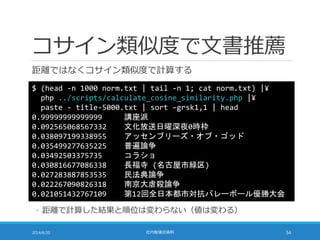
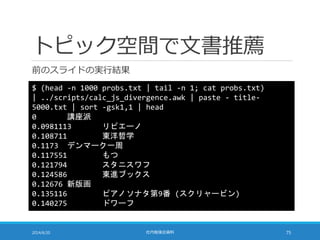
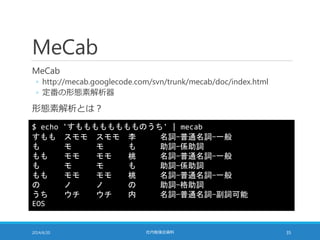
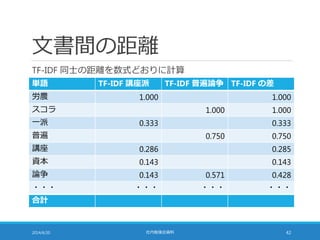
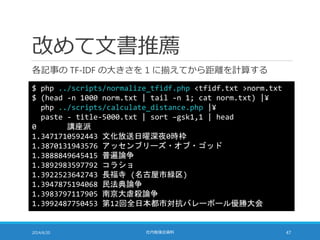
距離計算の高速化
TF-IDF の大きさを 1に揃えることで距離計算を高速化できる
◦ 点 A (a1, a2, a3, …, aN) と点 B (b1, b2, b3, …, bN) の距離は・・・
2014/6/20 社内勉強会資料 48
sum = 0;
for (i = 0; i < N; i++) {
sum += pow(b[i] – a[i], 2);
}
sum = sqrt(sum);
◦ pow の部分を展開すると・・・
sum = 0;
for (i = 0; i < N; i++) {
sum += b[i]*b[i] – 2*a[i]*b[i] + a[i]*a[i];
}
sum = sqrt(sum);
49.
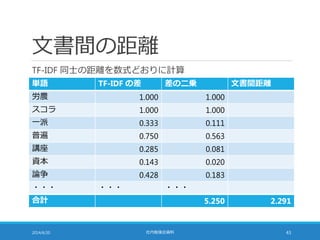
距離計算の高速化
TF-IDF の大きさを 1に揃えることで距離計算を高速化できる
◦ pow の部分を展開すると・・・
2014/6/20 社内勉強会資料 49
sum = 0;
for (i = 0; i < N; i++) {
sum += b[i]*b[i] – 2*a[i]*b[i] + a[i]*a[i];
}
sum = sqrt(sum);
◦ ばらばらに足してみると・・・
sum = 0;
for (i = 0; i < N; i++) sum += b[i]*b[i];
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
for (i = 0; i < N; i++) sum += a[i]*a[i];
sum = sqrt(sum);
50.
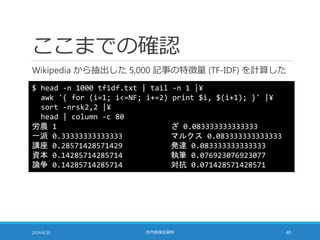
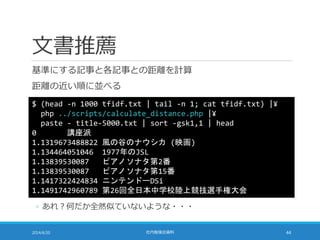
距離計算の高速化
TF-IDF の大きさを 1に揃えることで距離計算を高速化できる
◦ ばらばらに足してみると・・・
2014/6/20 社内勉強会資料 50
◦ 大きさを 1 に揃えたのだから・・・
sum = 0;
for (i = 0; i < N; i++) sum += b[i]*b[i];
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
for (i = 0; i < N; i++) sum += a[i]*a[i];
sum = sqrt(sum);
sum = 0;
sum += 1;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum += 1;
sum = sqrt(sum);
51.
