[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략
1.
양승도, Sr. Mgr,Solutions Architect
Data Freedom을 위한
Database 최적화 전략
2.
본 강연에서 다룰내용
▪ Data Freedom, 왜?
▪ Data Freedom, 무엇인가?
▪ Data Freedom, 어떻게?
▪ Use the right tool
▪ Utilize the managed services
▪ Database migration
▪ Data Lake
▪ 실제 적용 사례
▪ Call to Action !
그러나, 그 결과는침체…
감사에 대한
두려움
AUDIT
독점적
소유권
속박되고 형벌적
라이센싱
아주 비싸고
6.
Monolithic Architecture
“아마존닷컴은 10년전(1995년) 웹 서버와 데이터베이스 백엔드를 가지는
모놀리식(Monolithic) 애플리케이션 이었습니다.”
A Conversation with Werner Vogels , 2006
http://queue.acm.org/detail.cfm?id=1142065
10년 전부터 시작된변화
▪ 오픈소스 데이터베이스 시스템이 성숙하기 시작
▪ 관리형 데이터베이스 서비스가 가능
▪ 스토리지는 더 이상 데이터 아키텍쳐의 제약사항이 아님
▪ Cloud?
▪ DevOps?
▪ Microservices?
10.
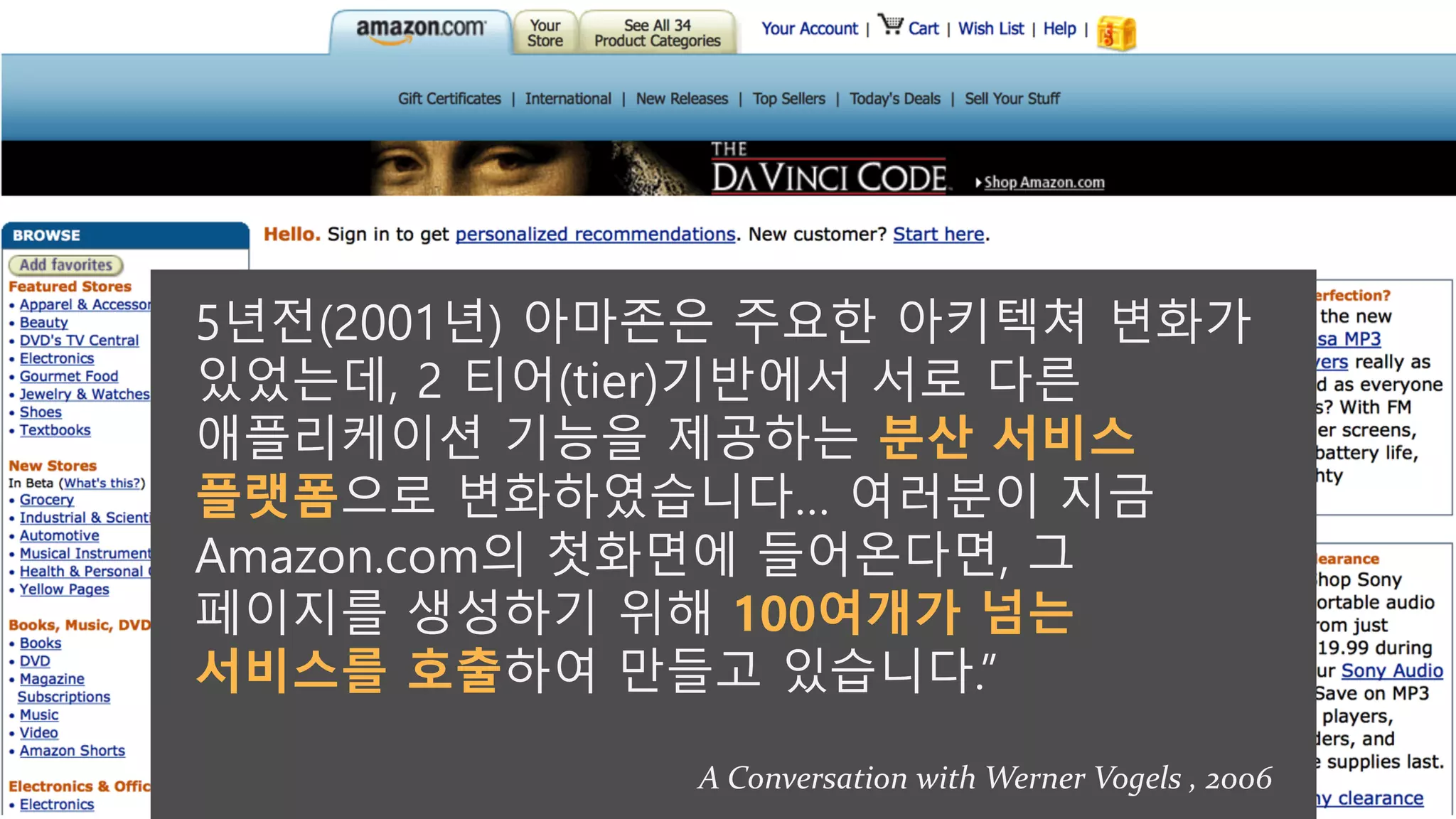
5년전(2001년) 아마존은 주요한아키텍쳐 변화가
있었는데, 2 티어(tier)기반에서 서로 다른
애플리케이션 기능을 제공하는 분산 서비스
플랫폼으로 변화하였습니다… 여러분이 지금
Amazon.com의 첫화면에 들어온다면, 그
페이지를 생성하기 위해 100여개가 넘는
서비스를 호출하여 만들고 있습니다.”
A Conversation with Werner Vogels , 2006
상용 데이터베이스로 부터독립
지속적으로 증가하는 독점적인 상용 데이터베이스의 비용과 감사에 대한 위험으로 부터
독립할 수 있는 방안이 필요
기존 독점적인 사용
데이터베이스의 비용을 어떻게
줄일 수 있는지?
기존 독점적인 상용
데이터베이스는 감사의 위험이
상시 존재
비용 위험
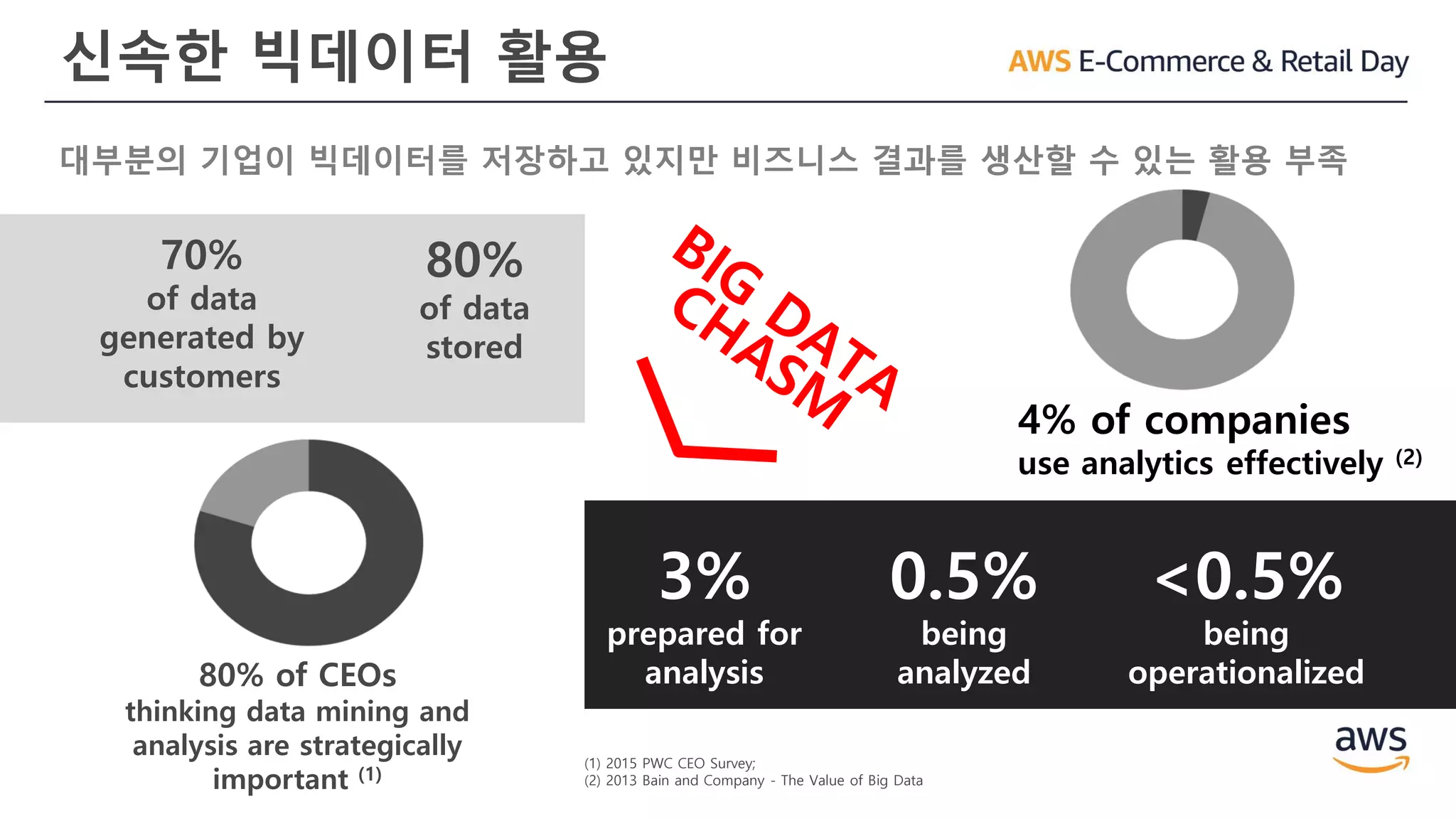
신속한 빅데이터 활용
대부분의기업이 빅데이터를 저장하고 있지만 비즈니스 결과를 생산할 수 있는 활용 부족
4% of companies
use analytics effectively (2)
70%
of data
generated by
customers
80%
of data
stored
3%
prepared for
analysis
0.5%
being
analyzed
<0.5%
being
operationalized80% of CEOs
thinking data mining and
analysis are strategically
important (1)
(1) 2015 PWC CEO Survey;
(2) 2013 Bain and Company - The Value of Big Data
15.
새로운 비즈니스 과제수행
최근 4차 산업혁명의 중요한 화두인 AI & Machine Learning 기반의 다양한 새로운 비즈니스
과제 수행을 위한 방법론 대두
이미지 패턴 분석 음성 인식 및
자연어 처리
자율 주행 자동차
16.
