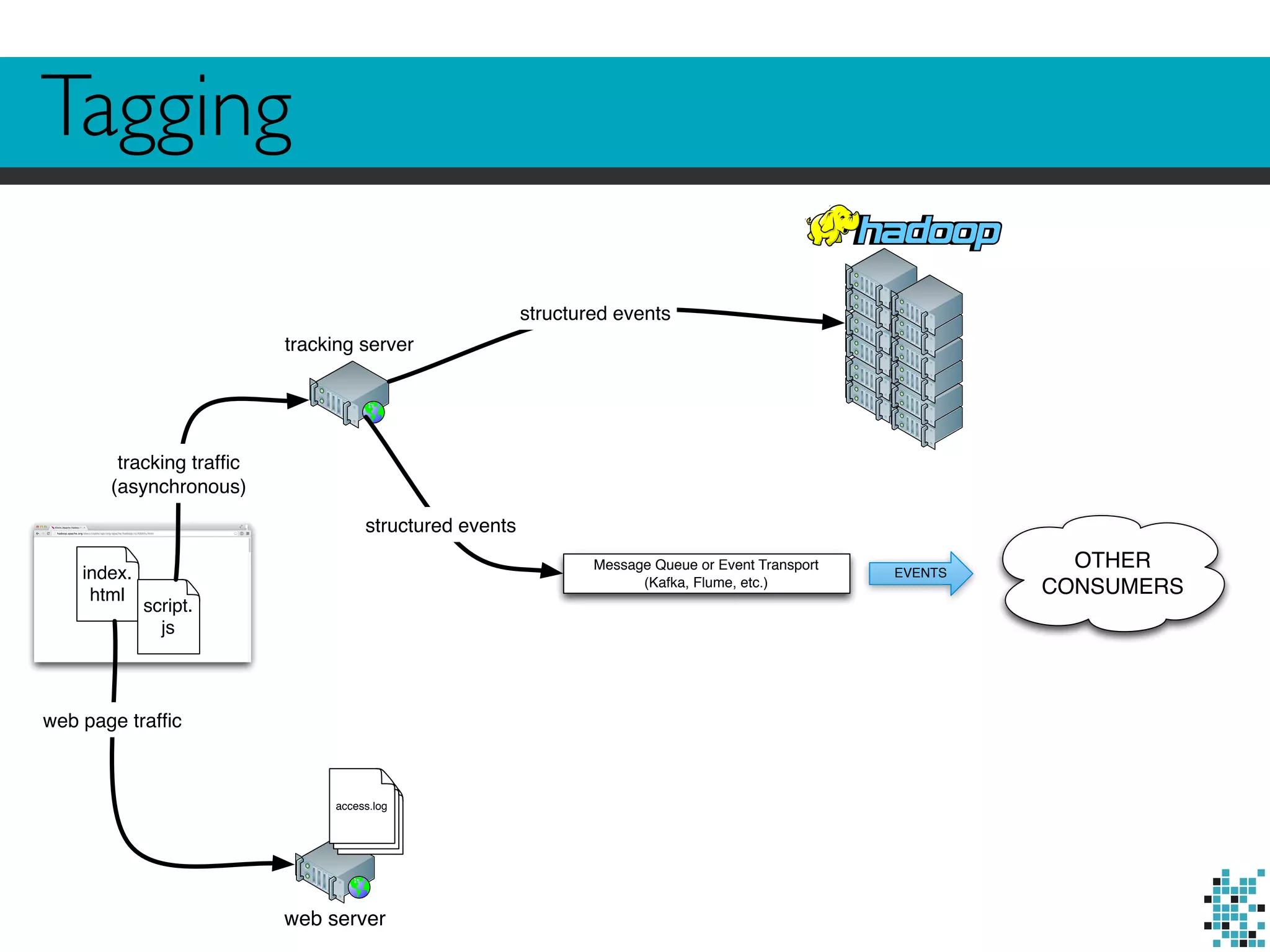
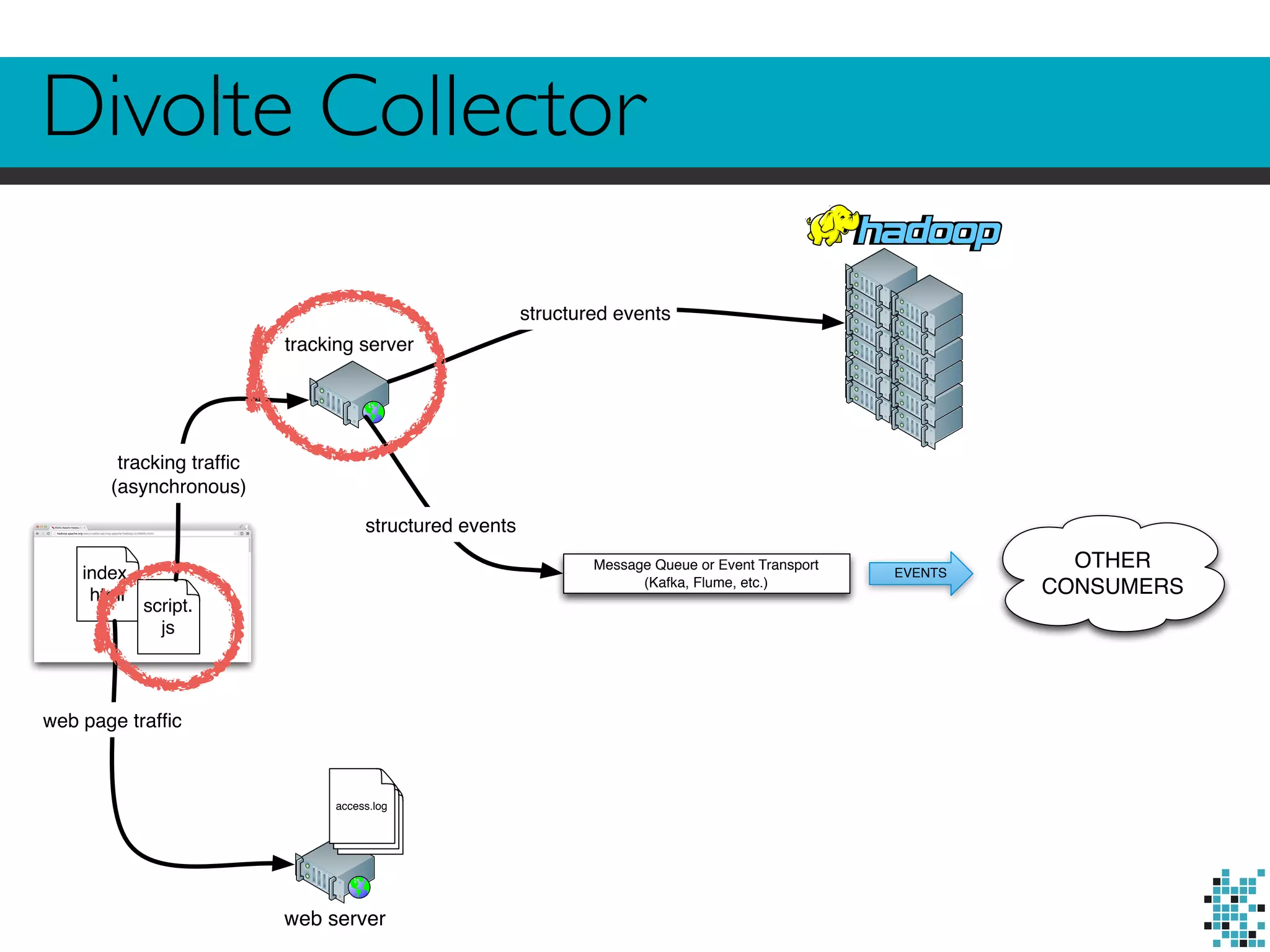
The document describes Divolte Collector, a tool for parsing and collecting structured event data from HTTP server logs and tags in real-time. It discusses options for accessing log/tag data, including parsing logs in Hadoop, streaming logs, and instrumenting pages with tags. It then outlines Divolte Collector's tag-based approach, how it structures and maps data, and how the tool can be configured to output events to Kafka or HDFS.

