![Distributed Streams [1] Presented by: Ashraf Bashir](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-1-2048.jpg)
![Objectives Introduce the model of Distributed Streams. Understand the main factors that affect the Distributed Stream model. How to manage “One-shot queries” in Distributed Streams ? Handling “message loss” in Distributed Streams. Introduce “decentralized computations techniques” in Distributed Streams. A brief overview on “Aggregate Computation” and main problems that exist in it. Overview of “Minos Garofalakis” [2] for the future of Distributed Streams System 1/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-2-2048.jpg)


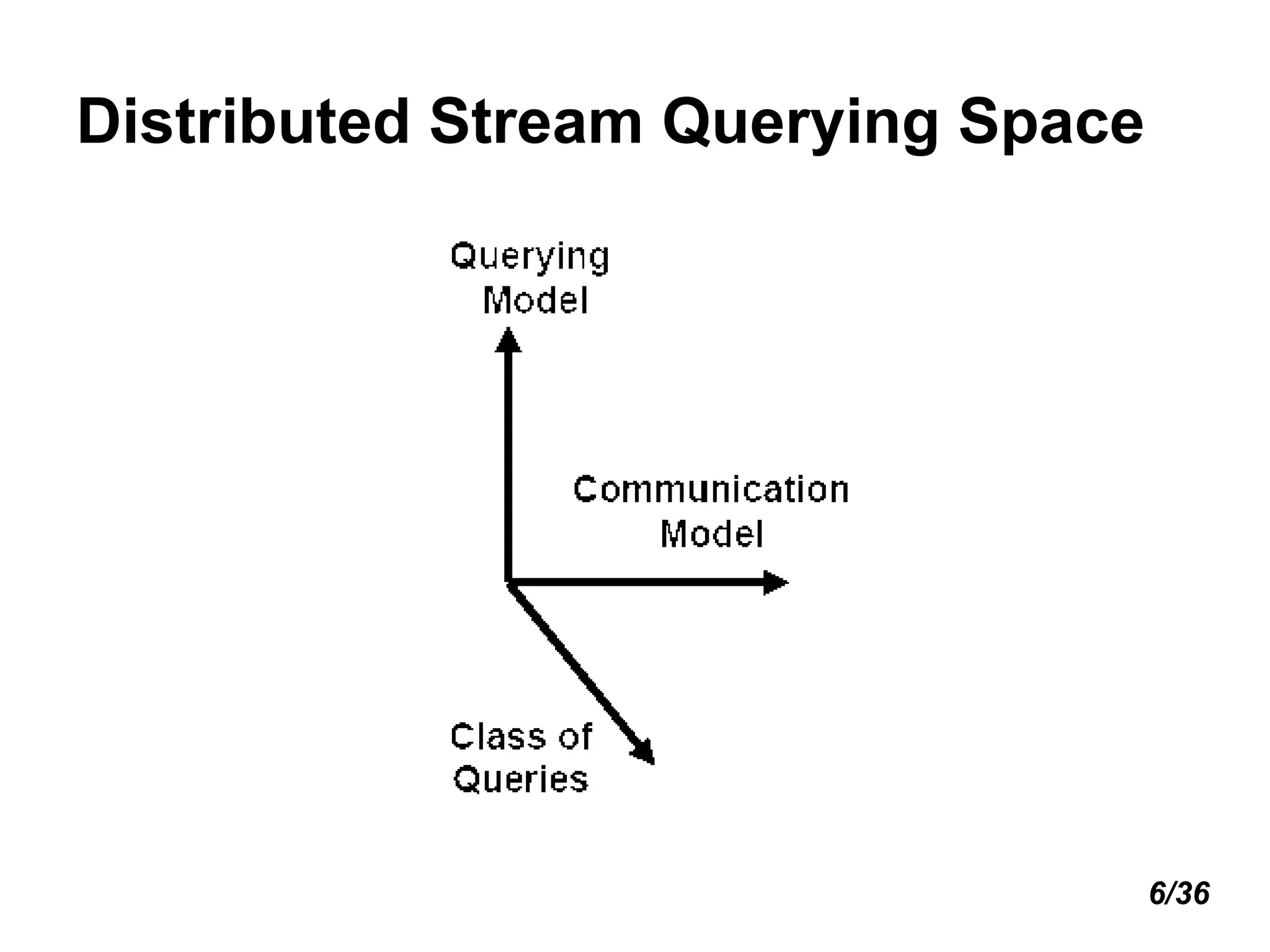


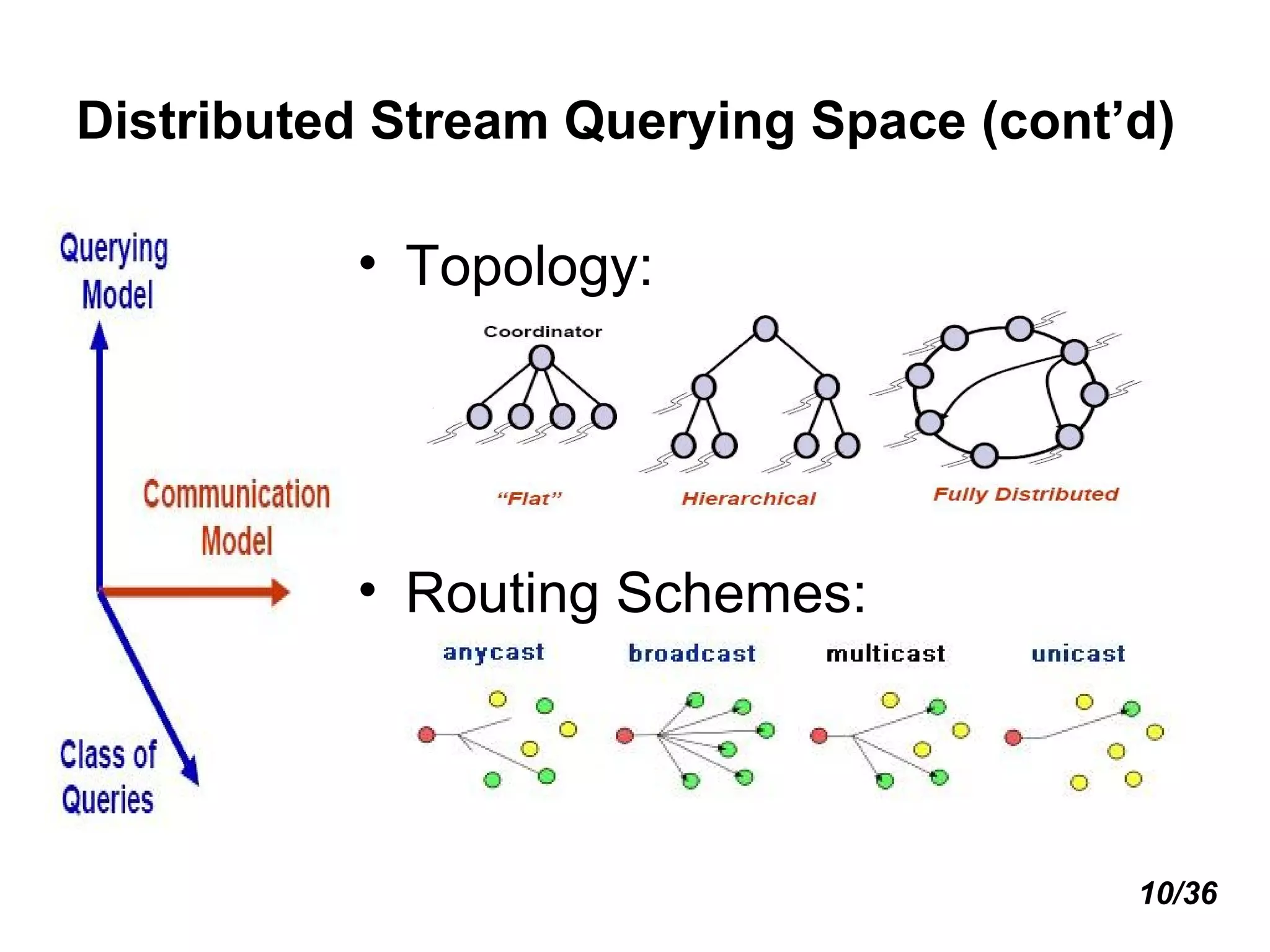
![Distributed Stream Querying Space (cont’d) Simple algebraic vs. holistic aggregates [3] Holistic aggregates need the whole input to compute the query result (no summary suffices) E.g., count distinct , need to remember all distinct items to tell