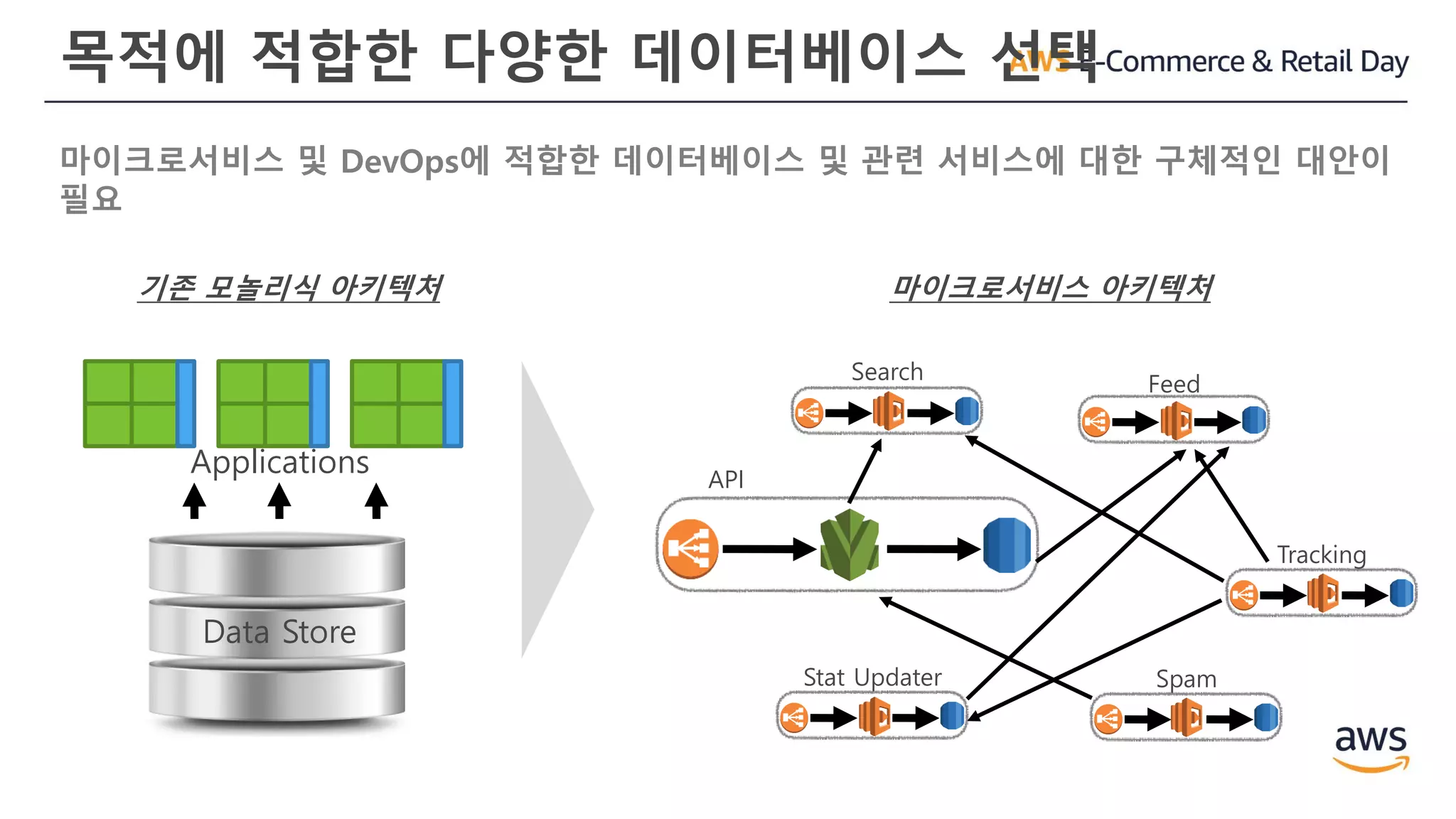
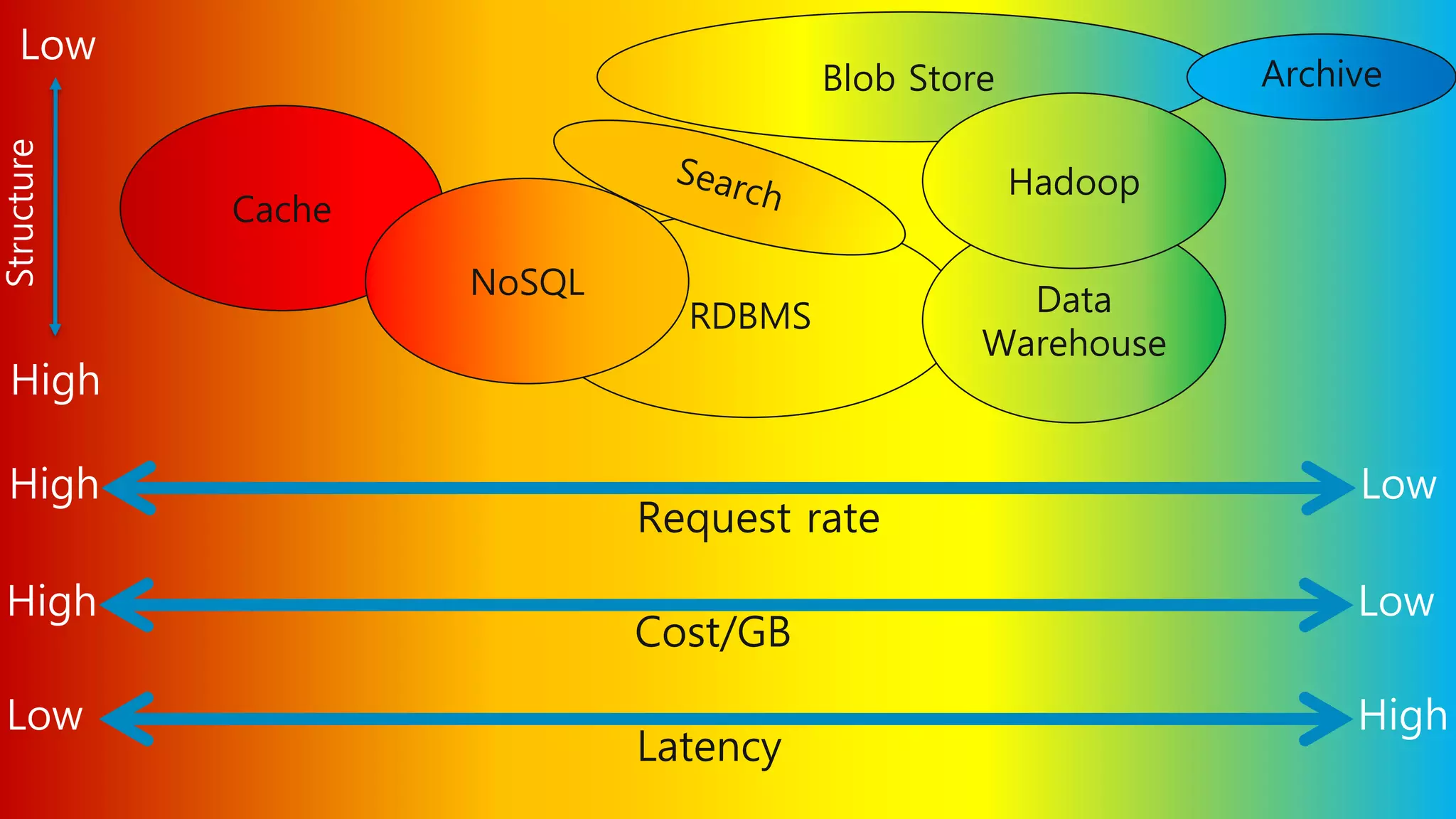
목적에 적합한 다양한데이터베이스 선택
마이크로서비스 및 DevOps에 적합한 데이터베이스 및 관련 서비스에 대한 구체적인 대안이
필요
Search
Feed
Tracking
SpamStat Updater
API
마이크로서비스 아키텍처기존 모놀리식 아키텍처
Data Store
Applications
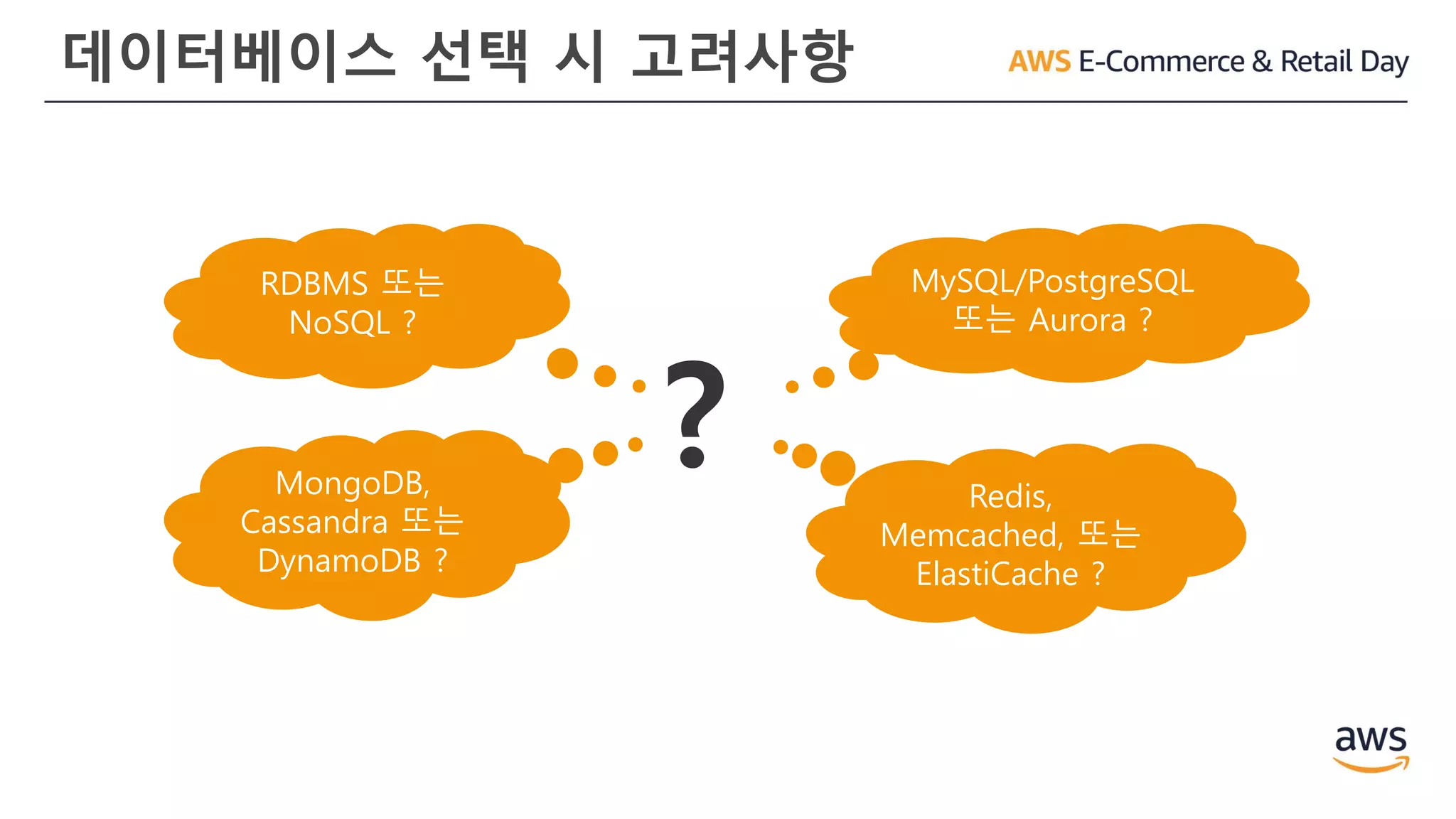
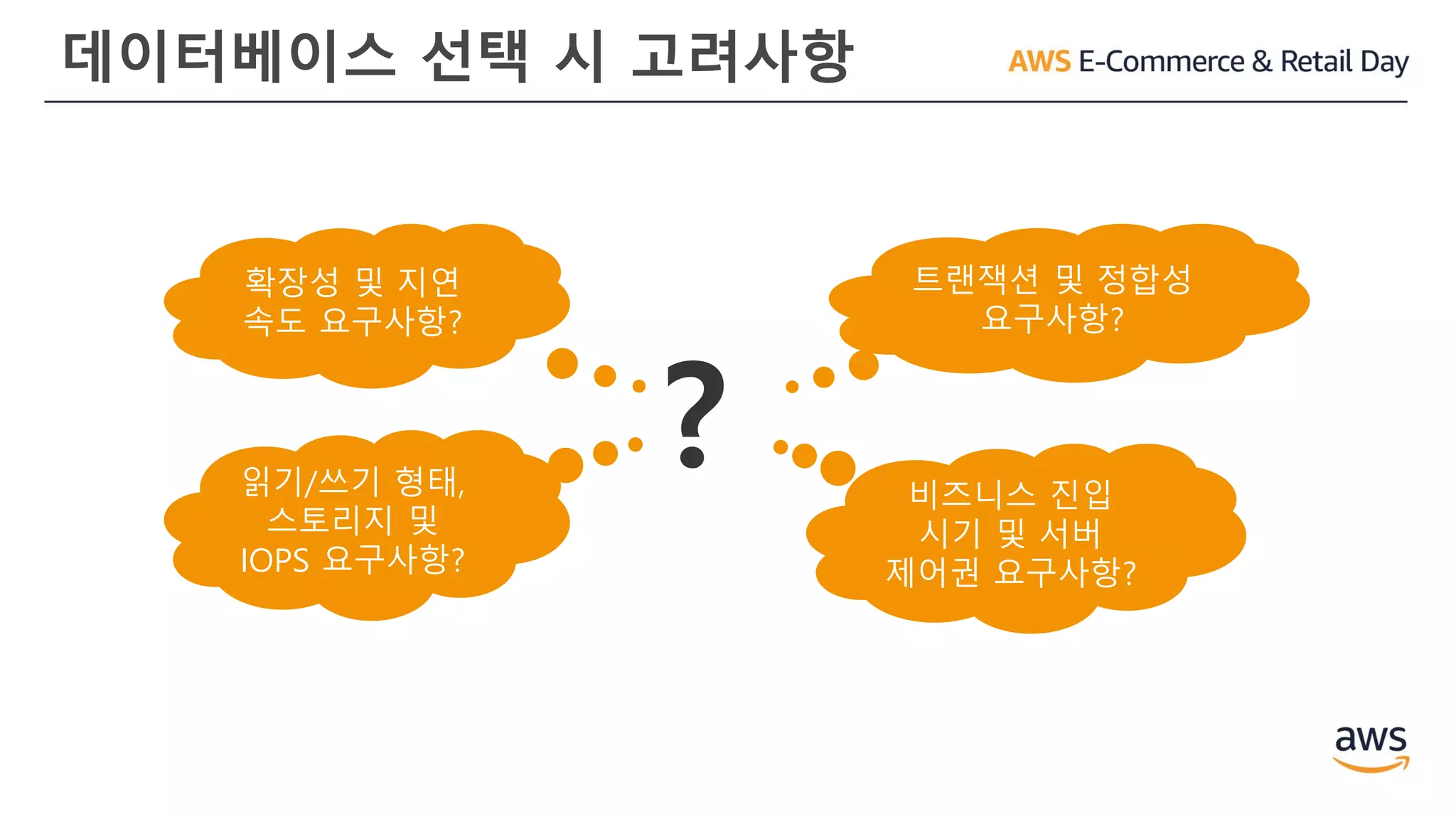
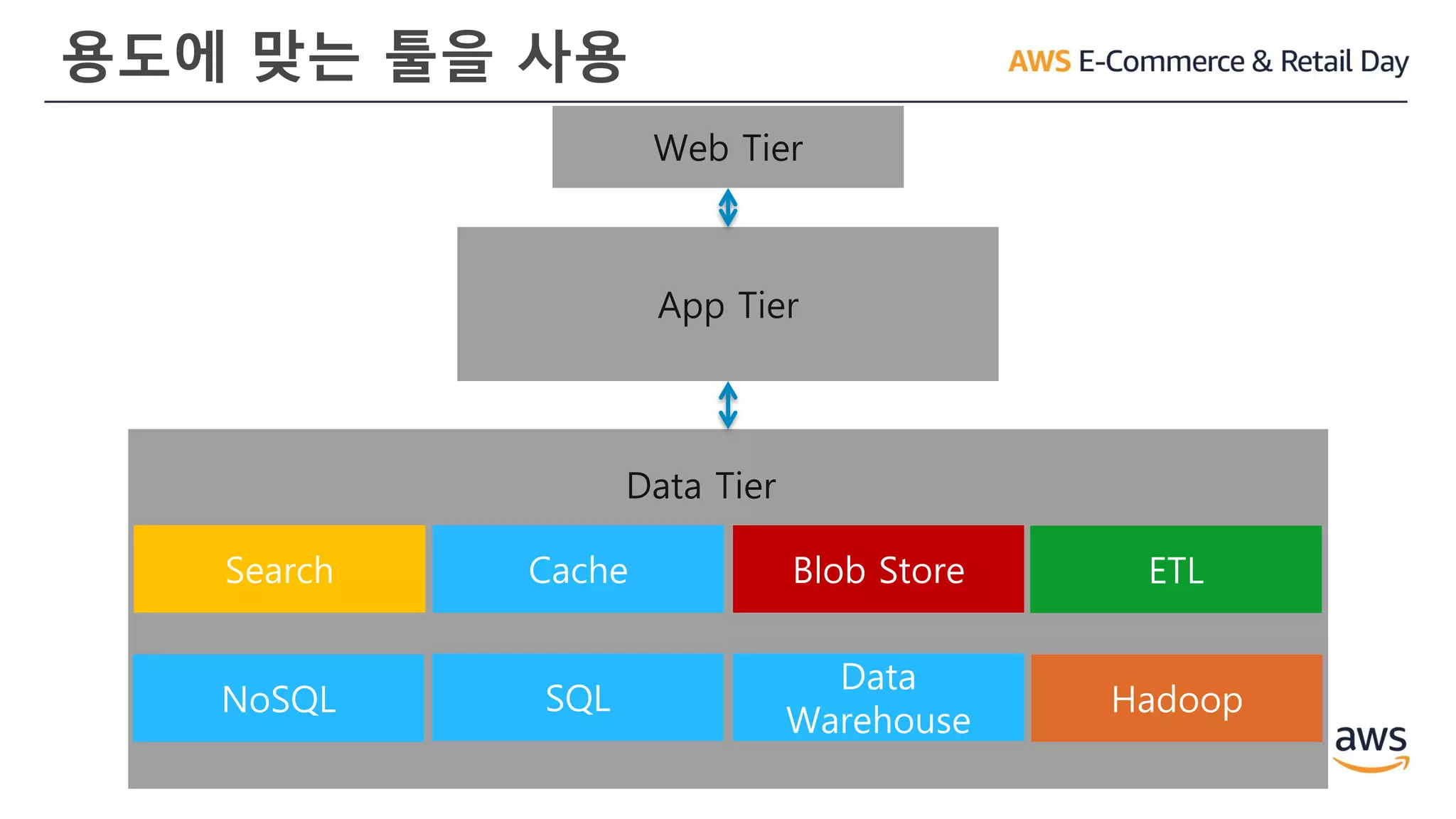
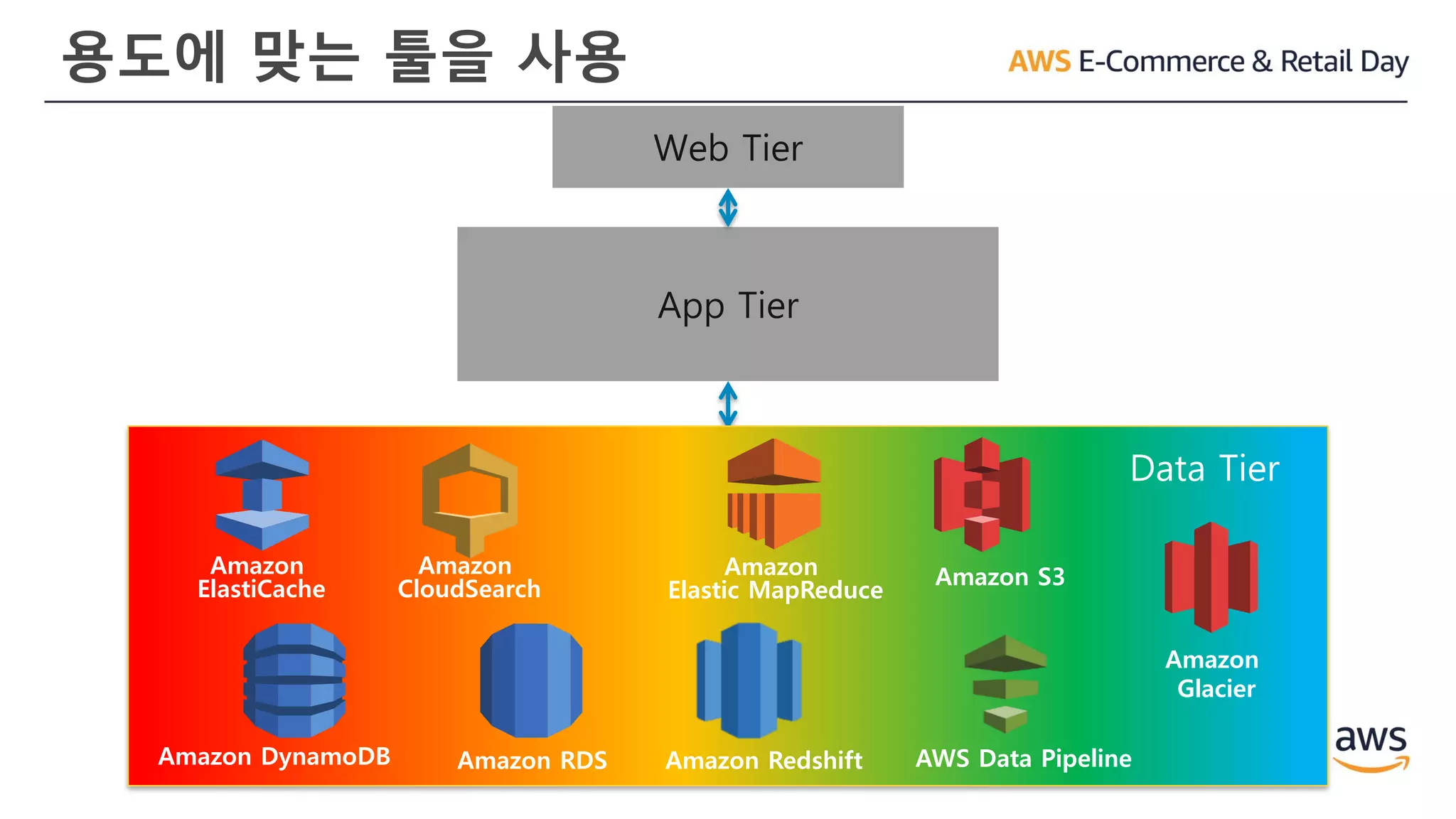
용도에 맞는 툴을사용
App Tier
Web Tier
Data Tier
Amazon RDS
Amazon
CloudSearch
Amazon DynamoDB
Amazon
ElastiCache
Amazon
Elastic MapReduce
Amazon S3
Amazon
Glacier