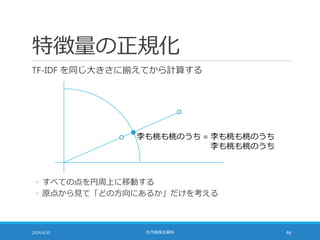
距離計算の高速化
TF-IDF の大きさを 1に揃えることで距離計算を高速化できる
◦ 大きさを 1 に揃えたのだから・・・
2014/6/20 社内勉強会資料 51
◦ ここまでを整理すると・・・
sum = 0;
sum += 1;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum += 1;
sum = sqrt(sum);
sum = 2;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum = sqrt(sum);
52.
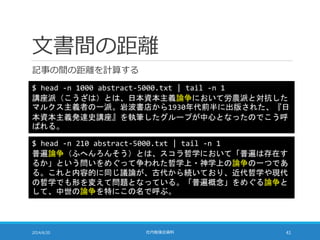
距離計算の高速化
TF-IDF の大きさを 1に揃えることで距離計算を高速化できる
◦ ここまでを整理すると・・・
2014/6/20 社内勉強会資料 52
◦ 距離そのものを計算しなくても大小関係が分かればよいので・・・
sum = 2;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum = sqrt(sum);
sum = 0;
for (i = 0; i < N; i++) sum += a[i]*b[i];
◦ これを大きな順に並べれば距離の近い順と同じになる
◦ a[i]*b[i] という形の計算しか残っていないのがポイント
◦ TF-IDF がどちらも 0 ではない単語だけ計算すればよい







![問題の整理
文書の「座標」とは何か?
それさえ決まれば、あとは距離を計算してソートするだけ
というわけで・・・
文書推薦の本質は以下の関数を実装する問題にほかならない
2014/6/20 社内勉強会資料 9
double[] documentToPosition (String document) {
...
}
◦ 文書を受け取って
◦ 座標を返す](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-9-320.jpg)
![特徴抽出
「座標」のことを「特徴量」と言う
◦ 特徴ベクトルと言ったりもするが同じだと思っておいて構わない
特徴量
◦ オブジェクトの特徴を表現する double[] 型の値
◦ 文書 = String オブジェクト
◦ 座標 = double[]
特徴抽出
◦ オブジェクトから特徴量を取り出すこと
2014/6/20 社内勉強会資料 10](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-10-320.jpg)
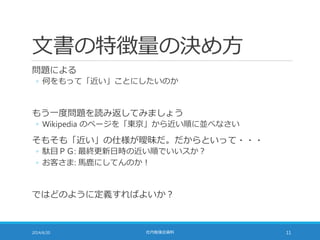





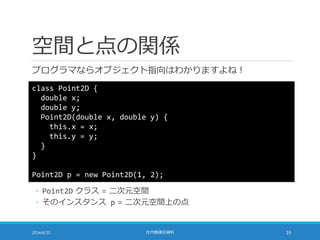
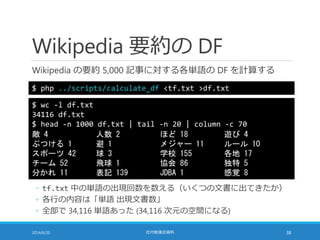
![TF-IDF の座標としての解釈
日本語のすべての単語を考える
◦ たとえば・・・広辞苑第六版の収録項目数 24 万語
それらの単語に通し番号をつける
文書の TF-IDF を 24 万要素の double[] で表現できる
◦ 文書に現れない単語は TF = 0 だから TF-IDF = 0
文書を 24 万次元空間上の点として表すことができた
2014/6/20 社内勉強会資料 17](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-17-320.jpg)

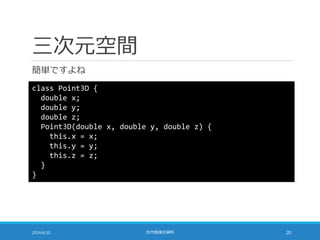
![二十四万次元空間
まあ普通は配列を使うでしょう
2014/6/20 社内勉強会資料 22
class Point240000D {
double[] x;
Point240000D(double[] x) {
this.x = new double[240000];
for (int i = 0; i < 240000; i++) {
this.x[i] = x[i];
}
}
}](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-22-320.jpg)
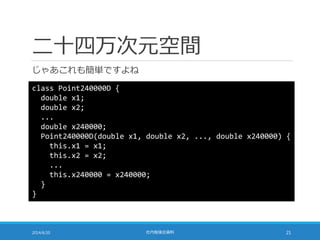
![二十四万次元空間
よく考えてみたら配列そのもので十分でした
2014/6/20 社内勉強会資料 23
double[] p = new double[240000];
