Download as PDF, PPTX


![@hemant_pt
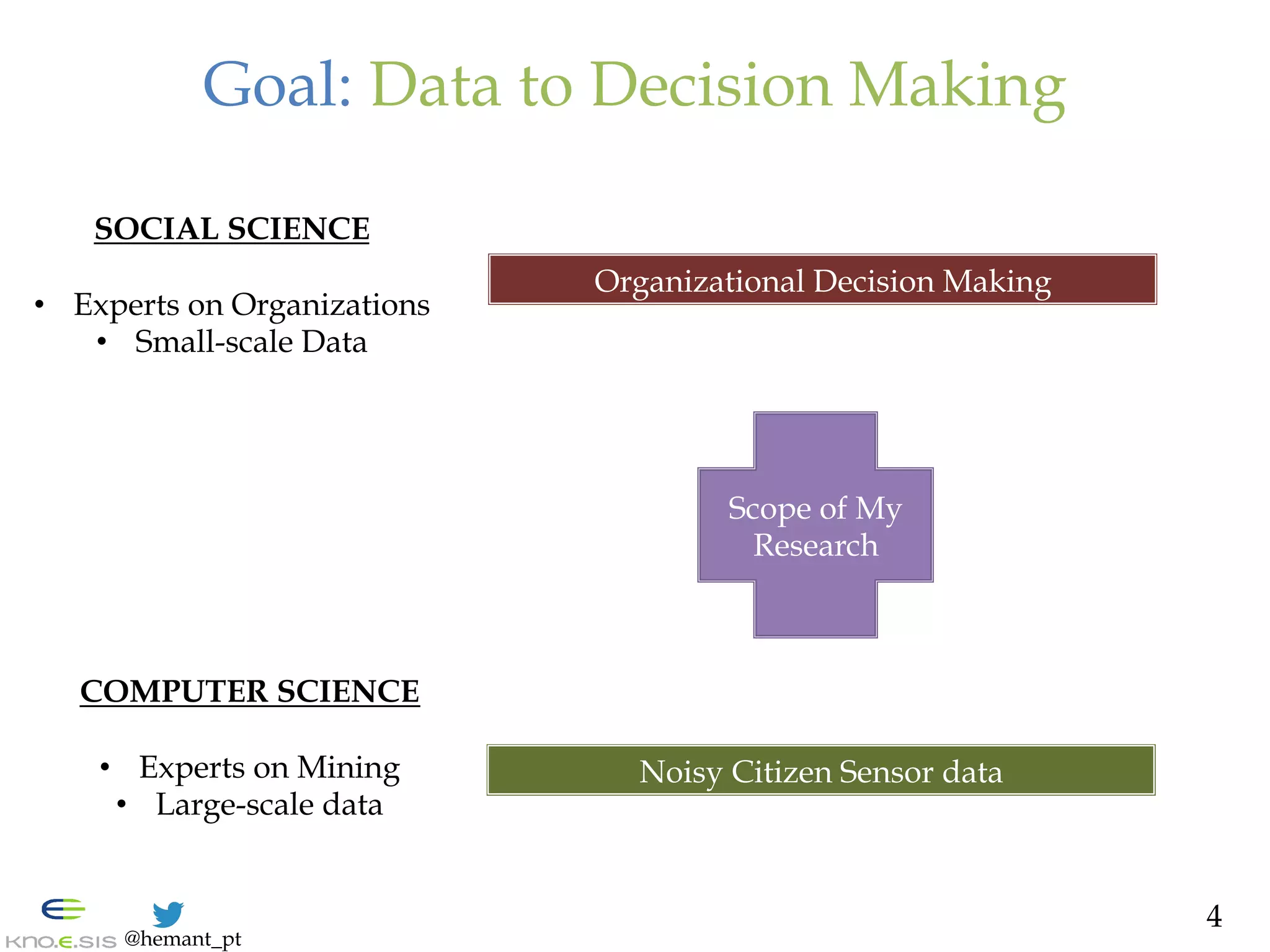
Computer-Supported Cooperative
Work (CSCW) Matrix
6
[Johansen
1988,
Baecker
1995]
TIME
PLACE](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-6-2048.jpg)






![@hemant_pt
Conversation Classification: Offline
Theories
— Psycholinguistics Indicators [Clark & Gibbs, 1986, Chafe 1987, etc.]
— Determiners (‘the’ vs. ‘a/an’)
— Dialogue Management (e.g., ‘thanks’, ’anyway’), etc.
