Recommended
PDF
민첩하고 비용효율적인 Data Lake 구축 - 문종민 솔루션즈 아키텍트, AWS
PDF
Amazon Redshift로 데이터웨어하우스(DW) 구축하기
PDF
AWS 빅데이터 아키텍처 패턴 및 모범 사례- AWS Summit Seoul 2017
PDF
대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...
PDF
Amazon DocumentDB vs MongoDB 의 내부 아키텍쳐 와 장단점 비교
PDF
AWS Summit Seoul 2023 | 다중 계정 및 하이브리드 환경에서 안전한 IAM 체계 만들기
PDF
더욱 진화하는 AWS 네트워크 보안 - 신은수 AWS 시큐리티 스페셜리스트 솔루션즈 아키텍트 :: AWS Summit Seoul 2021
PDF
고객의 플랫폼/서비스를 개선한 국내 사례 살펴보기 – 장준성 AWS 솔루션즈 아키텍트, 강산아 NDREAM 팀장, 송영호 야놀자 매니저, ...
PDF
사례로 알아보는 Database Migration Service : 데이터베이스 및 데이터 이관, 통합, 분리, 분석의 도구 - 발표자: ...
PDF
LG 이노텍 - Amazon Redshift Serverless를 활용한 데이터 분석 플랫폼 혁신 과정 - 발표자: 유재상 선임, LG이노...
PDF
있는 그대로 저장하고, 바로 분석 가능한, 새로운 관점의 데이터 애널리틱 플랫폼 - 정세웅 애널리틱 스페셜리스트, AWS
PDF
실시간 스트리밍 분석 Kinesis Data Analytics Deep Dive
PDF
데브시스터즈 데이터 레이크 구축 이야기 : Data Lake architecture case study (박주홍 데이터 분석 및 인프라 팀...
PDF
Amazon Aurora Deep Dive (김기완) - AWS DB Day
PDF
AWS Summit Seoul 2023 | AWS에서 OpenTelemetry 기반의 애플리케이션 Observability 구축/활용하기
PDF
AWS를 활용한 리테일,이커머스 워크로드와 온라인 서비스 이관 사례::이동열, 임혁용:: AWS Summit Seoul 2018
PPTX
AWS 의 비용 절감 프레임워크와 신규 프로그램을 활용한 전략적 비용절감 :: AWS Travel and Transportation 온라인...
PDF
천만사용자를 위한 AWS 클라우드 아키텍처 진화하기 – 문종민, AWS솔루션즈 아키텍트:: AWS Summit Online Korea 2020
PDF
[AWS Migration Workshop] 데이터베이스를 AWS로 손쉽게 마이그레이션 하기
PDF
AWS 상의 컨테이너 서비스 소개 ECS, EKS - 이종립 / Principle Enterprise Evangelist @베스핀글로벌
PDF
[AWS Builders] 클라우드 비용, 어떻게 줄일 수 있을까?
PDF
[AWS Builders] AWS 네트워크 서비스 소개 및 사용 방법 - 김기현, AWS 솔루션즈 아키텍트
PDF
아키텍처 현대화 분야 신규 서비스 - 주성식, AWS 솔루션즈 아키텍트 :: AWS re:Invent re:Cap 2021
PDF
[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] AWS 클라우드 보안
PDF
Amazon SageMaker 모델 학습 방법 소개::최영준, 솔루션즈 아키텍트 AI/ML 엑스퍼트, AWS::AWS AIML 스페셜 웨비나
PDF
개발자가 알아야 할 Amazon DynamoDB 활용법 :: 김일호 :: AWS Summit Seoul 2016
PDF
AWS Fargate on EKS 실전 사용하기
PDF
AWS 기반 클라우드 아키텍처 모범사례 - 삼성전자 개발자 포털/개발자 워크스페이스 - 정영준 솔루션즈 아키텍트, AWS / 유현성 수석,...
PPTX
글로벌 기업들의 효과적인 데이터 분석을 위한 Data Lake 구축 및 분석 사례 - 김준형 (AWS 솔루션즈 아키텍트)
PDF
데이터 분석가를 위한 신규 분석 서비스 - 김기영, AWS 분석 솔루션즈 아키텍트 / 변규현, 당근마켓 소프트웨어 엔지니어 :: AWS r...
More Related Content
PDF
민첩하고 비용효율적인 Data Lake 구축 - 문종민 솔루션즈 아키텍트, AWS
PDF
Amazon Redshift로 데이터웨어하우스(DW) 구축하기
PDF
AWS 빅데이터 아키텍처 패턴 및 모범 사례- AWS Summit Seoul 2017
PDF
대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...
PDF
Amazon DocumentDB vs MongoDB 의 내부 아키텍쳐 와 장단점 비교
PDF
AWS Summit Seoul 2023 | 다중 계정 및 하이브리드 환경에서 안전한 IAM 체계 만들기
PDF
더욱 진화하는 AWS 네트워크 보안 - 신은수 AWS 시큐리티 스페셜리스트 솔루션즈 아키텍트 :: AWS Summit Seoul 2021
PDF
고객의 플랫폼/서비스를 개선한 국내 사례 살펴보기 – 장준성 AWS 솔루션즈 아키텍트, 강산아 NDREAM 팀장, 송영호 야놀자 매니저, ...
What's hot
PDF
사례로 알아보는 Database Migration Service : 데이터베이스 및 데이터 이관, 통합, 분리, 분석의 도구 - 발표자: ...
PDF
LG 이노텍 - Amazon Redshift Serverless를 활용한 데이터 분석 플랫폼 혁신 과정 - 발표자: 유재상 선임, LG이노...
PDF
있는 그대로 저장하고, 바로 분석 가능한, 새로운 관점의 데이터 애널리틱 플랫폼 - 정세웅 애널리틱 스페셜리스트, AWS
PDF
실시간 스트리밍 분석 Kinesis Data Analytics Deep Dive
PDF
데브시스터즈 데이터 레이크 구축 이야기 : Data Lake architecture case study (박주홍 데이터 분석 및 인프라 팀...
PDF
Amazon Aurora Deep Dive (김기완) - AWS DB Day
PDF
AWS Summit Seoul 2023 | AWS에서 OpenTelemetry 기반의 애플리케이션 Observability 구축/활용하기
PDF
AWS를 활용한 리테일,이커머스 워크로드와 온라인 서비스 이관 사례::이동열, 임혁용:: AWS Summit Seoul 2018
PPTX
AWS 의 비용 절감 프레임워크와 신규 프로그램을 활용한 전략적 비용절감 :: AWS Travel and Transportation 온라인...
PDF
천만사용자를 위한 AWS 클라우드 아키텍처 진화하기 – 문종민, AWS솔루션즈 아키텍트:: AWS Summit Online Korea 2020
PDF
[AWS Migration Workshop] 데이터베이스를 AWS로 손쉽게 마이그레이션 하기
PDF
AWS 상의 컨테이너 서비스 소개 ECS, EKS - 이종립 / Principle Enterprise Evangelist @베스핀글로벌
PDF
[AWS Builders] 클라우드 비용, 어떻게 줄일 수 있을까?
PDF
[AWS Builders] AWS 네트워크 서비스 소개 및 사용 방법 - 김기현, AWS 솔루션즈 아키텍트
PDF
아키텍처 현대화 분야 신규 서비스 - 주성식, AWS 솔루션즈 아키텍트 :: AWS re:Invent re:Cap 2021
PDF
[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] AWS 클라우드 보안
PDF
Amazon SageMaker 모델 학습 방법 소개::최영준, 솔루션즈 아키텍트 AI/ML 엑스퍼트, AWS::AWS AIML 스페셜 웨비나
PDF
개발자가 알아야 할 Amazon DynamoDB 활용법 :: 김일호 :: AWS Summit Seoul 2016
PDF
AWS Fargate on EKS 실전 사용하기
PDF
AWS 기반 클라우드 아키텍처 모범사례 - 삼성전자 개발자 포털/개발자 워크스페이스 - 정영준 솔루션즈 아키텍트, AWS / 유현성 수석,...
Similar to AWS 기반 데이터 레이크(Datalake) 구축 및 분석 - 김민성 (AWS 솔루션즈아키텍트) : 8월 온라인 세미나
PPTX
글로벌 기업들의 효과적인 데이터 분석을 위한 Data Lake 구축 및 분석 사례 - 김준형 (AWS 솔루션즈 아키텍트)
PDF
데이터 분석가를 위한 신규 분석 서비스 - 김기영, AWS 분석 솔루션즈 아키텍트 / 변규현, 당근마켓 소프트웨어 엔지니어 :: AWS r...
PDF
고객 중심 서비스 출시를 위한 준비 “온오프라인 고객 데이터 통합” – 김준형 AWS 솔루션즈 아키텍트, 김수진 아모레퍼시픽:: AWS C...
PDF
AWS기반 서버리스 데이터레이크 구축하기 - 김진웅 (SK C&C) :: AWS Community Day 2020
PDF
모든 데이터를 위한 단 하나의 저장소, Amazon S3 기반 데이터 레이크::정세웅::AWS Summit Seoul 2018
PDF
PDF
Amazon.com 사례와 함께하는 유통 차세대 DW 구축을 위한 Data Lake 전략::구태훈::AWS Summit Seoul 2018
PDF
AWS Lake Formation을 통한 손쉬운 데이터 레이크 구성 및 관리 - 윤석찬 :: AWS Unboxing 온라인 세미나
PDF
[Retail & CPG Day 2019] AWS기반의 Data 분석 플랫폼 구축, 고객사례 (GS SHOP) -김형일, AWS 솔루션즈 ...
