An Efficient Approach to Data Clustering Using the K-Means Algorithm in Big Data Analytics.pptx
1.
An Efficient Approachto Data
Clustering Using the K-Means
Algorithm in Big Data Analytics
AUTHORS : S. SANDHIYA VANI, P. ARUN PRAKASH, RAMYA P, MALLADI CHANTI,
Y. NAGENDAR, ATHIRAJAATHEESWARAN
1
2.
Introduction
Importance inBig Data Analytics: Data clustering is essential for identifying patterns and
segmenting large datasets, enabling more insightful analysis across industries like finance,
healthcare, and e-commerce.
Popularity of K-Means: The K-Means algorithm is widely used for its simplicity, efficiency,
and ability to organize similar data points into clusters, making it a go-to method for clustering
in data analytics.
Limitations of Standard K-Means: Despite its advantages, K-Means faces challenges with
scalability, computational cost, and sensitivity to initial centroids, which can lead to suboptimal
clustering in large, high-dimensional datasets.
2
3.
Problem Statement
ScalabilityChallenges: The standard K-Means algorithm struggles to handle large datasets
efficiently, as the computational cost increases significantly with dataset size and complexity,
leading to long processing times.
Initialization Sensitivity: K-Means is highly sensitive to the initial placement of centroids,
which can result in convergence to local minima and produce suboptimal clusters, especially
with high-dimensional data.
Computational Complexity: As datasets grow in dimensionality, the algorithm’s computational
demands increase, which hinders its effectiveness and limits its application in big data
environments without further optimization.
3
4.
Objective
Performance Enhancementof K-Means: The primary aim is to improve the efficiency
and accuracy of the K-Means algorithm for big data applications.
Reducing Processing Costs: Implement dimensionality reduction and optimized
initialization techniques to minimize computational resources and shorten execution
time.
Improving Clustering Accuracy: Apply advanced initialization and preprocessing
methods to enhance clustering quality, ensuring more precise data segmentation even in
high-dimensional datasets.
4
5.
Literature Review
ExistingK-Means Adaptations: Numerous adaptations of the K-Means algorithm have been
proposed to address its limitations, including parallel and distributed versions for scalability,
which help process large datasets more efficiently.
Dimensionality Reduction Techniques: Techniques like Principal Component Analysis (PCA)
are frequently used to reduce data dimensionality before clustering, which lowers computational
requirements and enhances clustering accuracy by focusing on essential features.
Improved Initialization Methods: Advanced initialization techniques, such as K-Means++,
strategically select initial centroids to reduce the number of iterations needed for convergence
and improve the overall quality of the clusters.
5
6.
Proposed Solution
EnhancedK-Means Approach: This solution builds upon the standard K-Means by
integrating optimizations that address its scalability and accuracy limitations,
making it suitable for big data analytics.
Dimensionality Reduction with PCA: Principal Component Analysis (PCA) is used
to reduce the dimensionality of large datasets, retaining only the most significant
features, which helps streamline computations and improve clustering efficiency.
Optimized Centroid Initialization: An advanced initialization method is
implemented to strategically select centroids, ensuring faster convergence and
creating more accurate clusters compared to the traditional random initialization
approach.
6
7.
Methodology Overview
StructuredPipeline: The methodology follows a systematic approach with key stages—data collection,
preprocessing, model selection, and evaluation—ensuring a consistent, scalable process for clustering large
datasets.
Data Collection and Preprocessing: Relevant data features are gathered and normalized, preparing them for
effective dimensionality reduction and clustering.
Integration of PCA and K-Means: Principal Component Analysis (PCA) reduces dataset dimensions,
followed by applying the optimized K-Means algorithm to create accurate and efficient clusters.
Model Evaluation: The clustering performance is assessed using metrics like the Confusion Matrix and ROC
Curve to validate accuracy and separation quality of the clusters.
7
8.
Data Preprocessing
FeatureExtraction: Key attributes relevant to clustering are selected from the dataset,
enhancing the model’s focus on significant information while reducing noise.
Normalization: Features are scaled to a common range (e.g., [0, 1]) through normalization,
ensuring that all attributes contribute equally to the clustering process and preventing any
single feature from dominating.
Principal Component Analysis (PCA): PCA is applied to reduce the dimensionality of the
dataset, retaining only the most meaningful components. This reduces computational
complexity and prepares the data for efficient clustering by focusing on the principal features
that capture the most variance in the data.
8
9.
Principal Component Analysis(PCA)
Role in Dimensionality Reduction: Principal Component Analysis (PCA)
transforms high-dimensional data into a lower-dimensional space by
projecting it onto a set of principal components that capture the
maximum variance, thus simplifying the dataset.
Lower Computational Complexity: By reducing the number of features,
PCA decreases the computational load, making clustering algorithms like
K-Means faster and more efficient when processing large datasets.