— Drawback
— Offline analysis focused on positive conversation instances
— Hypotheses
— Offline theoretic features are discriminative
— Such features correlate with information density
15](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-15-2048.jpg)
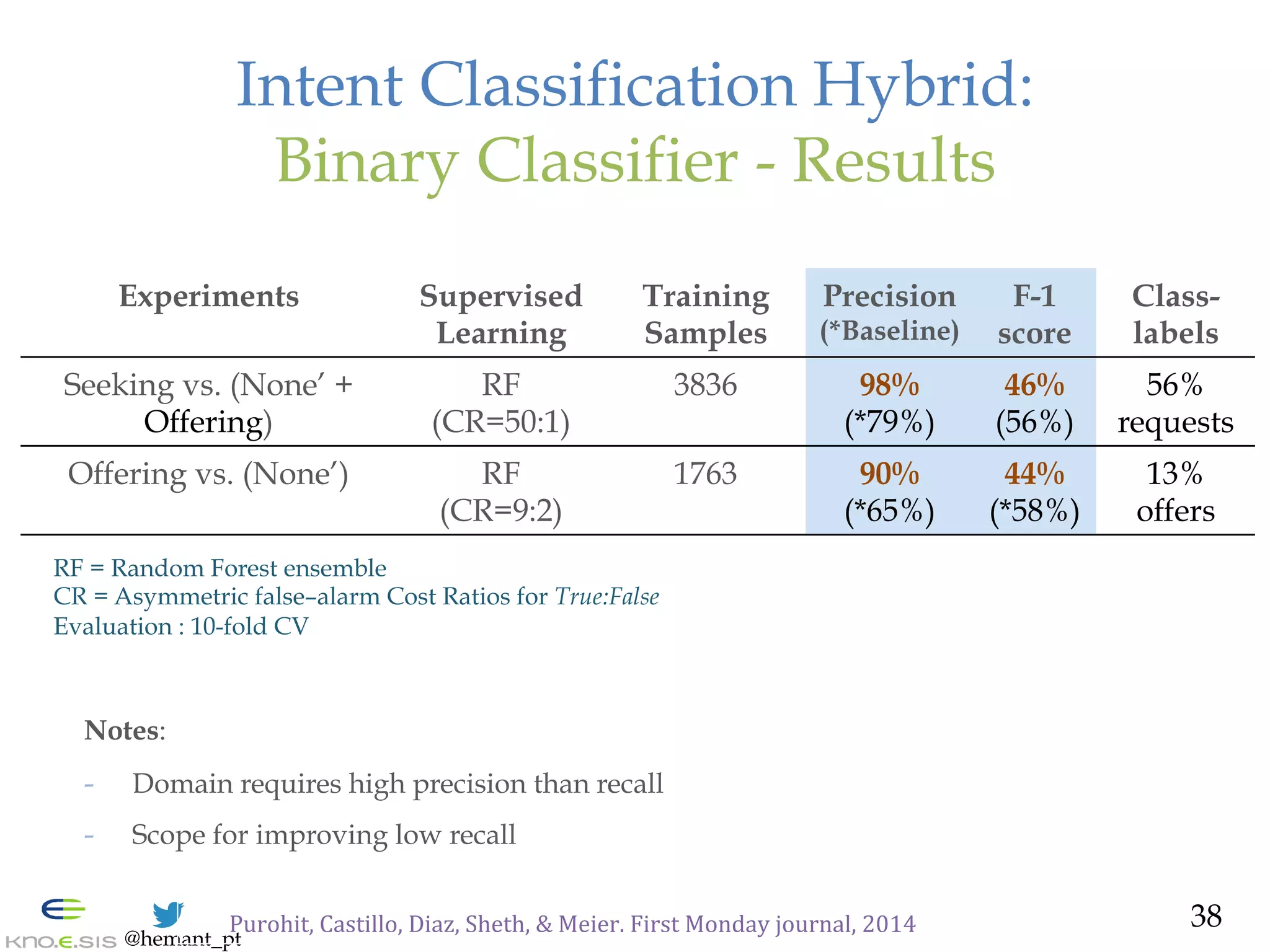
![@hemant_pt
Conversation Classification: Results
— Dataset
— Tweets from 3 Disasters, and 3 Non-Disaster events
— Varying set size (3.8K – 609K), time periods
— Classifier:
— Decision Tree
— Evaluation: 10-fold Cross Validation
— Accuracy: 62% - 78% [Lowest for {Mention,None} ]
— AUC range: 0.63 - 0.84
17
Purohit,
Hampton,
Shalin,
Sheth
&
Flach.
In
Journal
of
Computers
in
Human
Behavior,
2013](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-17-2048.jpg)

![@hemant_pt
Conversation Classification:
Psycholinguistic Analysis
— LIWC: Tool for deeper content analysis [Pennebaker, 2001]
— Gives a measure per psychological category
— Categories of interest
— Social Interaction
— Sensed Experience
— Communication
— Analyzed output sets in confusion matrices
Ø Higher values for positive classified conversation
Ø suggests higher information for cooperative intent
19
Purohit,
Hampton,
Shalin,
Sheth
&
Flach.