PDF
데이터의 힘, 스타트업의 생존을 넘어 성장으로 - 김용대 사업개발 담당, AWS / 박재영 CTO, 크몽 :: AWS Summit Seou...
PDF
AWS에서 빅데이터 프로젝트 시작하기 - 이종화 솔루션즈 아키텍트, AWS
PDF
Ad-Tech on AWS 세미나 | AWS와 데이터 분석
PDF
Effective Data Lake : 고객 경험을 통한 사례 탐구 - 유다니엘 솔루션즈 아키텍트, AWS :: AWS Summit Seo...
PDF
빅데이터를 위한 AWS 모범사례와 아키텍처 구축 패턴 :: 양승도 :: AWS Summit Seoul 2016
PDF
PDF
금융 데이터분석을 위한 효과적인 AWS 아키텍쳐::유다니엘::AWS Summit Seoul 2018
PDF
AWS기반 서버리스 데이터레이크 구축하기 - 김진웅 (SK C&C) :: AWS Community Day 2020
PDF
[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략
PDF
2017 Ad-Tech on AWS 세미나ㅣAWS에서의 빅데이터와 분석
PDF
AWS BigData 전략과 관련 AWS 서비스 이해하기
More from Amazon Web Services Korea
PDF
Enabling Agility with Data Governance - 발표자: 김성연, Analytics Specialist, WWSO,...
PDF
Amazon DocumentDB - Architecture 및 Best Practice (Level 200) - 발표자: 장동훈, Sr. ...
PDF
Amazon OpenSearch - Use Cases, Security/Observability, Serverless and Enhance...
PDF
Amazon EMR - Enhancements on Cost/Performance, Serverless - 발표자: 김기영, Sr Anal...
PDF
Internal Architecture of Amazon Aurora (Level 400) - 발표자: 정달영, APAC RDS Speci...
PDF
[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...
PDF
Amazon Redshift Deep Dive - Serverless, Streaming, ML, Auto Copy (New feature...
PDF
AWS Modern Infra with Storage Roadshow 2023 - Day 2
PDF
[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법
PDF
Demystify Streaming on AWS - 발표자: 이종혁, Sr Analytics Specialist, WWSO, AWS :::...
PDF
AWS Modern Infra with Storage Roadshow 2023 - Day 1
PDF
Amazon Elasticache - Fully managed, Redis & Memcached Compatible Service (Lev...
PDF
[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기
PDF
[D3T1S06] Neptune Analytics with Vector Similarity Search
PDF
[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기
PDF
[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...
PDF
[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습
PDF
[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습
PDF
[D3T1S03] Amazon DynamoDB design puzzlers
PDF
[D3T1S02] Aurora Limitless Database Introduction
AWS 기반 데이터 레이크(Datalake) 구축 및 분석 - 김민성 (AWS 솔루션즈아키텍트) : 8월 온라인 세미나 1. © 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
김민성, 솔루션스 아키텍트
2017년 8월 29일
AWS 기반 데이터 레이크(Datalake)
구축 및 분석
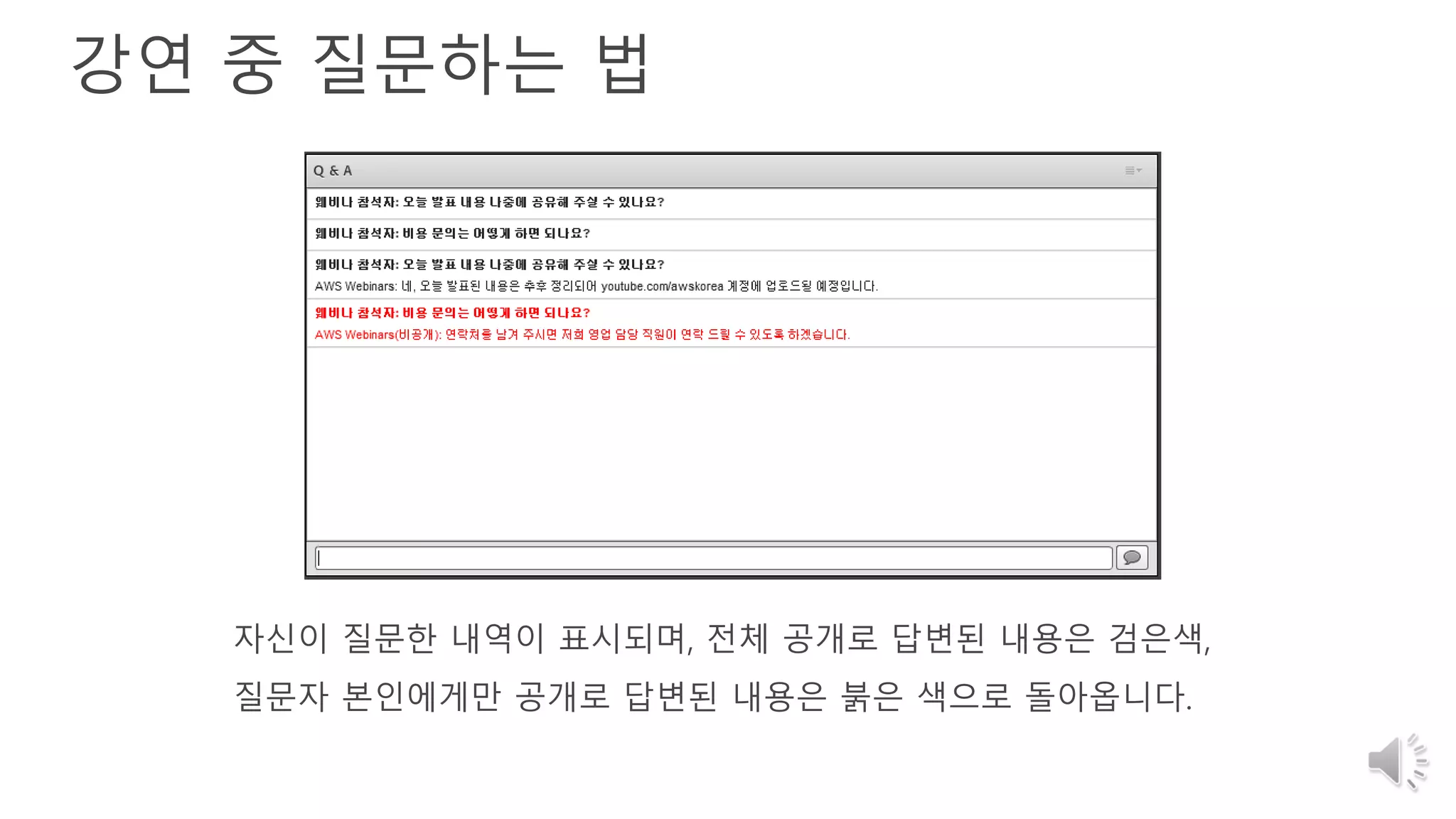
2. 강연 중 질문하는 법
자신이 질문한 내역이 표시되며, 전체 공개로 답변된 내용은 검은색,
질문자 본인에게만 공개로 답변된 내용은 붉은 색으로 돌아옵니다.
3. 본 세션의 주요 주제
• 빅데이터
• Data Lake의 정의 및 조건
• AWS에서의 Data Lake
4. 5. 빅 데이터의 도전과 과제
Source: Forrsights Strategy Spotlight: Business Intelligence And Big Data, Q4 2012.
