Download as PDF, PPTX








































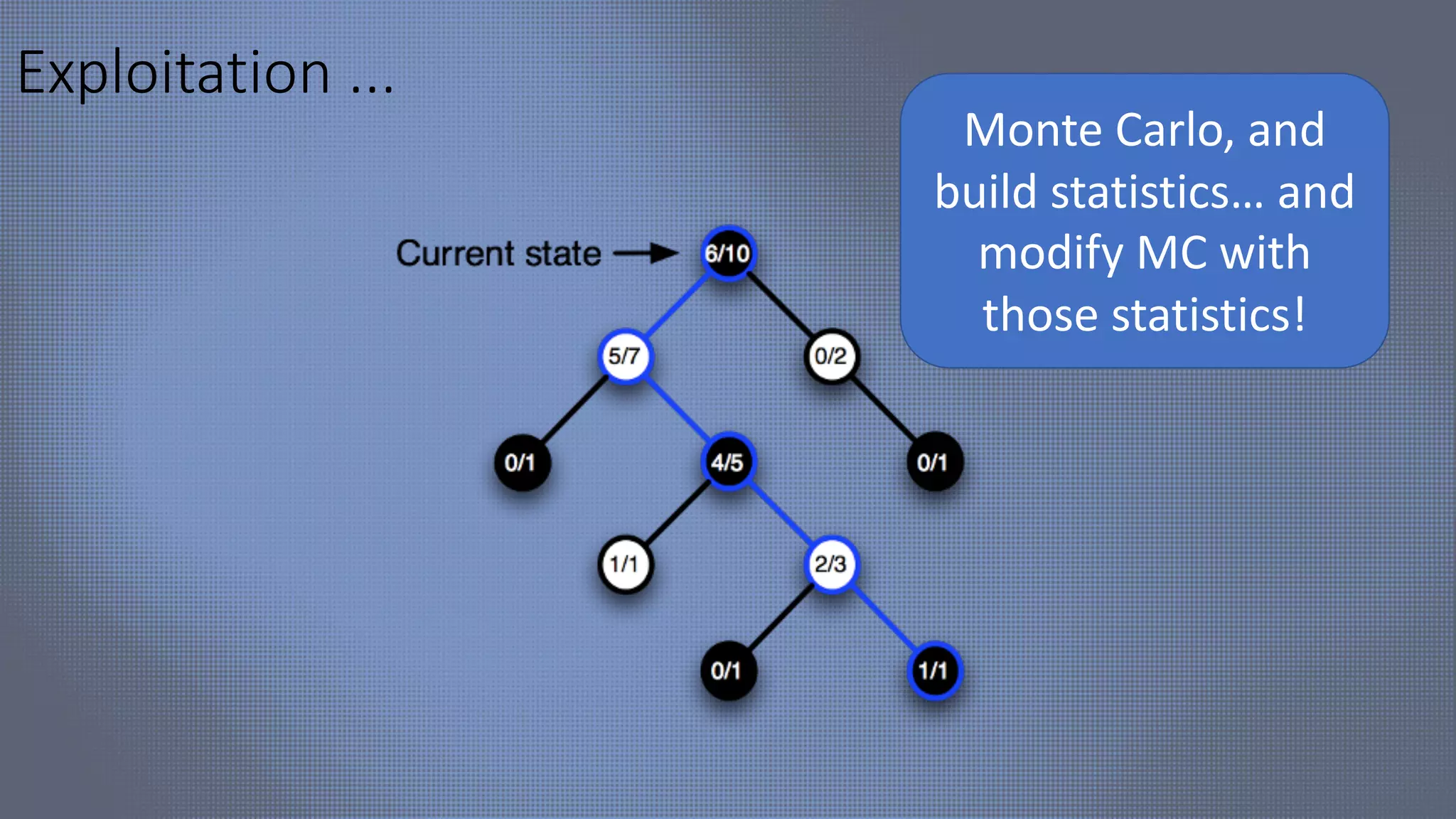
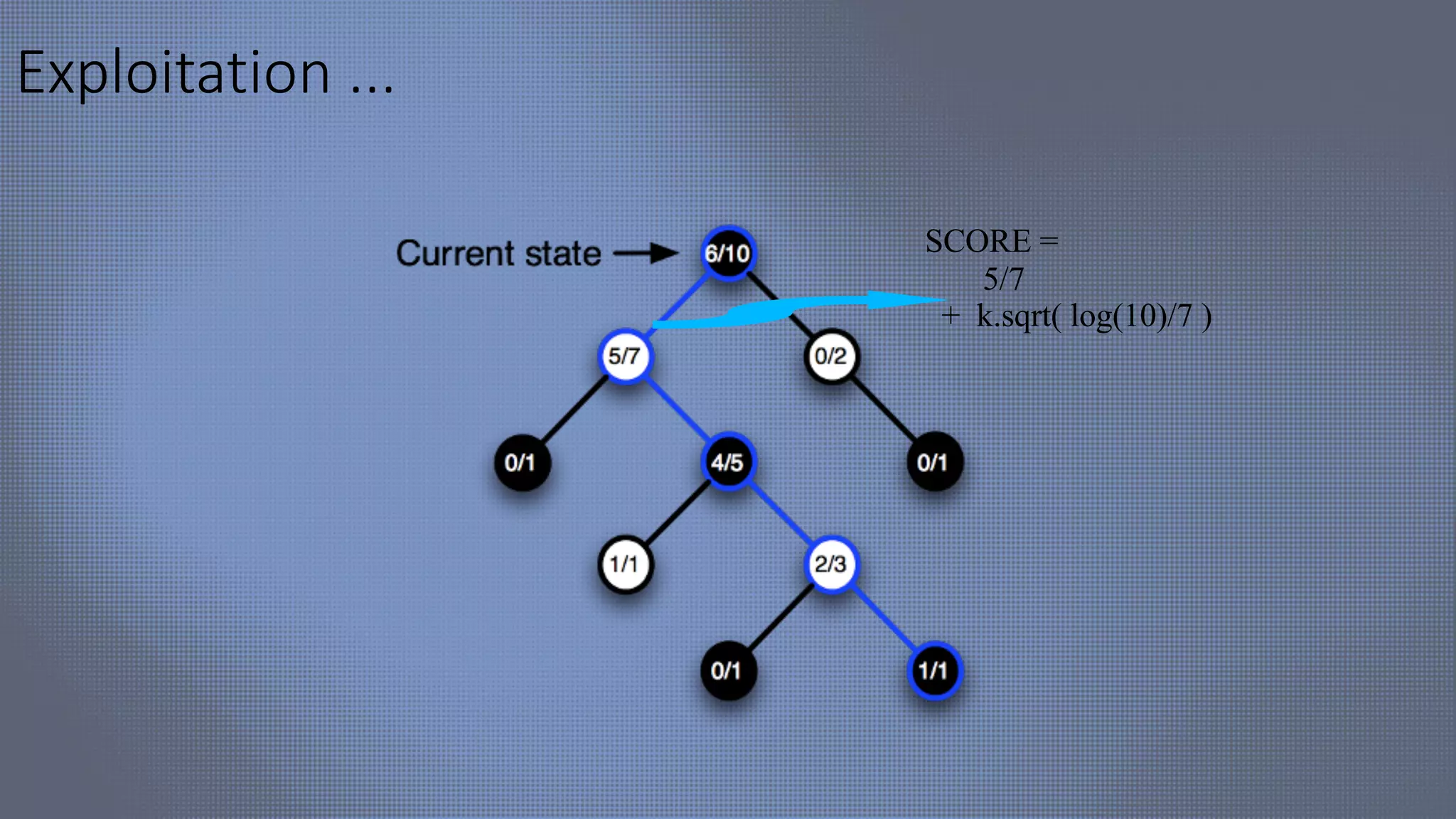
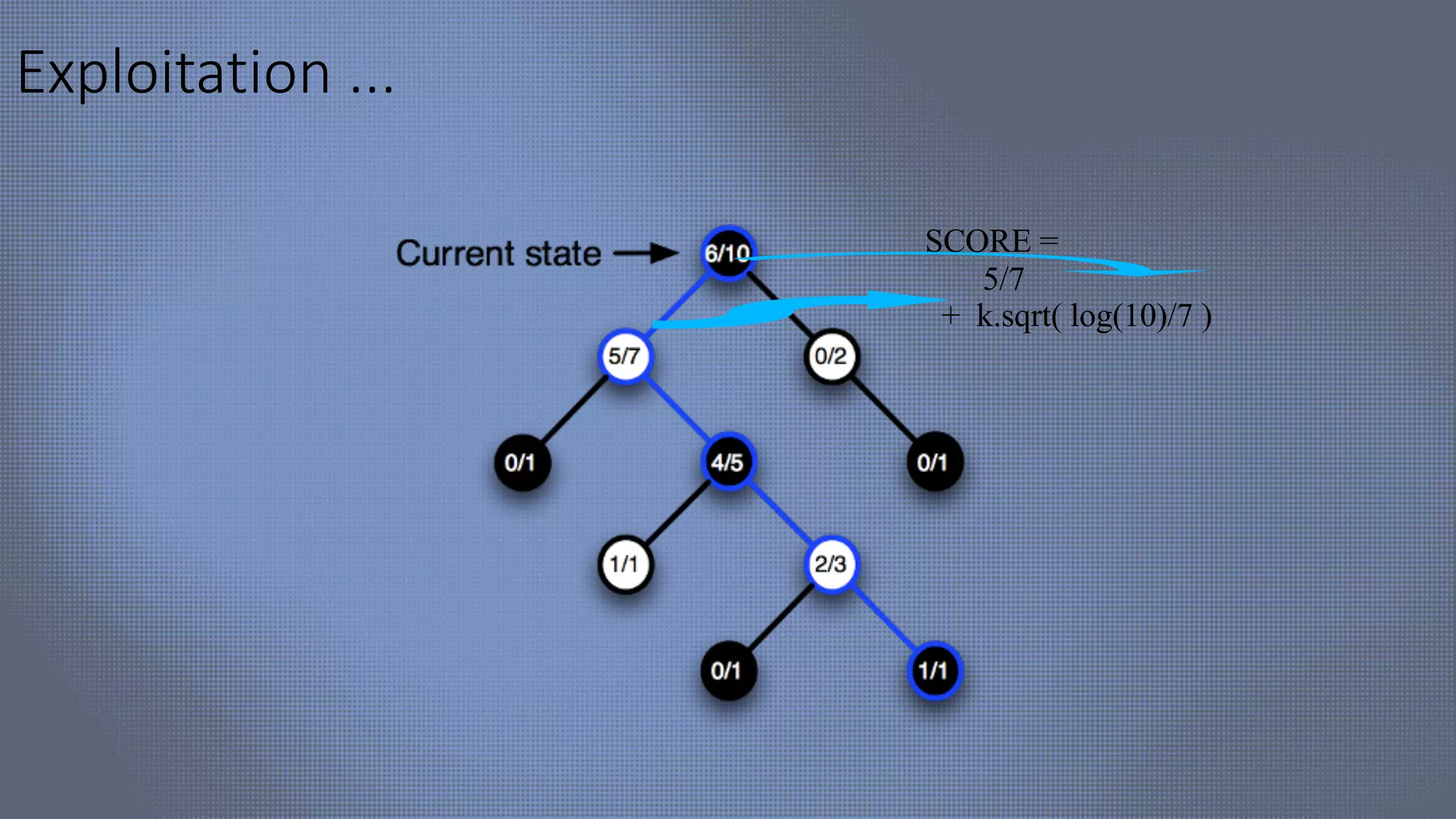
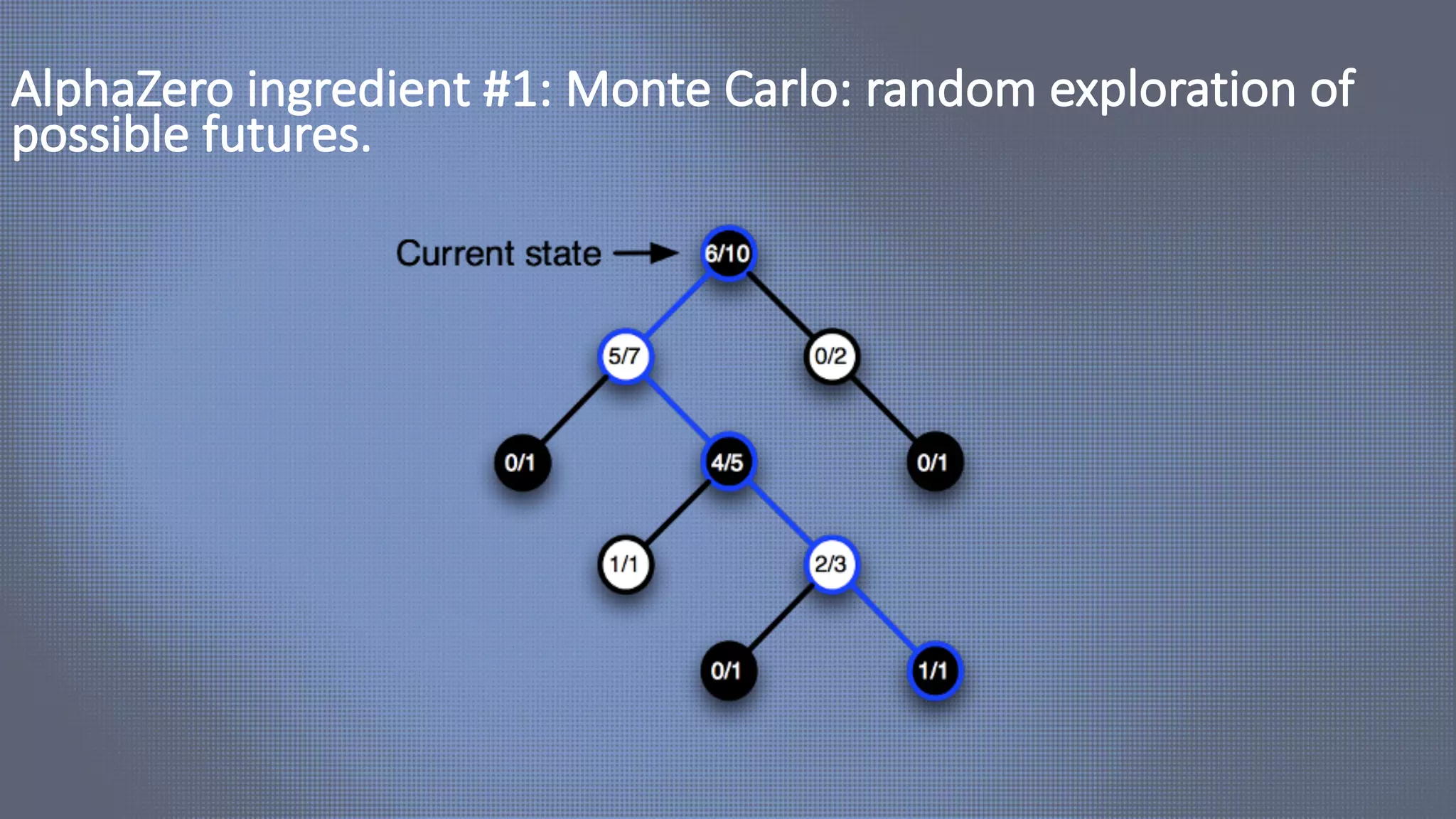