p[getId("李")] = 0.1429;
p[getId("も")] = 0.0019;
p[getId("桃")] = 2.0000;
p[getId("の")] = 0.0002;
p[getId("うち")] = 0.0885;
◦ というわけで 24 万要素の配列 = 24 万次元空間の点
N 次元空間と言われたら N 要素の配列を考えればよい
◦ N 次元配列ではないことに注意](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-23-320.jpg)

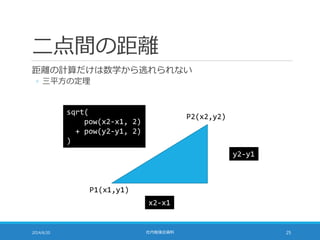
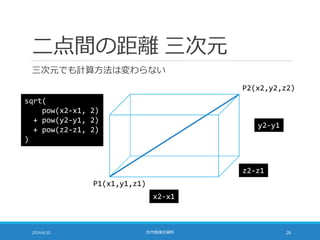
![二点間の距離 24 万次元
24 万次元でも計算方法は変わらない
2014/6/20 社内勉強会資料 27
double calcDistance(double[] a, double[] b) {
double distance = 0;
for (int i = 0; i < 240000; ++i) {
distance += pow(b[i] – a[i], 2);
}
return sqrt(distance);
}
◦ 次元数に応じてループの回数が増えるだけ](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-27-320.jpg)


![Wikipedia 要約の取得
日本語 Wikipedia のデータベースからダウンロード
◦ http://dumps.wikimedia.org/jawiki/
2014/6/20 社内勉強会資料 30
$ wget http://dumps.wikimedia.org/jawiki/latest/jawiki-
latest-abstract.xml
◦ データは巨大なので注意しましょう(2014-05-21 版で 1.4 GB)
$ head –n 5 jawiki-latest-abstract.xml
<feed>
<doc>
<title>Wikipedia: アンパサンド</title>
<url>http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%B3%E3%83%
91%E3%82%B5%E3%83%B3%E3%83%89</url>
<abstract>right|thumb|100px|[[Trebuchet MS フォン
ト]]</abstract>](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-30-320.jpg)
![テキストの抽出
ダウンロードした XML ファイルから必要な情報を切り出す
◦ 何が必要かは処理内容に応じて考える
◦ 今回の用途では「見出し」と「要約」を使う
2014/6/20 社内勉強会資料 31
$ grep -B2 '<abstract>' jawiki-latest-abstract.xml | grep
'^<[ta]' >a.tmp
$ grep '^<t' a.tmp | cut -f2- -d' ' | sed 's,<[^>]*>$,,'
>title.txt
$ grep '^<a' a.tmp | sed 's/<[^>]*>//g' >abstract.txt
$ rm a.tmp
◦ scripts/extract_title_abstract.sh を参照](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-31-320.jpg)
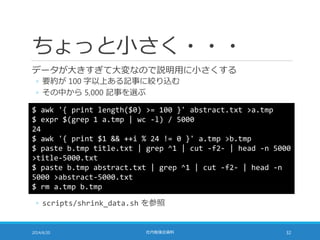
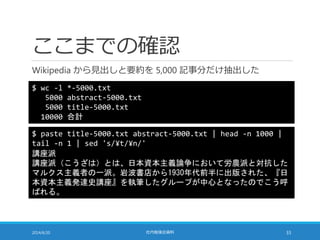
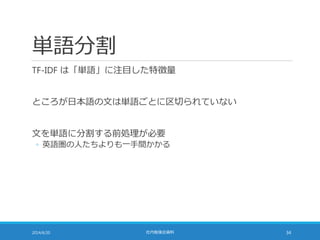




![距離計算の高速化
TF-IDF の大きさを 1 に揃えることで距離計算を高速化できる
◦ 点 A (a1, a2, a3, …, aN) と点 B (b1, b2, b3, …, bN) の距離は・・・
2014/6/20 社内勉強会資料 48
sum = 0;
for (i = 0; i < N; i++) {
sum += pow(b[i] – a[i], 2);
}
sum = sqrt(sum);
◦ pow の部分を展開すると・・・
sum = 0;
for (i = 0; i < N; i++) {
