Download as PDF, PPTX





























![Impossibility result - group membership
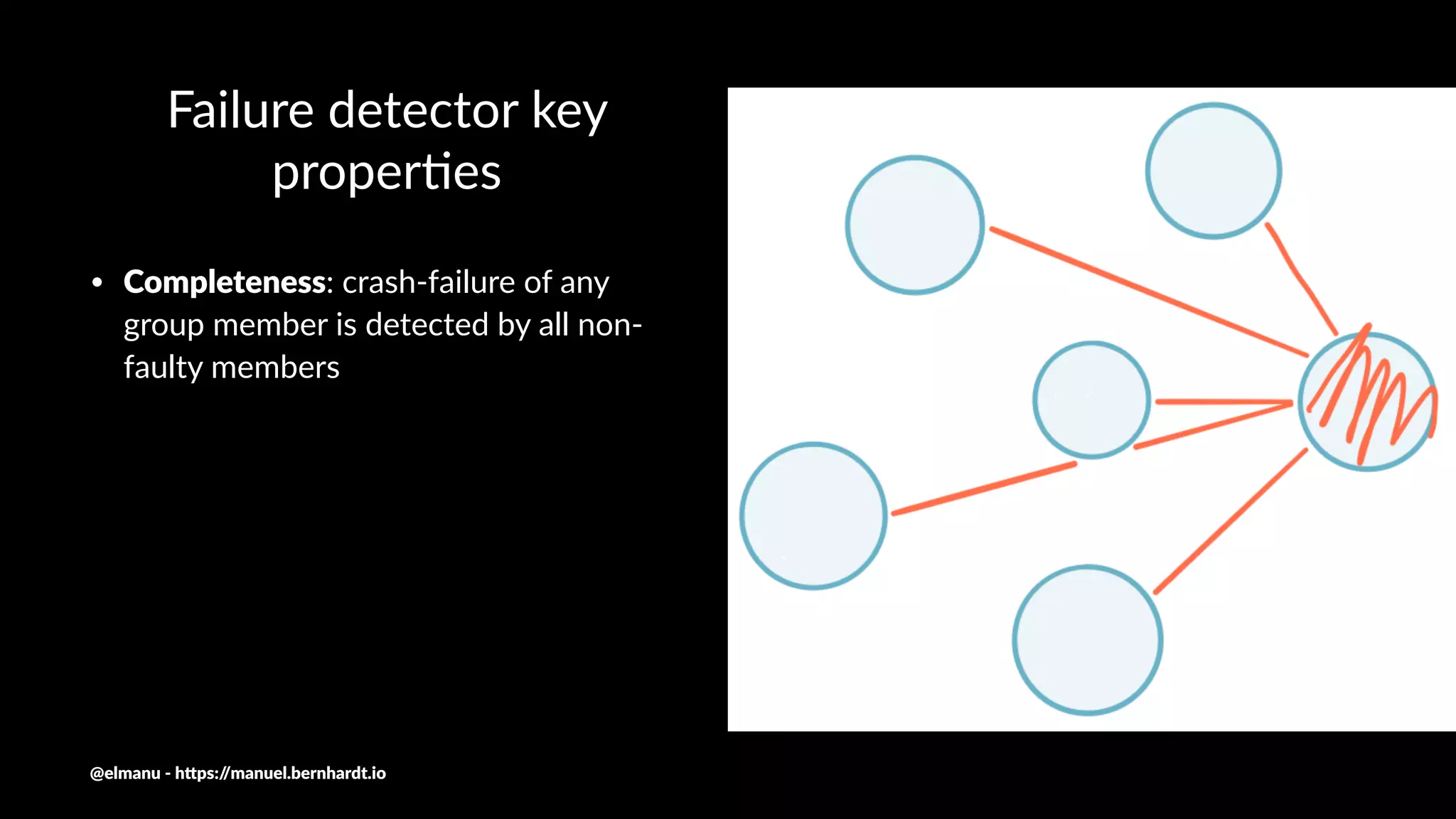
[...] the primary-par//on group membership problem cannot be
solved in asynchronous systems with crash failures, even if one
allows the removal or killing of non-faulty processes that are
erroneously suspected to have crashed 9
9
Chandra et al: On the Impossibility of Group Membership (1996)
@elmanu - h+ps://manuel.bernhardt.io](https://image.slidesharecdn.com/anybodyoutthere-180312123008/75/Is-there-anybody-out-there-42-2048.jpg)




![Reaching consensus: .me
private[cluster] final case class Gossip(
members: immutable.SortedSet[Member],
overview: GossipOverview = GossipOverview(),
version: VectorClock = VectorClock(),
tombstones: Map[UniqueAddress, Gossip.Timestamp] = Map.empty)
@elmanu - h+ps://manuel.bernhardt.io](https://image.slidesharecdn.com/anybodyoutthere-180312123008/75/Is-there-anybody-out-there-47-2048.jpg)




![Reaching consensus: conven/ons
• reaching a decision by not transmi2ng any informa4on
• example: Akka Cluster leader designa4on
/**
* INTERNAL API
* Orders the members by their address except that members with status
* Joining, Exiting and Down are ordered last (in that order).