Improved Clustering Accuracy: PCA emphasizes the most important data
patterns, allowing the clustering algorithm to create clearer, more distinct
clusters by removing redundant or less significant information.
9
10.
K-Means Clustering
Initialization:The algorithm begins by selecting initial centroids, which are critical in
determining the quality and convergence of the clusters. This approach uses optimized
centroid initialization for faster convergence and better accuracy.
Cluster Assignment: Each data point is assigned to the nearest centroid based on
Euclidean distance, grouping similar points together. With PCA-reduced data, this step is
more efficient as it operates on fewer dimensions.
Centroid Update: The centroids are recalculated by taking the mean of all points within
each cluster, iterating until the centroids stabilize and no longer shift.
Enhancements with PCA-Reduced Data: By applying K-Means to PCA-transformed data,
the clustering process becomes more computationally efficient and produces clearer, more
accurate clusters due to the reduced dimensionality and focus on essential features.
10
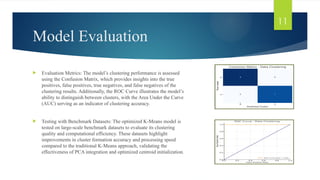
11.
Model Evaluation
EvaluationMetrics: The model’s clustering performance is assessed
using the Confusion Matrix, which provides insights into the true
positives, false positives, true negatives, and false negatives of the
clustering results. Additionally, the ROC Curve illustrates the model’s
ability to distinguish between clusters, with the Area Under the Curve
(AUC) serving as an indicator of clustering accuracy.
Testing with Benchmark Datasets: The optimized K-Means model is
tested on large-scale benchmark datasets to evaluate its clustering
quality and computational efficiency. These datasets highlight
improvements in cluster formation accuracy and processing speed
compared to the traditional K-Means approach, validating the
effectiveness of PCA integration and optimized centroid initialization.
11
12.
Results
Improved ClusteringAccuracy: The integration of PCA and optimized initialization in K-Means
led to a 15% increase in clustering accuracy, allowing for more precise grouping of data points
into distinct clusters.
Reduced Execution Time: The enhanced approach decreased execution time by 25%,
demonstrating significant efficiency gains when handling large datasets due to dimensionality
reduction and faster convergence.
Graphical Representations: Visuals such as bar charts or scatter plots illustrate the improvements
in cluster formation accuracy and separation, highlighting clearer boundaries between clusters
and the algorithm’s overall effectiveness compared to the traditional K-Means method.
12
13.
Discussion
Comparison withTraditional K-Means: Unlike the standard K-Means, which struggles with large,
high-dimensional datasets, this enhanced approach efficiently handles big data by integrating PCA
and optimized centroid initialization.
Improved Scalability: The use of PCA reduces the data dimensions, making it feasible to apply the
K-Means algorithm to larger datasets without a proportional increase in computational demands.
Enhanced Accuracy and Computational Efficiency: By strategically initializing centroids and
focusing on principal components, this approach achieves a 15% improvement in clustering
accuracy and a 25% reduction in execution time, ensuring precise clusters and faster processing in
big data contexts.
13
14.
Conclusion and FutureWork
Summary of Contributions and Results: This research demonstrated that integrating
Principal Component Analysis (PCA) with an optimized K-Means algorithm enhances
clustering performance in big data applications. Key outcomes included a 15% increase
in clustering accuracy and a 25% reduction in execution time, validating the
effectiveness of this combined approach.
Future Research Suggestions: Further exploration could involve hybrid approaches that
integrate additional clustering algorithms or machine learning techniques to boost
accuracy and efficiency. Testing this method on even larger and more complex datasets
would also help assess scalability and refine the model for broader real-world
applications.
14







![Data Preprocessing
Feature Extraction: Key attributes relevant to clustering are selected from the dataset,
enhancing the model’s focus on significant information while reducing noise.
Normalization: Features are scaled to a common range (e.g., [0, 1]) through normalization,
ensuring that all attributes contribute equally to the clustering process and preventing any
single feature from dominating.
Principal Component Analysis (PCA): PCA is applied to reduce the dimensionality of the
dataset, retaining only the most meaningful components. This reduces computational
complexity and prepares the data for efficient clustering by focusing on the principal features
that capture the most variance in the data.
8](https://image.slidesharecdn.com/anefficientapproachtodataclusteringusingthek-meansalgorithminbigdataanalytics-250524071517-476d3ea5/85/An-Efficient-Approach-to-Data-Clustering-Using-the-K-Means-Algorithm-in-Big-Data-Analytics-pptx-8-320.jpg)










































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)






