Download as PDF, PPTX


![99% of all data in Hadoop
156.68.7.63 - - [28/Jul/1995:11:53:28 -0400] "GET /images/WORLD-logosmall.gif HTTP/1.0" 200 669
137.244.160.140 - - [28/Jul/1995:11:53:29 -0400] "GET /images/WORLD-logosmall.gif HTTP/1.0" 304 0
163.205.160.5 - - [28/Jul/1995:11:53:31 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 4324
163.205.160.5 - - [28/Jul/1995:11:53:40 -0400] "GET /shuttle/countdown/count70.gif HTTP/1.0" 200 46573
140.229.50.189 - - [28/Jul/1995:11:53:54 -0400] "GET /shuttle/missions/sts-67/images/images.html HTTP/1.0"
163.206.89.4 - - [28/Jul/1995:11:54:02 -0400] "GET /shuttle/technology/sts-newsref/sts-mps.html HTTP/1.0" 2
163.206.89.4 - - [28/Jul/1995:11:54:05 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
163.206.89.4 - - [28/Jul/1995:11:54:05 -0400] "GET /images/shuttle-patch-logo.gif HTTP/1.0" 200 891
131.110.53.48 - - [28/Jul/1995:11:54:07 -0400] "GET /shuttle/technology/sts-newsref/stsref-toc.html HTTP/1.
163.205.160.5 - - [28/Jul/1995:11:54:14 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
130.160.196.81 - - [28/Jul/1995:11:54:15 -0400] "GET /shuttle/resources/orbiters/challenger.html HTTP/1.0"
131.110.53.48 - - [28/Jul/1995:11:54:16 -0400] "GET /images/shuttle-patch-small.gif HTTP/1.0" 200 4179
137.244.160.140 - - [28/Jul/1995:11:54:16 -0400] "GET /shuttle/missions/sts-69/mission-sts-69.html HTTP/1.0
131.110.53.48 - - [28/Jul/1995:11:54:18 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
131.110.53.48 - - [28/Jul/1995:11:54:19 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1713
130.160.196.81 - - [28/Jul/1995:11:54:19 -0400] "GET /shuttle/resources/orbiters/challenger-logo.gif HTTP/1
163.205.160.5 - - [28/Jul/1995:11:54:25 -0400] "GET /shuttle/missions/sts-70/images/images.html HTTP/1.0" 2
130.181.4.158 - - [28/Jul/1995:11:54:26 -0400] "GET /history/rocket-history.txt HTTP/1.0" 200 26990
137.244.160.140 - - [28/Jul/1995:11:54:30 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 304 0
137.244.160.140 - - [28/Jul/1995:11:54:31 -0400] "GET /images/launch-logo.gif HTTP/1.0" 304 0
137.244.160.140 - - [28/Jul/1995:11:54:38 -0400] "GET /history/apollo/images/apollo-logo1.gif HTTP/1.0" 304
168.178.17.149 - - [28/Jul/1995:11:54:48 -0400] "GET /shuttle/missions/sts-65/mission-sts-65.html HTTP/1.0"
140.229.50.189 - - [28/Jul/1995:11:54:53 -0400] "GET /shuttle/missions/sts-67/images/KSC-95EC-0390.jpg HTTP
131.110.53.48 - - [28/Jul/1995:11:54:58 -0400] "GET /shuttle/missions/missions.html HTTP/1.0" 200 8677
131.110.53.48 - - [28/Jul/1995:11:55:02 -0400] "GET /images/launchmedium.gif HTTP/1.0" 200 11853
131.110.53.48 - - [28/Jul/1995:11:55:05 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786
128.159.111.141 - - [28/Jul/1995:11:55:09 -0400] "GET /procurement/procurement.html HTTP/1.0" 200 3499
128.159.111.141 - - [28/Jul/1995:11:55:10 -0400] "GET /images/op-logo-small.gif HTTP/1.0" 200 14915
128.159.111.141 - - [28/Jul/1995:11:55:11 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786
128.159.111.141 - - [28/Jul/1995:11:55:11 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-2-320.jpg)








![Looks familiar?
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-40578233-2', 'godatadriven.com');
ga('send', 'pageview');
</script>](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-15-320.jpg)