Amazon Redshift AWS Data Pipeline
24.
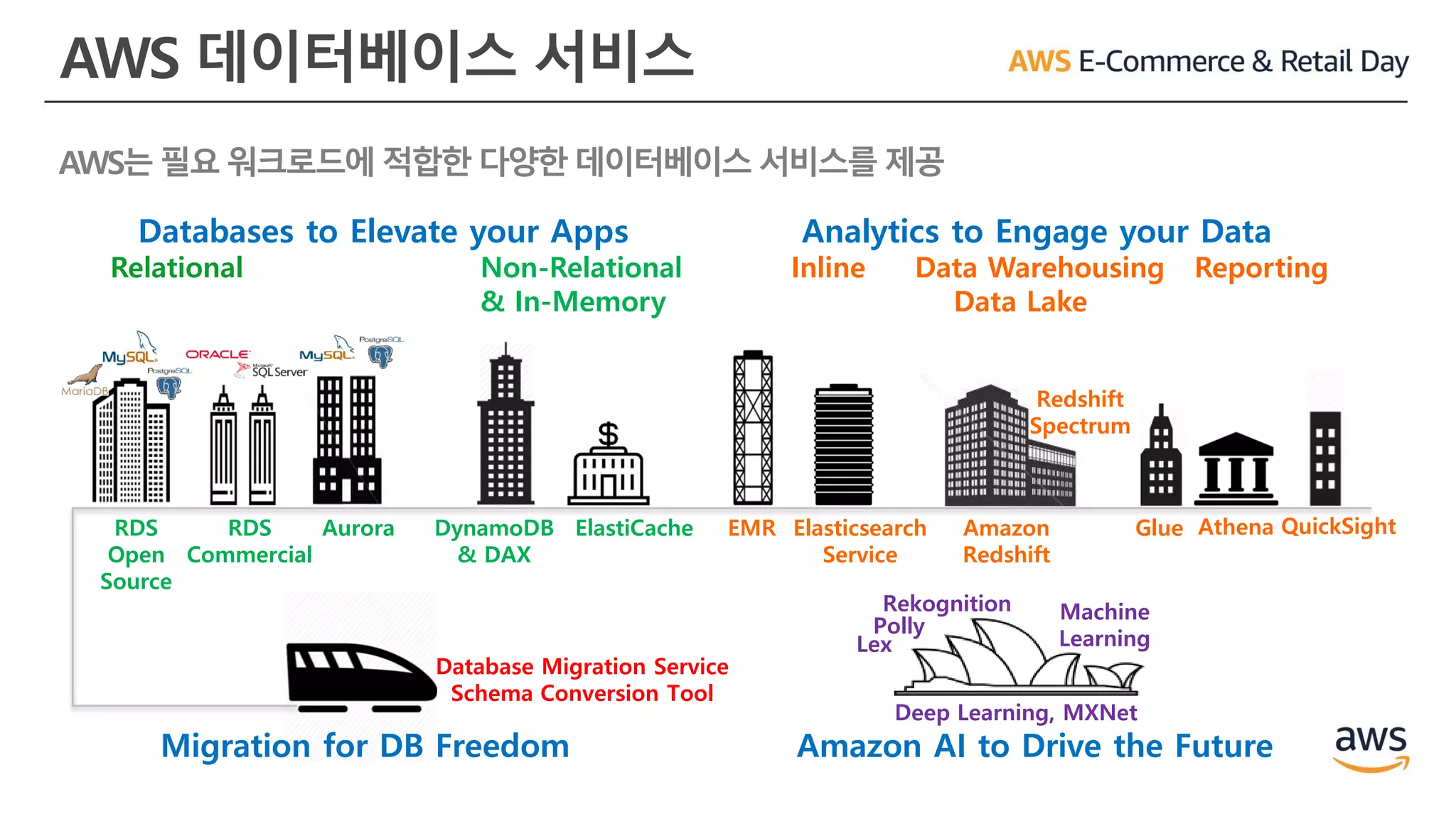
AWS 데이터베이스 서비스
RDS
Open
Source
RDS
Commercial
Aurora
Migrationfor DB Freedom
DynamoDB
& DAX
ElastiCache EMR Amazon
Redshift
Redshift
Spectrum
AthenaElasticsearch
Service
QuickSightGlue
Lex
Polly
Rekognition Machine
Learning
Databases to Elevate your Apps
Relational Non-Relational
& In-Memory
Analytics to Engage your Data
Inline Data Warehousing Reporting
Data Lake
Amazon AI to Drive the Future
Deep Learning, MXNet
Database Migration Service
Schema Conversion Tool
AWS는 필요 워크로드에 적합한 다양한 데이터베이스 서비스를 제공
25.