Base: 634 business intelligence users and planners
Unstructured
50TB
Semi-structured
2 TB
Structured
12 TB
12%
기업별
평균 데이터 볼륨의 크기
9 TB 75 TB
0.6 TB 5 TB
4 TB 50 TB
중소기업 대기업
6. 7. 빅데이터 분석 도구
Amazon
Kinesis
Amazon
Glacier
S3 DynamoDB
RDS
EMR
Amazon
Redshift
Data Pipeline
Amazon Kinesis
Streams app
Lambda Amazon ML
SQS
ElastiCache
DynamoDB
Streams Amazon Kinesis
Analytics
Amazon Elasticsearch
Service
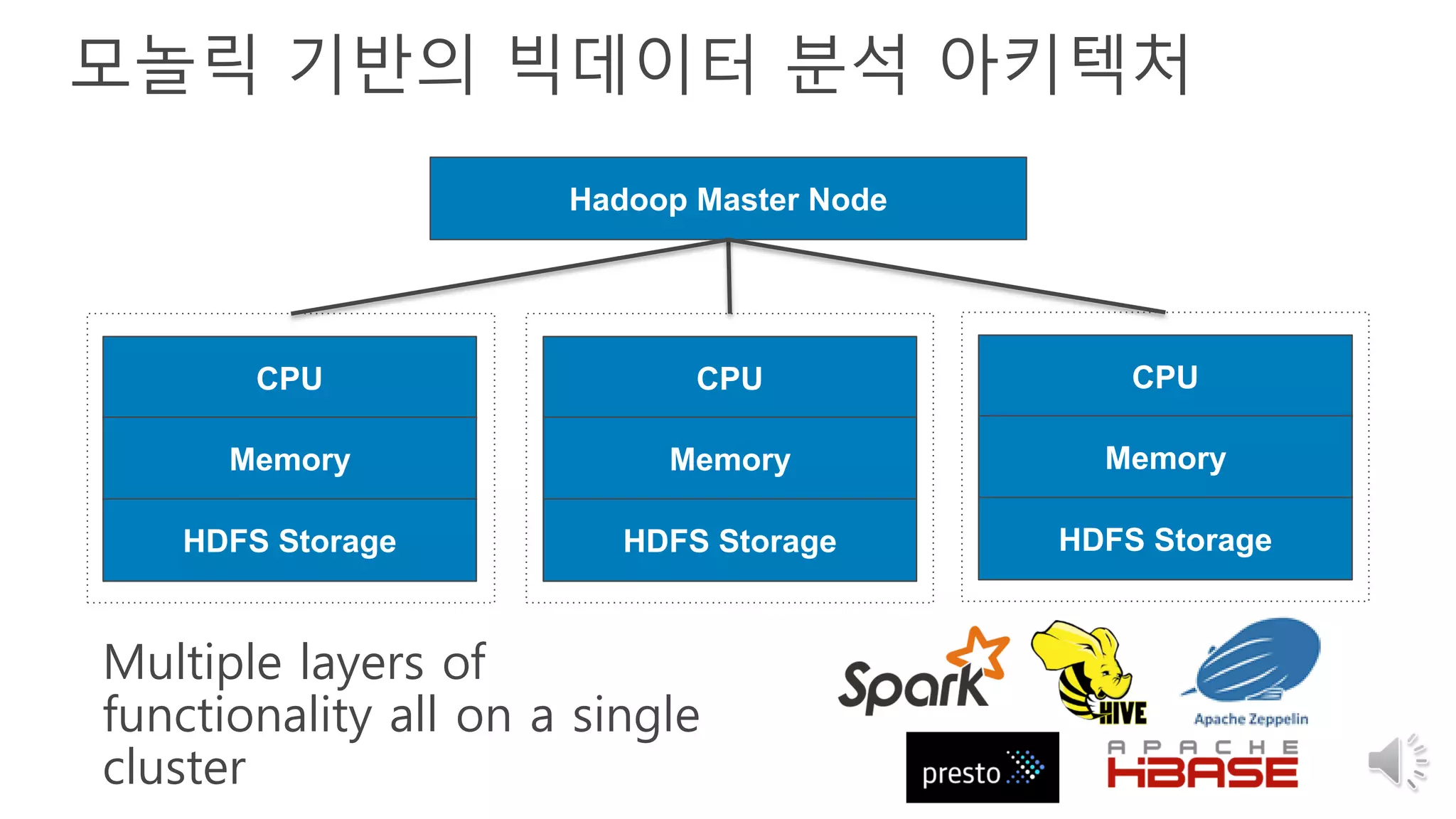
8. 9. 모놀릭 기반의 빅데이터 분석 아키텍처
CPU
Memory
HDFS Storage
CPU
Memory
HDFS Storage
CPU
Memory
HDFS Storage
Hadoop Master Node
Multiple layers of