*/
private[cluster] val leaderStatusOrdering: Ordering[Member] = ...
@elmanu - h+ps://manuel.bernhardt.io](https://image.slidesharecdn.com/anybodyoutthere-180312123008/75/Is-there-anybody-out-there-52-2048.jpg)


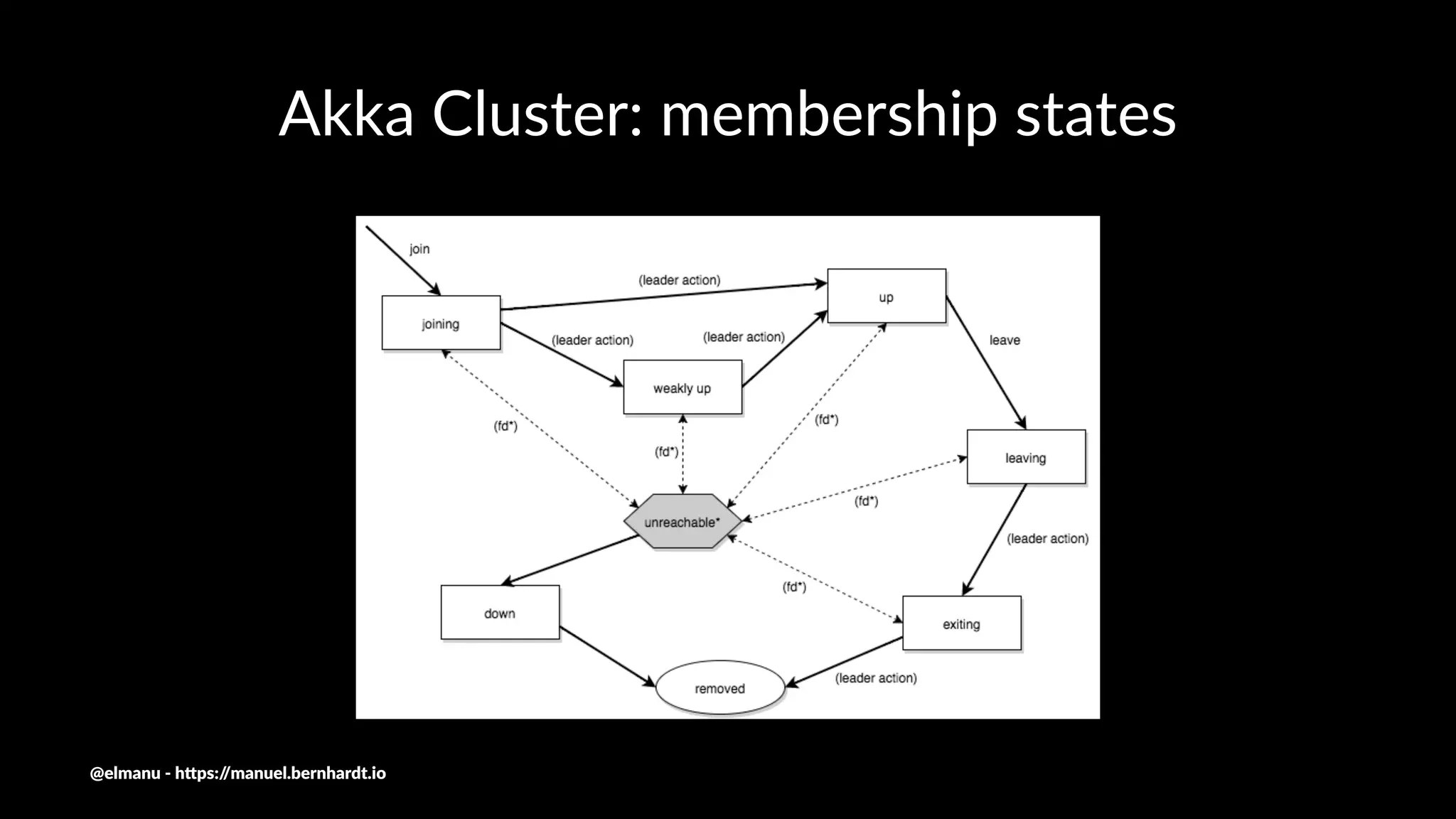
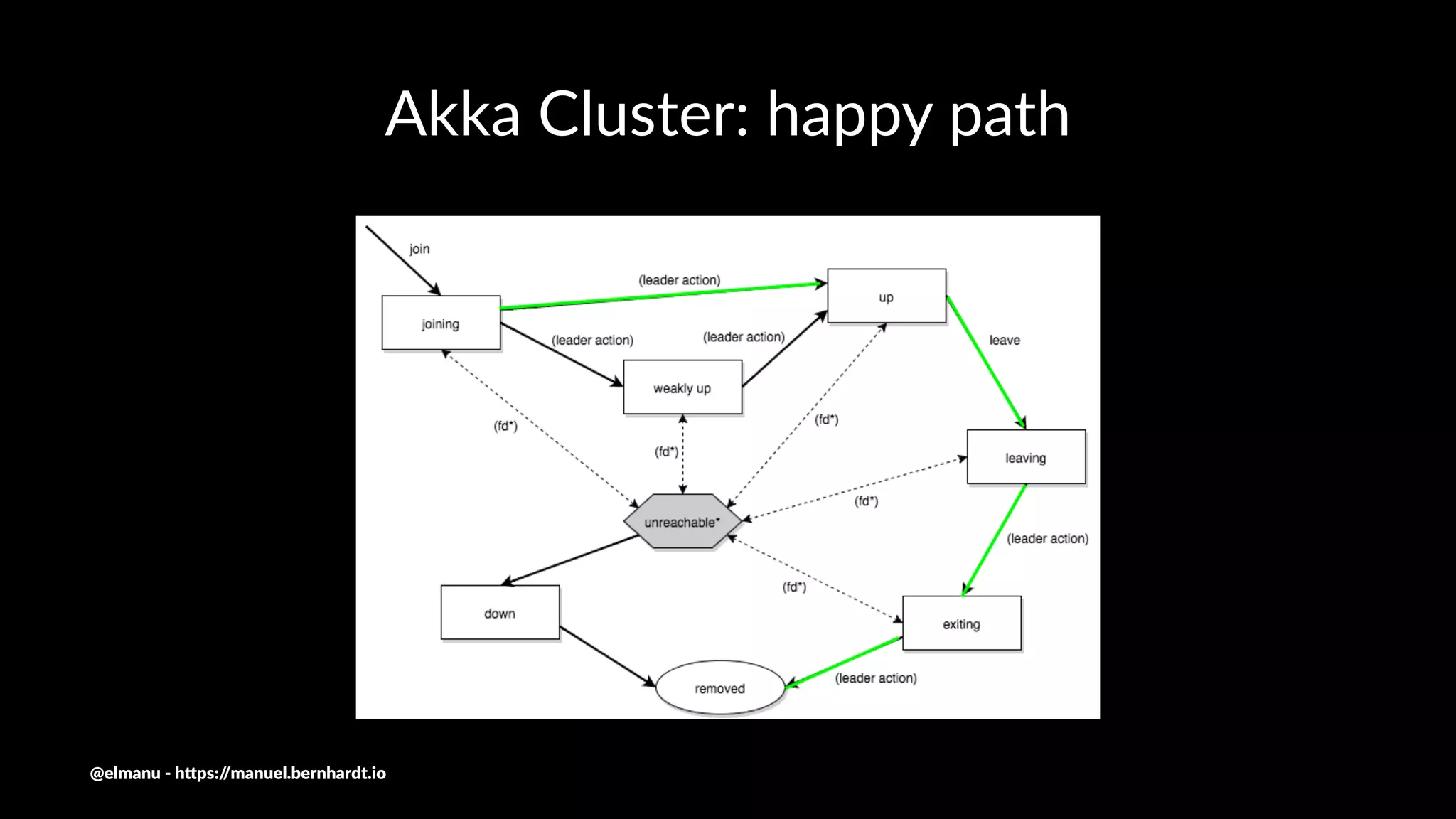