![Data with a schema in Avro
{
"namespace": "com.example.record",
"type": "record",
"name": "MyEventRecord",
"fields": [
{ "name": "location", "type": "string" },
{ "name": "pageType", "type": "string" },
{ "name": "timestamp", "type": "long" }
]
}](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-22-320.jpg)


![Useful performance
Requests per second: 14010.80 [#/sec] (mean)
Time per request: 0.571 [ms] (mean)
Time per request: 0.071 [ms] (mean, across all concurrent requests)
Transfer rate: 4516.55 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 1
Processing: 0 0 0.2 0 3
Waiting: 0 0 0.2 0 3
Total: 0 1 0.2 1 3
Percentage of the requests served within a certain time (ms)
50% 1
66% 1
75% 1
80% 1
90% 1
95% 1
98% 1
99% 1
100% 3 (longest request)](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-26-320.jpg)




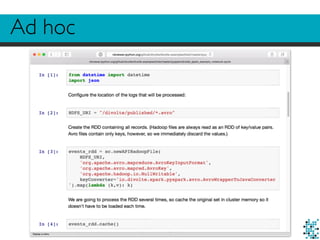
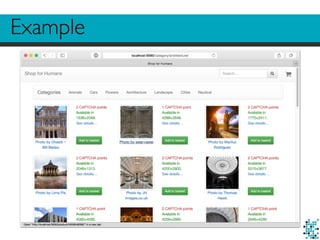
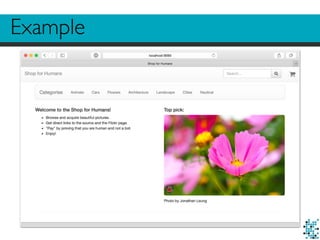



![Prototype UI
<div class="col-md-6">
<h4>Top pick:</h4>
<p>
<!-- Link to the product page with a source identifier for tracking -->
<a href="/product/{{ top_item['id'] }}/#/?source=top_pick">
<img class="img-responsive img-rounded" src="{{ top_item['variants']['Medium']['img_source'] }}">
<!-- Signal that we served an impression of this image -->
<script>divolte.signal('impression', { source: 'top_pick', productId: '{{ top_item['id'] }}'})</script>
</a>
</p>
<p>
Photo by {{ top_item['owner']['real_name'] or top_item['owner']['user_name']}}
</p>
</div>](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-40-320.jpg)
![Data collection in Divolte Collector
{
"name": "source",
"type": ["null", "string"],
"default": null
}
def locationUri = parse location() to uri
when eventType().equalTo('pageView') apply {
def fragmentUri = parse locationUri.rawFragment() to uri
map fragmentUri.query().value('source') onto 'source'
}
when eventType().equalTo('impression') apply {
map eventParameters().value('productId') onto 'productId'
map eventParameters().value('source') onto 'source'
}](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-41-320.jpg)