![99% of all data in Hadoop
156.68.7.63 - - [28/Jul/1995:11:53:28 -0400] "GET /images/WORLD-logosmall.gif HTTP/1.0" 200 669
137.244.160.140 - - [28/Jul/1995:11:53:29 -0400] "GET /images/WORLD-logosmall.gif HTTP/1.0" 304 0
163.205.160.5 - - [28/Jul/1995:11:53:31 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 4324
163.205.160.5 - - [28/Jul/1995:11:53:40 -0400] "GET /shuttle/countdown/count70.gif HTTP/1.0" 200 46573
140.229.50.189 - - [28/Jul/1995:11:53:54 -0400] "GET /shuttle/missions/sts-67/images/images.html HTTP/1.0" 163.206.89.4 - - [28/Jul/1995:11:54:02 -0400] "GET /shuttle/technology/sts-newsref/sts-mps.html HTTP/1.0" 200 163.206.89.4 - - [28/Jul/1995:11:54:05 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
163.206.89.4 - - [28/Jul/1995:11:54:05 -0400] "GET /images/shuttle-patch-logo.gif HTTP/1.0" 200 891
131.110.53.48 - - [28/Jul/1995:11:54:07 -0400] "GET /shuttle/technology/sts-newsref/stsref-toc.html HTTP/1.0" 163.205.160.5 - - [28/Jul/1995:11:54:14 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
130.160.196.81 - - [28/Jul/1995:11:54:15 -0400] "GET /shuttle/resources/orbiters/challenger.html HTTP/1.0" 131.110.53.48 - - [28/Jul/1995:11:54:16 -0400] "GET /images/shuttle-patch-small.gif HTTP/1.0" 200 4179
137.244.160.140 - - [28/Jul/1995:11:54:16 -0400] "GET /shuttle/missions/sts-69/mission-sts-69.html HTTP/1.0" 131.110.53.48 - - [28/Jul/1995:11:54:18 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
131.110.53.48 - - [28/Jul/1995:11:54:19 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1713
130.160.196.81 - - [28/Jul/1995:11:54:19 -0400] "GET /shuttle/resources/orbiters/challenger-logo.gif HTTP/1.0" 163.205.160.5 - - [28/Jul/1995:11:54:25 -0400] "GET /shuttle/missions/sts-70/images/images.html HTTP/1.0" 200 130.181.4.158 - - [28/Jul/1995:11:54:26 -0400] "GET /history/rocket-history.txt HTTP/1.0" 200 26990
137.244.160.140 - - [28/Jul/1995:11:54:30 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 304 0
137.244.160.140 - - [28/Jul/1995:11:54:31 -0400] "GET /images/launch-logo.gif HTTP/1.0" 304 0
137.244.160.140 - - [28/Jul/1995:11:54:38 -0400] "GET /history/apollo/images/apollo-logo1.gif HTTP/1.0" 304 168.178.17.149 - - [28/Jul/1995:11:54:48 -0400] "GET /shuttle/missions/sts-65/mission-sts-65.html HTTP/1.0" 140.229.50.189 - - [28/Jul/1995:11:54:53 -0400] "GET /shuttle/missions/sts-67/images/KSC-95EC-0390.jpg HTTP/131.110.53.48 - - [28/Jul/1995:11:54:58 -0400] "GET /shuttle/missions/missions.html HTTP/1.0" 200 8677
131.110.53.48 - - [28/Jul/1995:11:55:02 -0400] "GET /images/launchmedium.gif HTTP/1.0" 200 11853
131.110.53.48 - - [28/Jul/1995:11:55:05 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786
128.159.111.141 - - [28/Jul/1995:11:55:09 -0400] "GET /procurement/procurement.html HTTP/1.0" 200 3499
128.159.111.141 - - [28/Jul/1995:11:55:10 -0400] "GET /images/op-logo-small.gif HTTP/1.0" 200 14915
128.159.111.141 - - [28/Jul/1995:11:55:11 -0400] "GET /images/NASA-logosmall.gif HTTP/1.0" 200 786
128.159.111.141 - - [28/Jul/1995:11:55:11 -0400] "GET /images/KSC-logosmall.gif HTTP/1.0" 200 1204
192.213.154.220 - - [28/Jul/1995:11:55:15 -0400] "GET /shuttle/countdown/tour.html HTTP/1.0" 200 4347](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-2-2048.jpg)
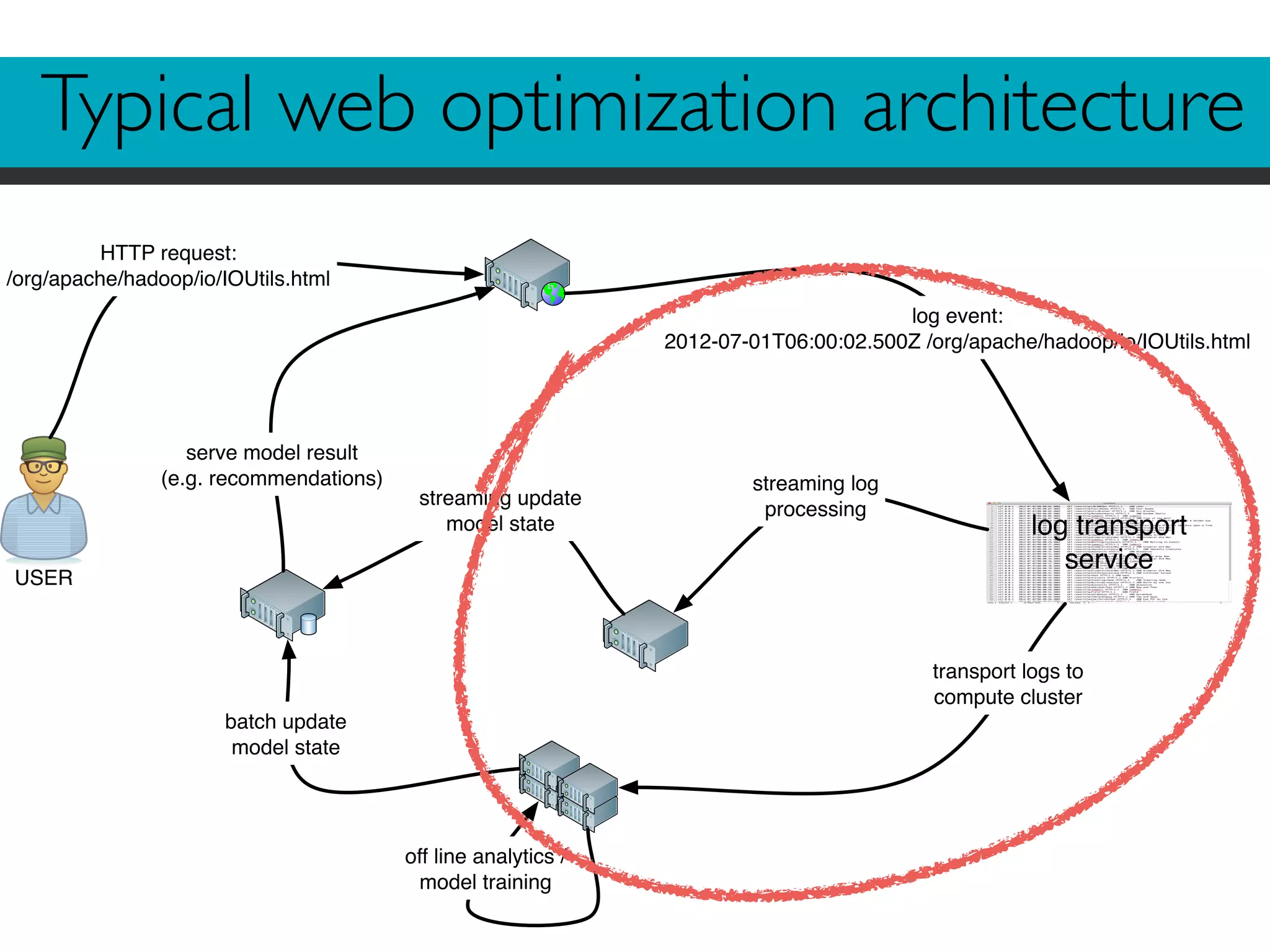
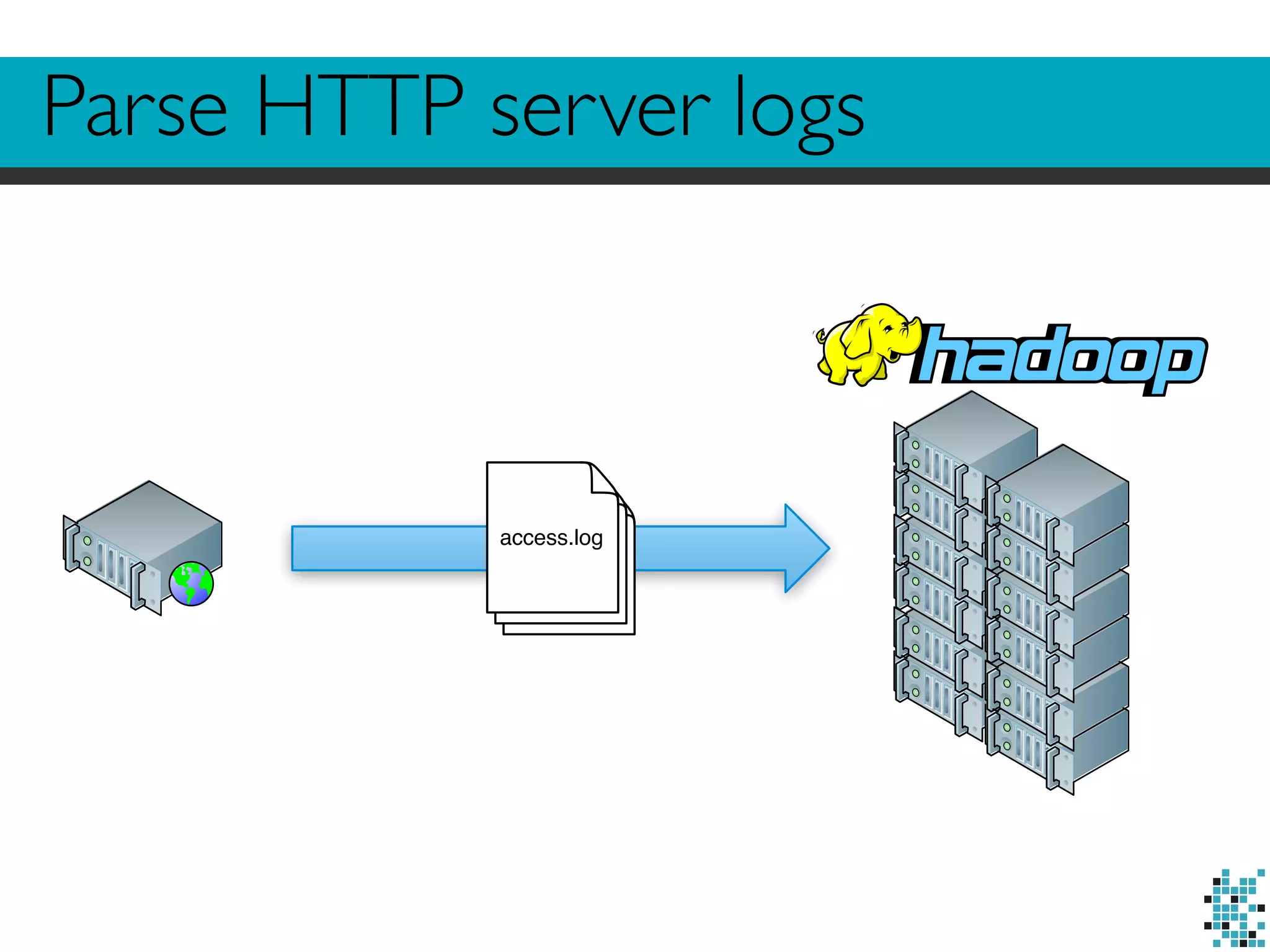


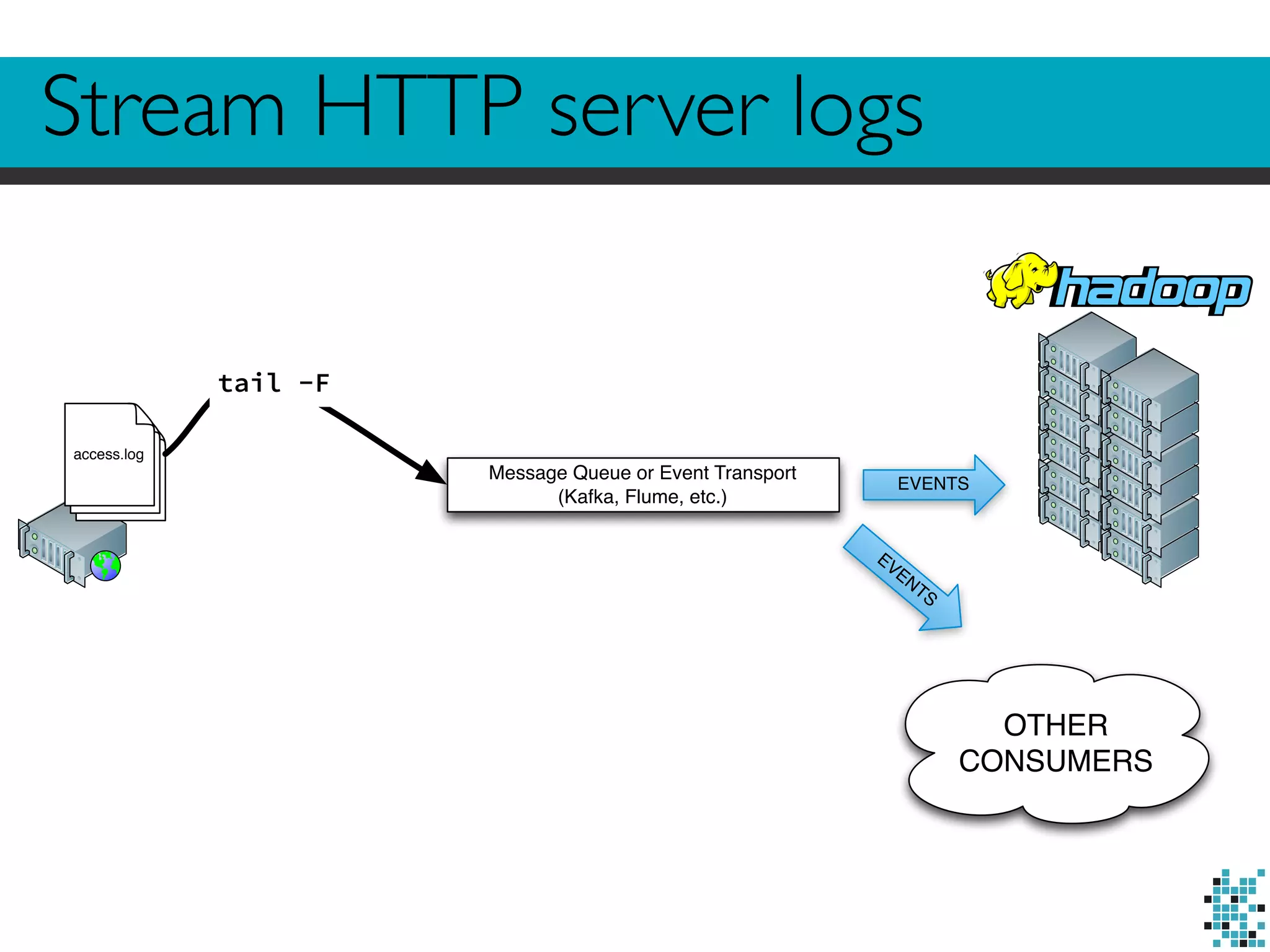





![Looks familiar?
