Download as PDF, PPTX










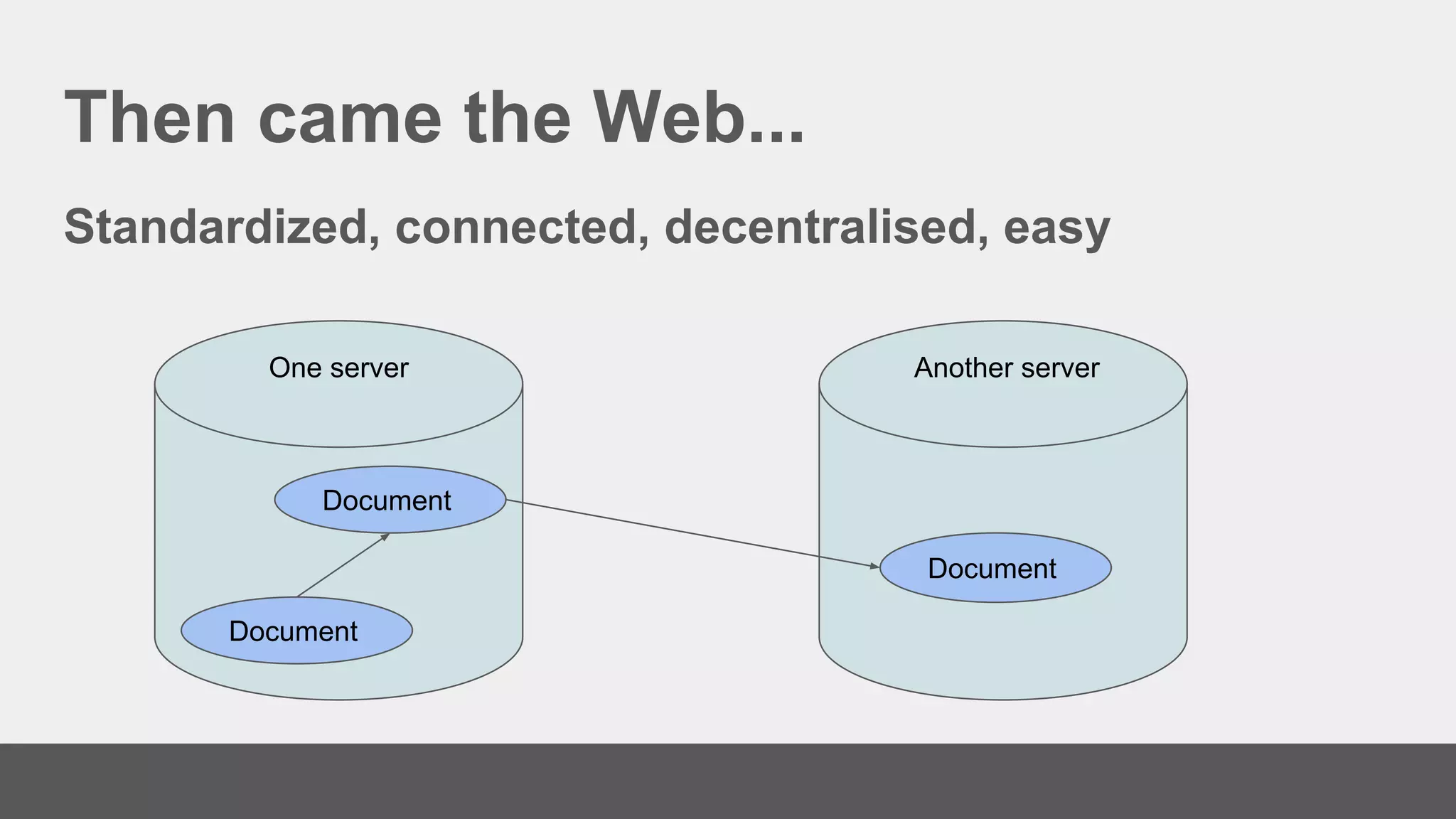








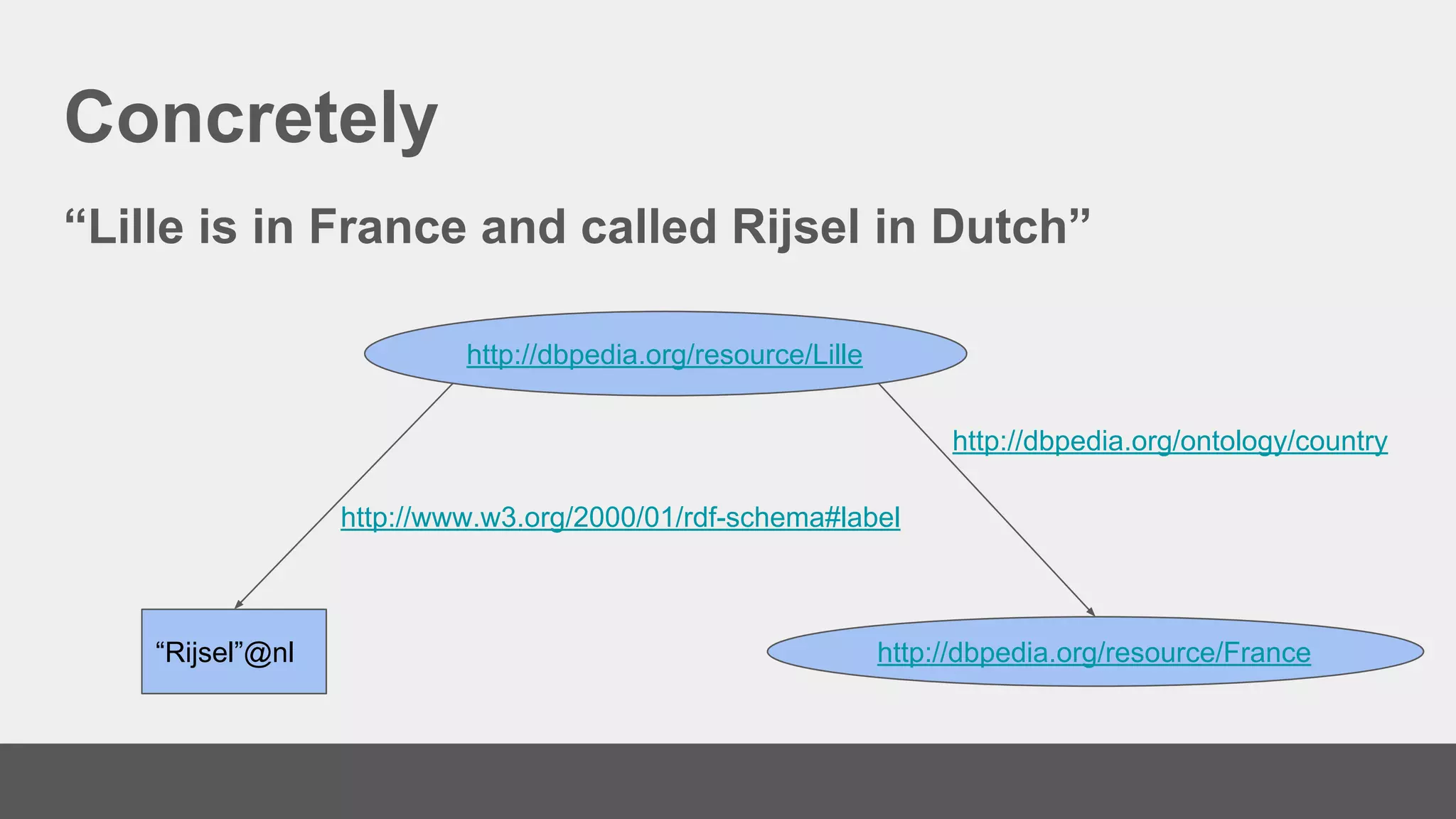















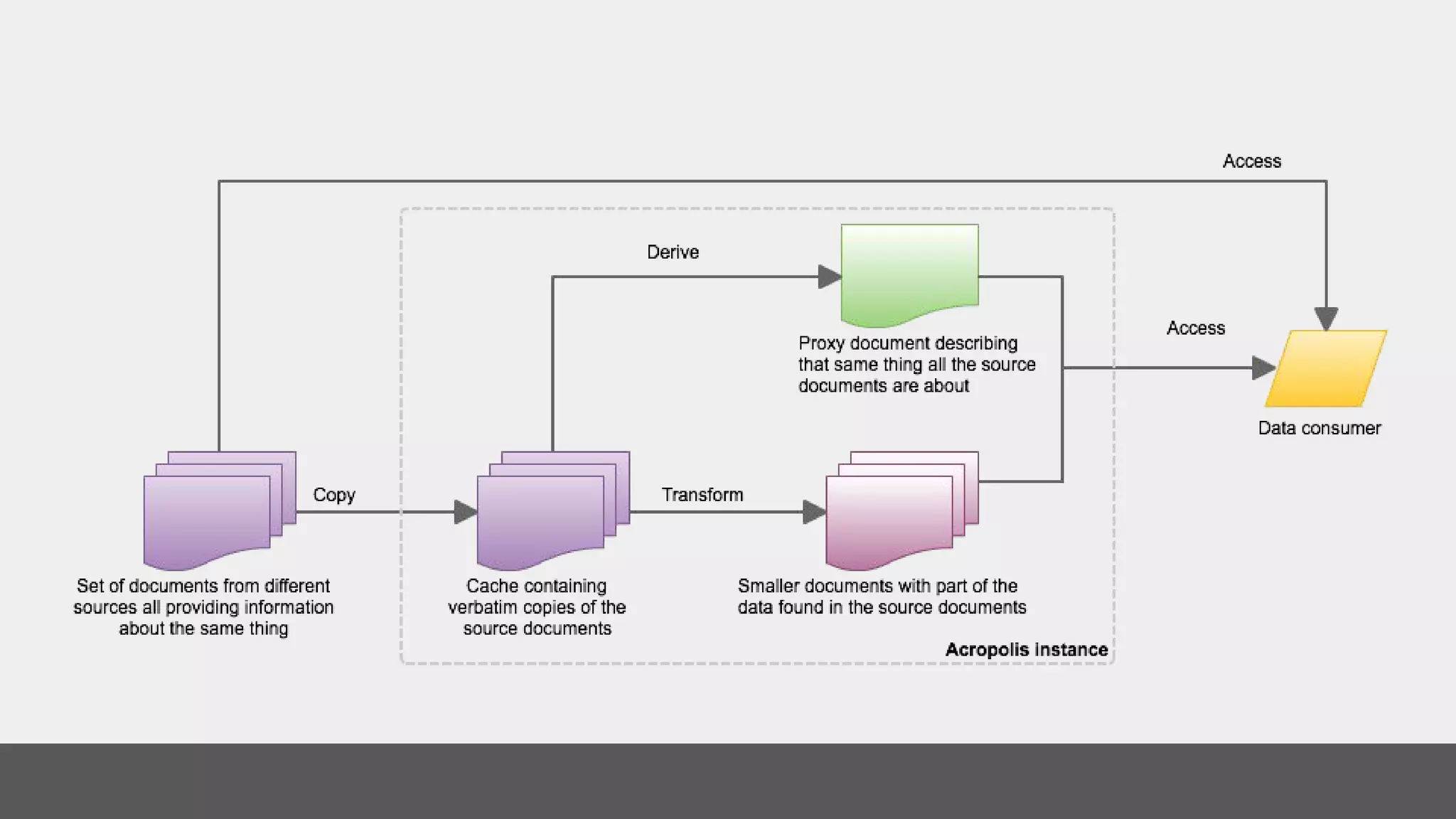
