Downloaded 25 times








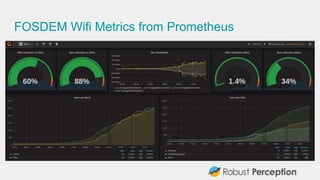

















Brian Brazil, founder of Robust Perception and a core developer of Prometheus, discusses the evolution of Prometheus for monitoring in cloud-native environments. He highlights the shift from traditional monitoring tools to a metrics-based system capable of handling dynamic services and high churn. Prometheus 2.0 and future developments aim to improve efficiency, reliability, and alerting capabilities in complex monitoring scenarios.















