functionality all on a single
cluster
10. 11. 12. 13. 14. 15. 16. 17. 메타데이터 관리
[ {
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionURL":"jdbc:mysql://RDS-
endpoint:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionDriverName":
"org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": "username",
"javax.jdo.option.ConnectionPassword": "password"
}
} ]
aws emr create-cluster --release-label emr-5.4.0 --instance-type
m3.xlarge --instance-count 2 --applications Name=Hive --
configurations hivemetadata.json --use-default-roles
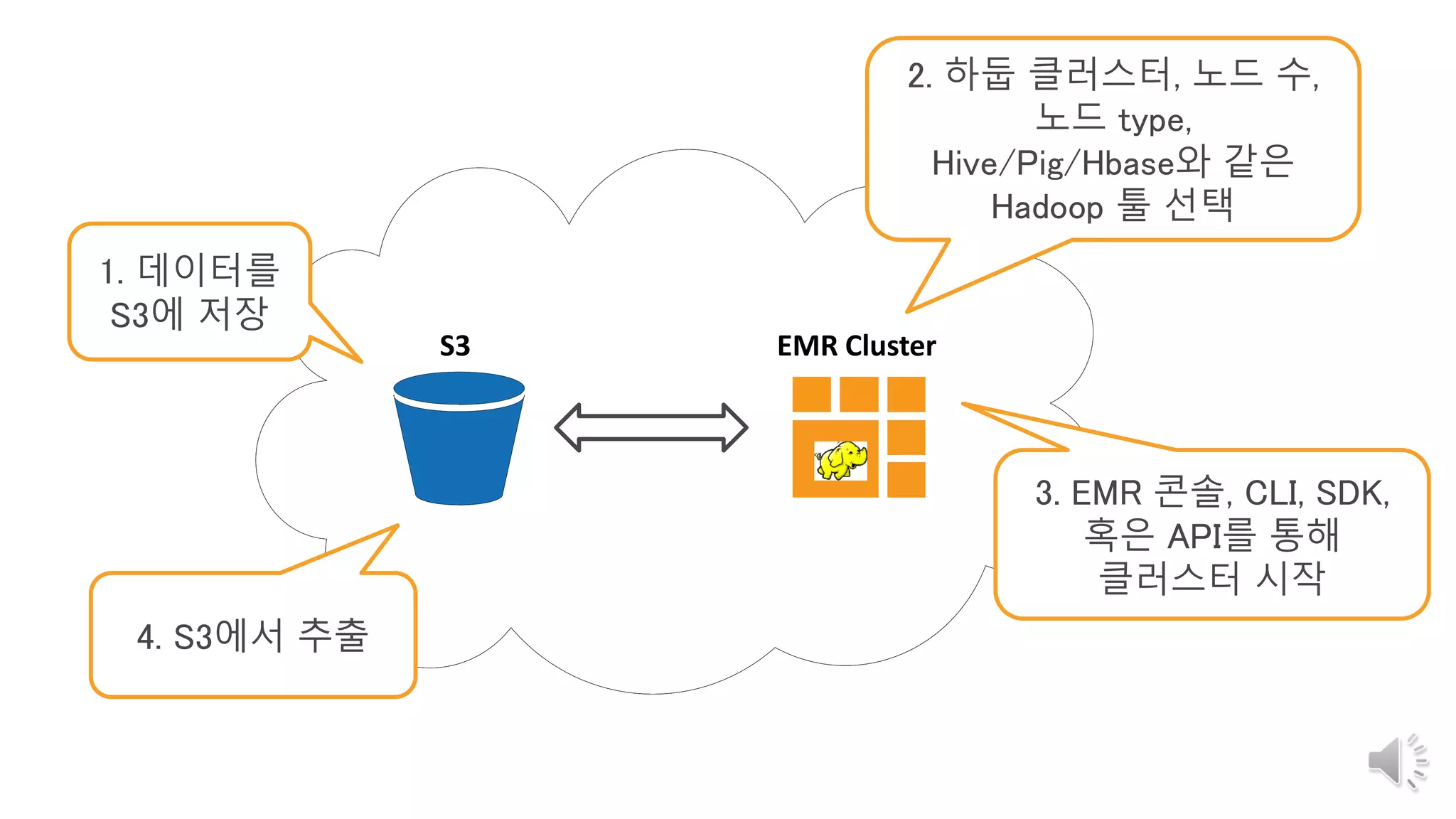