sum += b[i]*b[i] – 2*a[i]*b[i] + a[i]*a[i];
}
sum = sqrt(sum);](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-48-320.jpg)
![距離計算の高速化
TF-IDF の大きさを 1 に揃えることで距離計算を高速化できる
◦ pow の部分を展開すると・・・
2014/6/20 社内勉強会資料 49
sum = 0;
for (i = 0; i < N; i++) {
sum += b[i]*b[i] – 2*a[i]*b[i] + a[i]*a[i];
}
sum = sqrt(sum);
◦ ばらばらに足してみると・・・
sum = 0;
for (i = 0; i < N; i++) sum += b[i]*b[i];
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
for (i = 0; i < N; i++) sum += a[i]*a[i];
sum = sqrt(sum);](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-49-320.jpg)
![距離計算の高速化
TF-IDF の大きさを 1 に揃えることで距離計算を高速化できる
◦ ばらばらに足してみると・・・
2014/6/20 社内勉強会資料 50
◦ 大きさを 1 に揃えたのだから・・・
sum = 0;
for (i = 0; i < N; i++) sum += b[i]*b[i];
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
for (i = 0; i < N; i++) sum += a[i]*a[i];
sum = sqrt(sum);
sum = 0;
sum += 1;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum += 1;
sum = sqrt(sum);](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-50-320.jpg)
![距離計算の高速化
TF-IDF の大きさを 1 に揃えることで距離計算を高速化できる
◦ 大きさを 1 に揃えたのだから・・・
2014/6/20 社内勉強会資料 51
◦ ここまでを整理すると・・・
sum = 0;
sum += 1;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum += 1;
sum = sqrt(sum);
sum = 2;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum = sqrt(sum);](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-51-320.jpg)
![距離計算の高速化
TF-IDF の大きさを 1 に揃えることで距離計算を高速化できる
◦ ここまでを整理すると・・・
2014/6/20 社内勉強会資料 52
◦ 距離そのものを計算しなくても大小関係が分かればよいので・・・
sum = 2;
for (i = 0; i < N; i++) sum –= 2*a[i]*b[i];
sum = sqrt(sum);
sum = 0;
for (i = 0; i < N; i++) sum += a[i]*b[i];
◦ これを大きな順に並べれば距離の近い順と同じになる
◦ a[i]*b[i] という形の計算しか残っていないのがポイント
◦ TF-IDF がどちらも 0 ではない単語だけ計算すればよい](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-52-320.jpg)
![コサイン類似度 (高校レベル)
最後の式で計算される値をベクトルの内積と言う
2014/6/20 社内勉強会資料 53
sum = 0;
for (i = 0; i < N; i++) sum += a[i]*b[i];
a と b の原点からの距離が 1 のときは
「コサイン類似度」とも言う
θ
cos(θ)
a
b](https://image.slidesharecdn.com/documentrecommendation-140618082330-phpapp01/85/slide-53-320.jpg)