Downloaded 17 times



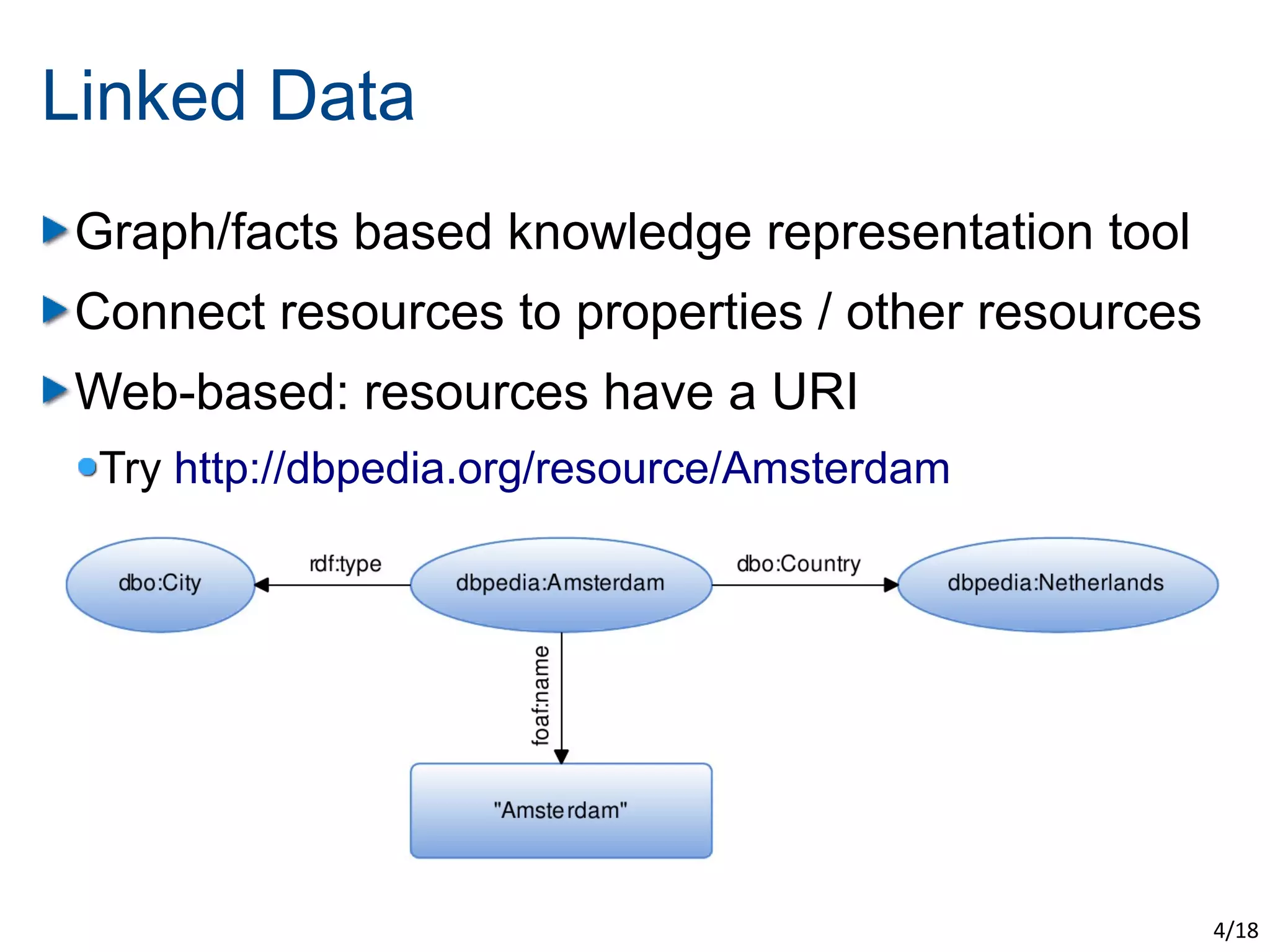




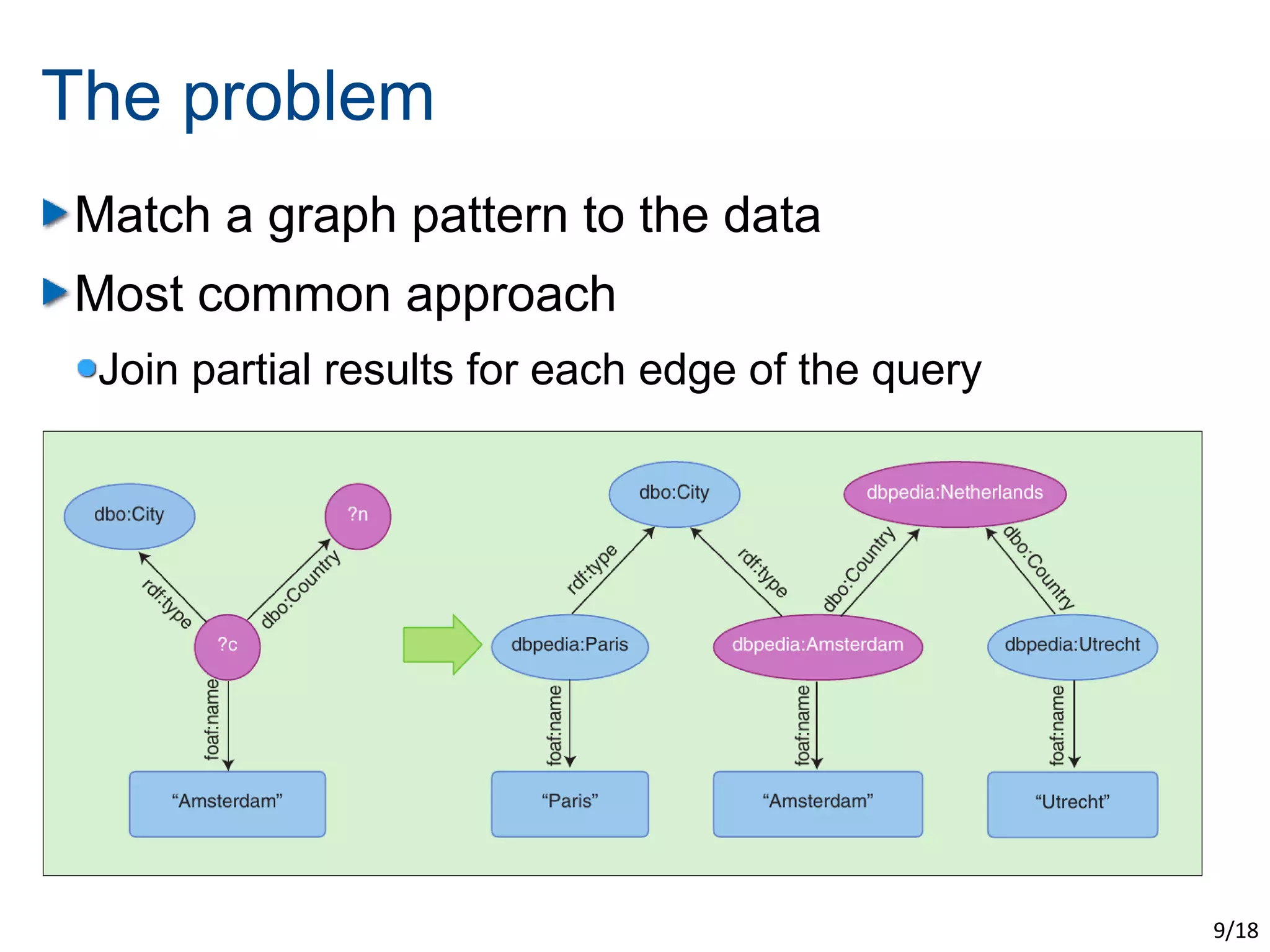

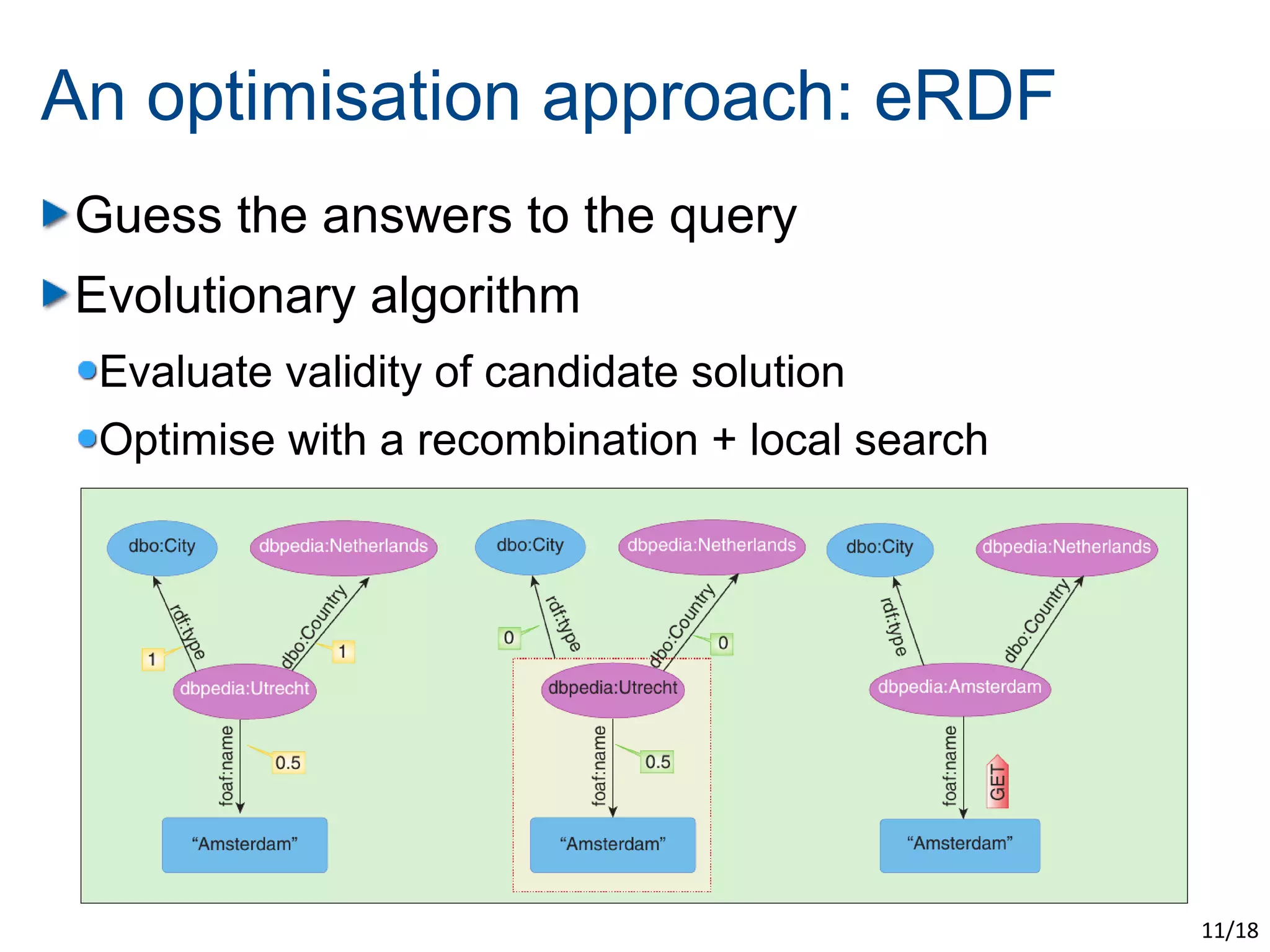
