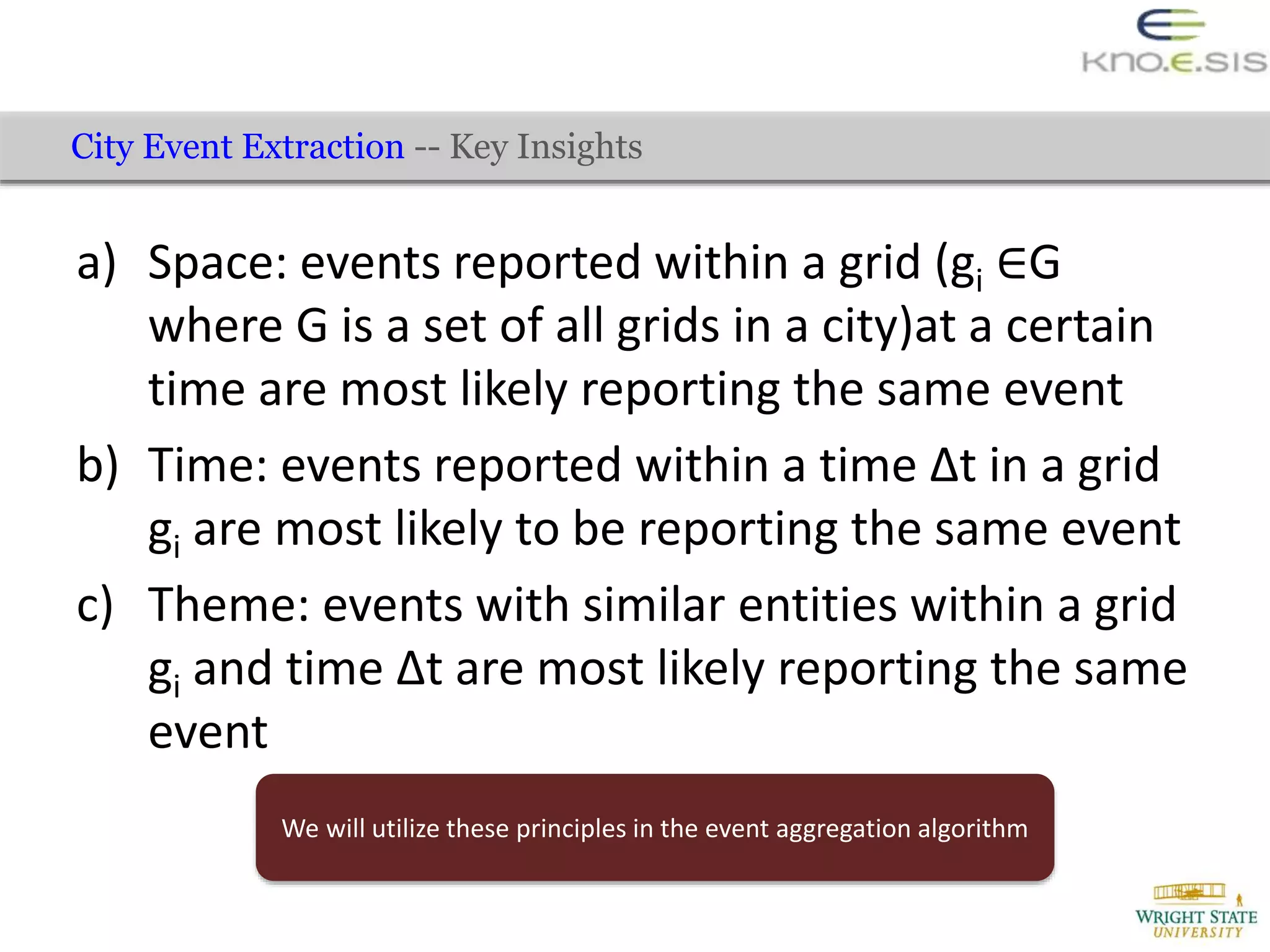
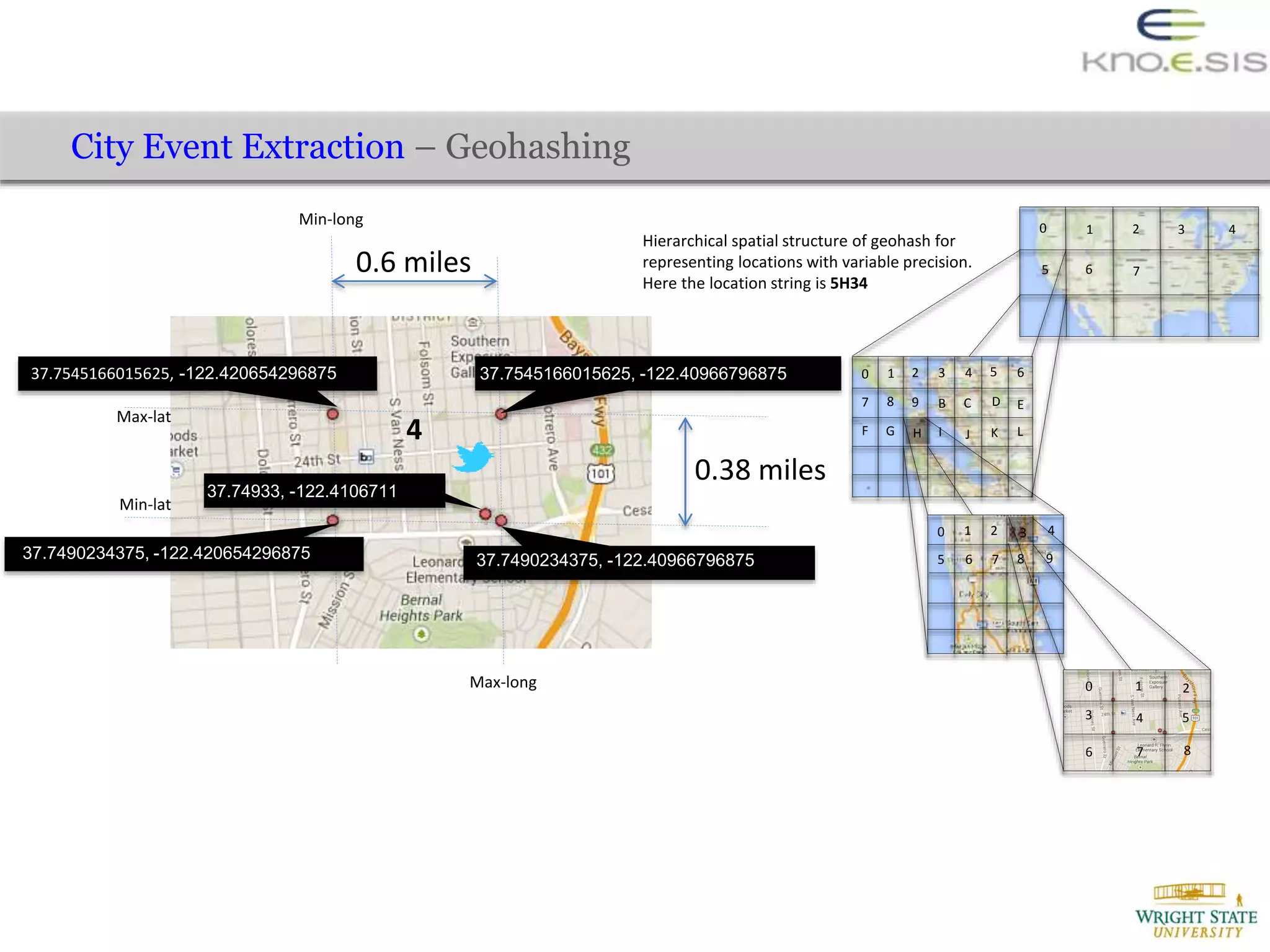


![Evaluation – Automated Creation of Training Data (to train CRF model)
Evaluation over 500 randomly chosen tweets from around 8,000 annotated tweets
Aho-Corasick [Commentz-Walter 1979] string matching algorithm implemented by LingPipe [Alias-i 2008]](https://image.slidesharecdn.com/extracting-city-traffic-events-from-social-streams-151209195518-lva1-app6891/75/Extracting-City-Traffic-Events-from-Social-Streams-24-2048.jpg)


![[Kumaran and Allan 2004] Giridhar Kumaran and James Allan. 2004. Text classification and named entities for new
event detection. In Proceedings of the 27th annual international ACM SIGIR conference on Research and development
in information retrieval. ACM, 297–304.