In
Journal
of
Computers
in
Human
Behavior,
2013
True
Positive
False
Negative
False
Positive
True
Negative](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-19-2048.jpg)






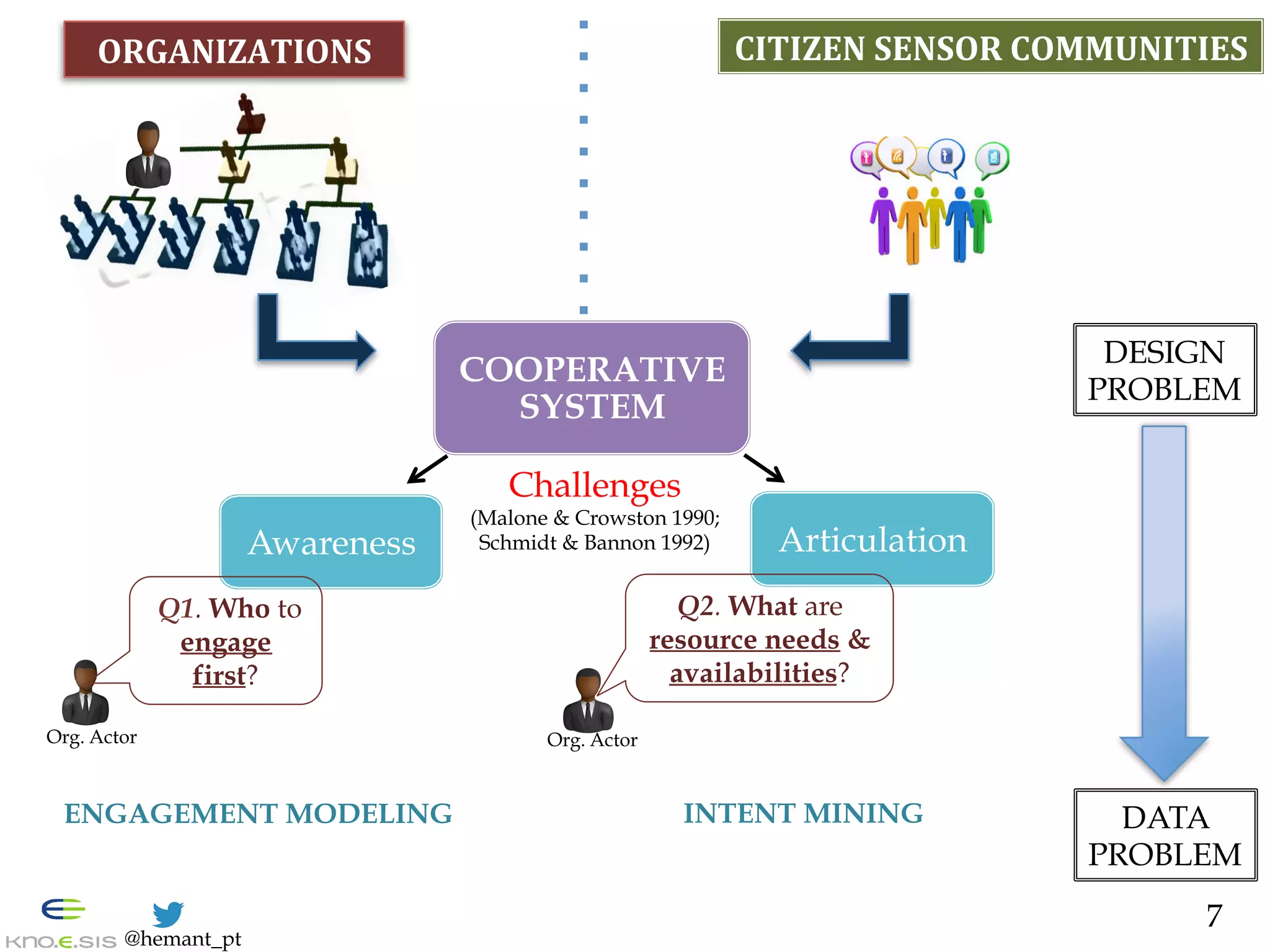
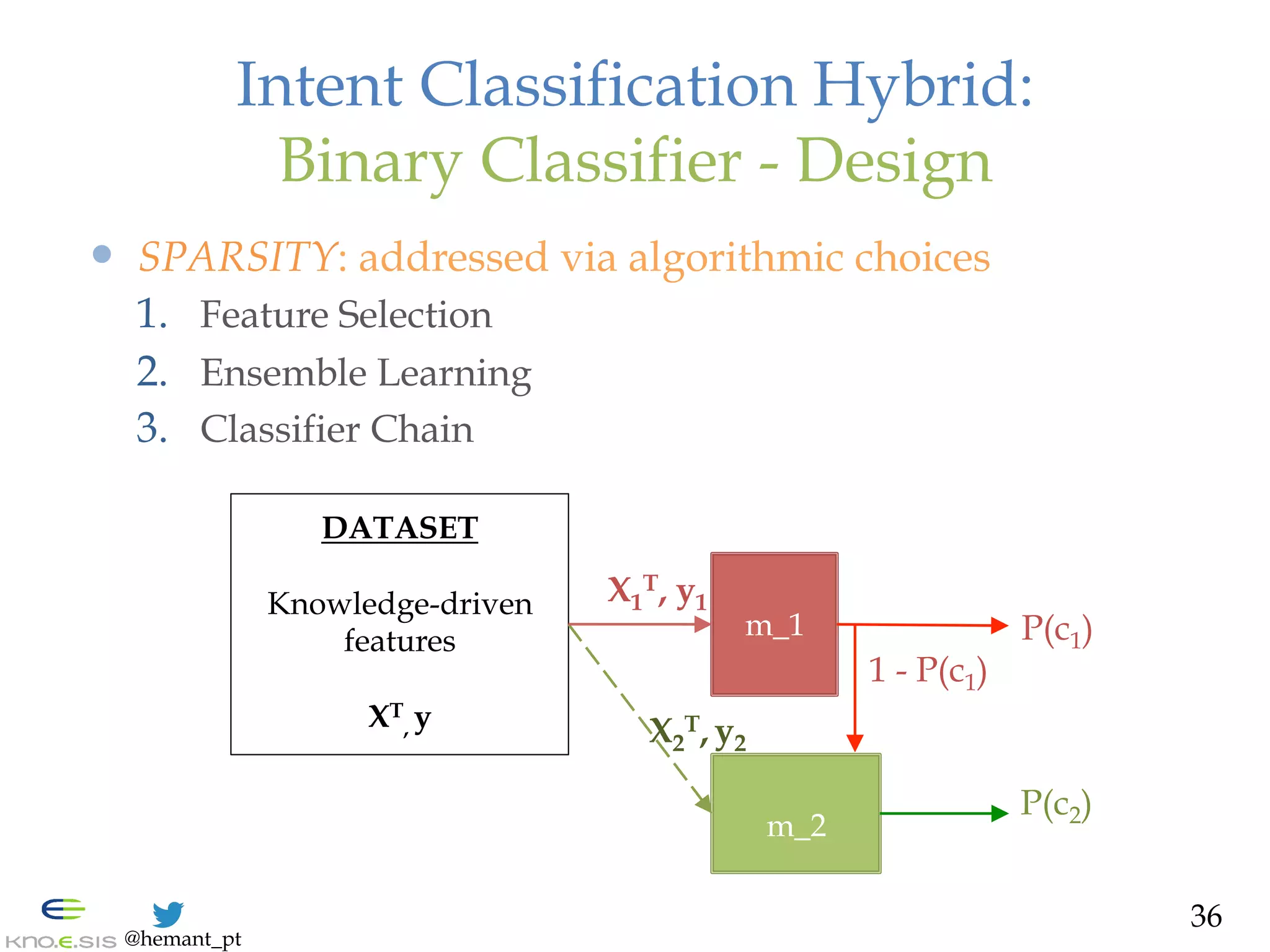
![@hemant_pt
Intent Classification: Challenges
— Unconstrained Natural Language in small space
— Ambiguity in interpretation
— Sparsity of low ‘signal-to-noise’: Imbalanced classes
— 1% signals (Seeking/Offering) in 4.9 million tweets #Sandy
— Hard-to-predict problem:
— commercial intent, F-1 score 65% on Twitter [Hollerit et al. 2013]
@Zuora wants to help @Network4Good with Hurricane Relief. Text SANDY to
80888 & donate $10 to @redcross @AmeriCares & @SalvationArmyUS #help
*Blue: offering intent, *Red: seeking intent
28](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-28-2048.jpg)
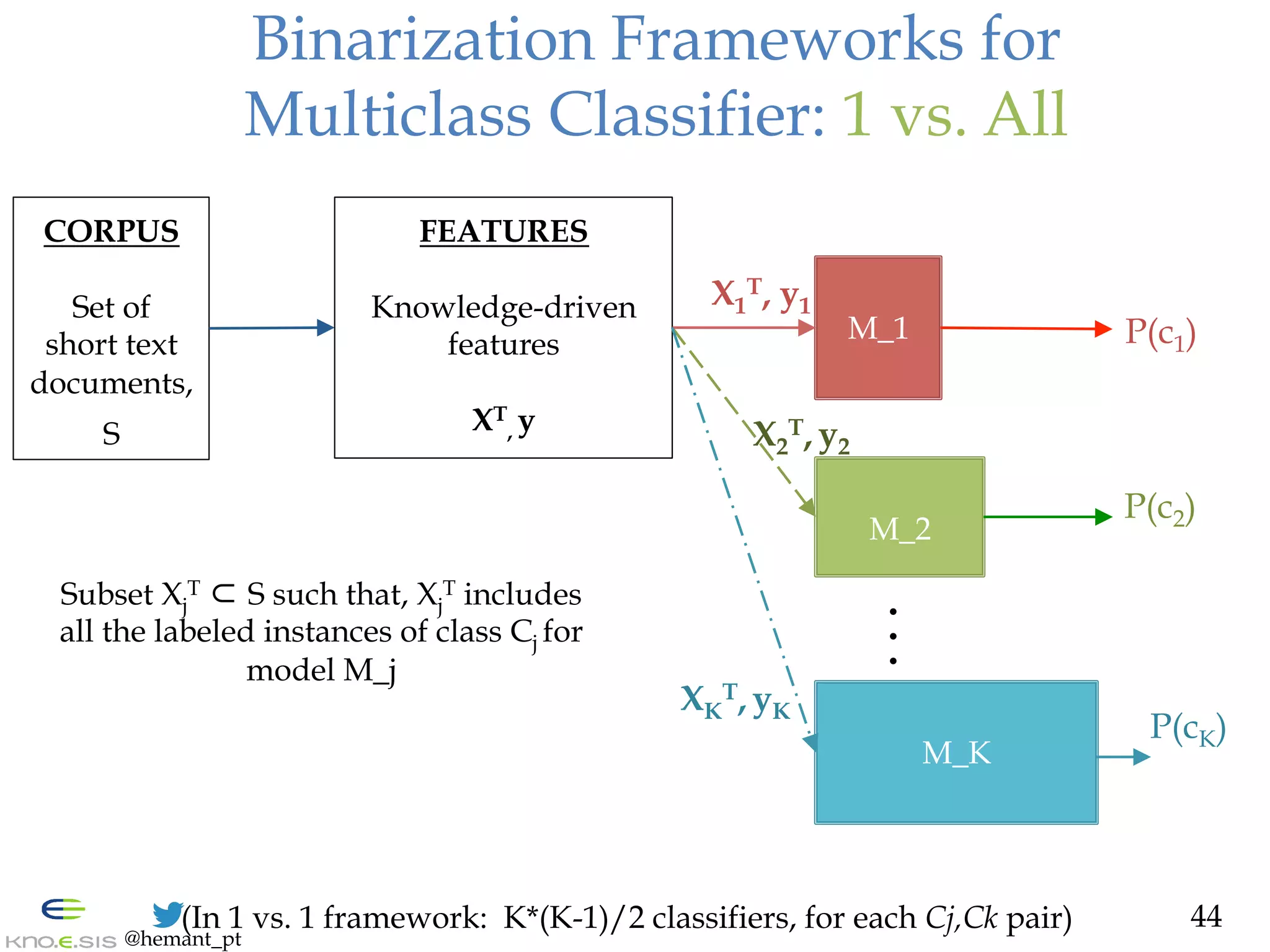
![@hemant_pt
Intent Classification: Types & Features
29
Intent
Binary
Crisis Domain:
- [Varga et al. 2013] Problem vs. Aid (Japanese)
- Features: Syntactic, Noun-Verb templates, etc.