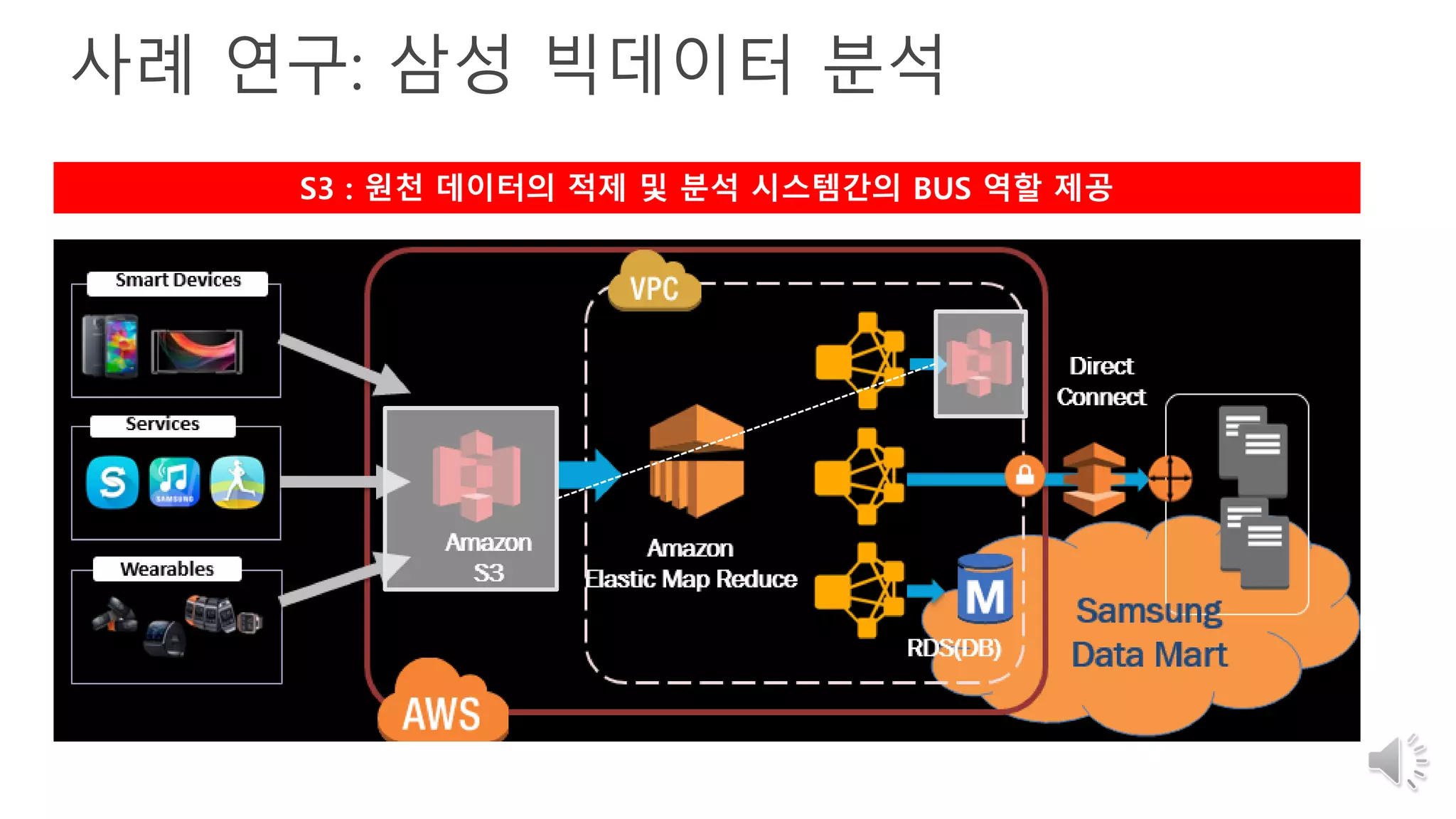
18. 19. 사례 연구: 삼성 빅데이터 분석
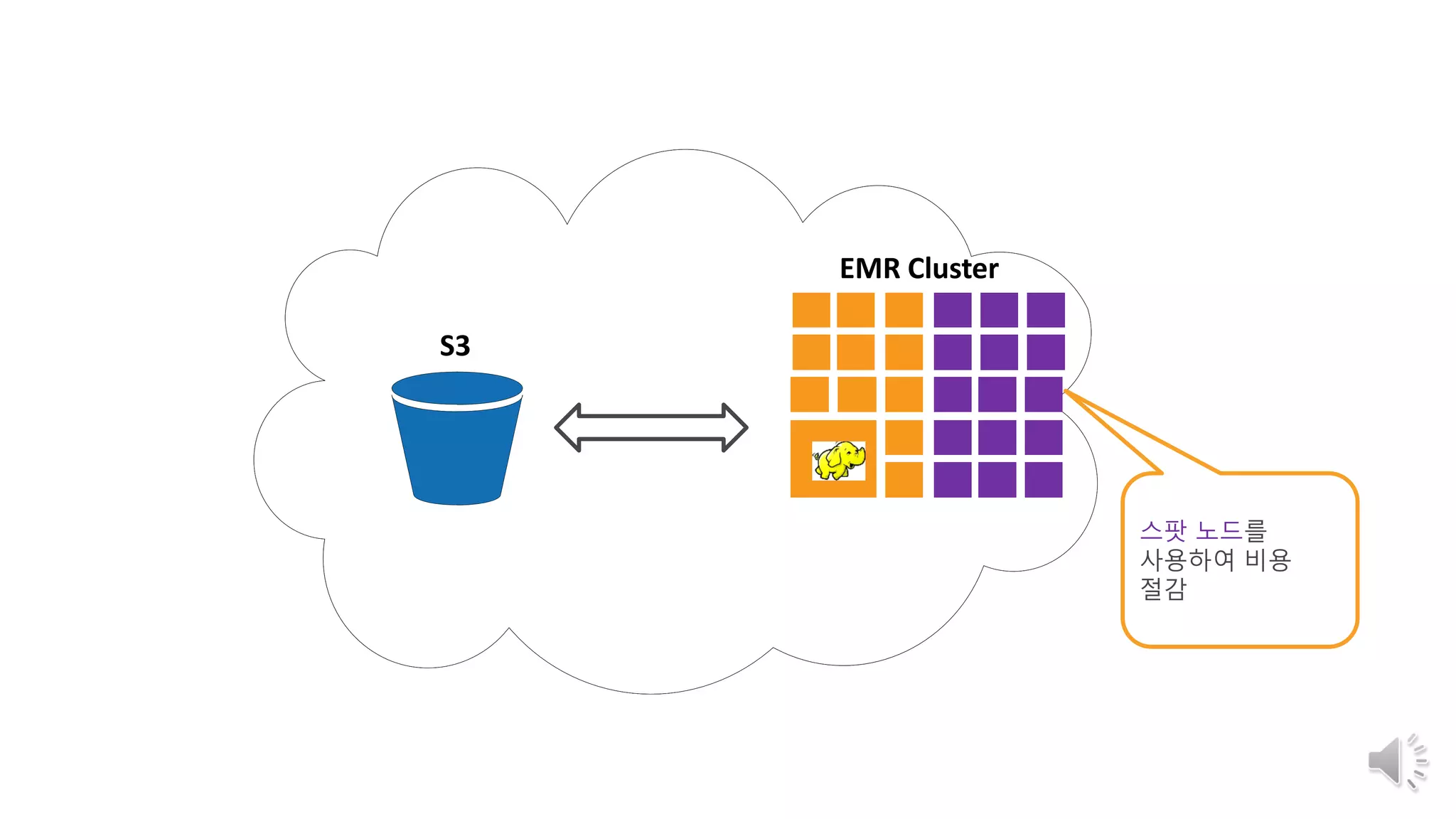
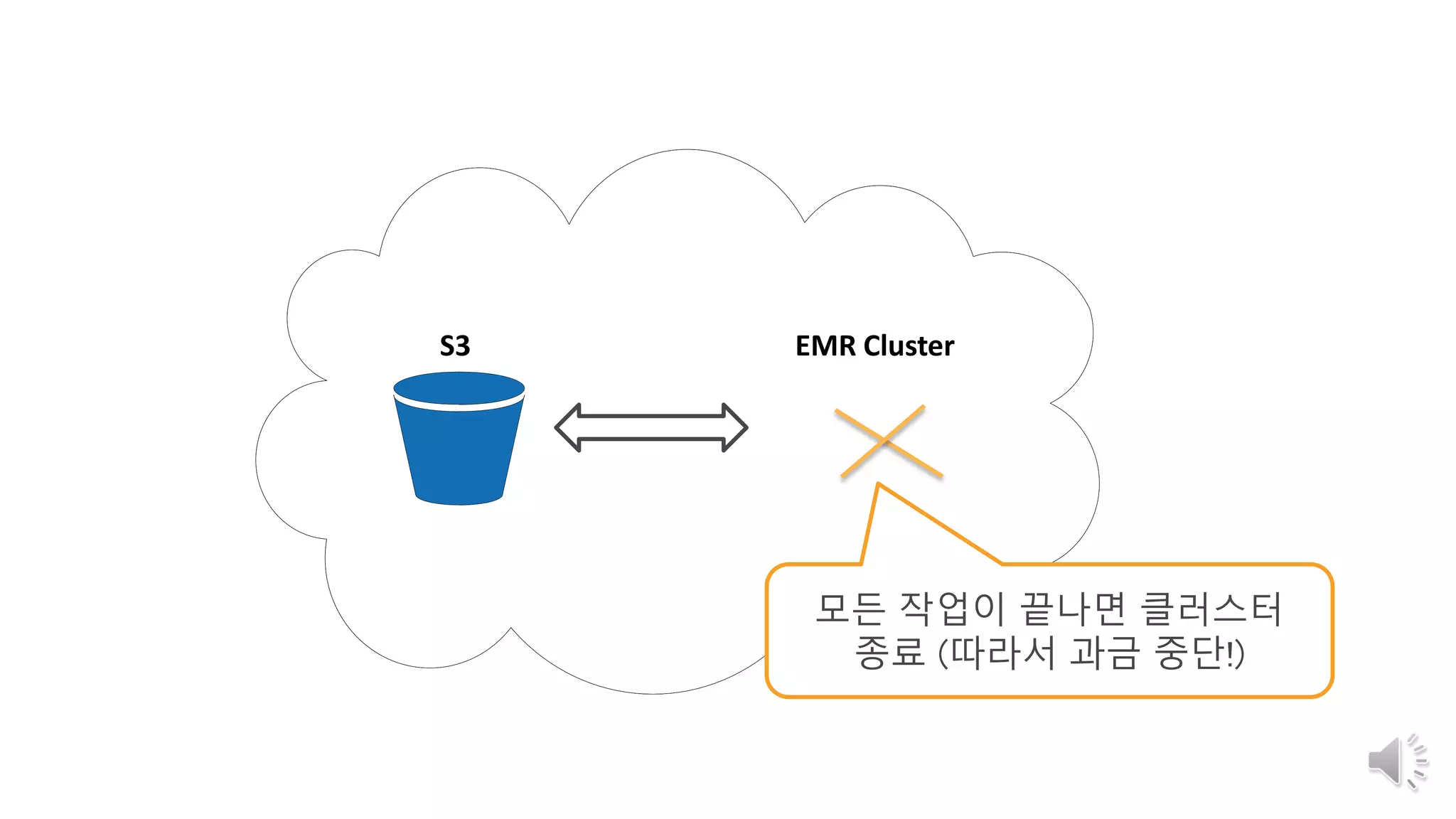
S3 : 원천 데이터의 적제 및 분석 시스템간의 BUS 역할 제공
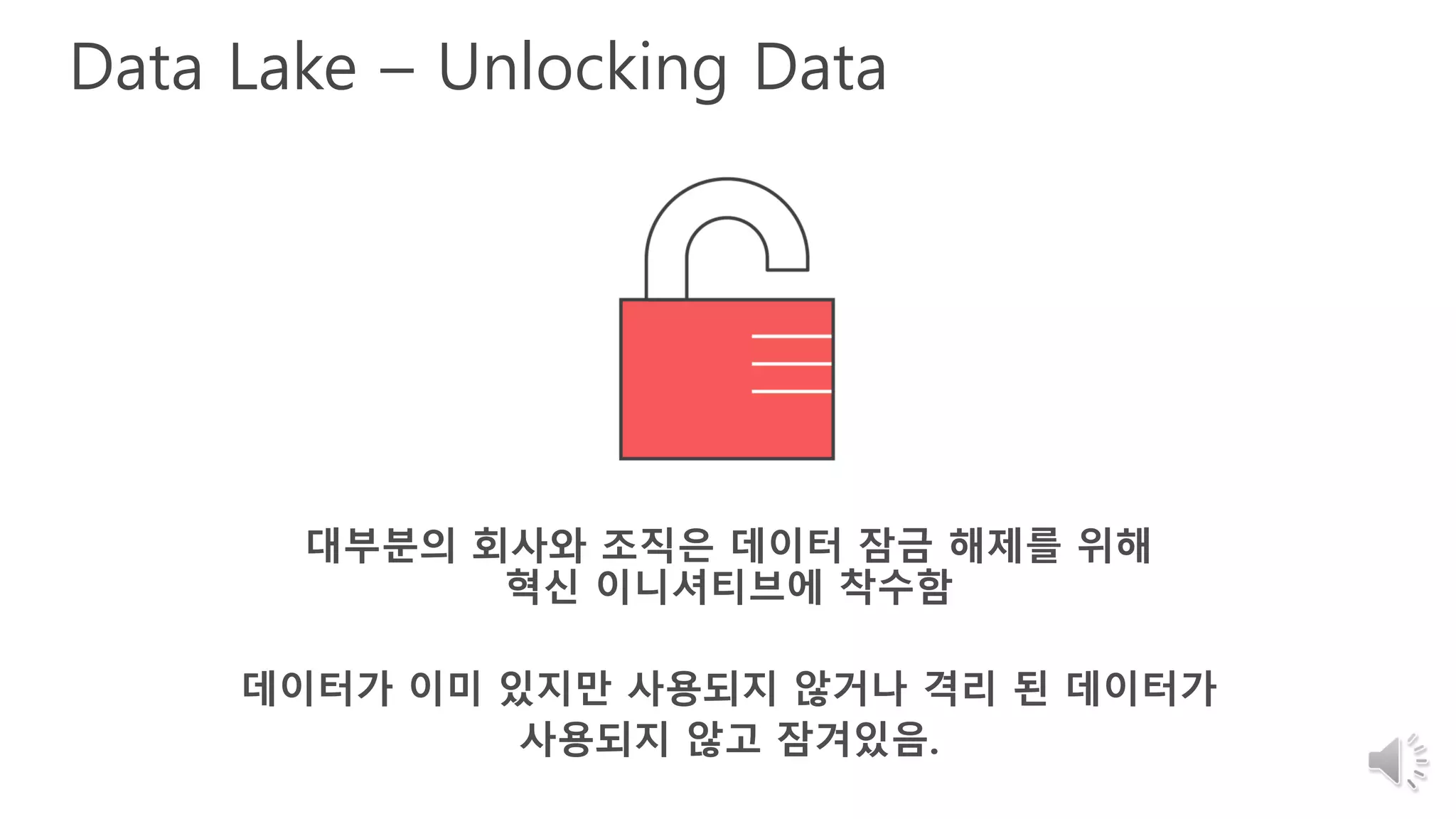
20. 21. Data Lake – Unlocking Data
대부분의 회사와 조직은 데이터 잠금 해제를 위해
혁신 이니셔티브에 착수함
데이터가 이미 있지만 사용되지 않거나 격리 된 데이터가
사용되지 않고 잠겨있음.
22. 22
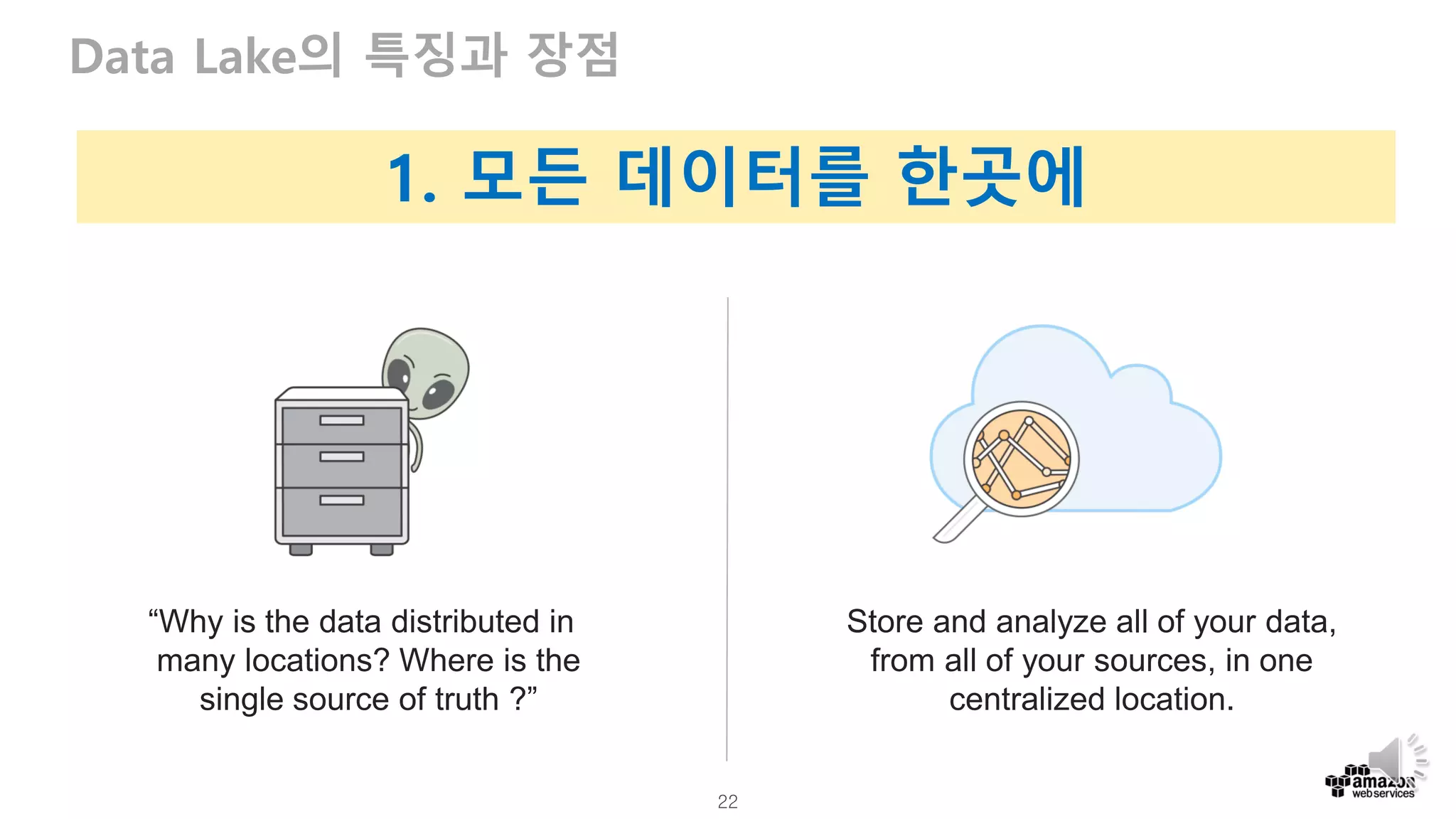
Data Lake의 특징과 장점
Store and analyze all of your data,
from all of your sources, in one
centralized location.
“Why is the data distributed in
many locations? Where is the
single source of truth ?”
