




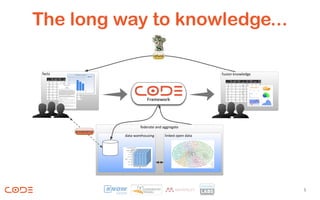










The document presents a framework for a big data benchmarking project aimed at improving access to unstructured data. It outlines the project's three steps: analyzing data, lifting and extending it to a linked data cloud, and creating user-friendly interaction methods for data exploration. Funded by the European Commission, the initiative seeks to enhance the quality and usability of data generated in various research domains.

















































