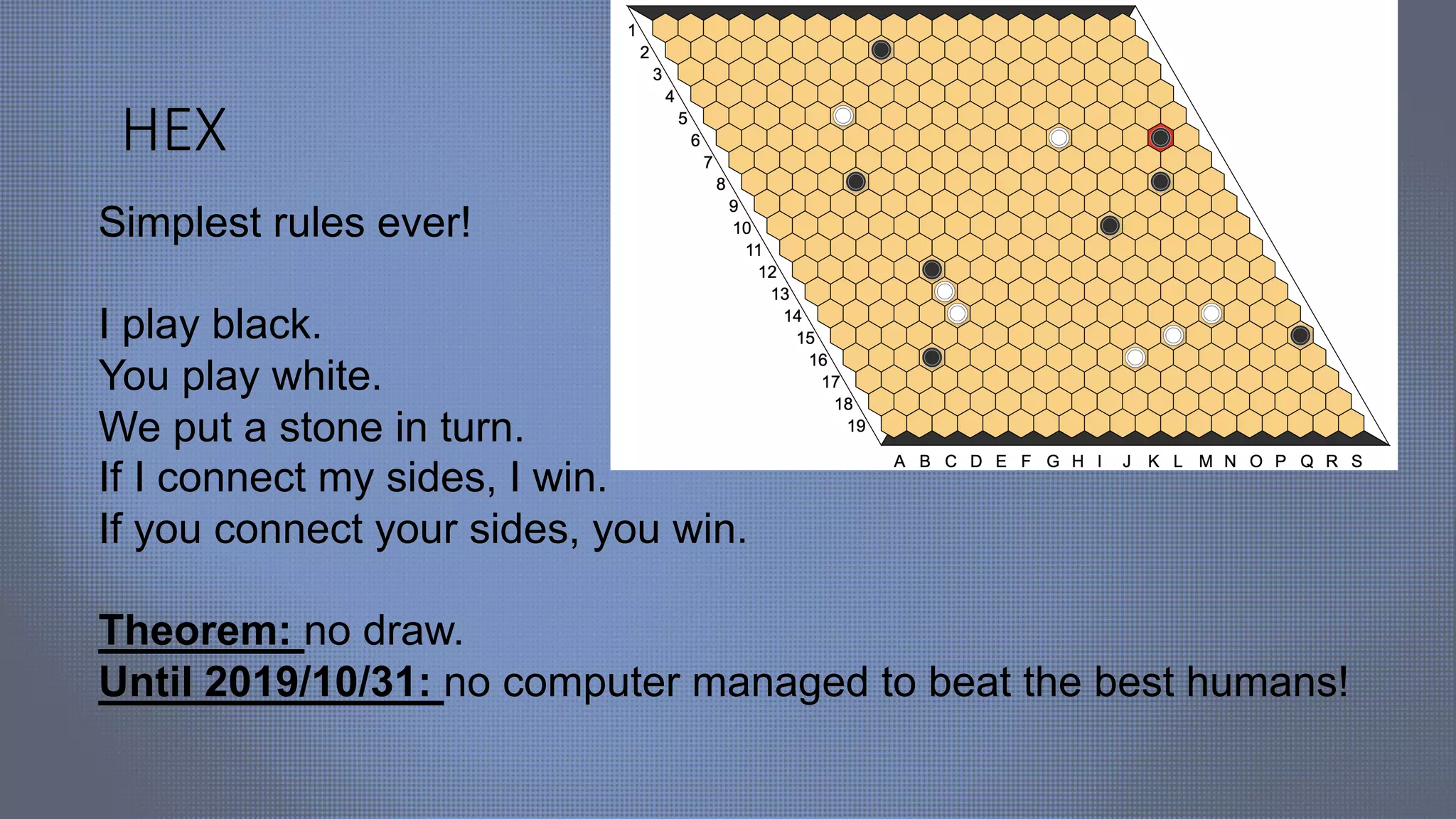
![HEX
According to Bonnet et al
(https://www.lamsade.dauphine.fr/~bonnet/publi/connection-
games.pdf), “Since its independent inventions in 1942 and 1948 by
the poet and mathematician Piet Hein and the economist and