[Lampos and Cristianini 2012] Vasileios Lampos and Nello Cristianini. 2012. Nowcasting events from the social web with
statistical learn- ing. ACM Transactions on Intelligent Systems and Technology (TIST) 3, 4 (2012), 72.
[Roitman et al. 2012] Haggai Roitman, Jonathan Mamou, Sameep Mehta, Aharon Satt, and LV Subramaniam. 2012.
Harnessing the Crowds for smart city sensing. In Proceedings of the 1st international workshop on Multimodal crowd
sensing. ACM, 17–18.
[Ritter et al. 2012] Alan Ritter, Oren Etzioni, Sam Clark, and others. 2012. Open domain event extraction from twitter. In
Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 1104–
1112.
[Wang et al. 2012] Xiaofeng Wang, Matthew S Gerber, and Donald E Brown. 2012. Automatic crime prediction using
events extracted from twitter posts. In Social Computing, Behavioral-Cultural Modeling and Prediction. Springer, 231–
238.
[Becker et al. 2011] Hila Becker, Mor Naaman, and Luis Gravano. 2011. Beyond Trending Topics: Real-World Event
Identification on Twitter.. In ICWSM.
[Alias-i 2008] Alias-i. 2008. LingPipe 4.1.0. (2008). http://alias-i.com/lingpipe