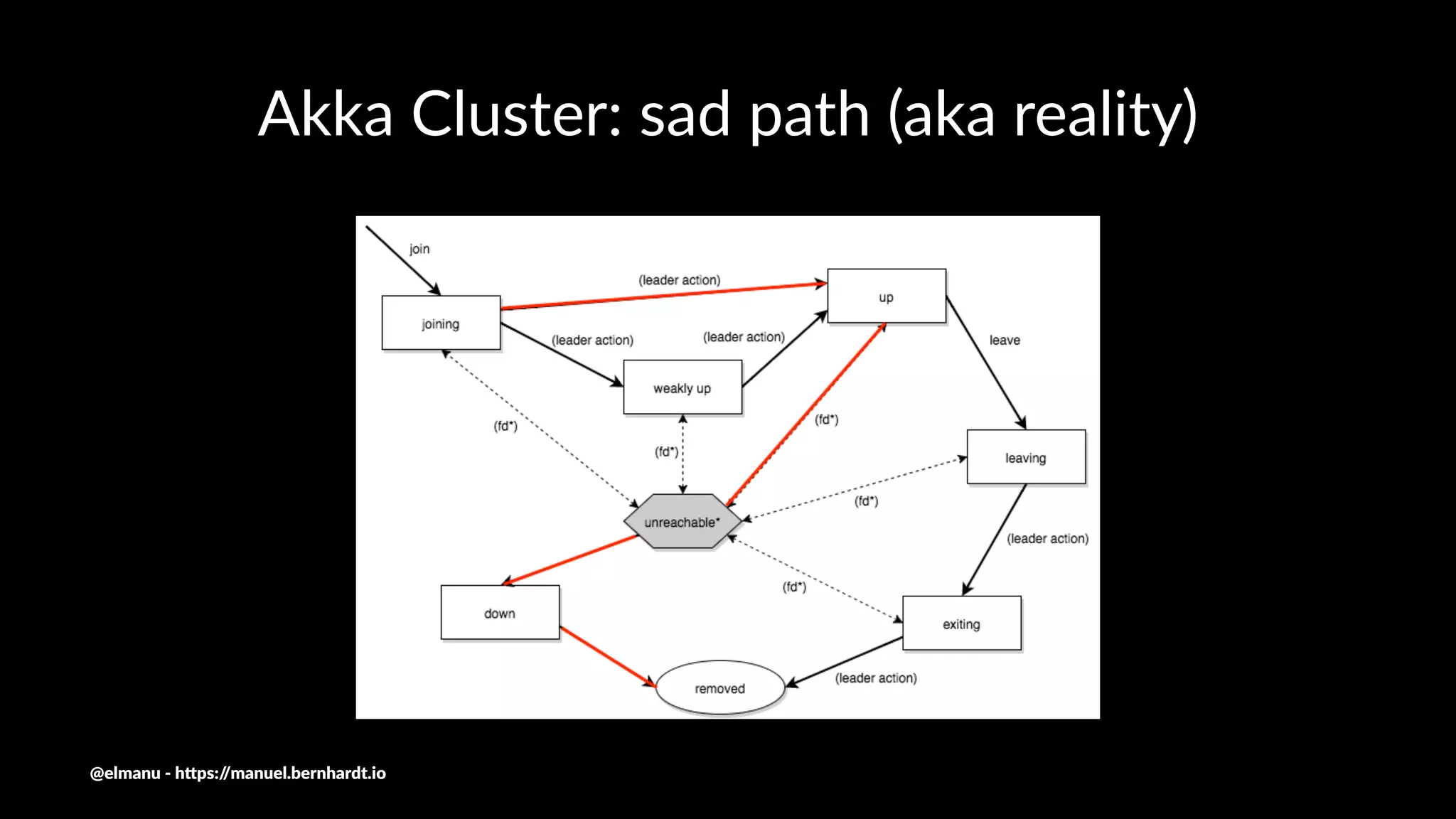