mathematician John Nash, the game of hex has acquired a special
spot in the heart of abstract game aficionados. Its purity and depth
has lead Jack van Rijswijck to conclude his PhD thesis with the
following hyperbole [1]: << Hex has a Platonic existence,
independent of human thought. If ever we find an
extraterrestrial civilization at all, they will know hex, without
any doubt.>> ”](https://image.slidesharecdn.com/slideshareevovisionindia-200324071016/75/Evolutionary-deep-learning-computer-vision-73-2048.jpg)



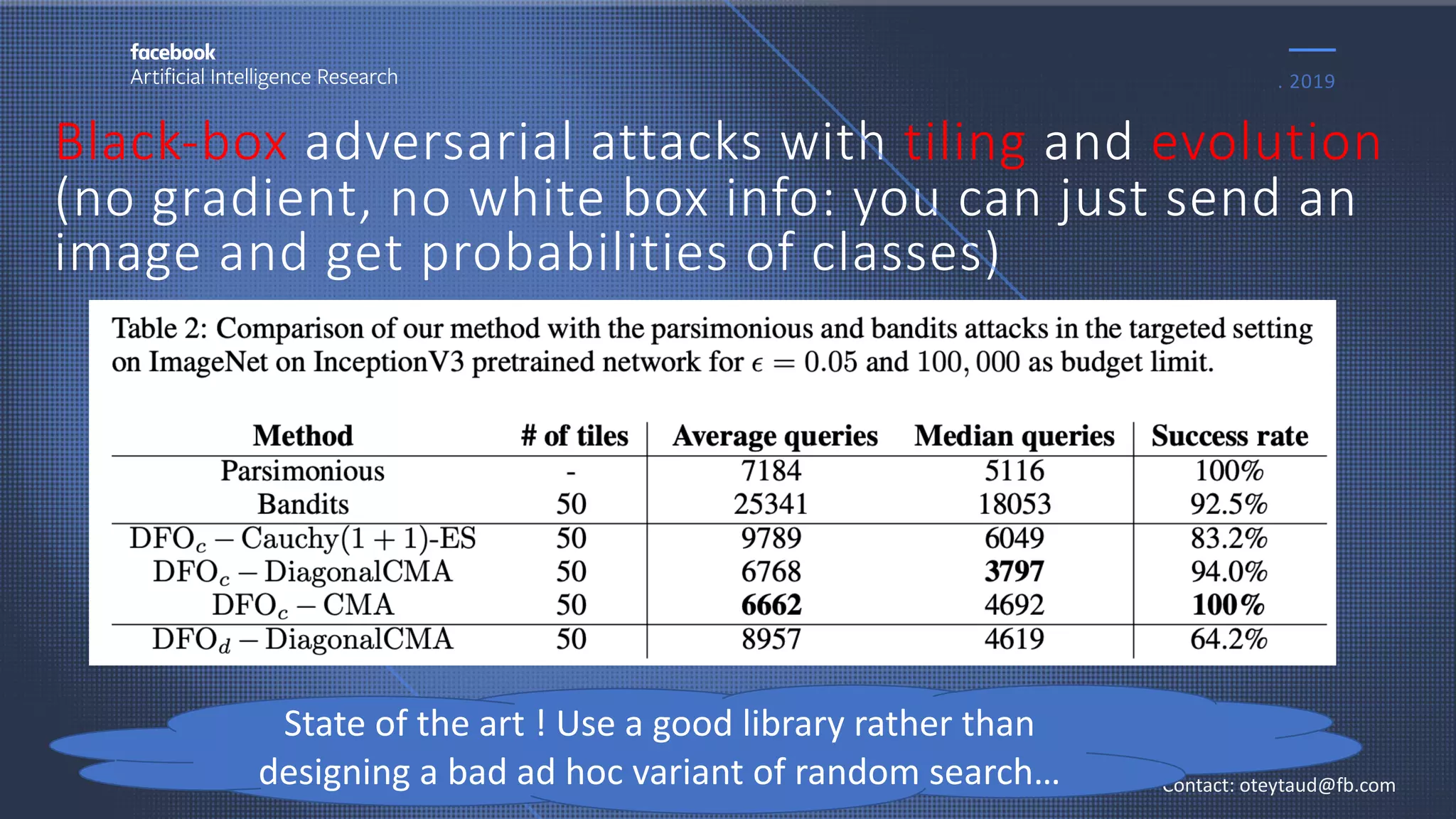
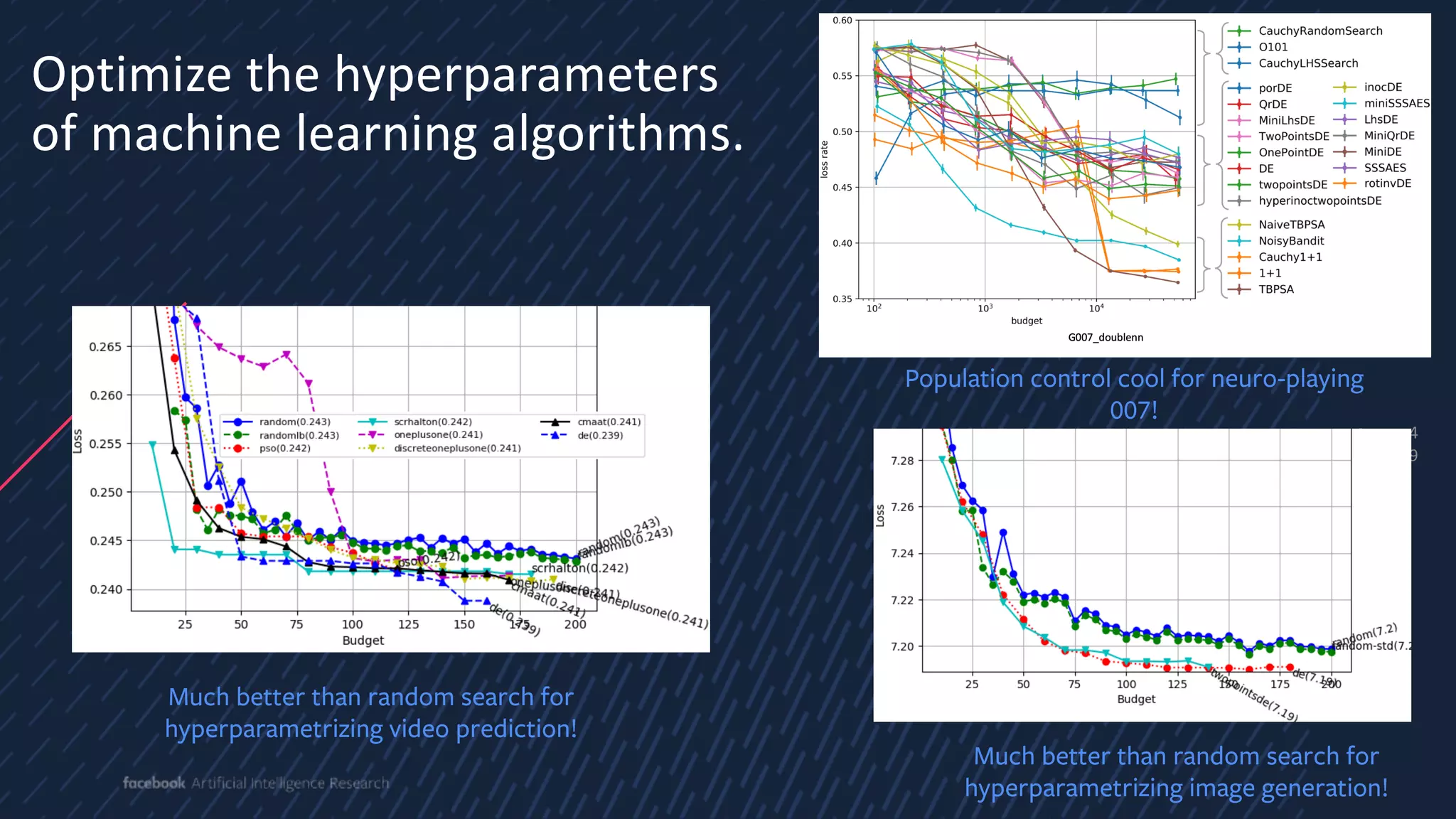
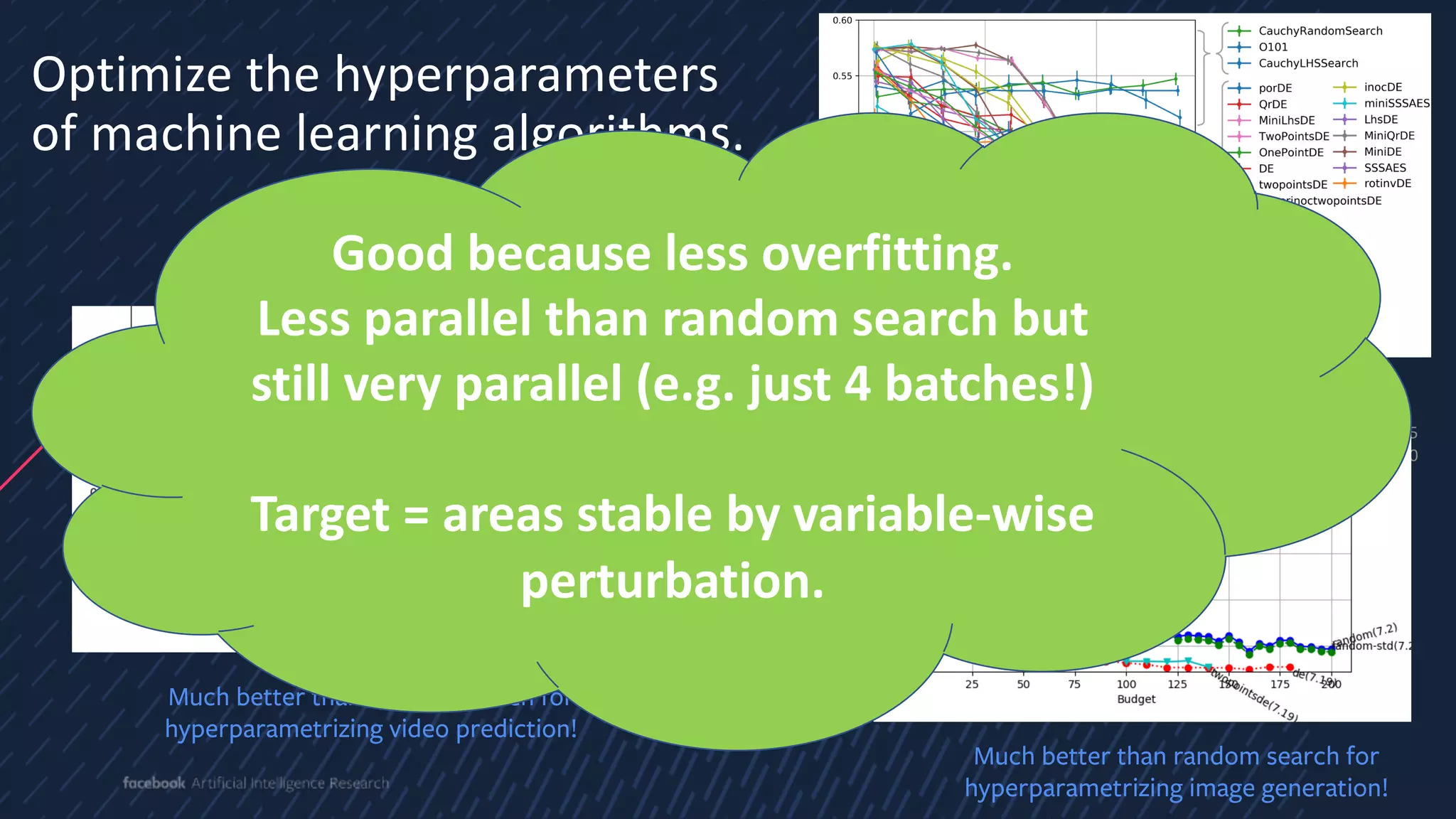
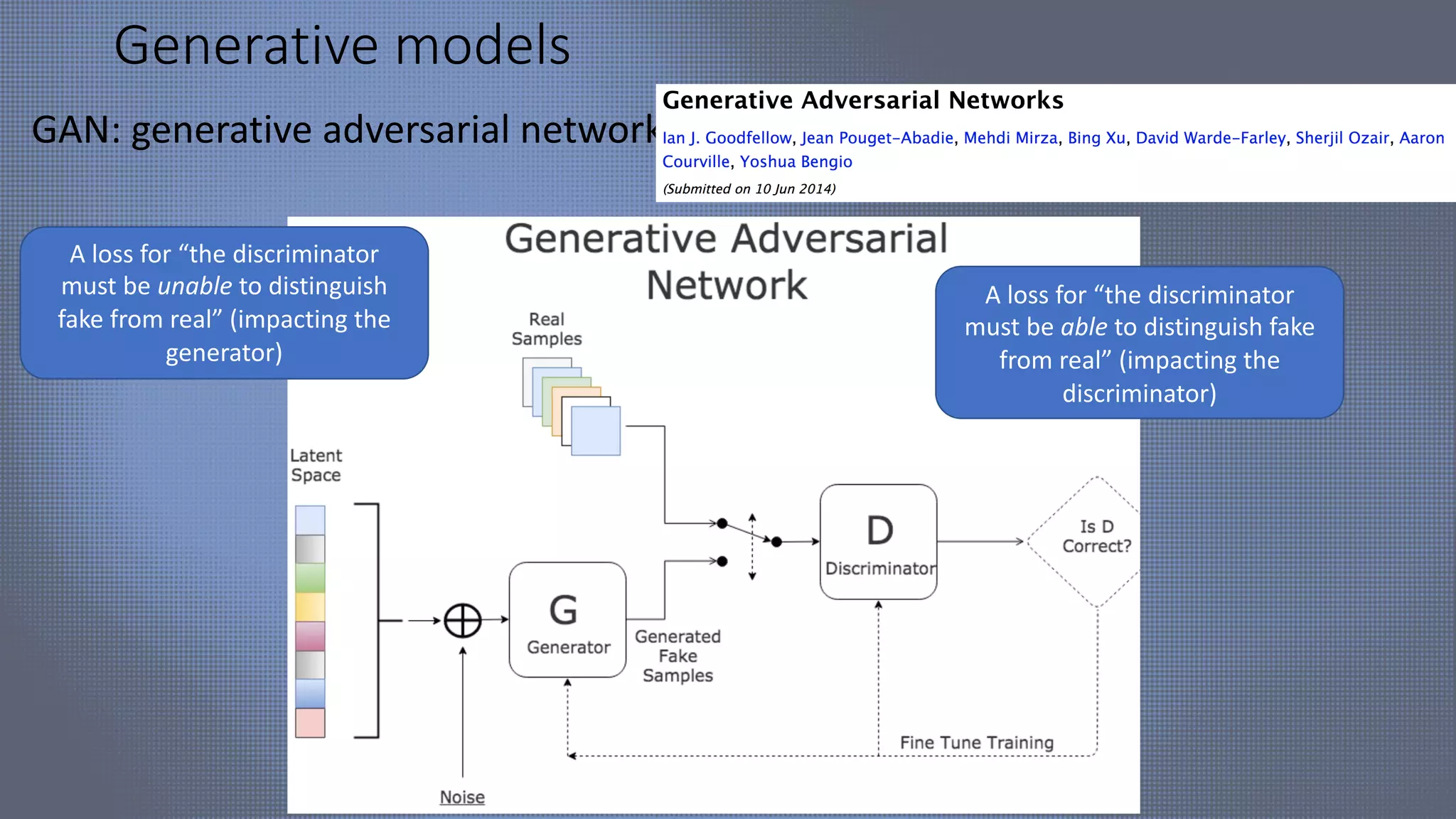
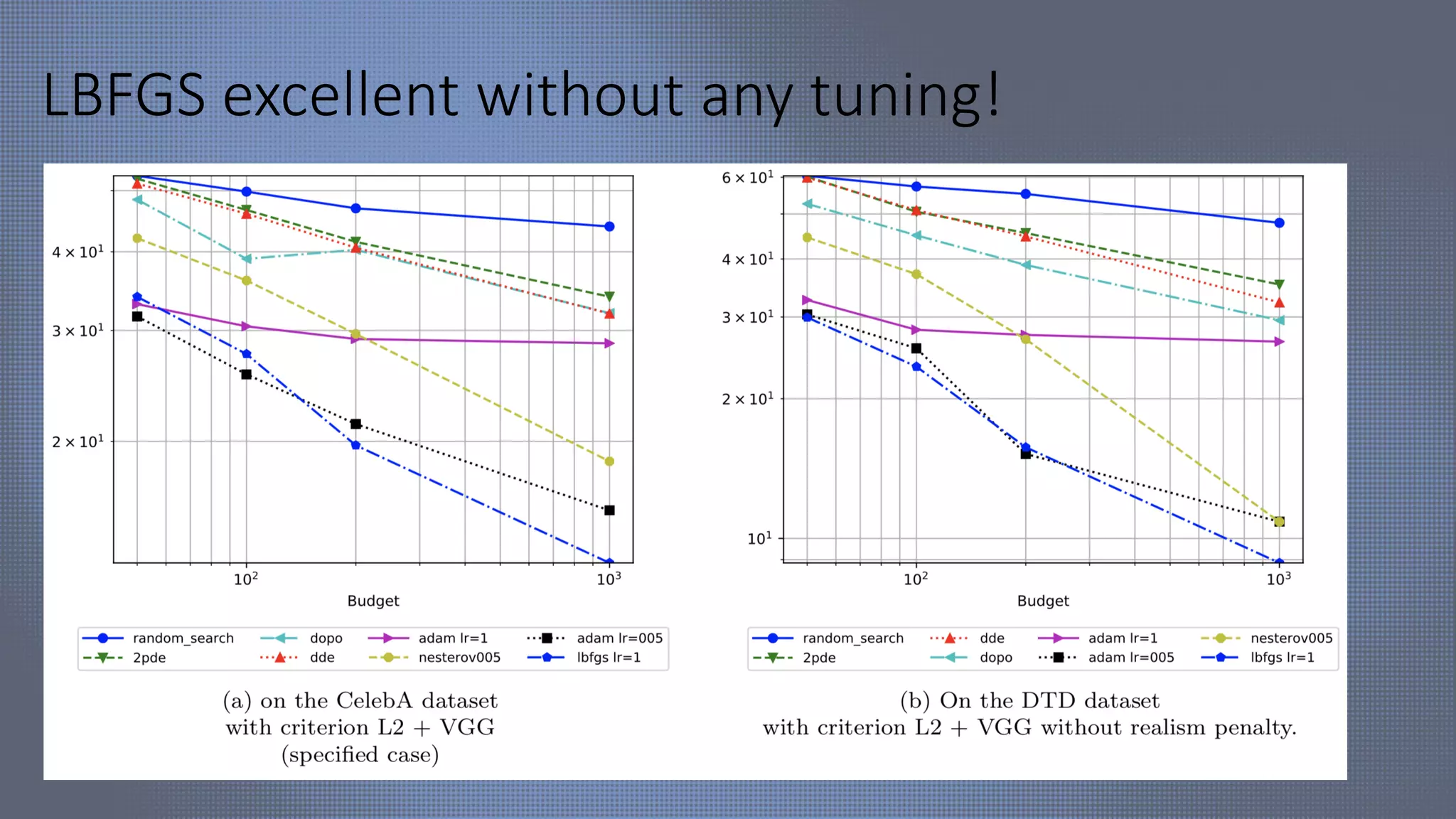
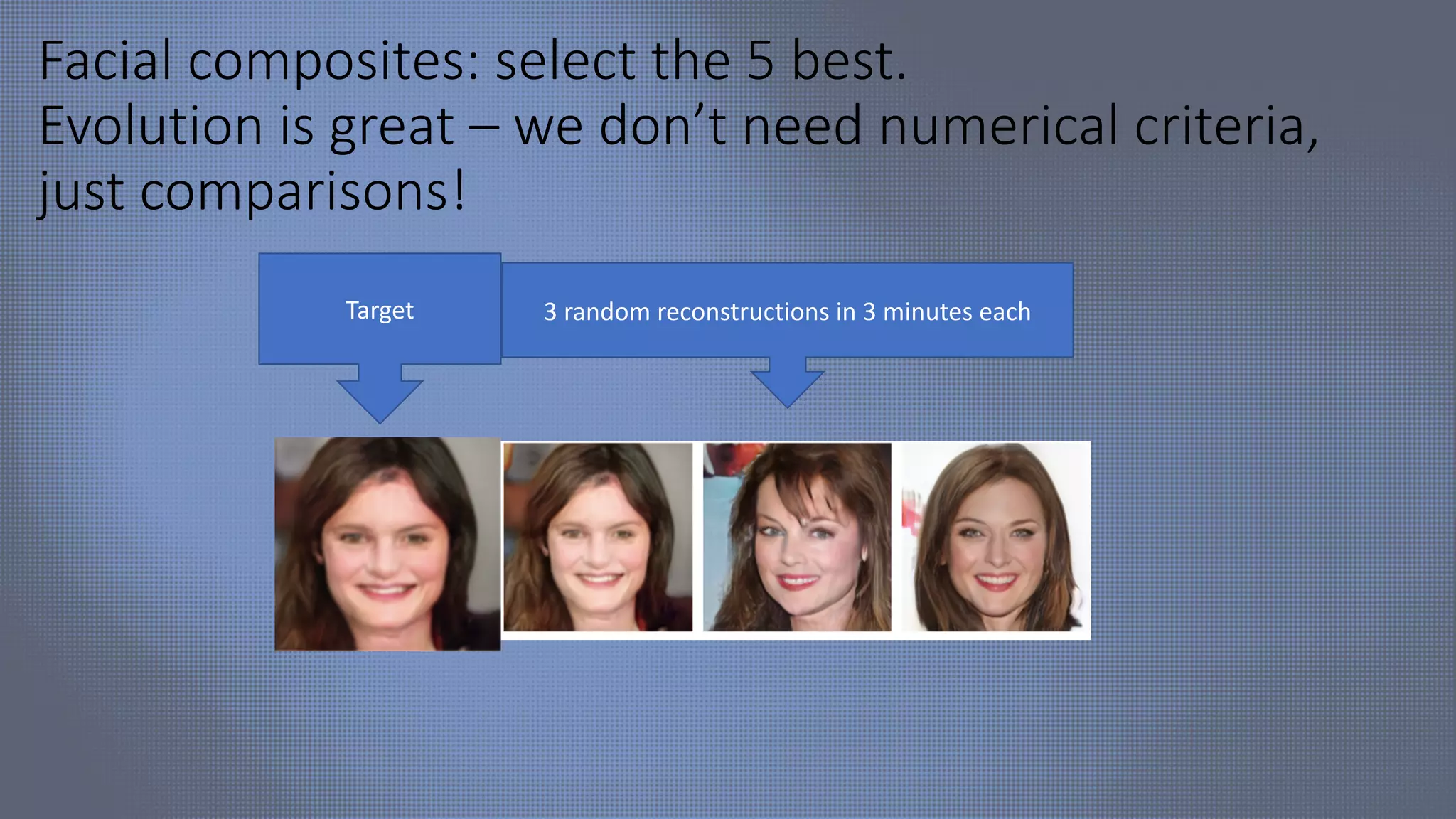