if new item is distinct or not Duplicate-sensitive vs. duplicate-insensitive Duplicate sensitivity indicates whether the result of aggregation evaluator is affected by a duplicated reading or not. E.g., BINARY AND vs SUM Complex queries E.g., distributed joins 9/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-10-2048.jpg)






![Loss (cont’d) The Flajolet-Martin sketch [4] Target: Estimates number of distinct inputs ( count distinct ) Given: A sequence of input x i Steps: Use hash function mapping input items to i with prob 2 -I Pr[ h(x) = 1 ] = 1/2 Pr[ h(x) = 2 ] = 1/4 Pr[ h(x) = 3 ] = 1/8 … etc. Construct an FM bitmap of length log N where N is number of inputs 20/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-21-2048.jpg)
![The Flajolet-Martin sketch (cont’d) For each incoming value x, set FM[h(x)] = 1 The position of the least significant 0 in the bitmap indicates the logarithm of the number of distinct items seen. Accuracy: Taking repetitions with randomly chosen hash functions improves the accuracy Loss (cont’d) 21/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-22-2048.jpg)









![Distributed Data Streams System Overview of “Minos Garofalakis” [2] on the future of DSS Main algorithmic idea: Trade-off communication/ approximation “ Unfortunately, approximate query processing tools are still not widely adopted in current Stream Processing Engines” [5] “ More complex tools for approximate in-network data processing/collection have yet to gain wider acceptance” [5] 32/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-33-2048.jpg)



![Future Work How to make Stream mining (clustering, associations, classification, change detection,…etc. ) ? Can all queries be converted to ODI ? Compressing and Filtering XML Streams [6] Graph-data streams [7] [8] Extend ERD to express streams (ERD stream modeling) A general distributed query language (dist-streamSQL?) Define a language so a query optimizer can find a plan that guarantees good performance, small communication? 36/36](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-37-2048.jpg)