Commercial Domain:
- [Hollerit et al. 2013] Buy vs. Sell intent
- Features: N-grams, Part-of-Speech
Multiclass
Commercial Domain:
- Not on Twitter](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-29-2048.jpg)
![@hemant_pt
Intent Classification Top-Down:
Binary Classifier - Prior Knowledge
— Conceptual Dependency Theory [Schank, 1972]
— Make meaning independent from the actual words in input
— e.g., Class in an Ontology abstracts similar instances
— Verb Lexicon [Hollerit et al. 2013]
— Relevant Levin’s Verb categories [Levin, 1993]
— e.g., give, send, etc.
— Syntactic Pattern
— Auxiliary & modals: e.g., ‘be’, ‘do’, ‘could’, etc. [Ramanand et al. 2010]
— Word order: Verb-Subject positions, etc.
Purohit,
Hampton,
Bhatt,
Shalin,
Sheth
&
Flach.
In
Journal
of
CSCW,
2014
31](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-31-2048.jpg)

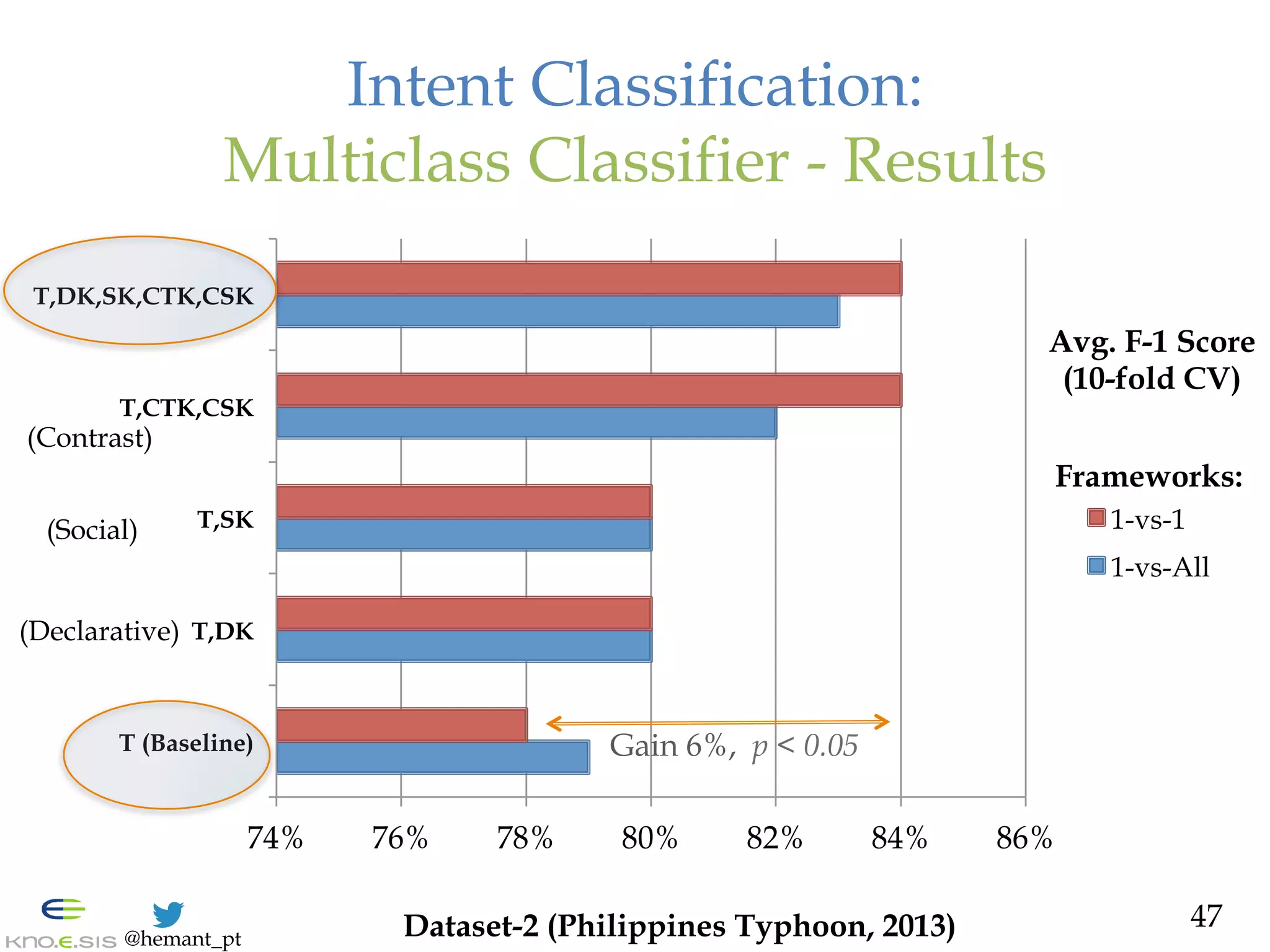
![@hemant_pt
Intent Classification Top-Down:
Binary Classifier - Lessons
— Preliminary Study
— 2000 conversation and then rule-based classified tweets:
labeled by two native speakers
— Labels: Seeking, Offering, None
— Results
— Avg. F-1 score: 78% (Baseline F-1 score: 57% [Varga et al. 2013] )
— Lessons
— Role of prior knowledge: Domain Independent & Dependent
— Limitation: Exhaustive rule-set, low Recall, Ambiguity
addressed, but sparsity
Purohit,
Hampton,
Bhatt,
Shalin,
Sheth
&
Flach.