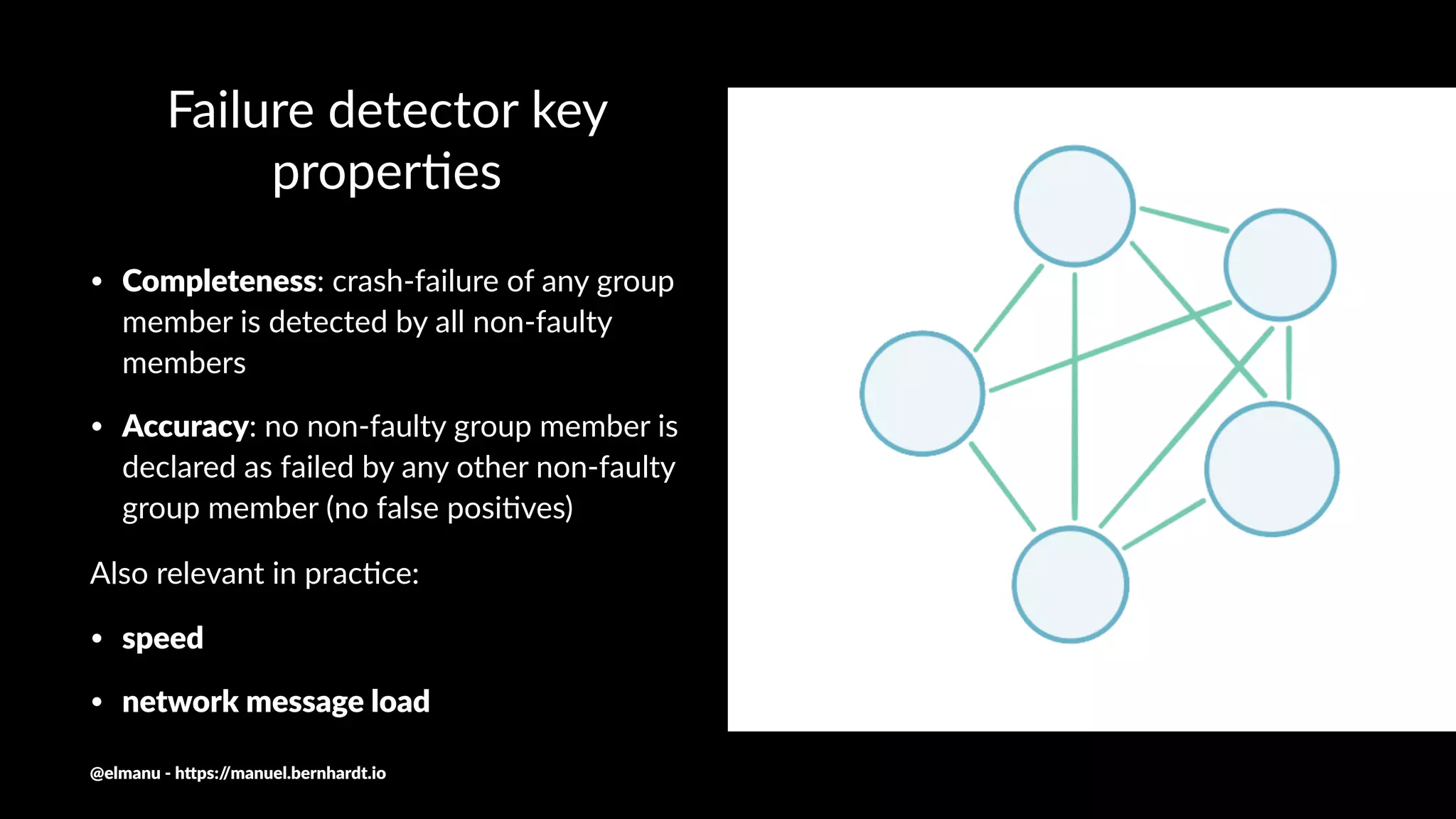
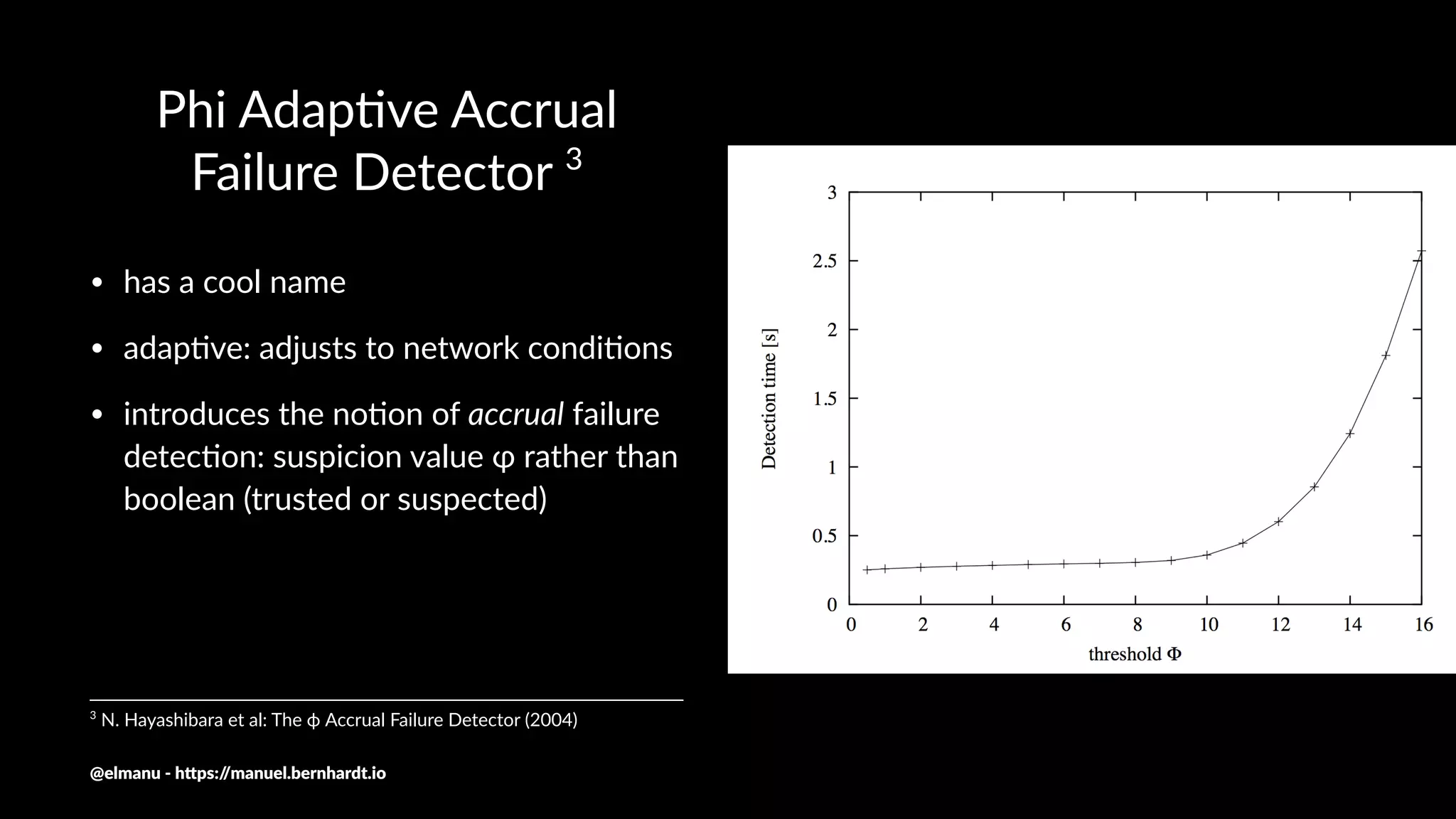
