Downloaded 34 times



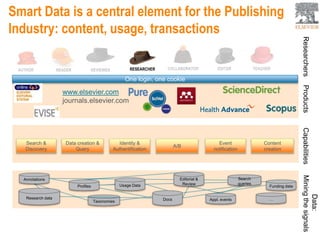

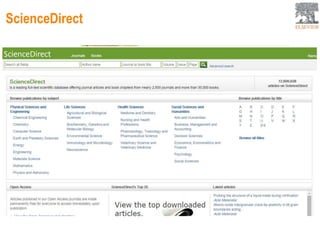
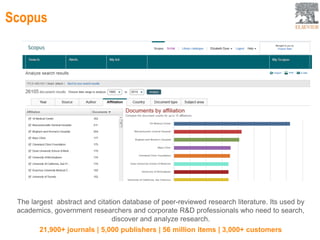
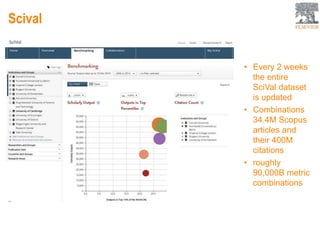






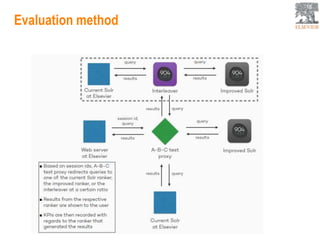
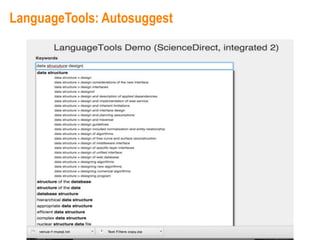





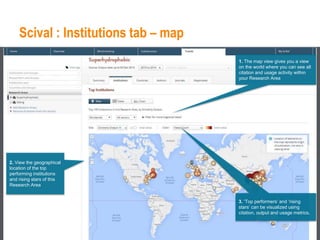
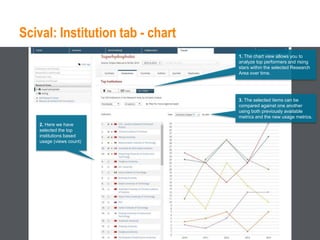


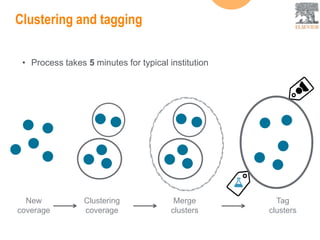

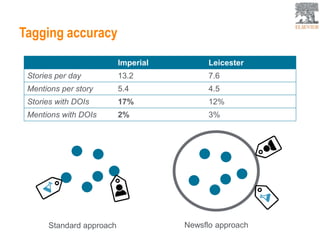

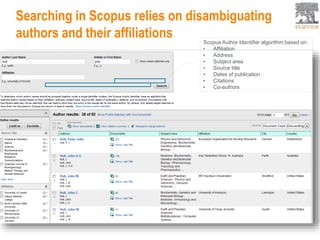


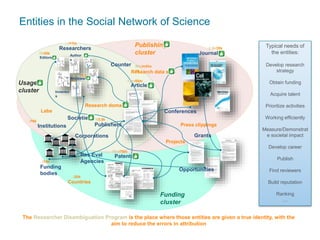




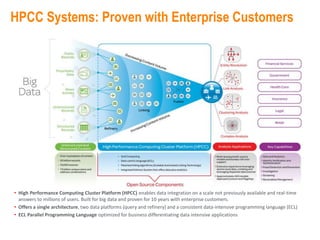
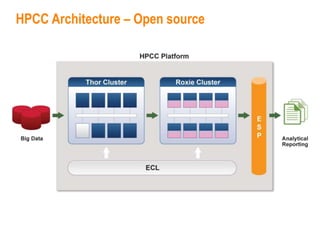
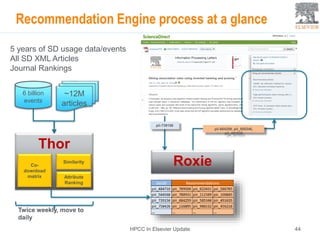






This document provides an overview of Elsevier's platforms and capabilities related to smart data and algorithms. It discusses how Elsevier uses data from its publications, authors, and readers to power platforms like ScienceDirect, Scopus, Mendeley, and recommendation engines. It also describes some of Elsevier's work using algorithms and machine learning, including entity fingerprinting, research trend analysis, and content recommendation. Elsevier aims to develop smart data capabilities that can benefit readers, editors, authors and other stakeholders across the publishing and research landscape.

















![The Right Metrics for Generation Open [Open Access Week 2014]](https://cdn.slidesharecdn.com/ss_thumbnails/bpr2cyg7tkadlxkbr9lo-signature-49a229ccc192ecfdd279541f6016379be3d277ac873aafea168a8257eb161f85-poli-141023162319-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



