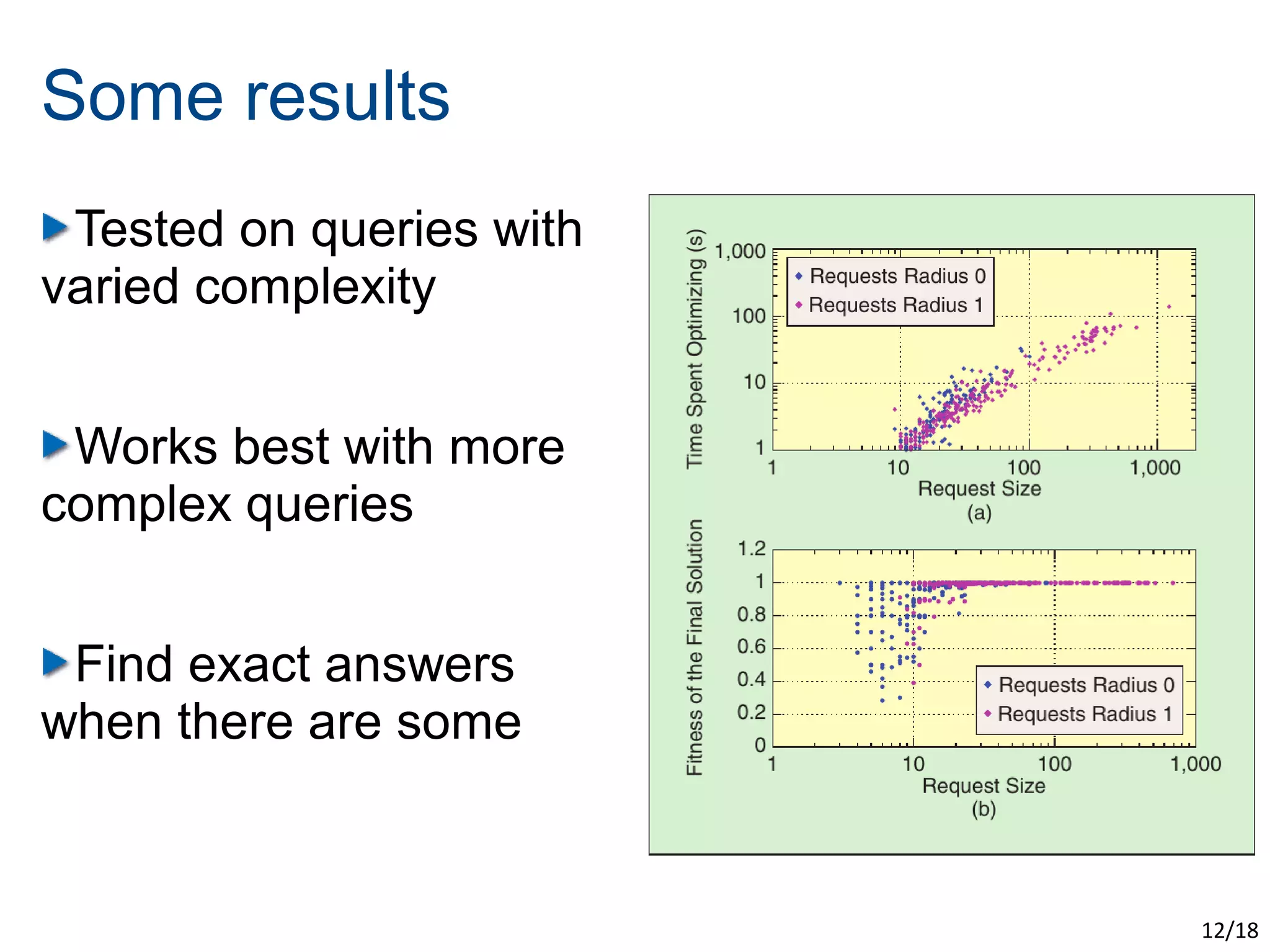

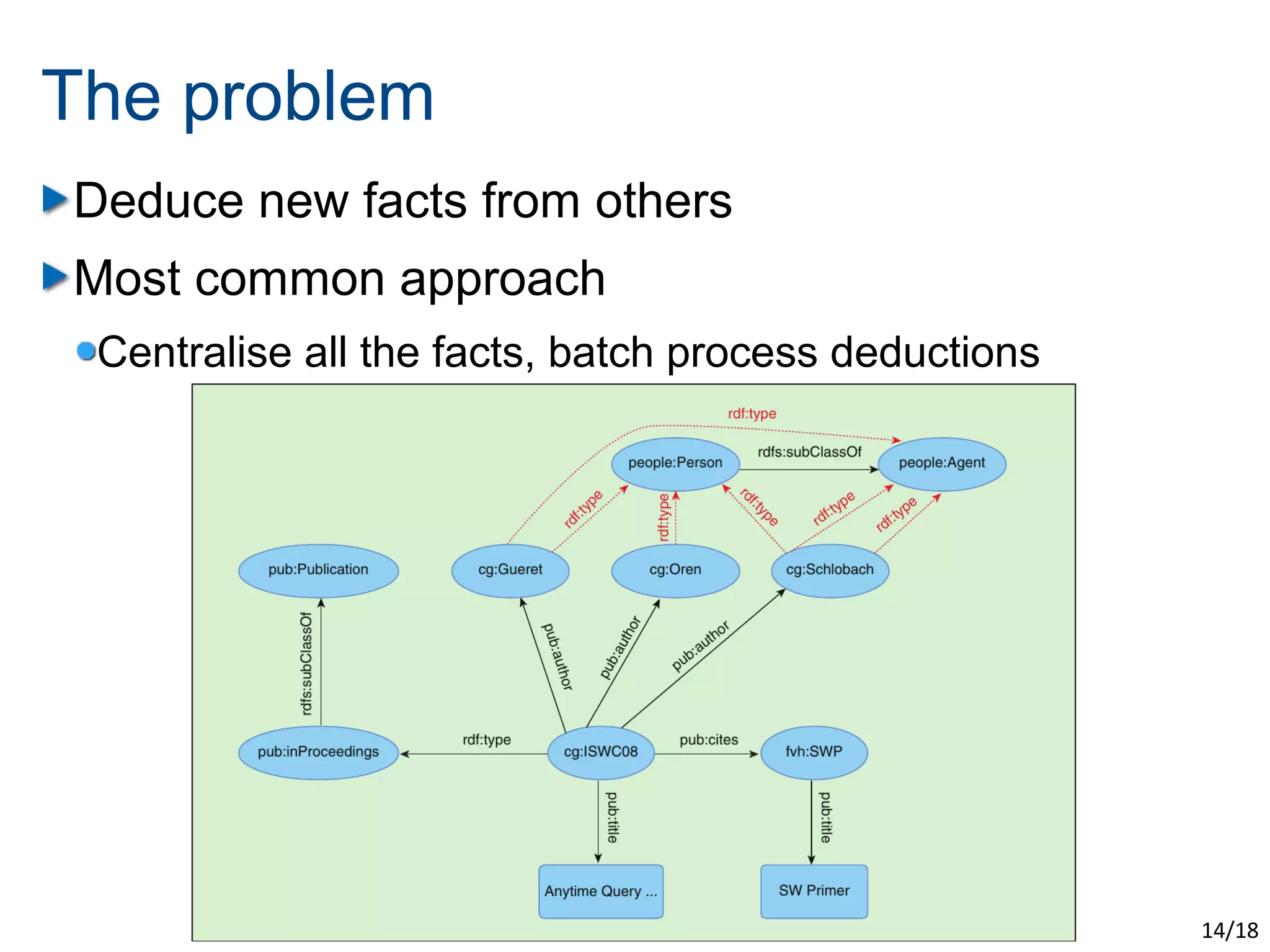

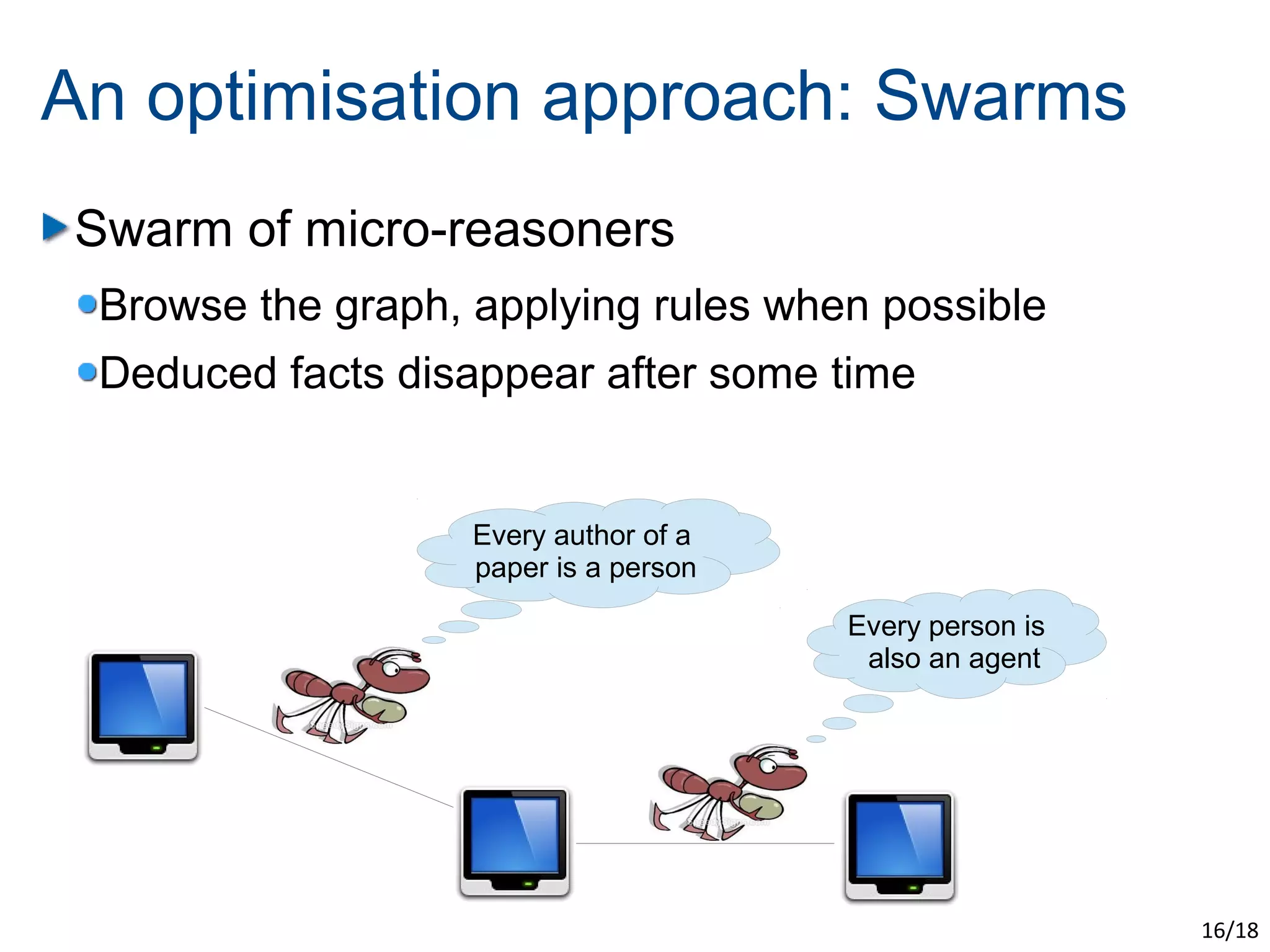
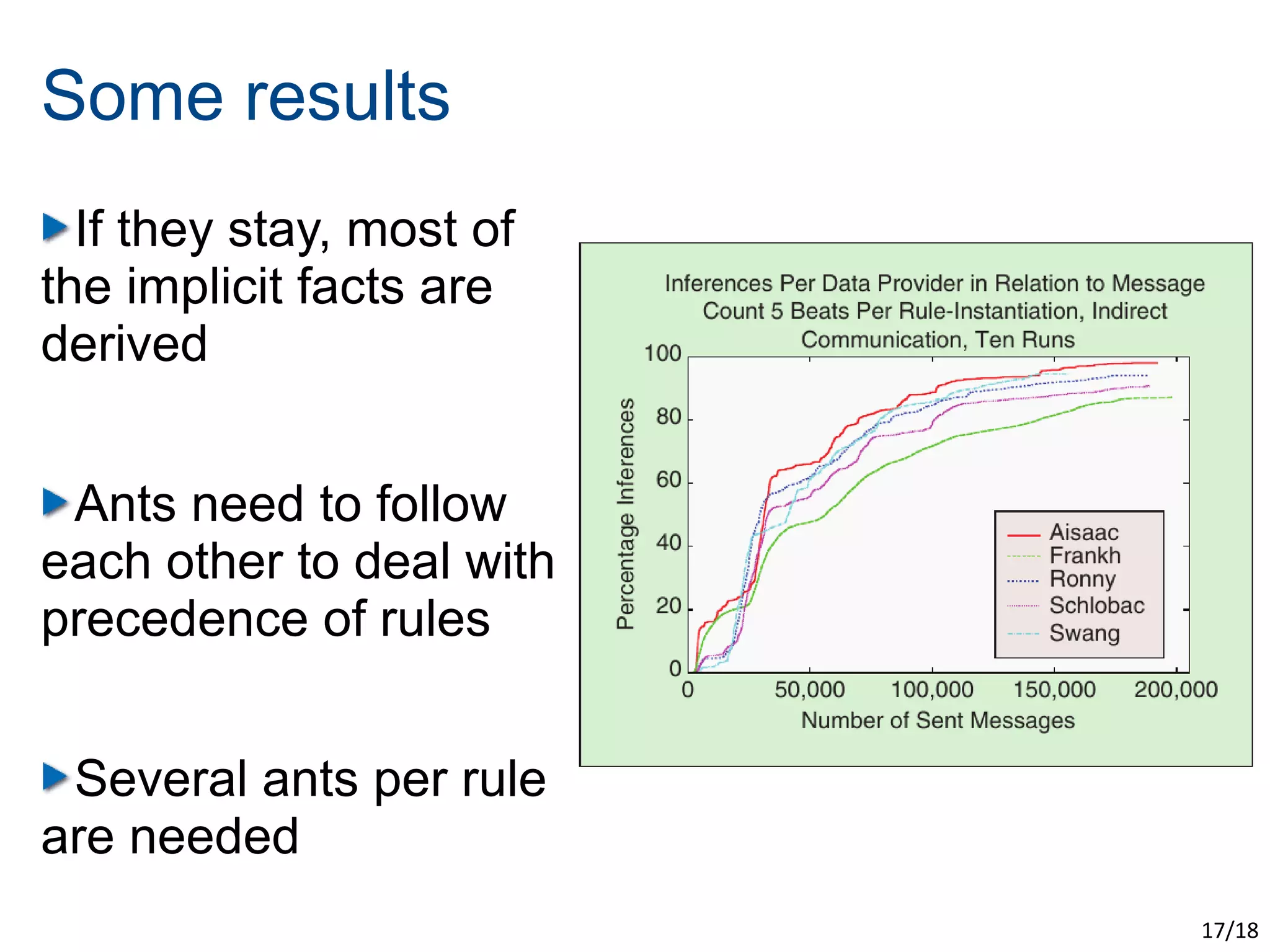


The document discusses the challenges of scaling up the Semantic Web through evolutionary and swarm computing techniques. It emphasizes optimizing logical deduction to manage issues like data consistency and completeness, and presents two examples: an evolutionary approach using algorithms to guess answers and a swarm-based model for deducing facts. The conclusion highlights the trade-offs of applying optimization, including increased scalability and speed at the expense of determinism and completeness.


![[db tech showcase Tokyo 2018] #dbts2018 #B16 『The Basics of Machine Learning』](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018b16helithebasicsofmachinelearning-180929170809-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































