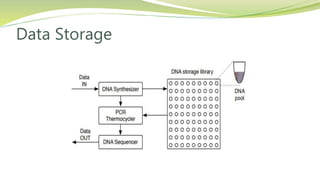
This seminar presentation discusses DNA data storage. It provides background on DNA and its structure, then summarizes the history of data storage from punch cards to modern technologies. Challenges of big data are reviewed. DNA is proposed as a storage medium due to its high density and longevity. The presentation explains how data is stored in DNA using algorithms and techniques like polymerase chain reaction. Current research by Microsoft is discussed as a case study. Both advantages like density and disadvantages like cost and read speeds are presented. Applications and future potential are considered.