[Commentz-Walter 1979] Beate Commentz-Walter. 1979. A string matching algorithm fast on the average. Springer.
References](https://image.slidesharecdn.com/extracting-city-traffic-events-from-social-streams-151209195518-lva1-app6891/75/Extracting-City-Traffic-Events-from-Social-Streams-35-2048.jpg)

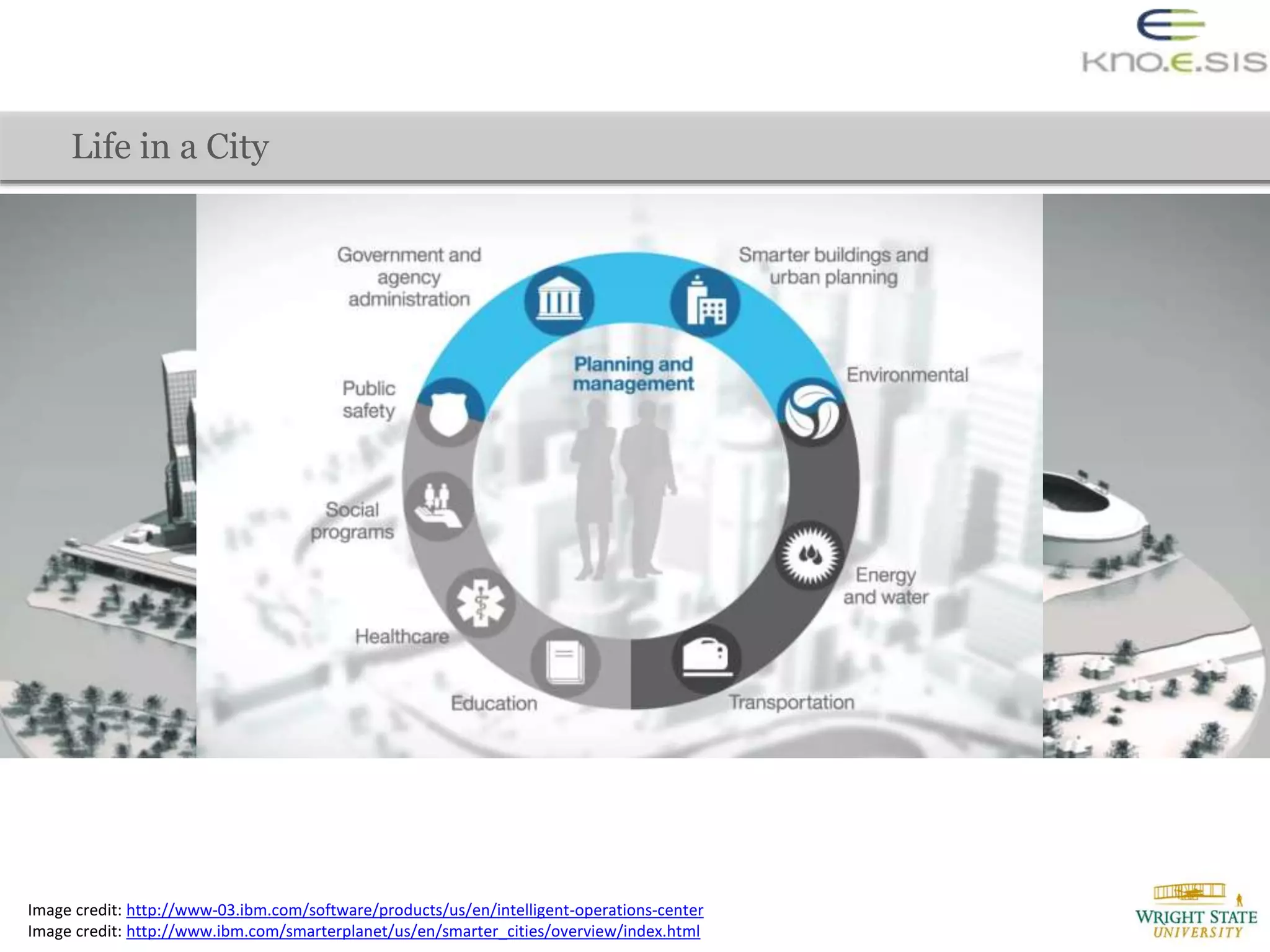
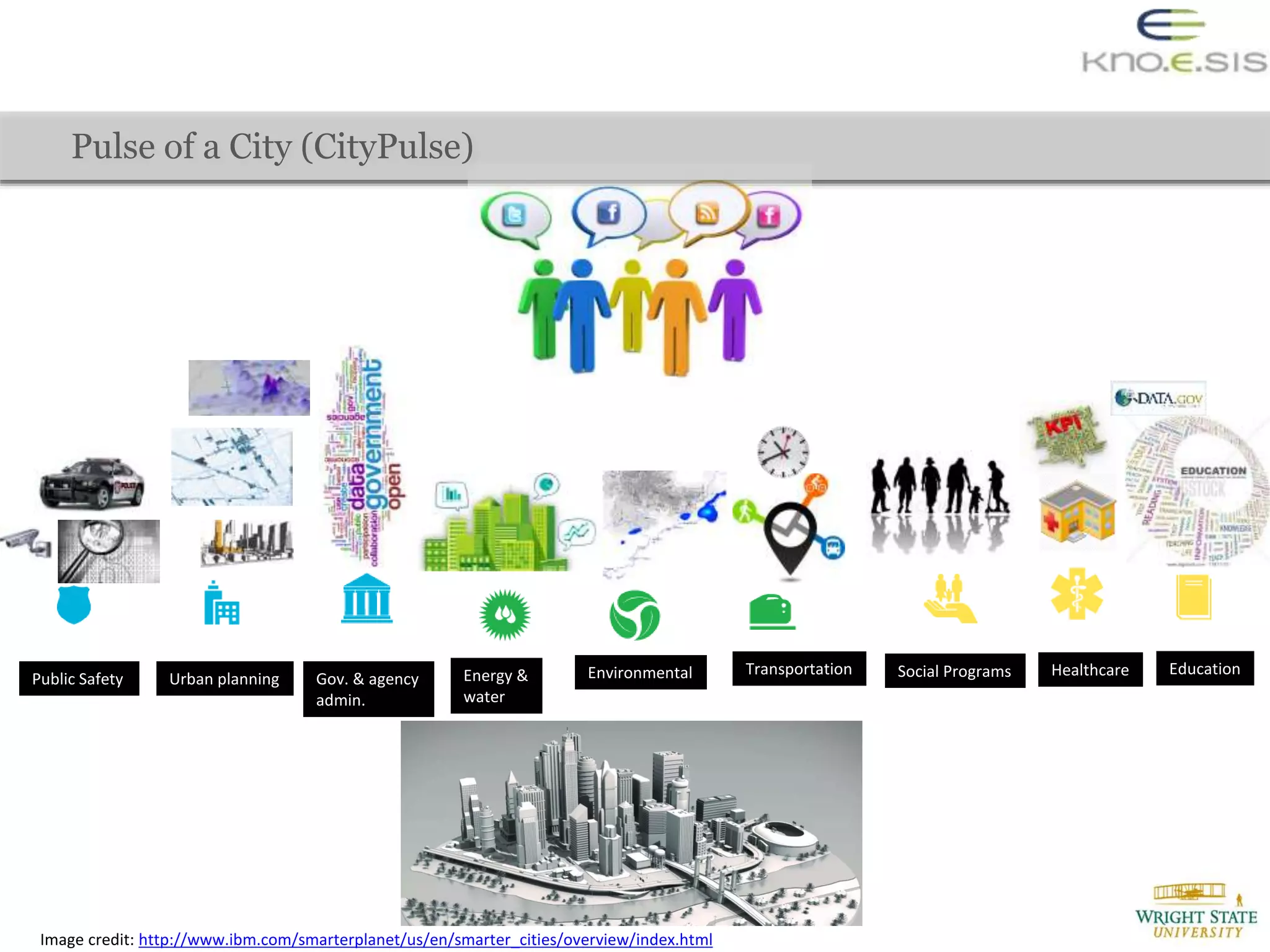