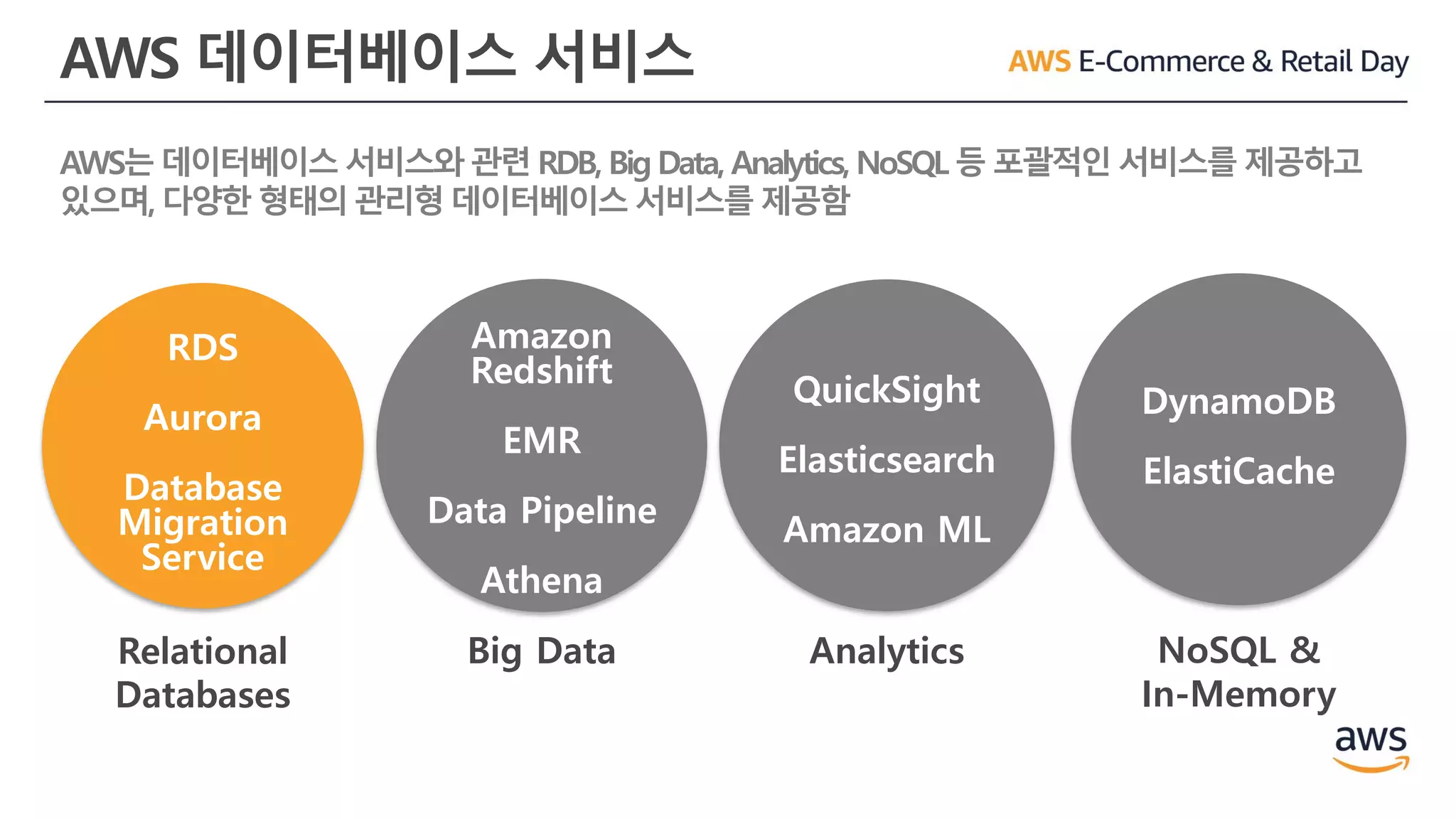
AWS 데이터베이스 서비스
AWS는데이터베이스 서비스와 관련 RDB, Big Data, Analytics, NoSQL 등 포괄적인 서비스를 제공하고
있으며, 다양한 형태의 관리형 데이터베이스 서비스를 제공함
Big
Data
RDS
Aurora
Database
Migration
Service
Relational
Databases
DynamoDB
ElastiCache
NoSQL &
In-Memory
Amazon
Redshift
EMR
Data Pipeline
Athena
Big Data
QuickSight
Elasticsearch
Amazon ML
Analytics
AWS 관리형 데이터베이스서비스
Power, HVAC, net
Rack & stack
Server maintenance
OS installation
OS patches
DB s/w patches
Database backups
Scaling
High availability
DB s/w installs
App optimization
Your Server
Power, HVAC, net
Rack & stack
Server maintenance
OS installation
Amazon EC2
OS patches
DB s/w patches
Database backups
Scaling
High availability
DB s/w installs
App optimization
Amazon RDS
Power, HVAC, net
Rack & stack
Server maintenance
OS installation
OS patches
DB s/w patches
Database backups
Scaling
High availability
DB s/w installs
App optimization
28.
“No server iseasier to
manage than no server”
Werner Vogels
(CTO, Amazon.com)
Image: 20081108 DDP Werner_Vogels / Guido van Nispen / license
29.
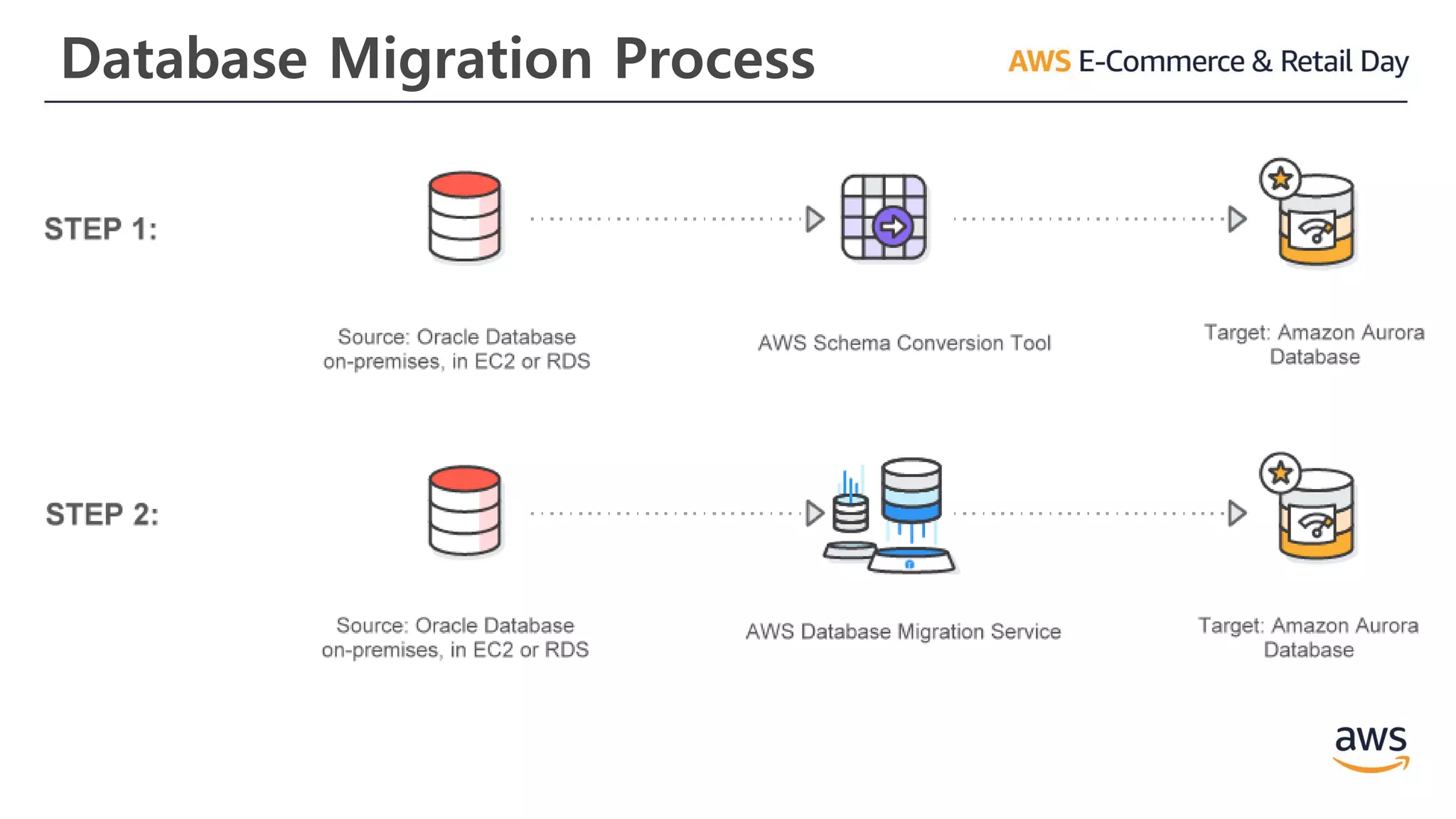
AWS Database MigrationService (AWS DMS)
DMS는 최소한의 중단 시간으로 쉽고 안전하게 AWS로
데이터베이스를 마이그레이션 합니다. 가장 널리
사용되는 상용 및 오픈 소스 데이터베이스간에
데이터를 마이그레이션 할 수 있습니다.
Amazon Aurora
30.
