引用
14
[1] Rombach, Robin,et al. "High-resolution image synthesis with latent
diffusion models." Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition. 2022.
[2] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance
fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[3] Dhariwal, Prafulla, and Alexander Nichol. "Diffusion models beat gans on
image synthesis." Advances in Neural Information Processing Systems 34
(2021): 8780-8794.
15.
引用
15
• [4] Ho,Jonathan, and Tim Salimans. "Classifier-free diffusion
guidance." arXiv preprint arXiv:2207.12598 (2022).
• [5] Oord, Aaron, et al. "Parallel wavenet: Fast high-fidelity speech
synthesis." International conference on machine learning. PMLR, 2018.
![DEEP LEARNING JP
[DL Papers]
“DreamFusion: Text-to-3D using 2D Diffusion”
Presenter: Takahiro Maeda D2
(Toyota Technological Institute)
http://deeplearning.jp/](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
“DreamFusion: Text-to-3D using 2D Diffusion”
Presenter: Takahiro Maeda D2
(Toyota Technological Institute)
http://deeplearning.jp/](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/75/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-1-2048.jpg)



![3. 研究背景
5
• ビデオゲームやCG映画は,大量の高精細な3Dモデルが必要
• これまでは,モデリングソフトなどを用いて人手で3Dモデルを作成
• 機械学習により生成する試みはあったが,データセットが少量のため
困難
• 発展が著しい Diffusionによる画像生成 + NeRFによる3次元形状
推定を組み合わせれば,大量の3Dモデルを生成できるのでは?
Stable Diffusion [1] NeRF[2]
サメ](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-5-320.jpg)
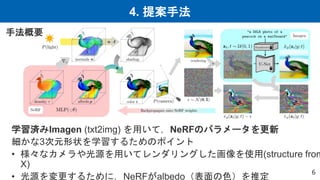
![4. 提案手法
• Classifier-free diffusion guidance[4] (CFG)
– テキストへの忠実性をコントロールする手法
– Stable Diffusion, GLIDE, Imagenなどの有名な手法で採用されている
– Diffusionの損失関数
ℒdiff 𝜙, 𝒙 = 𝔼[𝜔𝑡 𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 − 𝝐 ]
– classifier diffusion guidance[3]
𝝐𝜙(𝒛𝑡; 𝑦, 𝑡) = 𝝐𝜙 𝒛𝑡; 𝑡 − 𝜔𝑡𝜎𝑡𝛻𝒛𝑡log 𝑝(𝑦|𝒛𝑡)
– classifier-free diffusion guidance[4]
𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 = 1 + 𝜔 𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 − 𝜔𝝐𝜙 𝒛𝑡; ∅, 𝑡
テキストへの画像の忠実度を測るclassifierの勾
配
変更する推定ノイ
ズ
テキストを条件付け
した推定ノイズ
テキストを条件付けし
ない推定ノイズ
stable diffusion
𝜔 = 7.5
DreamFusion
𝝎 = 𝟏𝟎𝟎](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-8-320.jpg)

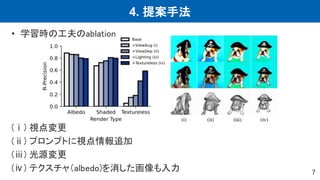
![4. 提案手法
10
• Score Distillation Sampling (SDS)
– Diffusion + NeRFの高計算負荷を緩和する高速化手法
– 色飽和した画像が出力されるため,画像生成には不向き
– Diffusionの損失関数の微分
𝛻𝜃ℒdiff 𝜙, 𝒙 = 𝔼[𝜔′
𝑡 𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 − 𝝐
𝜕𝝐𝜙 𝒛𝑡; 𝑦, 𝑡
𝜕𝒛𝑡
𝜕𝒙
𝜕𝜃
]
ただし,
𝜕𝒛𝑡
𝜕𝒙
=
𝜕(𝛼𝑡𝒙+𝜎𝑡𝝐)
𝜕𝒙
= 𝛼𝑡𝑰は省略,𝒙 = 𝑔(𝜃) (NeRF)
– Score Distillation Sampling
𝛻𝜃ℒdiff 𝜙, 𝒙 = 𝔼[𝜔′
𝑡 𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 − 𝝐
𝜕𝒙
𝜕𝜃
]
推定ノイズ誤
差 ノイズ推定器
の勾配
NeRFの勾配
削除](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-10-320.jpg)
![11
• Score Distillation Sampling (続き)
𝛻𝜃ℒdiff 𝜙, 𝒙 = 𝔼[𝜔′
𝑡 𝝐𝜙 𝒛𝑡; 𝑦, 𝑡 − 𝝐
𝜕𝒙
𝜕𝜃
]
– ノイズ推定器の勾配の無視により高速化し,現実的な計算コストに
– かなり場当たり的な手法では?
• 著者らはProbability Density Distillation Loss[5]と同等だと証明した
• 後付け感はぬぐえていない
• 話題性に乗ったスピード感のある論文なためしょうがない
– 勾配無視により色飽和した画像が生成されやすいらしい
– 色飽和した単調な背景が生成されやすいため,NeRFの学習が安定化するのでは?
色飽和の例](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-11-320.jpg)


![引用
14
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent
diffusion models." Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition. 2022.
[2] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance
fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
[3] Dhariwal, Prafulla, and Alexander Nichol. "Diffusion models beat gans on
image synthesis." Advances in Neural Information Processing Systems 34
(2021): 8780-8794.](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-14-320.jpg)
![引用
15
• [4] Ho, Jonathan, and Tim Salimans. "Classifier-free diffusion
guidance." arXiv preprint arXiv:2207.12598 (2022).
• [5] Oord, Aaron, et al. "Parallel wavenet: Fast high-fidelity speech
synthesis." International conference on machine learning. PMLR, 2018.](https://image.slidesharecdn.com/20221028dlseminarsdreamfusionv2-221028075435-fdcc2a8a/85/DL-DreamFusion-Text-to-3D-using-2D-Diffusion-15-320.jpg)


![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Freehand-Sketch to Image Synthesis 2018](https://cdn.slidesharecdn.com/ss_thumbnails/hozumi110918-181109001844-thumbnail.jpg?width=640&height=640&fit=bounds)






