1. 모든 데이터를 한곳에
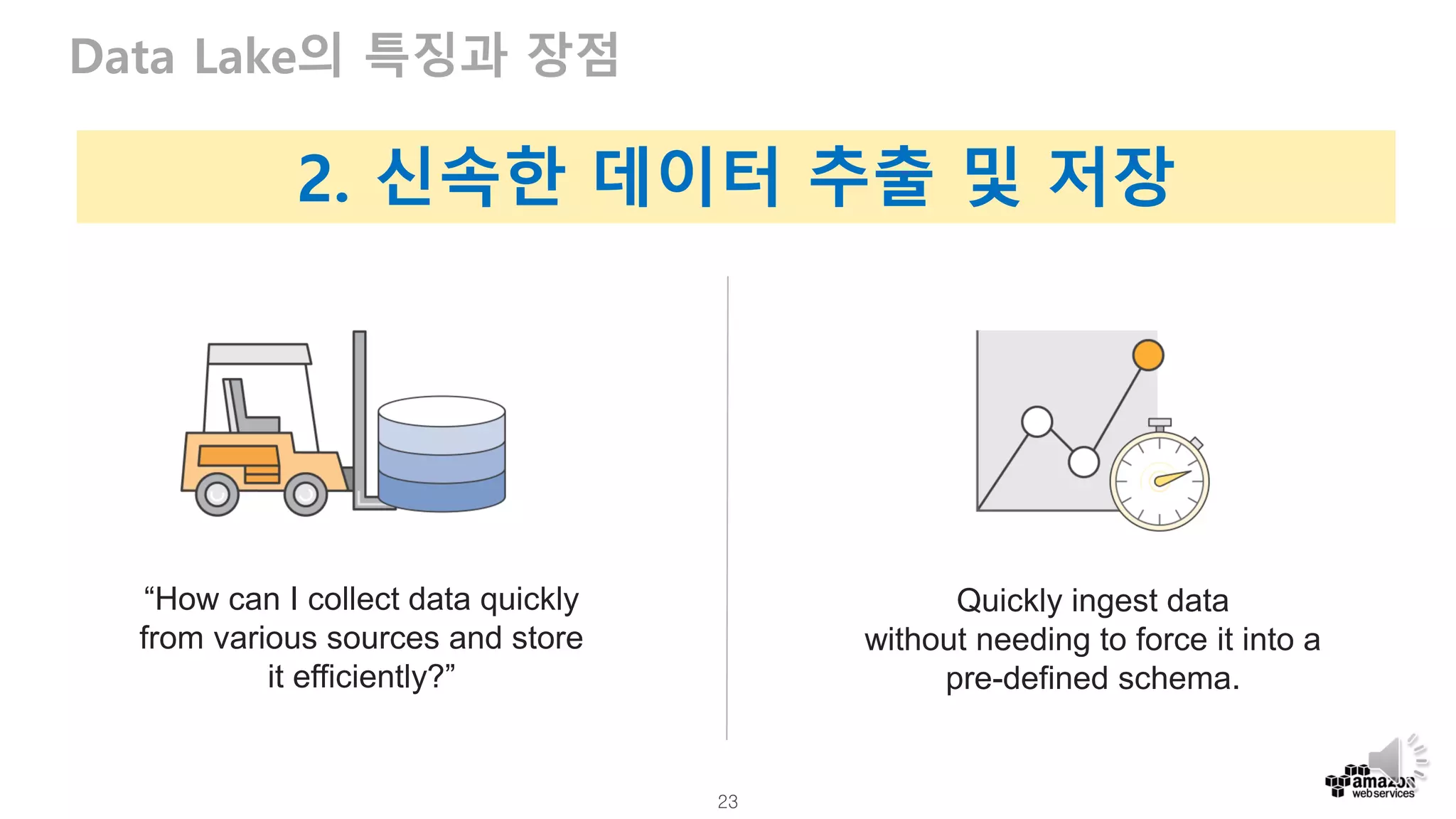
23. 23
Data Lake의 특징과 장점
Quickly ingest data
without needing to force it into a
pre-defined schema.
“How can I collect data quickly
from various sources and store
it efficiently?”
2. 신속한 데이터 추출 및 저장
24. 24
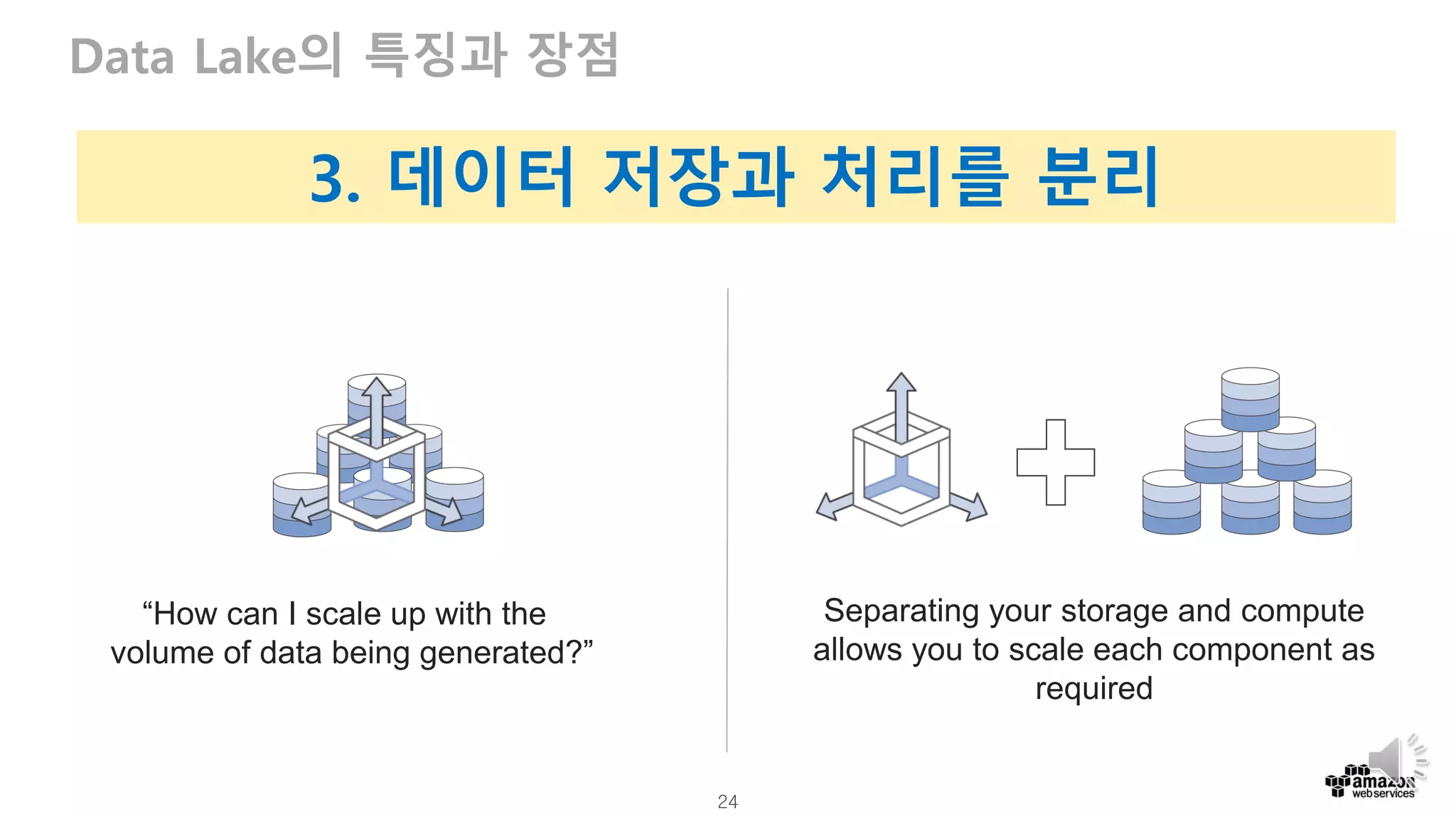
Data Lake의 특징과 장점
Separating your storage and compute
allows you to scale each component as
required
“How can I scale up with the
volume of data being generated?”
3. 데이터 저장과 처리를 분리
25. 25
Data Lake의 특징과 장점
4. 구조화 없이 분석 처리 (Schema on Read)
“Is there a way I can apply multiple
analytics and processing frameworks
to the same data?”
A Data Lake enables ad-hoc
analysis by applying schemas
on read, not write.