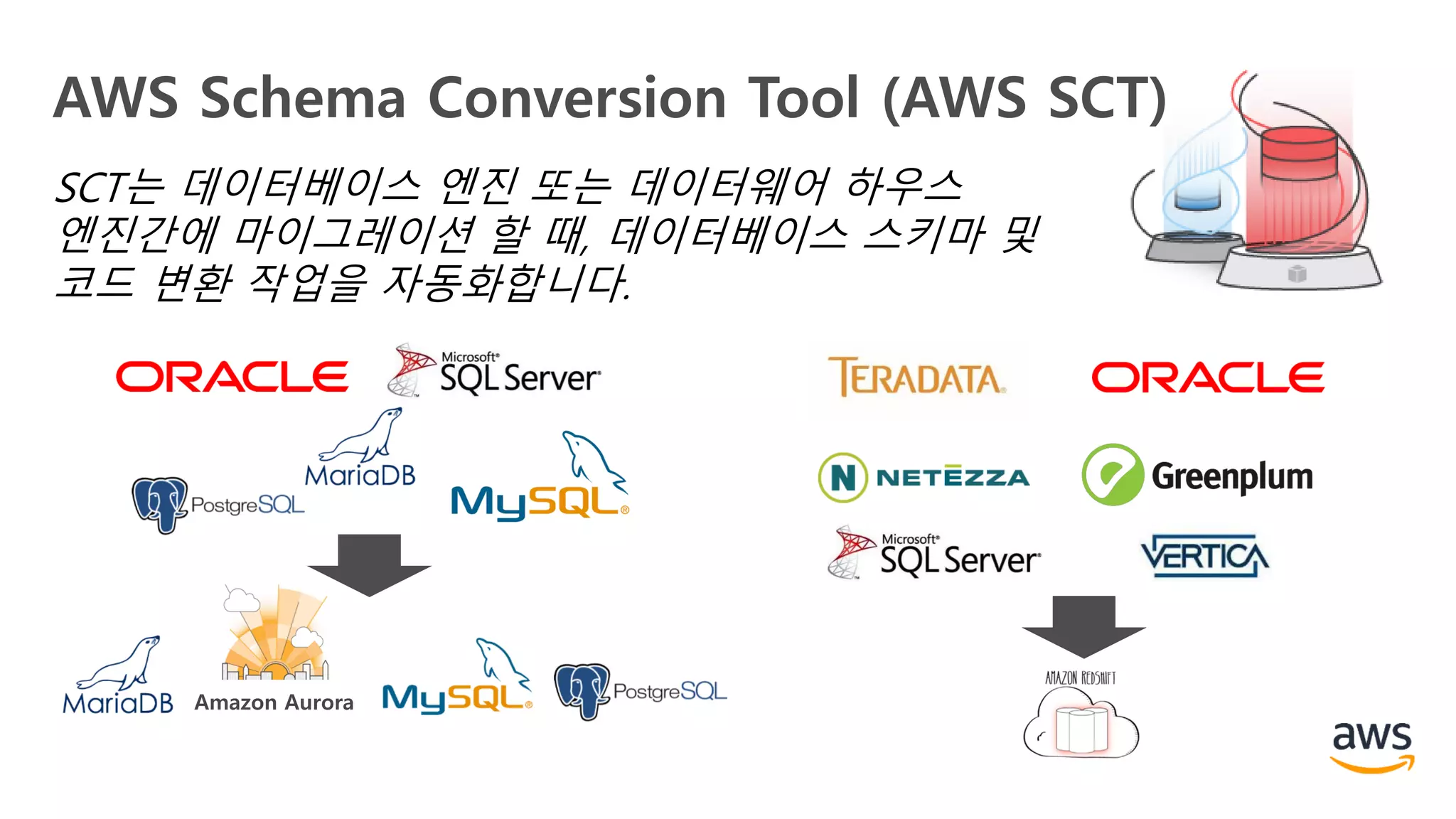
AWS Schema ConversionTool (AWS SCT)
SCT는 데이터베이스 엔진 또는 데이터웨어 하우스
엔진간에 마이그레이션 할 때, 데이터베이스 스키마 및
코드 변환 작업을 자동화합니다.
Amazon Aurora
Data Lake는 무엇인가?
▪Data Lake는 시스템이나 저장소 내에 원시
데이터 형식으로 데이터를 저장하는 방법으로,
다양한 스키마와 구조 형식의 데이터를 지원함
▪ 원시 데이터에서 시각화, 분석 및 기계 학습을
포함한 다양한 작업에 사용되는 변형 된 데이터에
이르기까지 기업의 모든 데이터를 단일 저장소에
저장하는 것
▪ 구조화된(Structure) 관계형 데이터베이스 (행 및
열), 반 구조화(Semi-Structure) 된 데이터 (CSV,
로그, XML, JSON), 구조화되지 않은
(Unstructured) 데이터 (전자 메일, 문서, PDF,
이미지, 오디오, 비디오)가 포함
34.
Data Lake의 특징과장점
모든 소스의 데이터를 한 곳에
저장하고 분석
“데이터가 너무 많은 장소에 분산.
한 곳에서 볼 수 없을까?
1. 모든 데이터를 한곳에(One Centralized Location)
35.
Data Lake의 특징과장점
사전에 정의된 방식을 강제하지
않고, 데이터를 신속하게 수집
“다양한 소스에서 어떻게
데이터를 신속하게 수집?
효율적으로 관리?
2. 신속한 데이터 추출 및 저장(Quickly Ingest Data)
36.
Data Lake의 특징과장점
저장공간과 분석을 위한 컴퓨팅
리소스를 분리.
각 구성요소를 별도로 확장.
생성되는 데이터가 점점 증가.
저장공간의 확장을 어떻게?
3. 데이터 저장과 처리를 분리(Decouple Compute & Storage)
37.
Data Lake의 특징과장점
4. 구조화 없이 분석 처리(Schema on Read)
여러가지 종류의 분석 및 처리
프레임워크를 동일한 데이터에
적용할 수 있는 방법?
Data Lake 는 쓰기가 아닌 읽기에
스키마를 적용하여 ad-hoc 분석이
가능.
38.
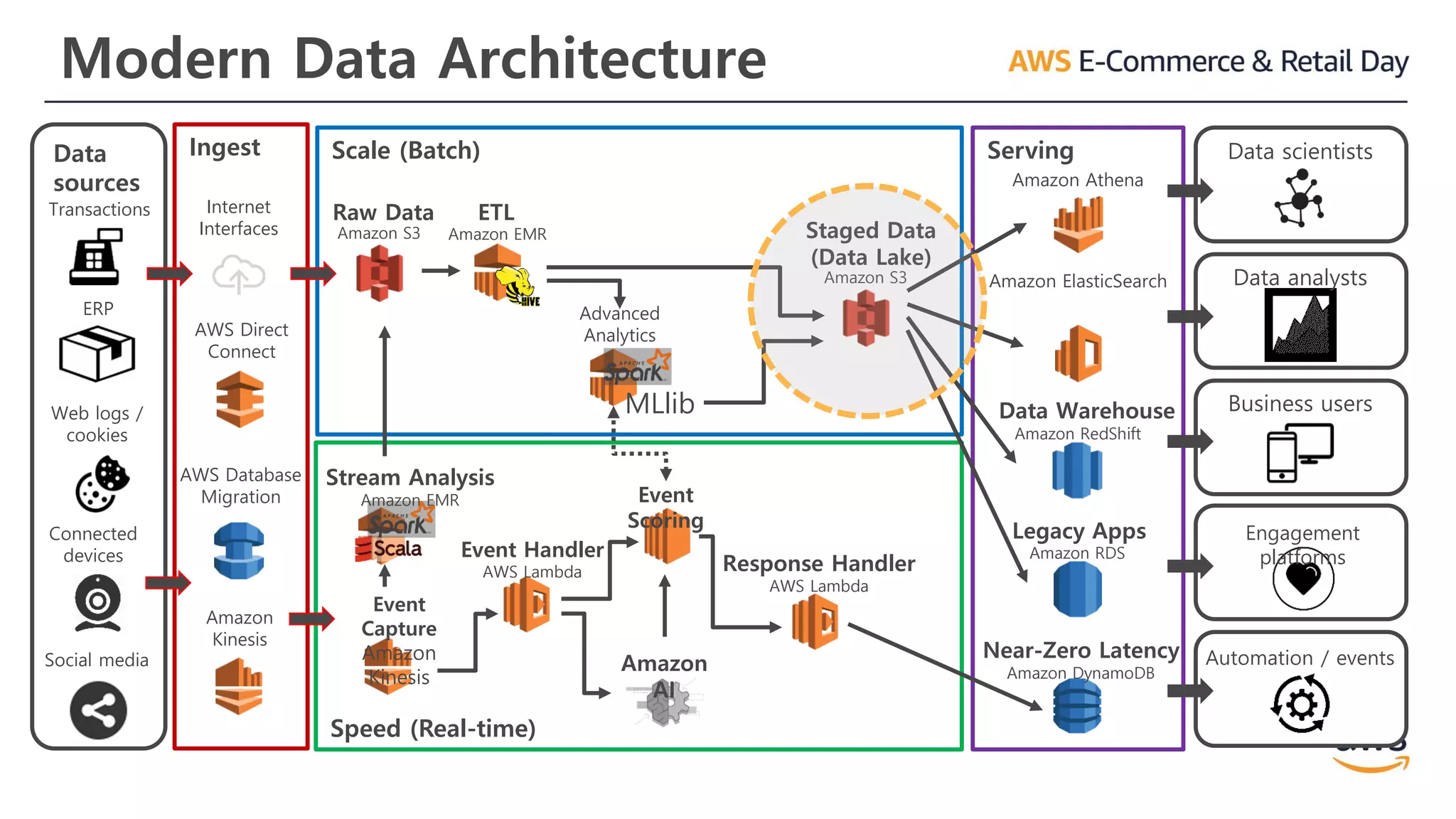
Modern Data Architecture
Speed(Real-time)
Ingest ServingData
sources
Scale (Batch)
Transactions
Web logs /
cookies
ERP
AWS Database
Migration
AWS Direct
Connect
Internet
Interfaces Amazon S3
Raw Data
Amazon S3
Staged Data
(Data Lake)
Amazon EMR
ETL
Amazon RedShift
Data Warehouse
Amazon RDS
Legacy Apps
Data analysts
Data scientists
Business users
Engagement
platforms
Amazon ElasticSearch
Amazon Athena
Amazon
Kinesis
Connected
devices
Social media
Advanced
Analytics
MLlib
Event
Capture
Amazon
Kinesis
Stream Analysis
Amazon EMR Event
Scoring
Amazon
AI
Event Handler
AWS Lambda Response Handler
AWS Lambda
Near-Zero Latency
Amazon DynamoDB
Automation / events
39.