![Consuming Kafka in Python
def handle_event(message, reader):
# Decode Avro bytes into a Python dictionary.
message_bytes = io.BytesIO(message.value)
decoder = avro.io.BinaryDecoder(message_bytes)
event = reader.read(decoder)
# Event logic.
if 'top_pick' == event['source'] and 'pageView' == event['eventType']:
# Register a click.
redis_client.hincrby(
ITEM_HASH_KEY,
CLICK_KEY_PREFIX + ascii_bytes(event['productId']),
1)
elif 'top_pick' == event['source'] and 'impression' == event['eventType']:
# Register an impression and increment experiment count.
p = redis_client.pipeline()
p.incr(EXPERIMENT_COUNT_KEY)
p.hincrby(
ITEM_HASH_KEY,
IMPRESSION_KEY_PREFIX + ascii_bytes(event['productId']),
1)
experiment_count, ingnored = p.execute()
if experiment_count == REFRESH_INTERVAL:
refresh_items()](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-44-320.jpg)
![def refresh_items():
# Fetch current model state. We convert everything to str.
current_item_dict = redis_client.hgetall(ITEM_HASH_KEY)
current_items = numpy.unique([k[2:] for k in current_item_dict.keys()])
# Fetch random items from ElasticSearch. Note we fetch more than we need,
# but we filter out items already present in the current set and truncate
# the list to the desired size afterwards.
random_items = [
ascii_bytes(item)
for item in random_item_set(NUM_ITEMS + NUM_ITEMS - len(current_items) // 2)
if not item in current_items][:NUM_ITEMS - len(current_items) // 2]
# Draw random samples.
samples = [
numpy.random.beta(
int(current_item_dict[CLICK_KEY_PREFIX + item]),
int(current_item_dict[IMPRESSION_KEY_PREFIX + item]))
for item in current_items]
# Select top half by sample values. current_items is conveniently
# a Numpy array here.
survivors = current_items[numpy.argsort(samples)[len(current_items) // 2:]]
# New item set is survivors plus the random ones.
new_items = numpy.concatenate([survivors, random_items])
# Update model state to reflect new item set. This operation is atomic
# in Redis.
p = redis_client.pipeline(transaction=True)
p.set(EXPERIMENT_COUNT_KEY, 1)
p.delete(ITEM_HASH_KEY)
for item in new_items:
p.hincrby(ITEM_HASH_KEY, CLICK_KEY_PREFIX + item, 1)
p.hincrby(ITEM_HASH_KEY, IMPRESSION_KEY_PREFIX + item, 1)
p.execute()](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-45-320.jpg)
![Serving a recommendation
class BanditHandler(web.RequestHandler):
redis_client = None
def initialize(self, redis_client):
self.redis_client = redis_client
@gen.coroutine
def get(self):
# Fetch model state.
item_dict = yield gen.Task(self.redis_client.hgetall, ITEM_HASH_KEY)
items = numpy.unique([k[2:] for k in item_dict.keys()])
# Draw random samples.
samples = [
numpy.random.beta(
int(item_dict[CLICK_KEY_PREFIX + item]),
int(item_dict[IMPRESSION_KEY_PREFIX + item]))
for item in items]
# Select item with largest sample value.
winner = items[numpy.argmax(samples)]
self.write(winner)](https://image.slidesharecdn.com/divoltecollectoroverview-151106113413-lva1-app6891/85/Divolte-collector-overview-46-320.jpg)








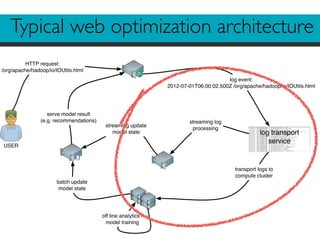
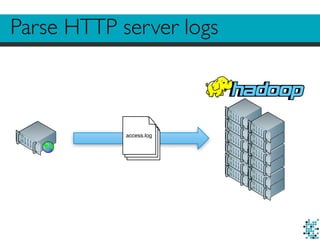
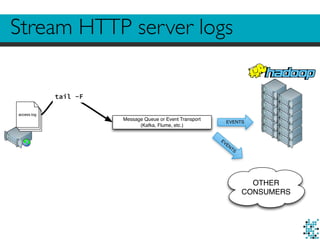
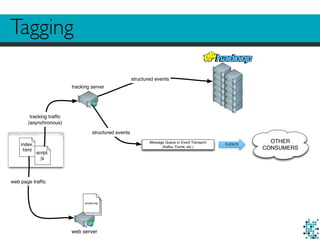
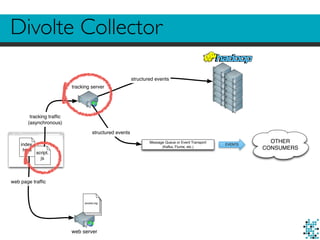
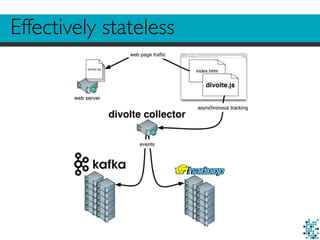
The document describes Divolte Collector, a tool for collecting clickstream data from web servers and streaming it to Apache Hadoop and Kafka in a structured format. It parses web server log files and tags pages with JavaScript to collect data on user behavior. The data is mapped to Avro schemas for interoperability and enriched with information like geolocation before being sent to event transports. This allows for real-time analytics on user behavior as well as batch processing and training of machine learning models.



















































