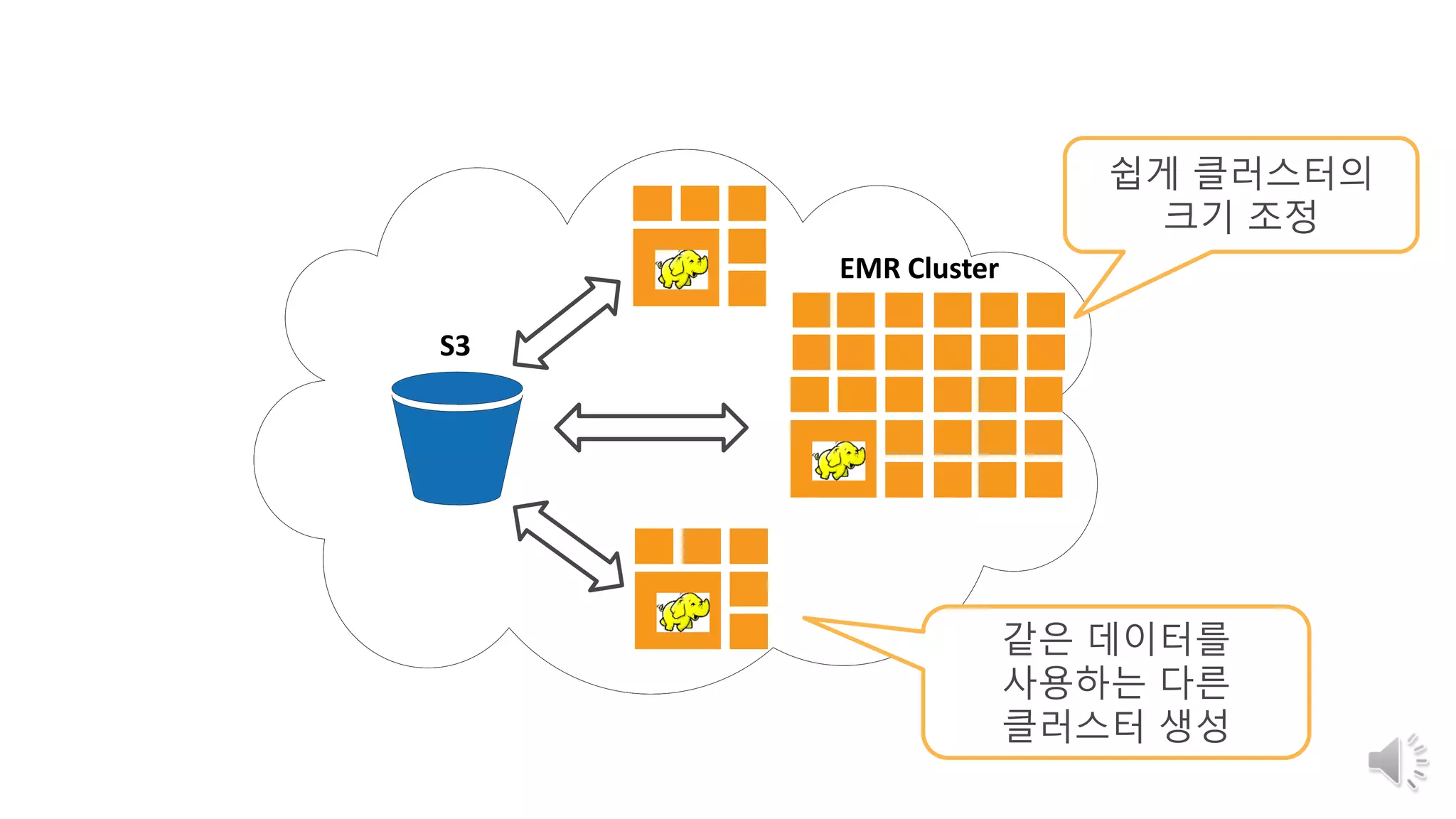
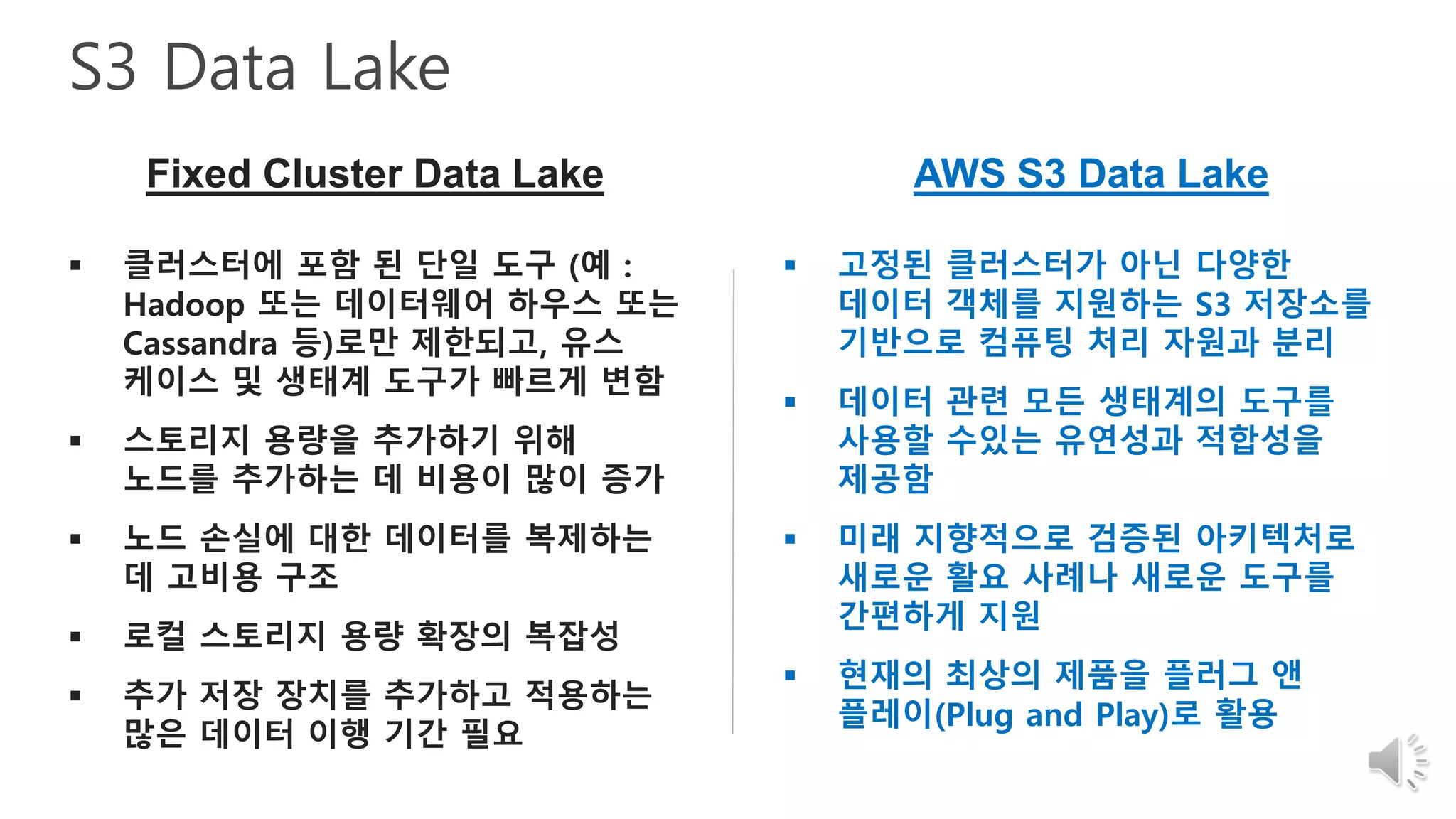
26. 27. 28. S3 Data Lake
Fixed Cluster Data Lake AWS S3 Data Lake
클러스터에 포함 된 단일 도구 (예 :
Hadoop 또는 데이터웨어 하우스 또는
Cassandra 등)로만 제한되고, 유스
케이스 및 생태계 도구가 빠르게 변함
스토리지 용량을 추가하기 위해
노드를 추가하는 데 비용이 많이 증가
노드 손실에 대한 데이터를 복제하는
데 고비용 구조
로컬 스토리지 용량 확장의 복잡성
추가 저장 장치를 추가하고 적용하는
많은 데이터 이행 기간 필요
고정된 클러스터가 아닌 다양한
데이터 객체를 지원하는 S3 저장소를
기반으로 컴퓨팅 처리 자원과 분리
데이터 관련 모든 생태계의 도구를
사용할 수있는 유연성과 적합성을
제공함
미래 지향적으로 검증된 아키텍처로
새로운 활요 사례나 새로운 도구를
간편하게 지원
현재의 최상의 제품을 플러그 앤
플레이(Plug and Play)로 활용
29. Data Lake로써의 S3
Designed for 11 9s
of durability
Designed for
99.99% availability
Durable Available High performance
Multiple upload
Range GET
Store as much as you need
Scale storage and compute
independently
No minimum usage commitments
Scalable
Amazon EMR
Amazon Redshift
Amazon DynamoDB
Integrated
Simple REST API
AWS SDKs
Event notification
Lifecycle Management
Easy to use
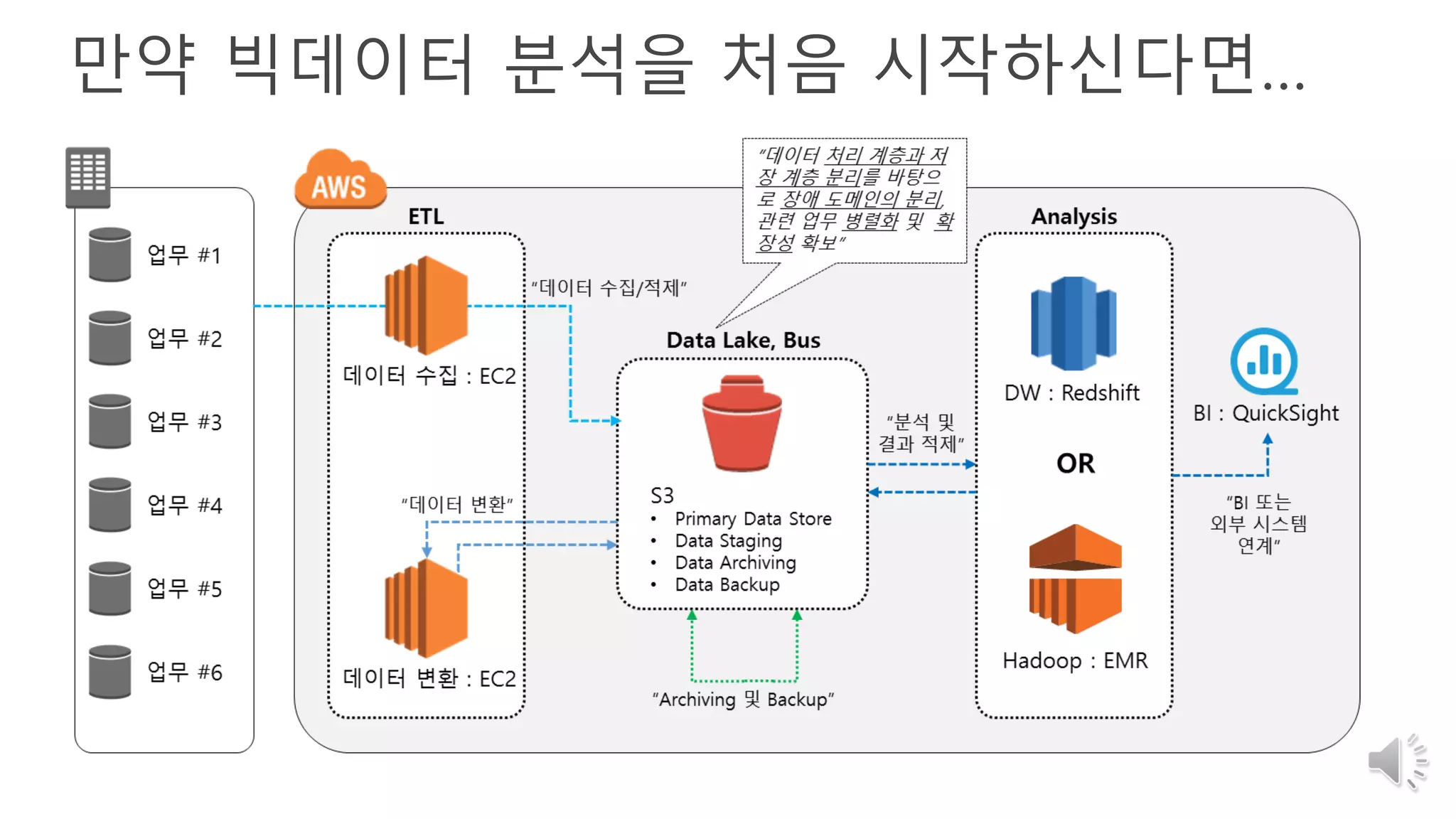
30. 31. Data Lake
Amazon EMR
Web
Mobile Application
LOG 데이터
Logstash
Crewing
Amazon Kinesis
실시간 분석 데이터 변환
원천 데이터 수집
실시간 예측
Amazon ML
Amazon EMR Amazon Elasticache Amazon DDB
Amazon
Elasticsearch
Amazon ML Amazon Athena
다양한 목적에 따른 분석 도구
“수많은 원천데이터를
실시간으로 수집 변환 하고”
“실시간으로 분석 하고”
“실시간으로 예측하며”
“분석에 목적에 맞춰
다양한 도구를 기반으로
분석 역량의 확장”
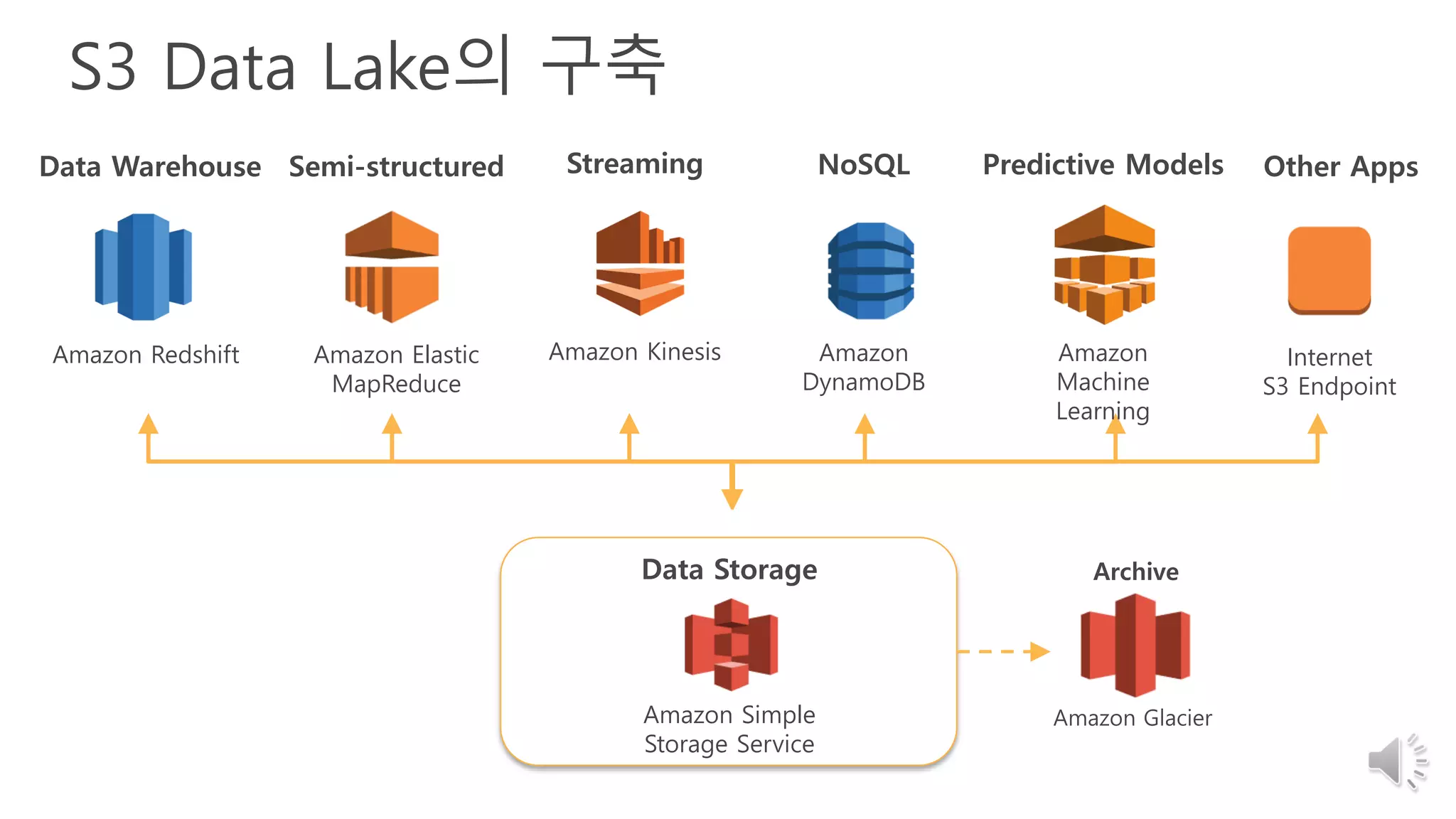
32. 33. S3 Data Lake의 구축
Amazon Redshift Amazon Elastic
MapReduce
Data Warehouse Semi-structured
Amazon GlacierAmazon Simple
Storage Service
Data Storage Archive
Amazon
DynamoDB
Amazon
Machine
Learning
Amazon Kinesis
NoSQL Predictive Models Other AppsStreaming
Internet
S3 Endpoint
34. 35. 36. 37. 질문에 대한 답변 드립니다.
발표자료/녹화영상 제공합니다.
http://bit.ly/awskr-webinar
더 나은 세미나를 위해
여러분의 의견을 남겨 주세요!





![메타데이터 관리
[ {