43
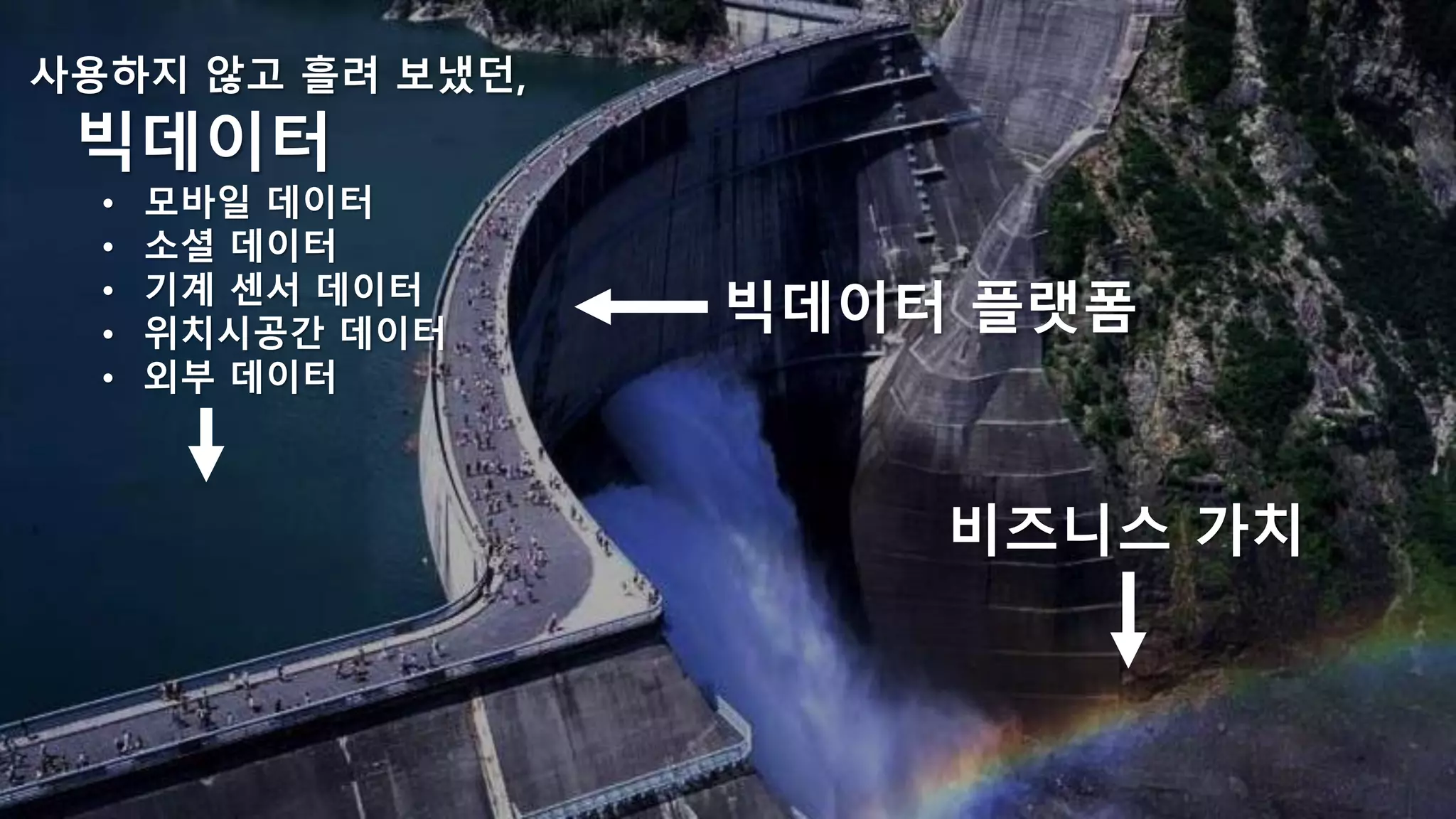
사용하지 않고 흘려보냈던,
빅데이터
• 모바일 데이터
• 소셜 데이터
• 기계 센서 데이터
• 위치시공간 데이터
• 외부 데이터
빅데이터 플랫폼
비즈니스 가치
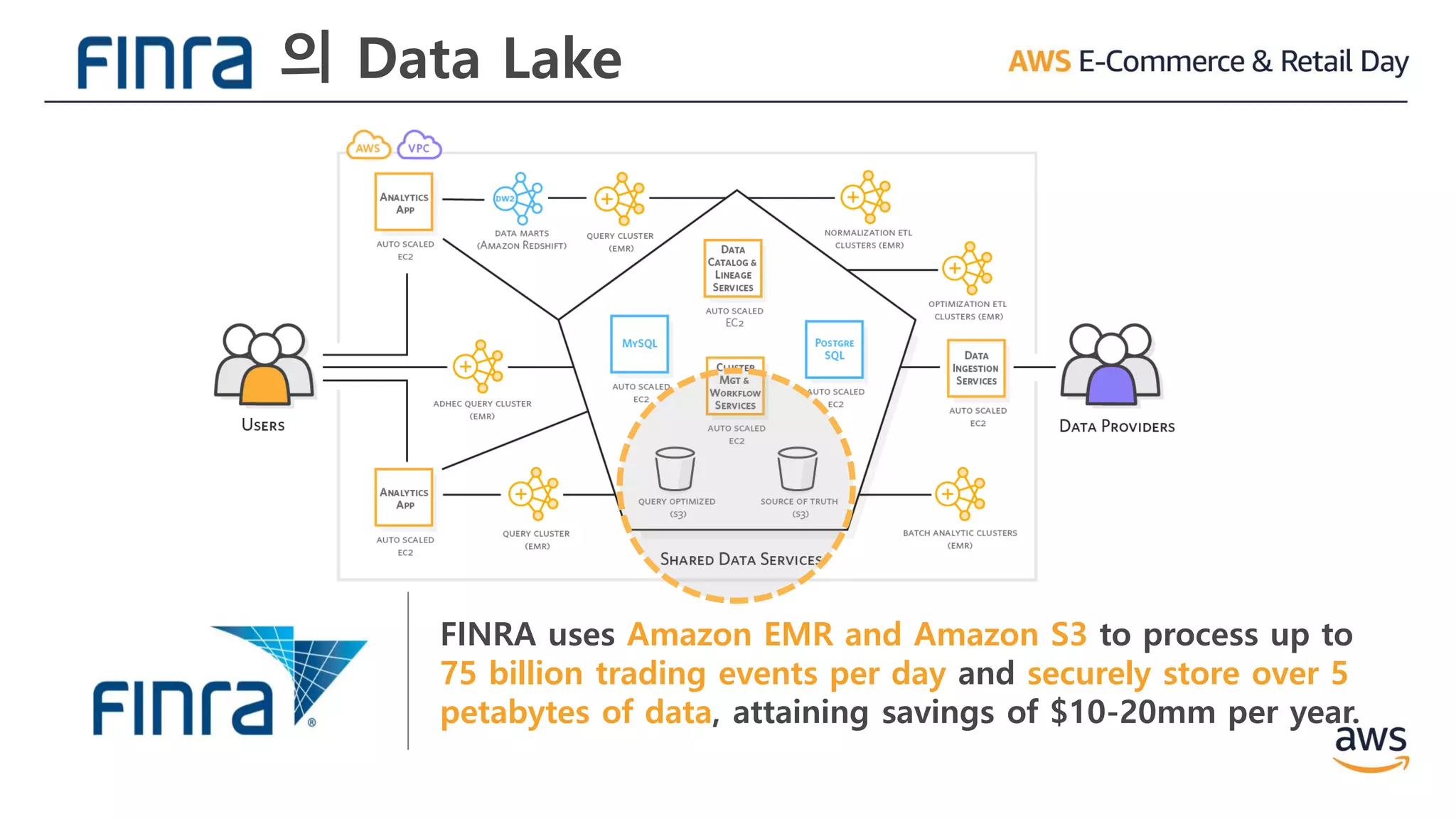
의 Data Lake
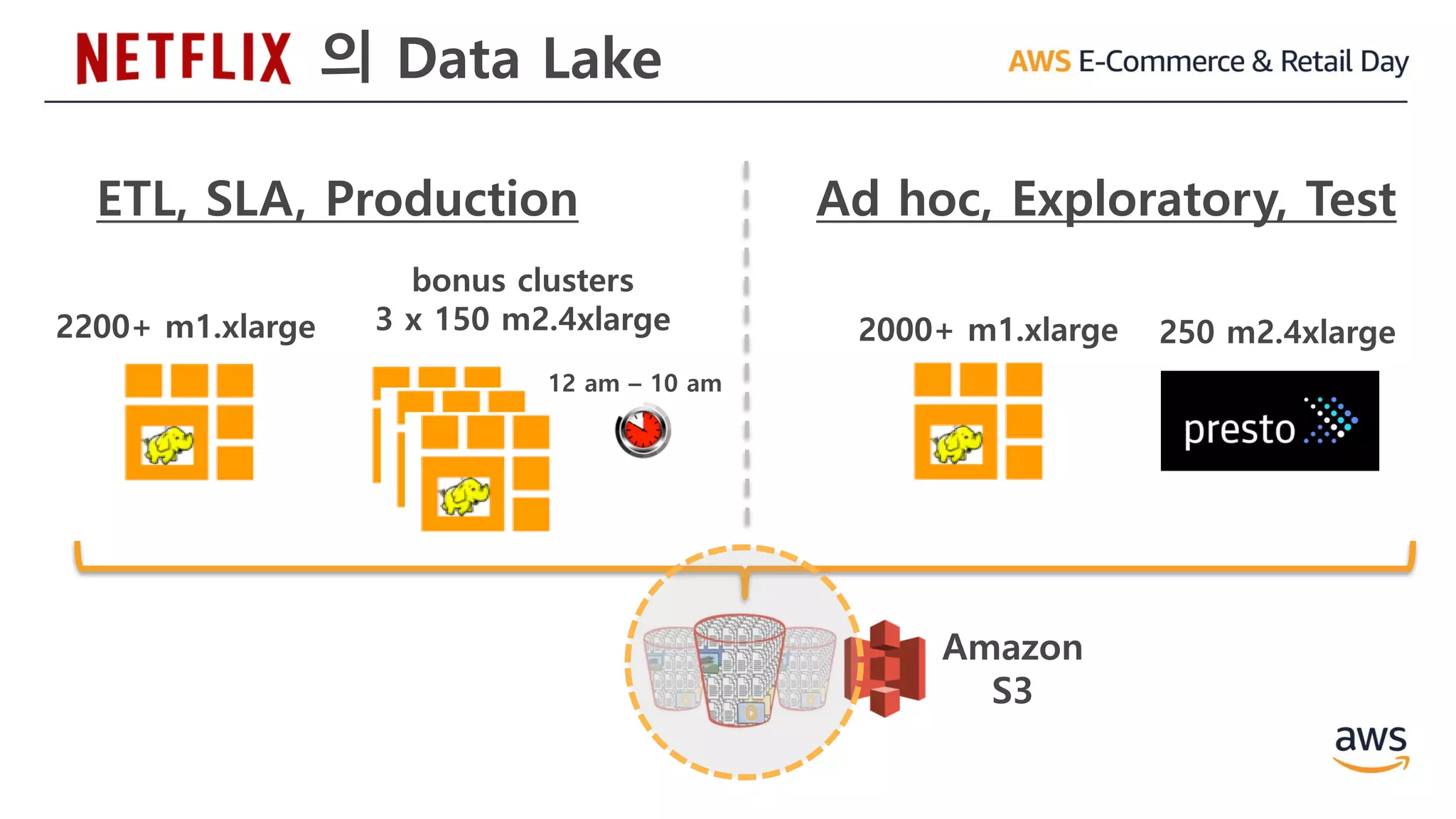
FINRAuses Amazon EMR and Amazon S3 to process up to
75 billion trading events per day and securely store over 5
petabytes of data, attaining savings of $10-20mm per year.
▪ Most recenttwo years of data is kept in the
Redshift data warehouse and snapshotted into S3
for disaster recovery
▪ Data between two and five years old is kept in S3
▪ Presto on EMR is used to ad-hoc query data in S3
▪ Average daily ingest of over 7B rows
▪ Migrated off legacy DW to AWS (start to finish) in
7 man-months
46.
새로운 비즈니스
A full-serviceresidential real estate brokerage
Redfin 은 수억 건의
부동산 정보와
수백만의 고객 정보를
관리
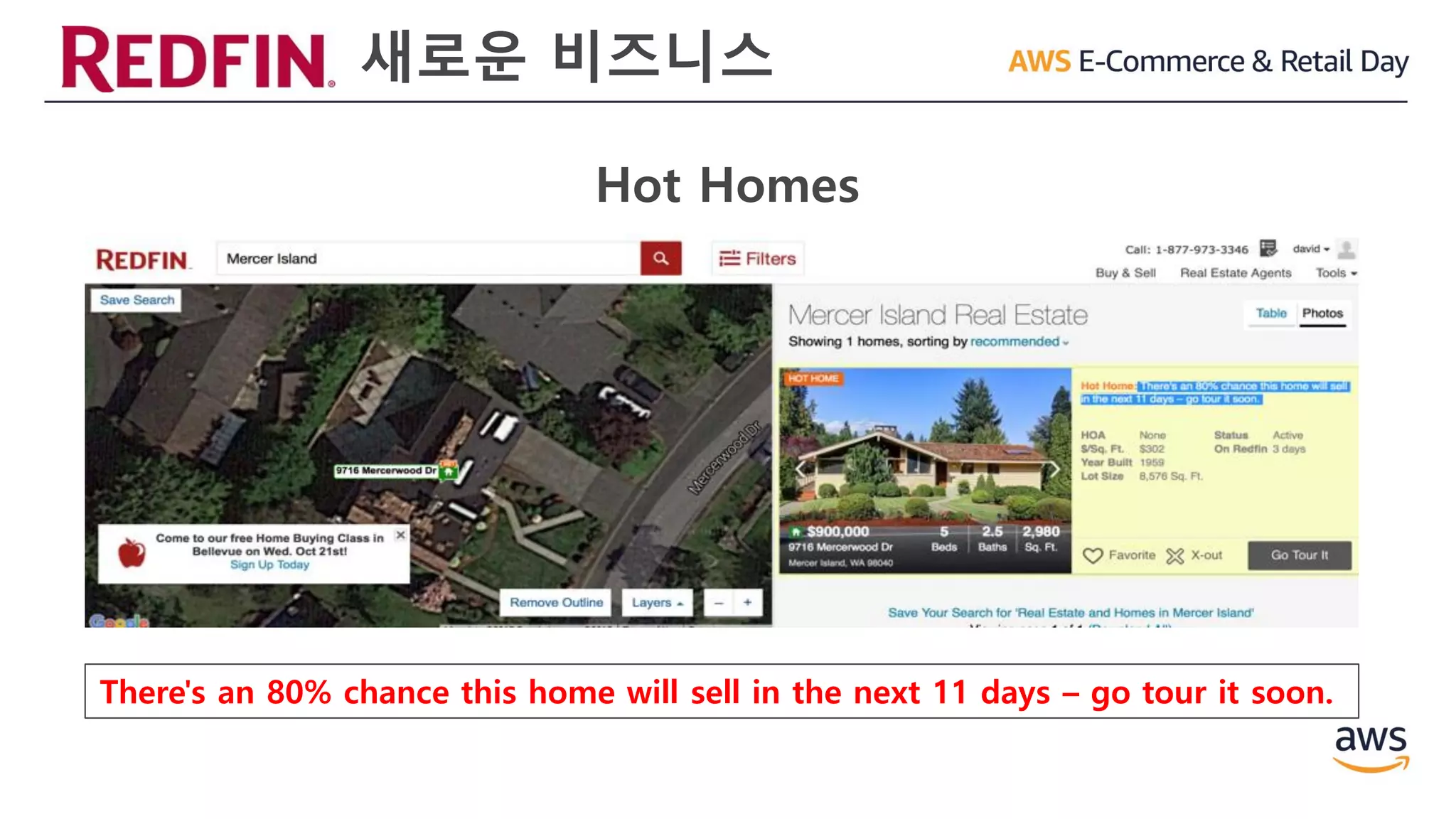
”Hot Homes” 알고리즘
사용. 500여 종류의
특성들을 분석하여
자동으로 매매 가능성을
계산
“Day One” 부터 AWS
클라우드를 모든 부분에
사용
https://aws.amazon.com/solutions/case-studies/redfin/
47.