![References [1] Minos Garofalakis, Processing Massive Data Streams, Yahoo Research & UC Berkeley, The VLDB school in Egypt, April 2008. [2] Dr. Minos Garofalakis homepage http:// www.softnet.tuc.gr/~minos / (last visit 25 th May 2009) [3] Graham Cormode, Minos N. Garofalakis, S. Muthukrishnan and Rajeev Rastogi. ACM SIGMOD Conference. Holistic Aggregates in a Networked World Distributed Tracking of Approximate Quantiles. Baltimore, Maryland, USA. 14 th -16 th June, 2005. [4] Graham Cormode, Fundamentals of Analyzing and Mining Data Streams, Workshop on data stream analysis, San Leucio-Italy, March 15 th -16 th , 2007 [5] Quoted from reference 1, slide 185 [6] Giovanni Guardalben, Compressing and Filtering XML Streams, The W3C Workshop on Binary Interchange of XML Information Item Sets, 24 th , 25 th and 26 th September, 2003, Santa Clara, California, USA [7] Jian Zhang , Massive Data Streams in Graph Theory and Computational Geometry, Yale University, New Haven, CT, USA, 2005 [8] Prof. Dr. Joan Feigenbaum ’s publications http://www.cs.yale.edu/homes/jf/Massive-Data-Pubs.html (last visit 25 th May 2009)](https://image.slidesharecdn.com/distributedstreams-091006144408-phpapp01/75/Distributed-Streams-38-2048.jpg)



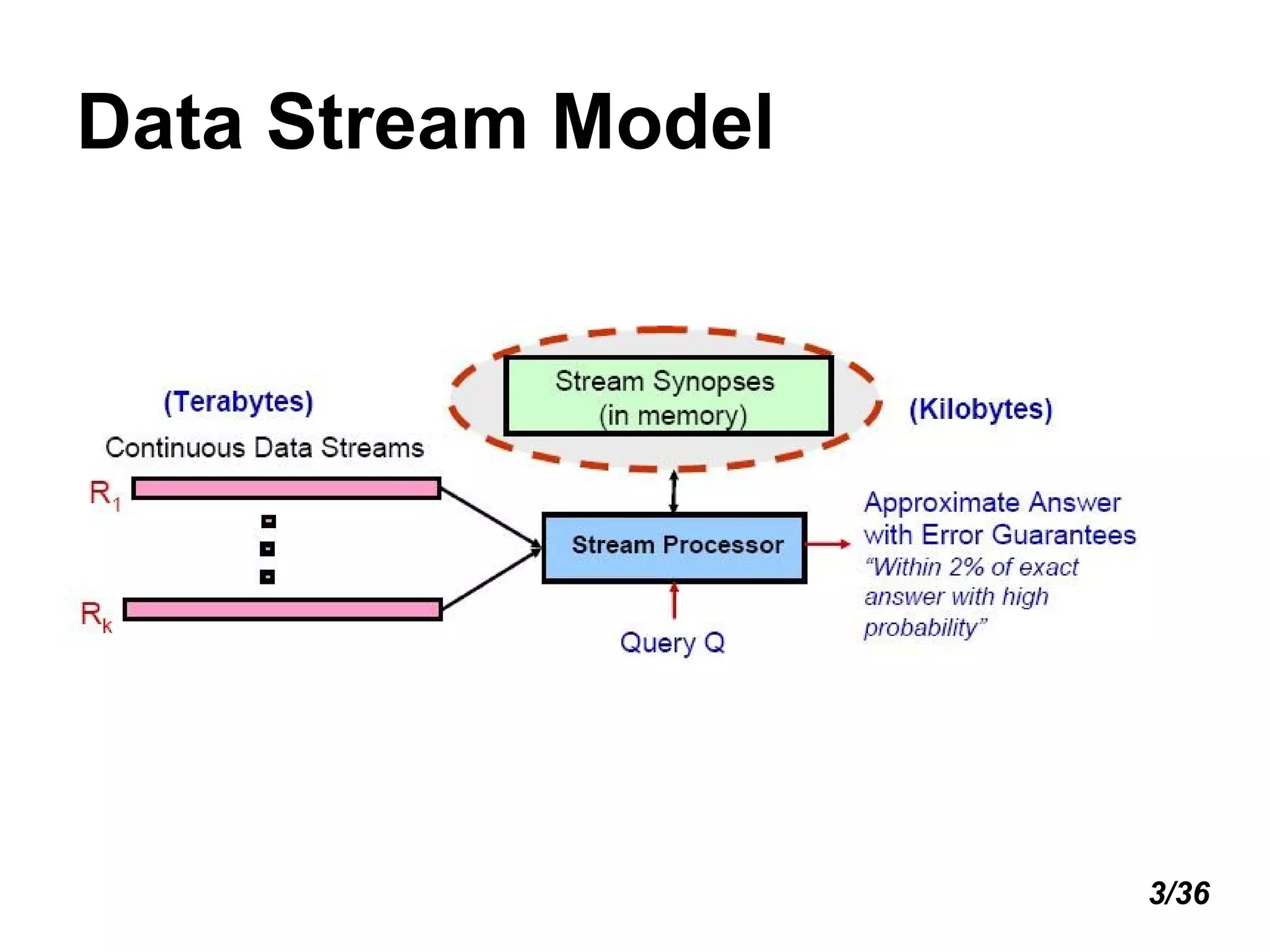
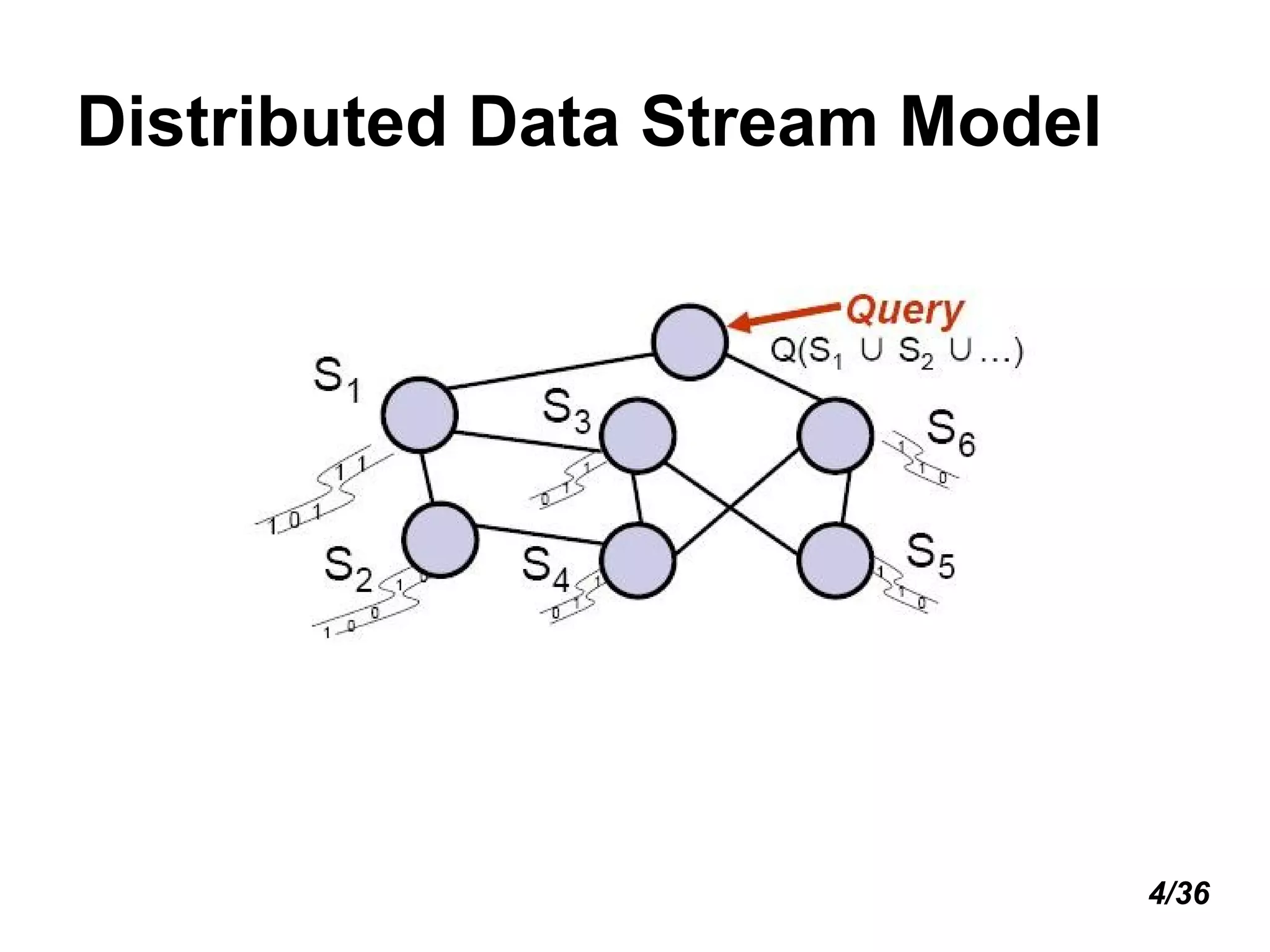
The document introduces distributed stream processing. It discusses maintaining synopses of streams using single-pass, small space and time algorithms. Distributed queries can be one-shot or continuous, requiring approximation to minimize communication. Tree-based aggregation and decentralized gossiping are introduced for in-network processing. Handling message loss and node failures is also important. Future work includes stream mining queries and compressing XML streams.

































