In
Journal
of
CSCW,
2014
33](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-33-2048.jpg)
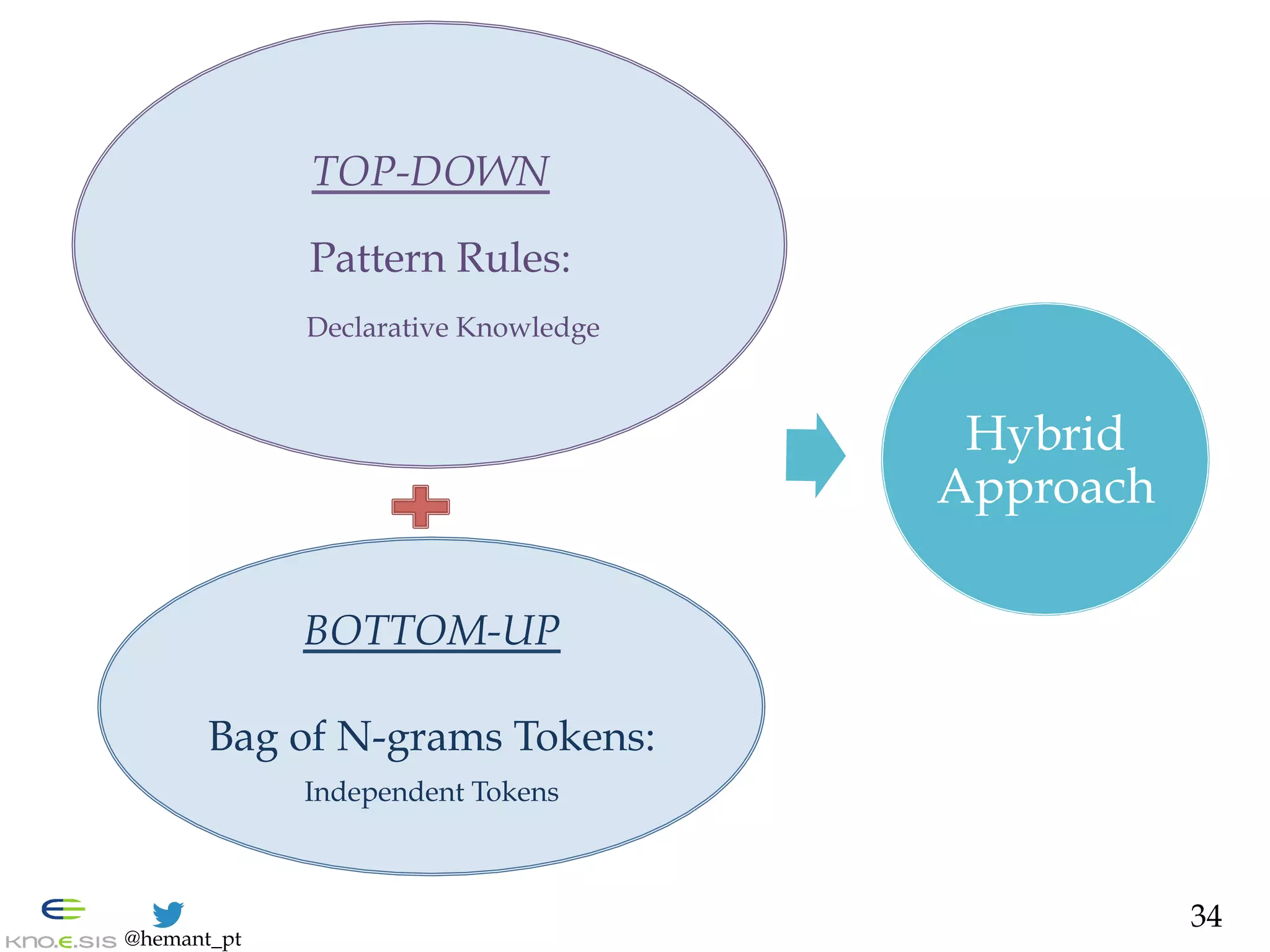
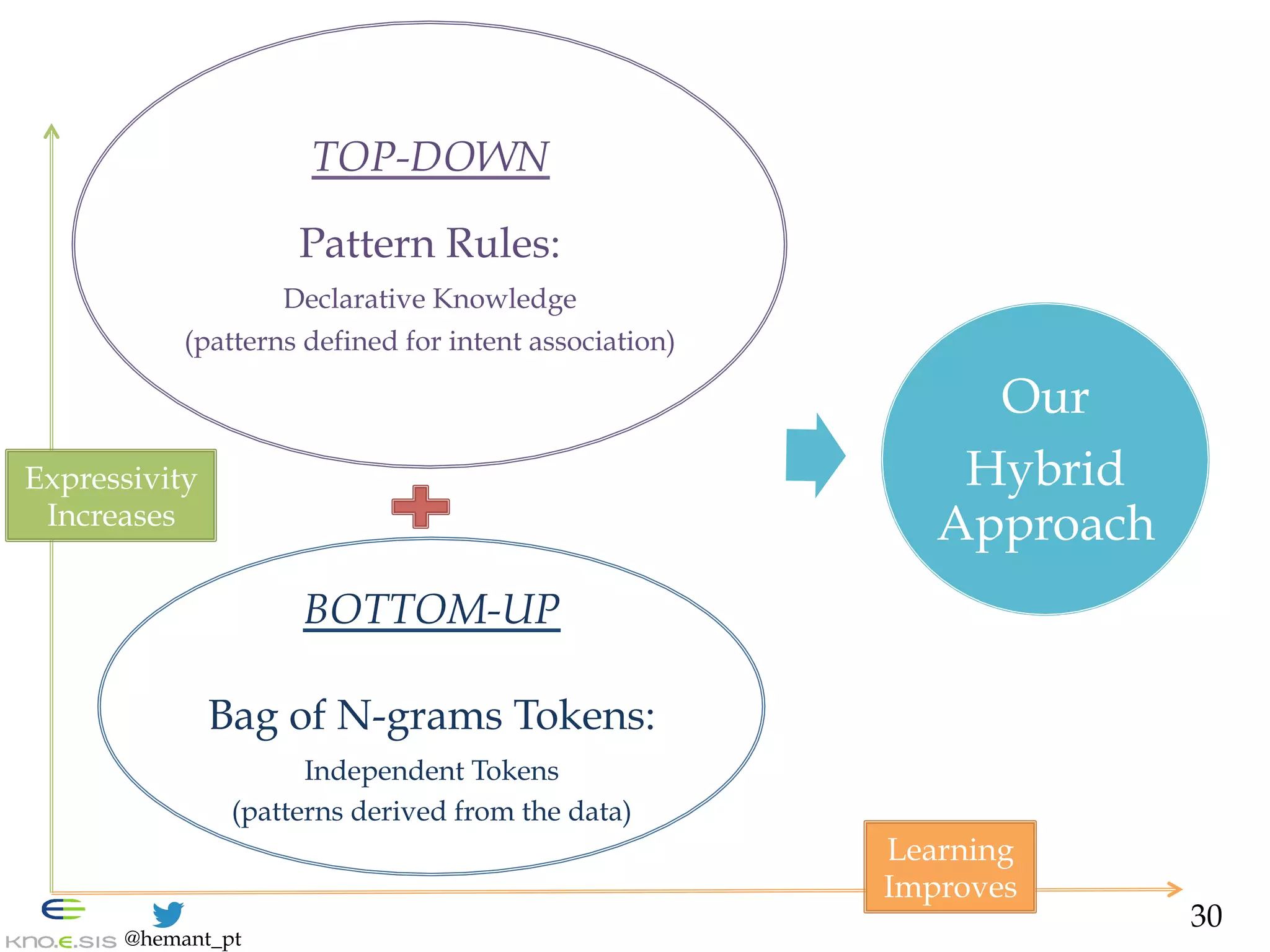
![@hemant_pt
Intent Classification Hybrid:
Binary Classifier - Design
— AMBIGUITY: addressed via rich feature space
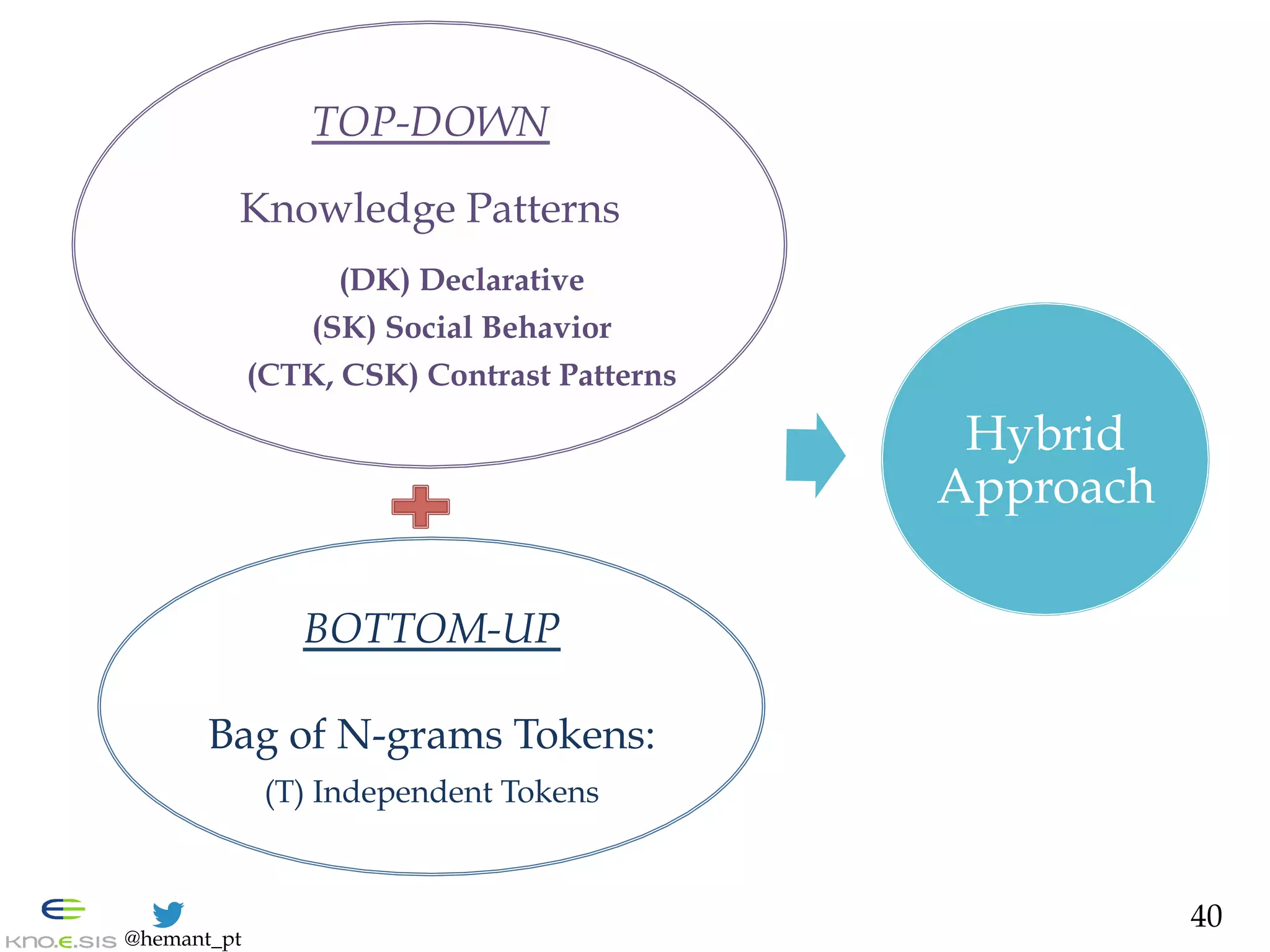
1. Top-Down: Declarative Knowledge Patterns [Ramanand et al. 2010]
DK(mi, P) ! {0,1}
e.g., P= b(like|want) b.*b(to)b.*b(bring|give|help|raise|donate)b
(acquired via Red Cross expert searches)
2. Abstraction: due to importance in info sharing [Nagarajan et al. 2010]
- Numeric (e.g., $10) à _NUM_
- Interactions (e.g., RT & @user) à _RT_ , _MENTION_
- Links (e.g., http://bit.ly) ! _URL_
3. Bottom-Up: N-grams after stemming and abstraction [Hollerit et al. 2013]
TOKENIZER ( mi ) à { bi-, tri-gram }
35](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-35-2048.jpg)


