새로운 비즈니스
There's an80% chance this home will sell in the next 11 days – go tour it soon.
Hot Homes
48.
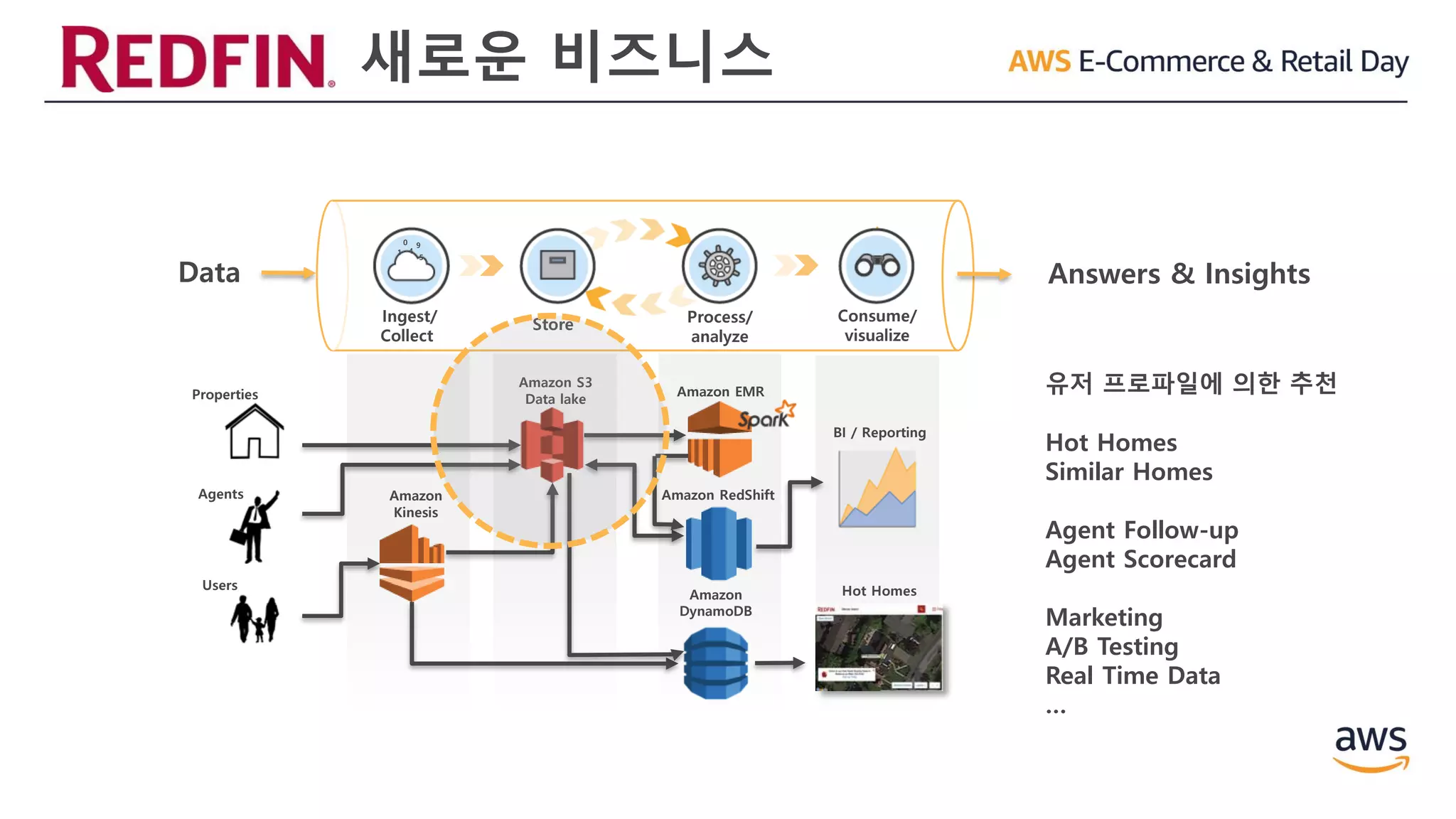
새로운 비즈니스
Ingest/
Collect
Consume/
visualize
Store Process/
analyze
Data
14
0 9
5
Amazon S3
Data lake
Amazon EMR
Amazon
Kinesis
Amazon RedShift
Answers & Insights
Hot HomesUsers
Properties
Agents
유저 프로파일에 의한 추천
Hot Homes
Similar Homes
Agent Follow-up
Agent Scorecard
Marketing
A/B Testing
Real Time Data
…
Amazon
DynamoDB
BI / Reporting
데이터 중심의 비즈니스
▪데이터 버스 구성 – 데이터의 수집, 저장, 분석, 시각화, 예측 등 각
단계에서 데이터가 효율적으로 사용될 수 있도록 데이터 버스를
효과적으로 구성
▪ 적합한 도구 사용 – 데이터의 엑세스 패턴, 온도, 작업 형태에 따라
올바른 저장소 및 도구를 사용
▪ 관리형 서비스 – 데이터 및 비즈니스 요건의 변화에 대한 빠른 대응 및
비용 효율적인 빅 데이터 환경 관리를 위하여 관리형 서비스 사용
▪ 다양한 실험 – 적은 비용으로 많은 실험을 수행함으로써 새로운
비즈니스 요구에 빠르게 대응
51.
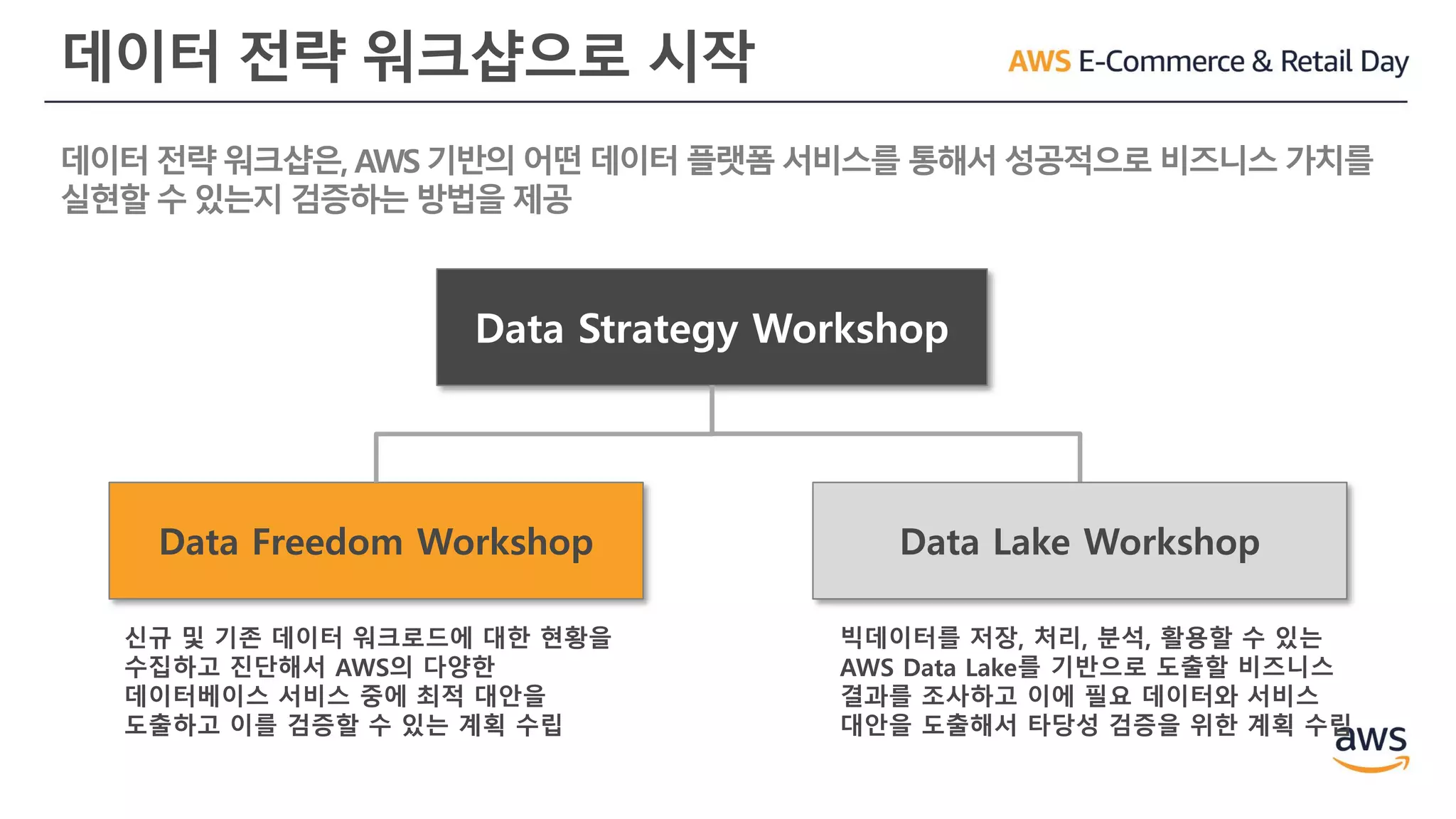
데이터 전략 워크샵으로시작
데이터 전략 워크샵은, AWS 기반의 어떤 데이터 플랫폼 서비스를 통해서 성공적으로 비즈니스 가치를
실현할 수 있는지 검증하는 방법을 제공
Data Strategy Workshop
Data Freedom Workshop Data Lake Workshop
신규 및 기존 데이터 워크로드에 대한 현황을
수집하고 진단해서 AWS의 다양한
데이터베이스 서비스 중에 최적 대안을
도출하고 이를 검증할 수 있는 계획 수립
빅데이터를 저장, 처리, 분석, 활용할 수 있는
AWS Data Lake를 기반으로 도출할 비즈니스
결과를 조사하고 이에 필요 데이터와 서비스
대안을 도출해서 타당성 검증을 위한 계획 수립
52.