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
!
ga('create', 'UA-40578233-2', 'godatadriven.com');
ga('send', 'pageview');
!
</script>](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-15-2048.jpg)


![Schema!
{
"namespace": "com.example.record",
"type": "record",
"name": "ClickEventRecord",
"fields": [
{ "name": "productNumber", "type": ["null", "string"], "default": null },
{ "name": "shop", "type": ["null", "string"], "default": null },
{ "name": "category", "type": ["null", "string"], "default": null },
{ "name": "advisor", "type": ["null", "string"], "default": null },
{ "name": "searchPhrase", "type": ["null", "string"], "default": null },
{ "name": "basketProductNumber", "type": ["null", "string"], "default": null },
{ "name": "basketSizeCode", "type": ["null", "string"], "default": null },
{ "name": "basketProductCount", "type": ["null", "string"], "default": null }
]
}](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-19-2048.jpg)
![Mapping
// Page type detector:
// http://.../basket
basket = "^https?://[^/]+/basket(?:[?#].*)?$"
!
// Page type detector:
// http://.../search?q=fiets
search = "^https?://[^/]+/search?.*$"
!
// Page type detector:
// http://.../checkout
checkout = "^https?://[^/]+/checkout(?:[?#].*)?$"
!
// Page type detector:
// http://.../thankyou
payment_ok = "^https://[^/]+/thankyou(?:[?#].*)?$"](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-20-2048.jpg)
![Mapping
pageType {
type = regex_name
regexes = [
home, category, shop, basket, search, customercare
]
field = location
}
productNumber {
type = regex_group
regex = pdp
field = location
group = product
}
viewportPixelWidth = viewportPixelWidth
viewportPixelHeight = viewportPixelHeight
screenPixelWidth = screenPixelWidth
screenPixelHeight = screenPixelHeight](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-21-2048.jpg)

![Configure
kafka_flusher {
enabled = true
producer = {
metadata.broker.list = [
"broker1:9092",
"broker2:9092",
"broker3:9092"
]
}
}
!