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionURL":"jdbc:mysql://RDS-
endpoint:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionDriverName":
"org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": "username",
"javax.jdo.option.ConnectionPassword": "password"
}
} ]
aws emr create-cluster --release-label emr-5.4.0 --instance-type
m3.xlarge --instance-count 2 --applications Name=Hive --
configurations hivemetadata.json --use-default-roles](https://image.slidesharecdn.com/datalakeonaws-170829070321/75/AWS-Datalake-AWS-8-17-2048.jpg)













![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)














![[AWS Migration Workshop] 데이터베이스를 AWS로 손쉽게 마이그레이션 하기](https://cdn.slidesharecdn.com/ss_thumbnails/fy19q2awsmigrationworkshop-yoojeongchoi-190619044742-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Builders] 클라우드 비용, 어떻게 줄일 수 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudeconomicsbonminkoo-190305081315-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Builders] AWS 네트워크 서비스 소개 및 사용 방법 - 김기현, AWS 솔루션즈 아키텍트](https://cdn.slidesharecdn.com/ss_thumbnails/1network-191112092246-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] AWS 클라우드 보안](https://cdn.slidesharecdn.com/ss_thumbnails/biohealthcareseminarsession04-180614105811-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Retail & CPG Day 2019] AWS기반의 Data 분석 플랫폼 구축, 고객사례 (GS SHOP) -김형일, AWS 솔루션즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/gsshop-191024042351-thumbnail.jpg?width=640&height=640&fit=bounds)








![[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략](https://cdn.slidesharecdn.com/ss_thumbnails/datafreedomdatabase-171027021754-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)


![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)