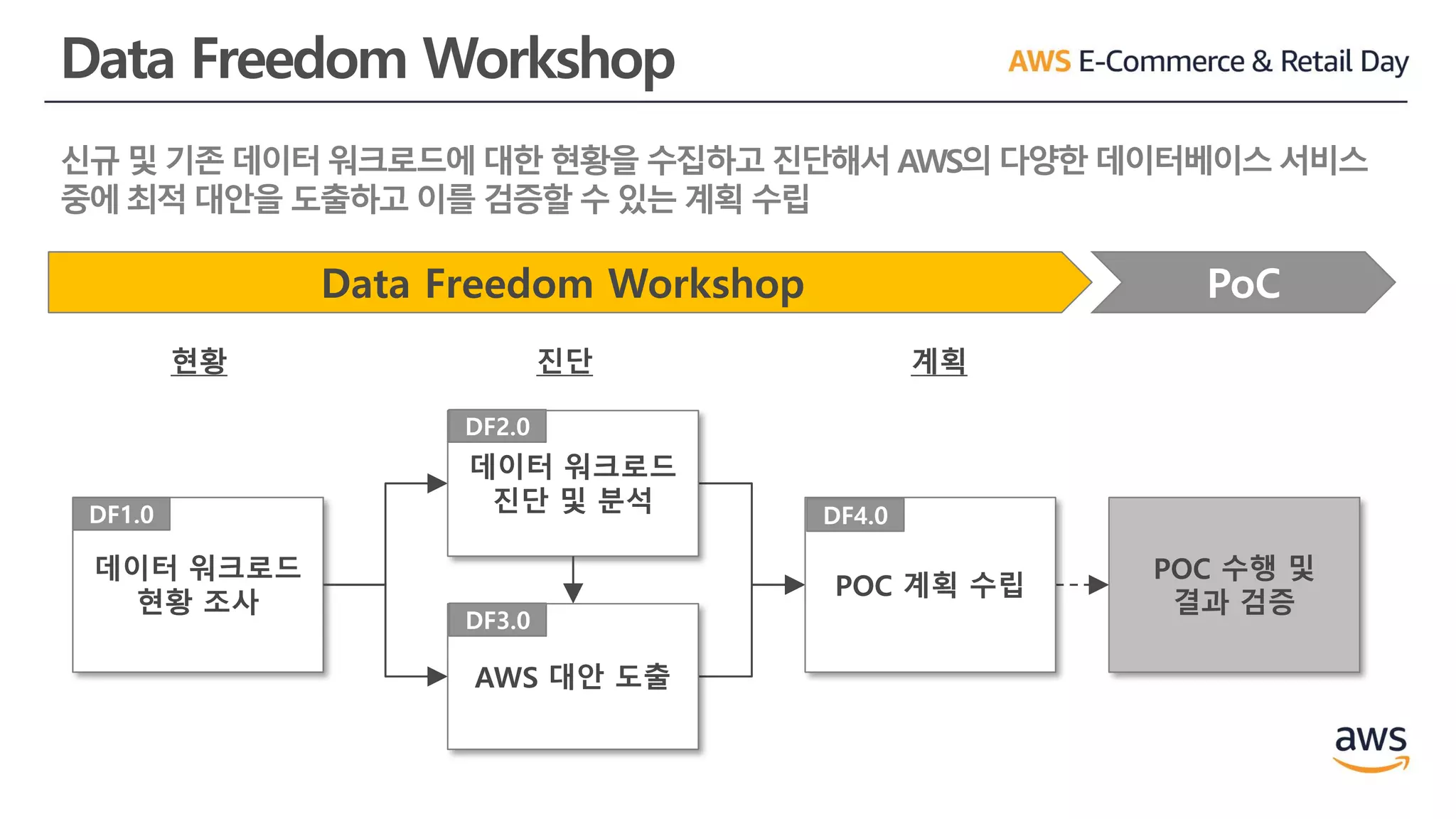
Data Freedom Workshop
신규및 기존 데이터 워크로드에 대한 현황을 수집하고 진단해서 AWS의 다양한 데이터베이스 서비스
중에 최적 대안을 도출하고 이를 검증할 수 있는 계획 수립
Data Freedom Workshop PoC
POC 수행 및
결과 검증
데이터 워크로드
현황 조사
DF1.0
데이터 워크로드
진단 및 분석
DF2.0
AWS 대안 도출
DF3.0
POC 계획 수립
DF4.0
현황 진단 계획
54.
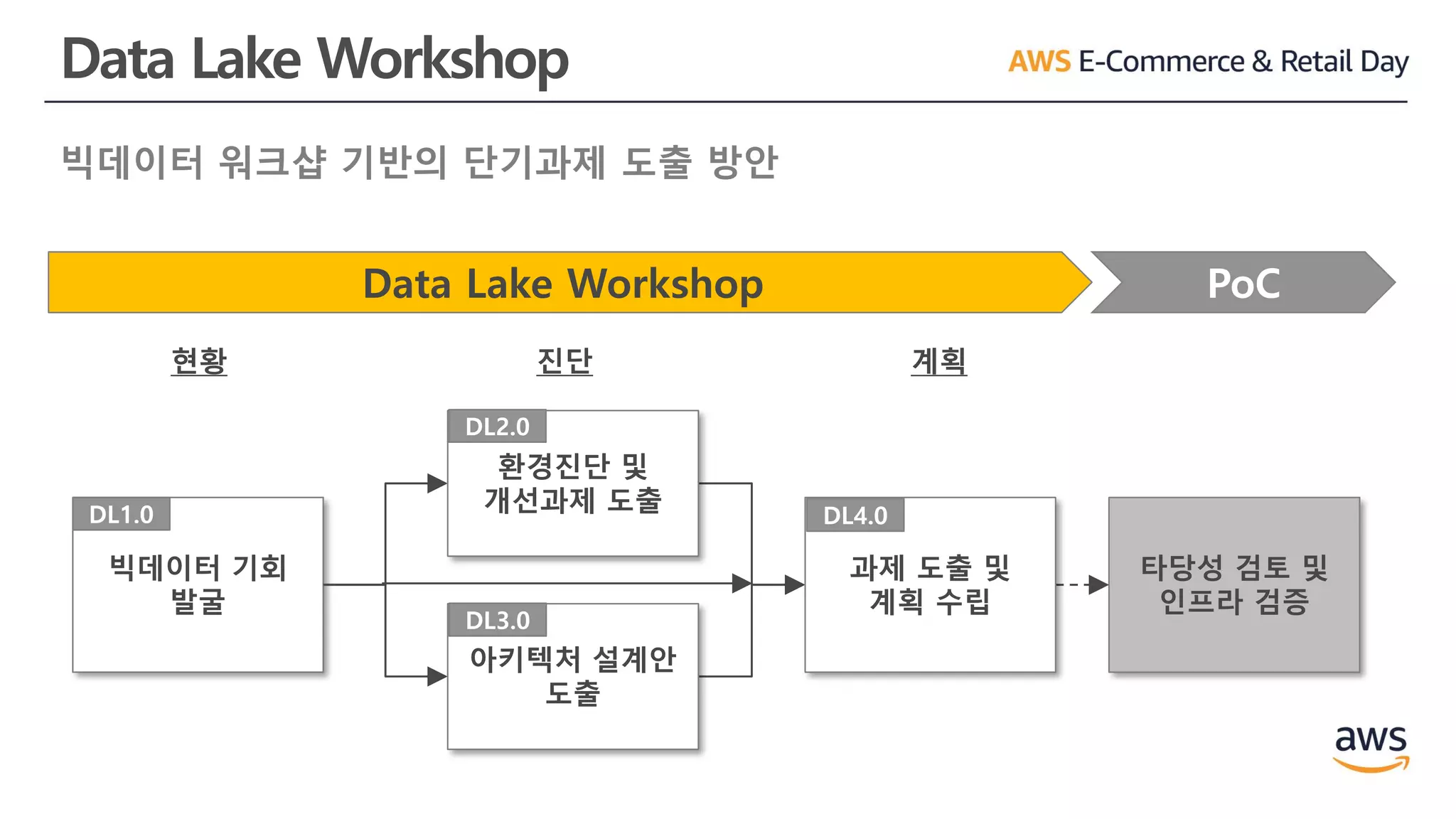
Data Lake Workshop
빅데이터워크샵 기반의 단기과제 도출 방안
Data Lake Workshop PoC
타당성 검토 및
인프라 검증
빅데이터 기회
발굴
DL1.0
환경진단 및
개선과제 도출
DL2.0
아키텍처 설계안
도출
DL3.0
과제 도출 및
계획 수립
DL4.0
현황 진단 계획






























![[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] 클라우드 소개 및 도입 로드맵](https://cdn.slidesharecdn.com/ss_thumbnails/biohealthcareseminarsession02-180614105441-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Partner TechShift 2017] EXEM의 AWS 마켓플레이스 실전 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/11-171102000503-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] 클라우드 시대 기존 Legacy에서 벗어나는 방법](https://cdn.slidesharecdn.com/ss_thumbnails/6-171101053200-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Partner TechShift] 클라우드 사업을 위한 3가지 소프트웨어 딜리버리 전략](https://cdn.slidesharecdn.com/ss_thumbnails/8-171101053546-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Gaming on AWS] The Braves of Japan (일본 게임시장의 AWS 활용법)](https://cdn.slidesharecdn.com/ss_thumbnails/03braves-of-japankorl-171027024354-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechForum] 고객을 360도로 이해하고 수익으로 연결하는 글로벌 선도 금융 기업들의 데이터 플랫폼 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/treasuredatatechforrm2017-171122013630-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Partner TechShift 2017] AWS로 당신의 소프트웨어를 혁신하라](https://cdn.slidesharecdn.com/ss_thumbnails/7-171101053421-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] 국내 소프트웨어 개발사를 위한 AWS 파트너프로그램 소개](https://cdn.slidesharecdn.com/ss_thumbnails/4-171101052745-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Windows on AWS] AWS를 활용한 그룹웨어 구축 방안](https://cdn.slidesharecdn.com/ss_thumbnails/3-171027022843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Windows on AWS] AWS 를 활용한 SQL Server 최적 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/5-171027022659-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Windows on AWS] Overview](https://cdn.slidesharecdn.com/ss_thumbnails/windowsonaws1025-171027022353-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Windows on AWS] AWS 를 활용한 Active Directory 연동 및 이관 방안](https://cdn.slidesharecdn.com/ss_thumbnails/4-171027022544-thumbnail.jpg?width=640&height=640&fit=bounds)
![[E-commerce & Retail Day] 인공지능서비스 활용방안](https://cdn.slidesharecdn.com/ss_thumbnails/random-171027021822-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Partner TechShift 2017] 국내 소프트웨어 개발사가 AWS를 고려해야 하는 이유](https://cdn.slidesharecdn.com/ss_thumbnails/3-171101052547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] AWS와 함께하는 글로벌 클라우드 소프트웨어 사업](https://cdn.slidesharecdn.com/ss_thumbnails/1-171101050333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[E-commerce & Retail Day] Amazon 혁신과 AWS Retail 사례](https://cdn.slidesharecdn.com/ss_thumbnails/amazonawsretail-171027021301-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] AWS와 협업을 통한 국내외 엔터프라이즈 SaaS 세일즈 성공사례: SendBird](https://cdn.slidesharecdn.com/ss_thumbnails/5-171101052933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] AWS와 함께 성장하는 안랩의 신규 클라우드 사업 도전](https://cdn.slidesharecdn.com/ss_thumbnails/2-171101052308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2017 AWS Startup Day] AWS 비용 최대 90% 절감하기: 스팟 인스턴스 Deep-Dive](https://cdn.slidesharecdn.com/ss_thumbnails/2017awsstartupdayspotdeepdive-171101100514-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Partner TechShift 2017] APN 컨설팅 파트너사와 함께 하는 클라우드 소프트웨어 사업](https://cdn.slidesharecdn.com/ss_thumbnails/12-171102000046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Partner TechShift 2017] AWS 마켓플레이스를 통한 글로벌 소프트웨어 판매하기](https://cdn.slidesharecdn.com/ss_thumbnails/9-171101053704-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 AWS Startup Day] 서버리스 마이크로서비스로 일당백 개발조직 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/awsstartupday2017-microservicespiljoong-171101081359-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Retail & CPG Day 2019] AWS기반의 Data 분석 플랫폼 구축, 고객사례 (GS SHOP) -김형일, AWS 솔루션즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/gsshop-191024042351-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)