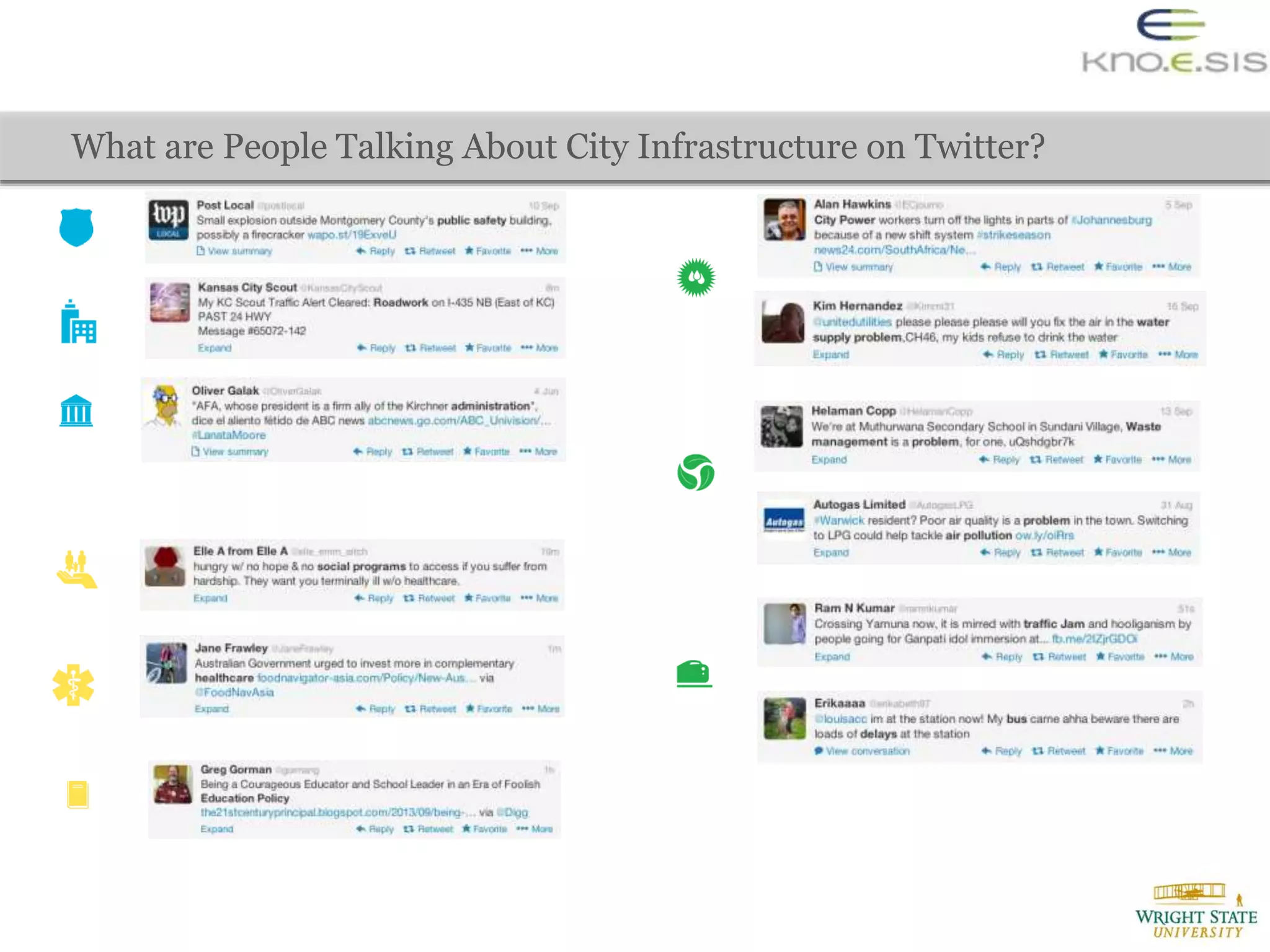
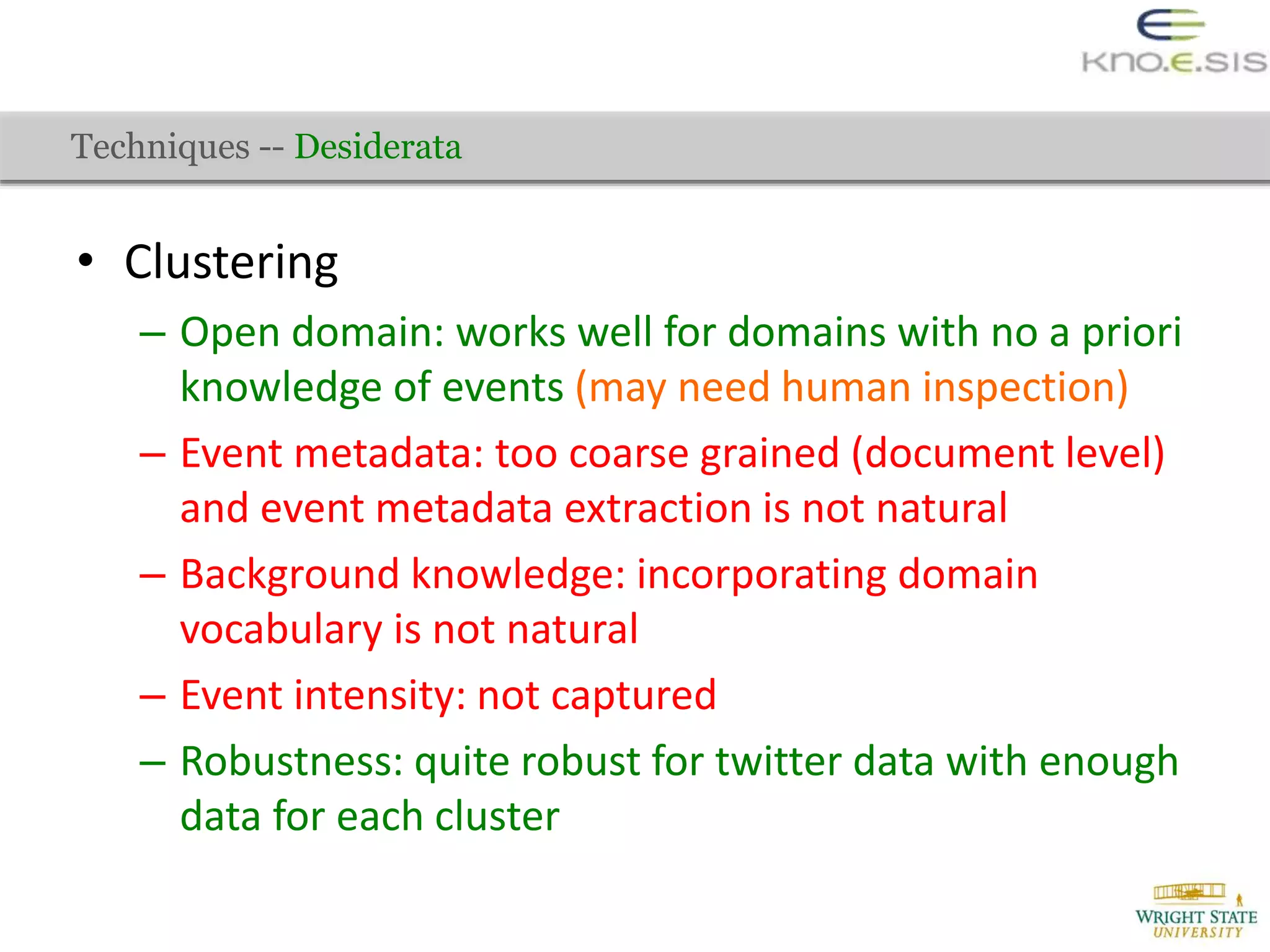
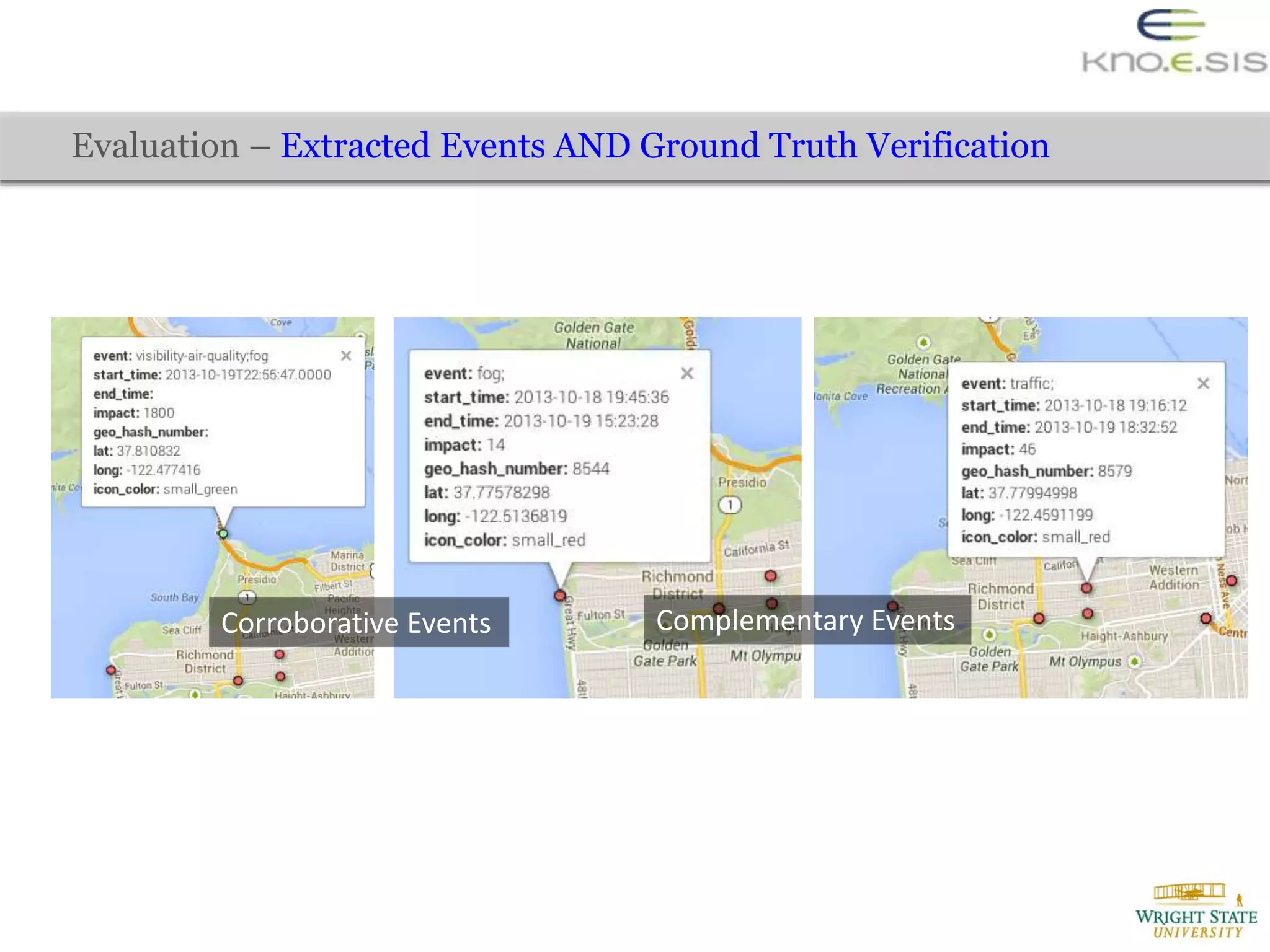
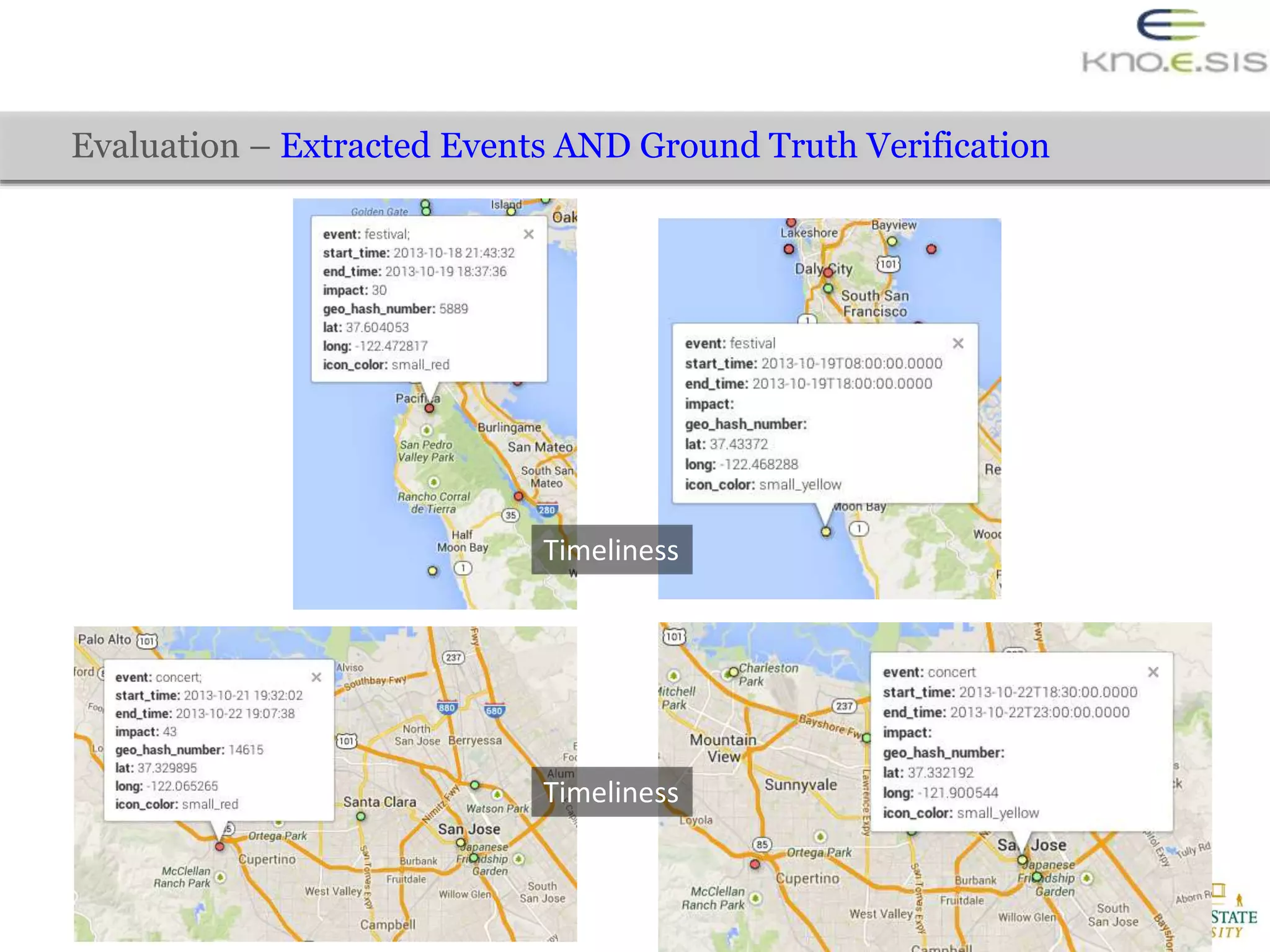
The document discusses the extraction of city traffic events from social media, particularly Twitter, utilizing various techniques such as sequence labeling and clustering to identify events related to city infrastructure. It outlines the challenges of analyzing informal data and presents solutions for event extraction, emphasizing the importance of domain knowledge for robust analysis. The findings indicate that extracted events can complement official reports, providing timely and corroborative insights into urban conditions.



































