…](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-23-2048.jpg)



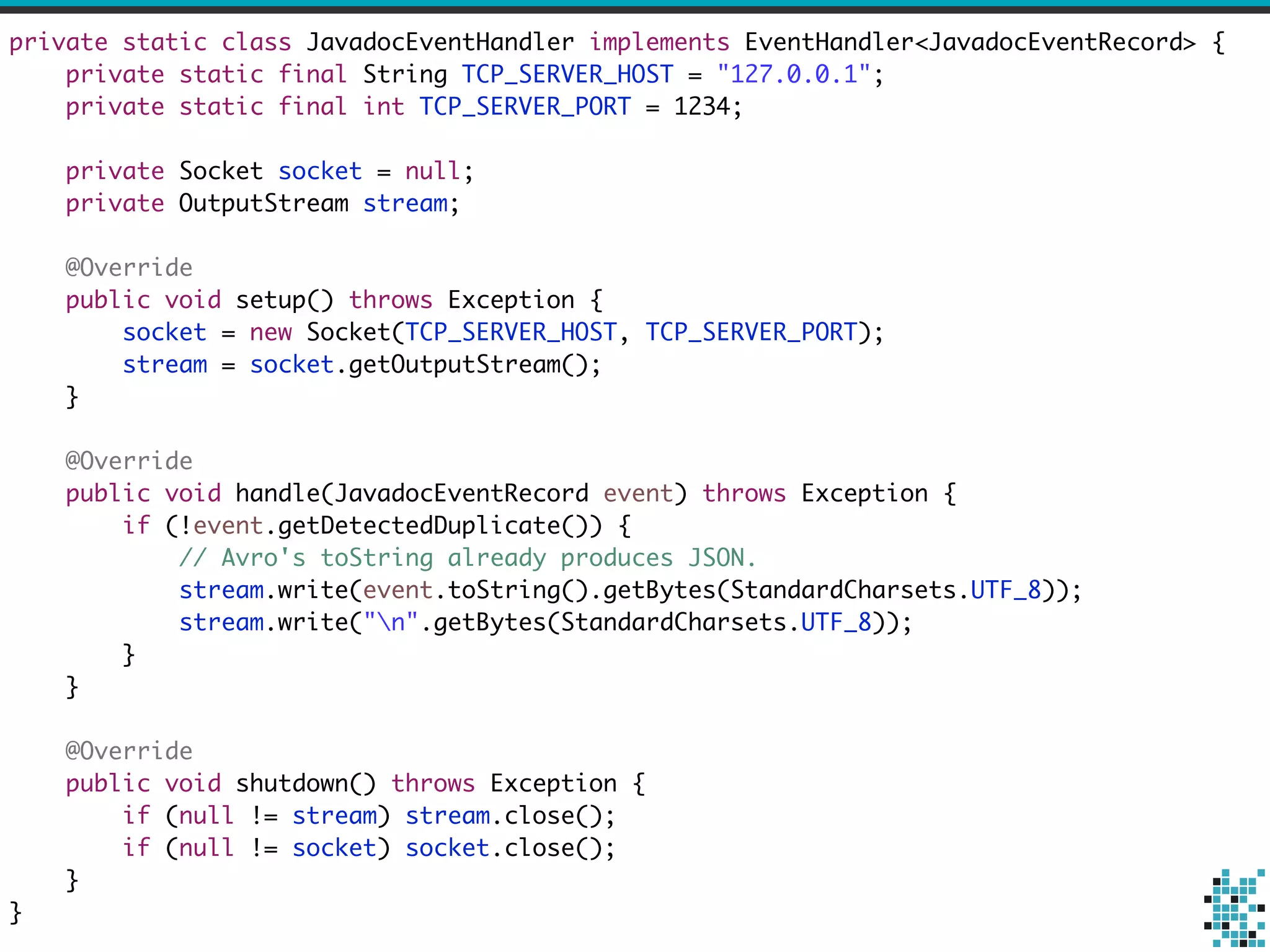
![public static void main(String[] args) {
final DivolteKafkaConsumer<JavadocEventRecord> consumer =
DivolteKafkaConsumer.createConsumer(
KAFKA_TOPIC,
ZOOKEEPER_QUORUM,
KAFKA_CONSUMER_GROUP_ID,
NUM_CONSUMER_THREADS,
() -> new JavadocEventHandler(),
JavadocEventRecord.getClassSchema());
!
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("Shutting down consumer.");
consumer.shutdownConsumer();
}));
!
System.out.println("Starting consumer.");
consumer.startConsumer();
}](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-29-2048.jpg)




!
// And then…
val records = events.toRecords
// or
val eventFields = events.fields("sessionId", "location", "timestamp")](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-36-2048.jpg)

!
// And then…
val eventStream = stream.toRecords
// or
val locationStream = stream.fields("location")](https://image.slidesharecdn.com/divoltecollector-meetup-141107031609-conversion-gate02/75/Divolte-Collector-meetup-presentation-37-2048.jpg)









































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)