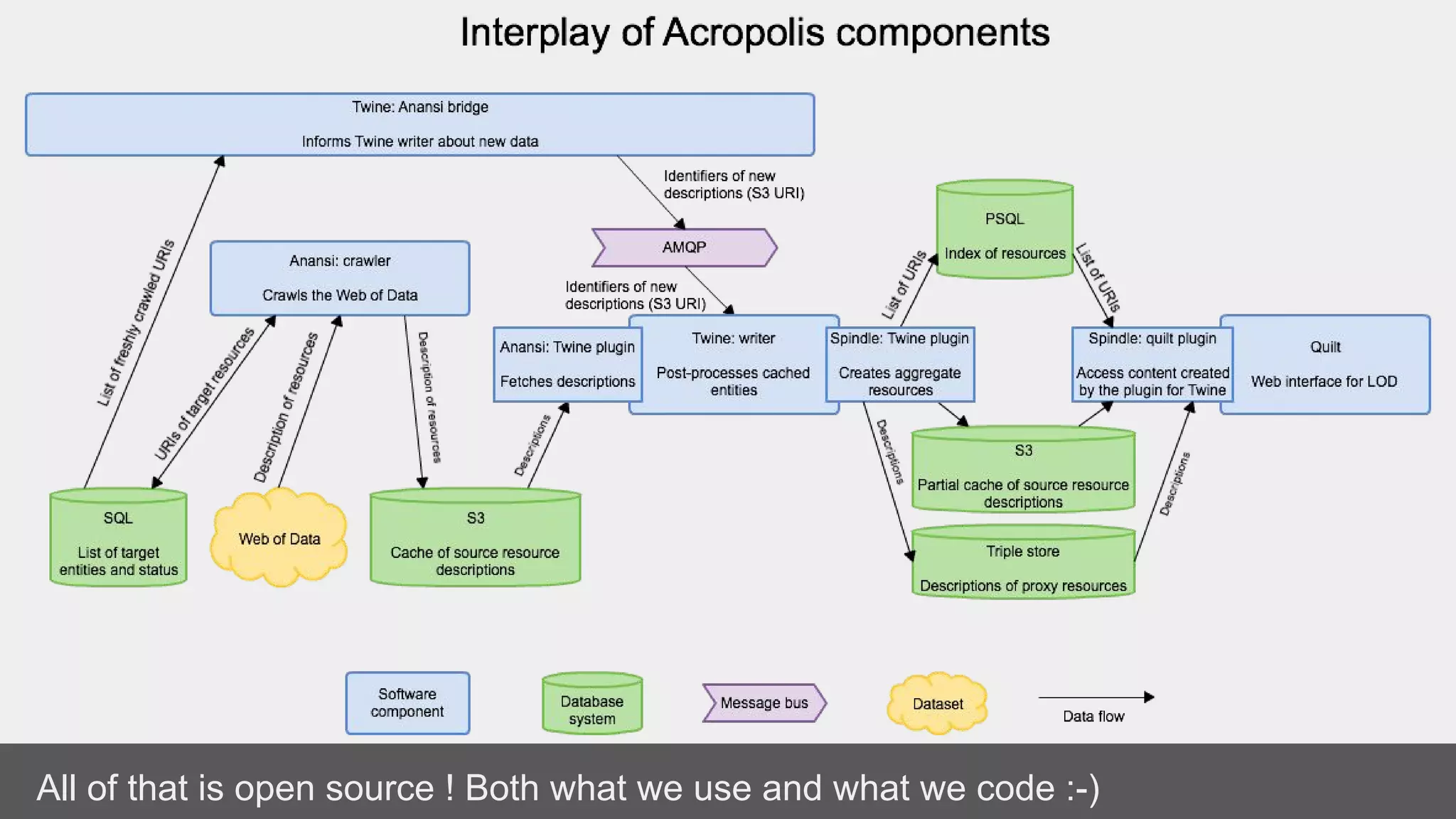


The document discusses linked data, its methods, and its applications in the research and education space, highlighting the transition from handling documents to managing data on the web. It emphasizes the importance of using identifiers, creating links, and the role of vocabularies in semantic web practices. Additionally, it outlines how the research and education space assists GLAM organizations in publishing linked open data and indexing for search interfaces.
























































