![@hemant_pt
Thanks to the Committee Members
64
[Left to Right] Prof. Amit Sheth, (advisor, WSU), Prof. Guozhu Dong (WSU), Prof. Srinivasan
Parthasarathy (OSU), Prof. TK Prasad (WSU), Dr. Patrick Meier (QCRI), Prof. Valerie Shalin (WSU)
Computer Science Social Science](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-64-2048.jpg)

![@hemant_pt
Ambiguity
Sparsity
Diversity
Scalability
• Mutual Influence in Sparse
Friendship Network
[AAAI ICWSM’12]
• User Summarization with
Sparse Profile Metadata
[ASE SocialInfo’12]
• Matching intent as task of
Information Retrieval [FM’14]
• Knowledge-aware Bi-partite
Matching [In preparation]
• Short-Text Document Intent
Mining [FM’14, JCSCW’14]
• Actor-Intent Mining
Complexity [In preparation]
• Modeling Group Using
Diverse Social Identity &
Cohesion [AAAI ICWSM’14]
• Modeling Diverse User-
Engagement [SOME WWW’11,
ACM WebSci’12]
(Interpretation)
(users)
(behaviors)
66
Other
works](https://image.slidesharecdn.com/hemant-purohit-phd-defense-citizen-organization-cooperation-150719213125-lva1-app6891/75/Hemant-Purohit-PhD-Defense-Mining-Citizen-Sensor-Communities-for-Cooperation-with-Organizations-66-2048.jpg)

The document is a PhD defense by Hemant Purohit focused on improving cooperation between citizen sensor communities and organizations through a study of intent and engagement modeling. It discusses various problems such as conversation classification, intent classification, and engagement modeling, along with contributions to cooperative system design and the use of online social data. The goal is to efficiently model intent and engagement to facilitate organizational decision-making and enhance data-driven cooperation.























































