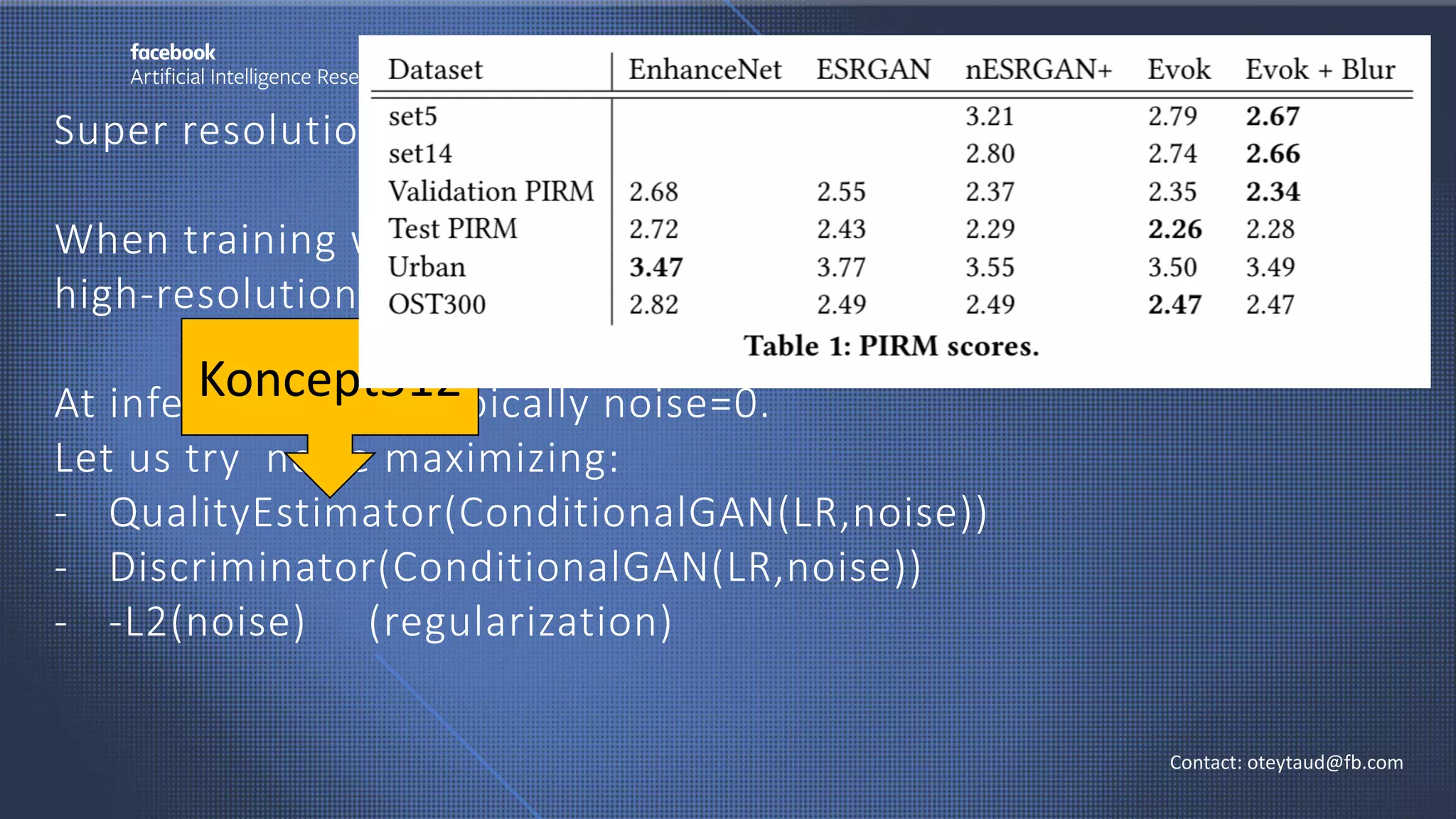
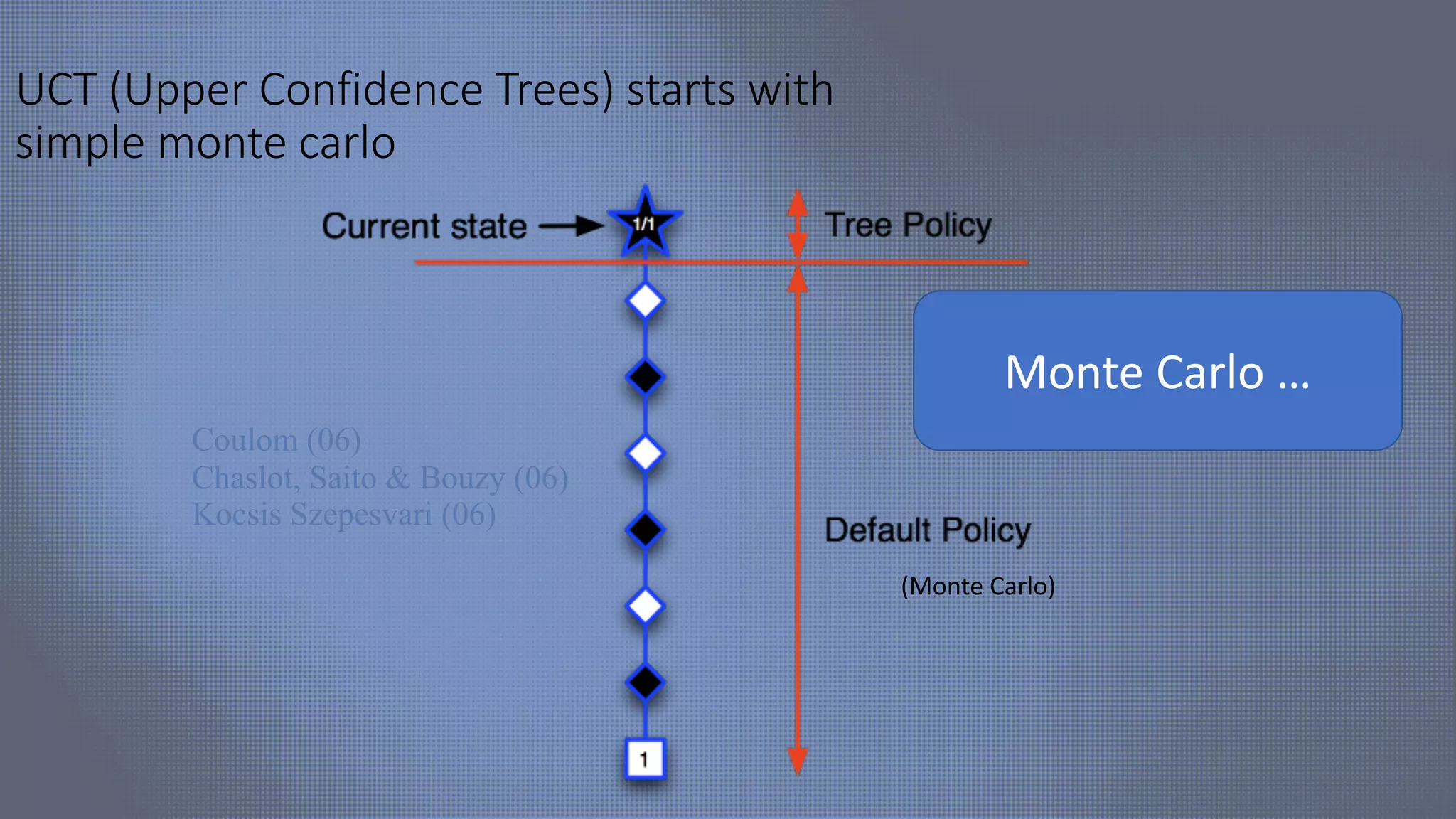
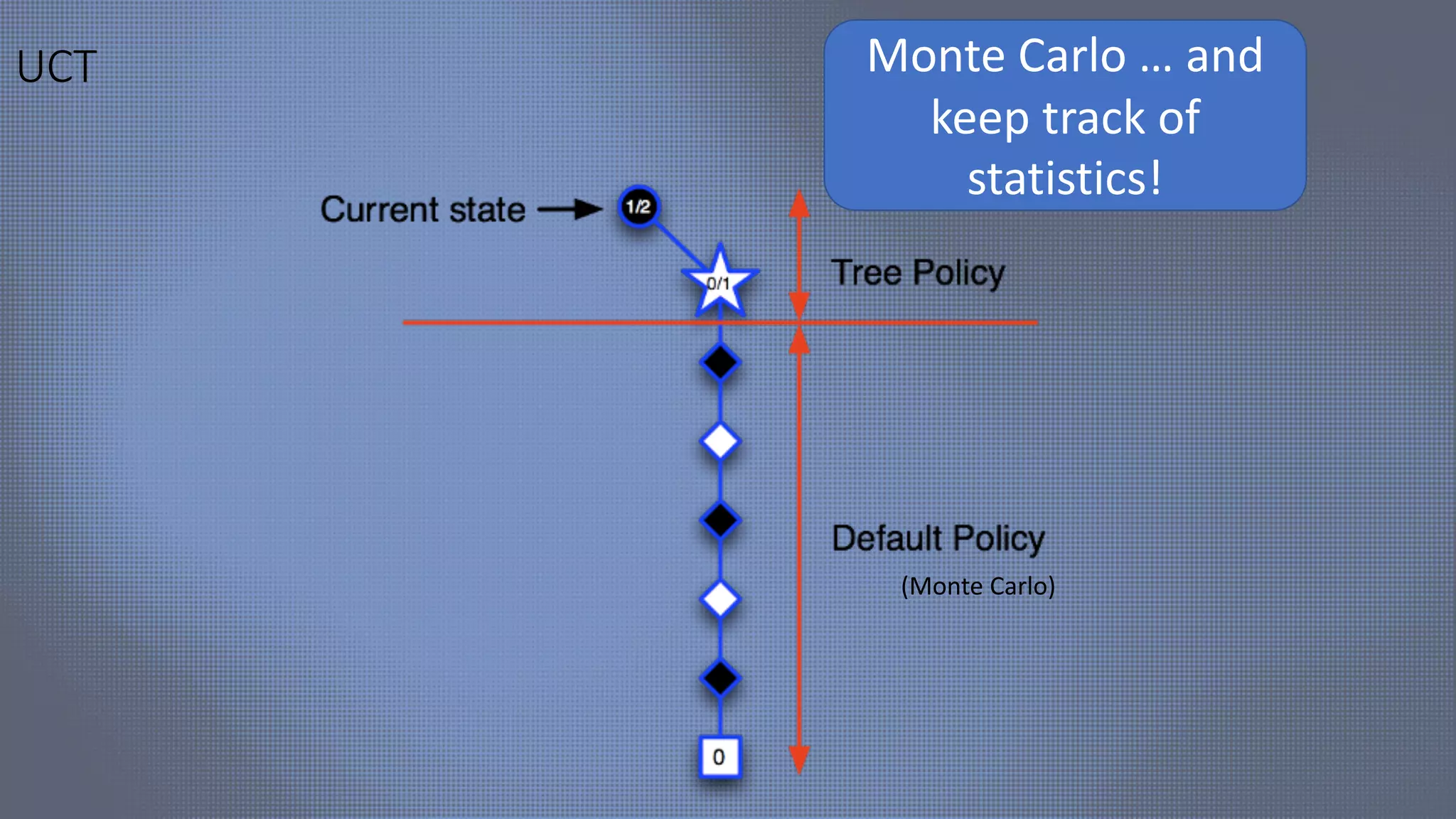
The document discusses evolutionary computer vision and derivative-free optimization methods, highlighting applications such as adversarial attacks, hyperparameter evolution, and generative adversarial networks (GANs). It features contributions from various researchers associated with Facebook AI Research and emphasizes the effectiveness of evolutionary strategies in optimization tasks. Additionally, the document touches on the significance of using comparison-based evaluations, particularly in the context of artistic and fashion generation.















