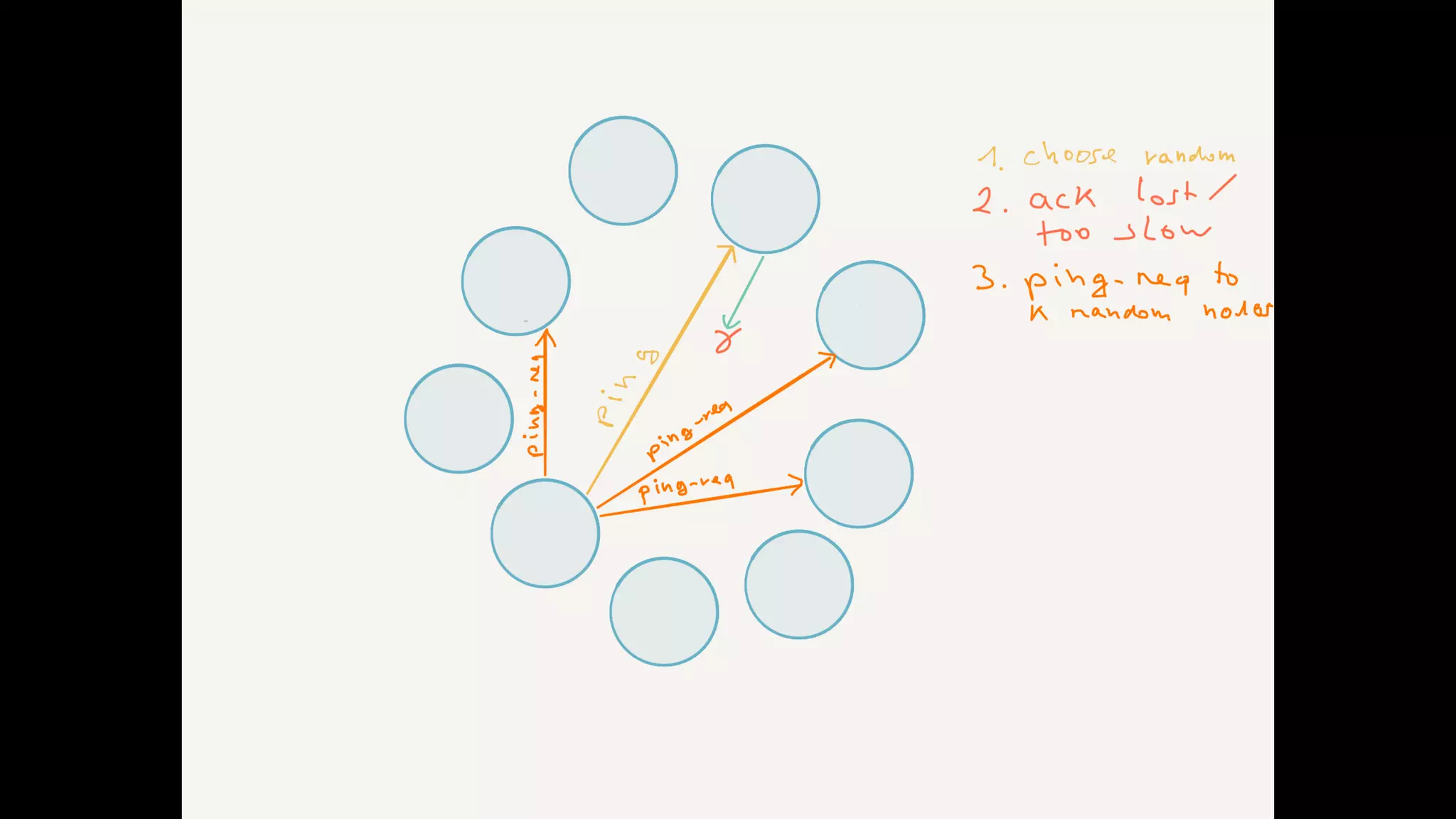
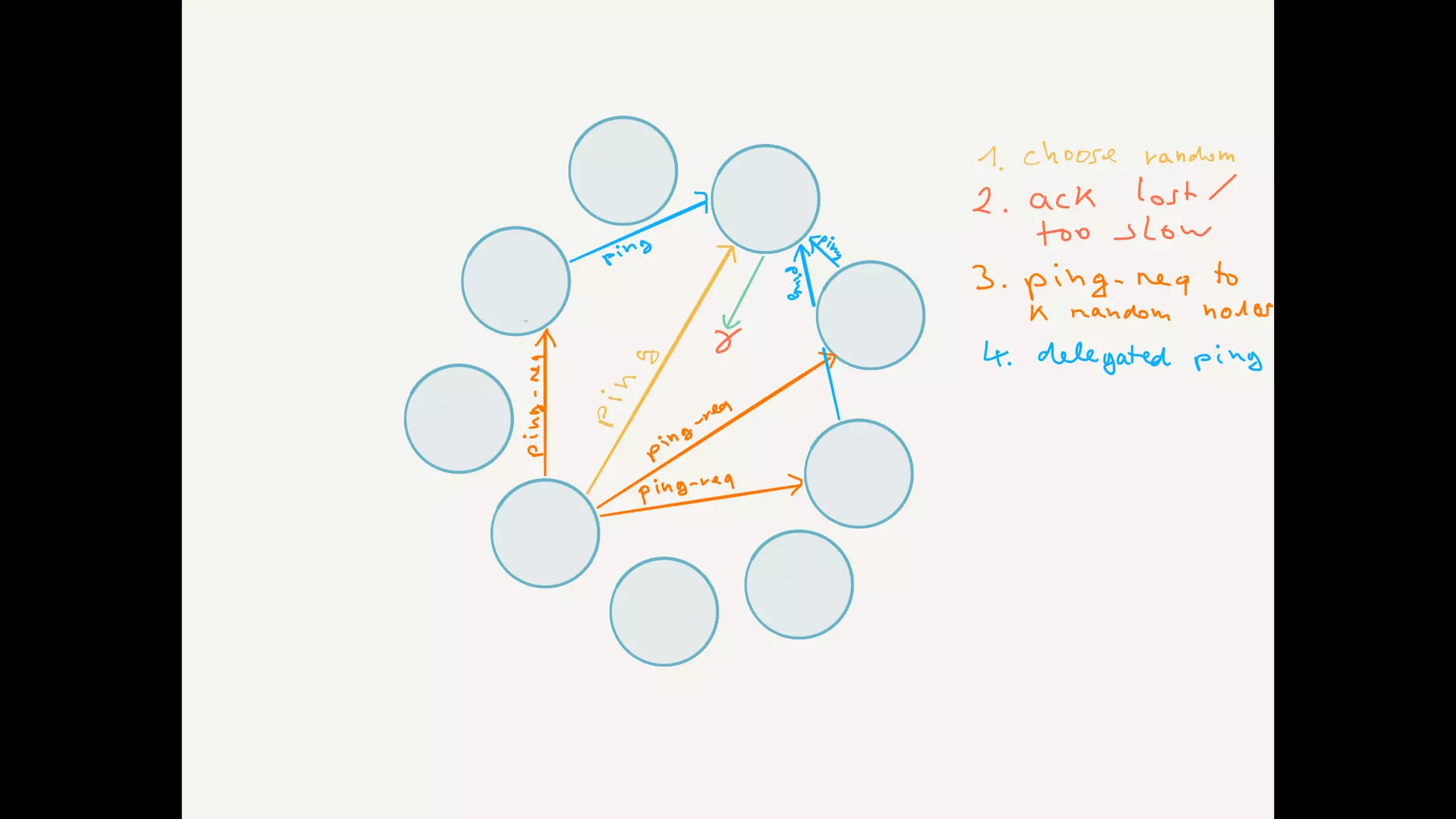
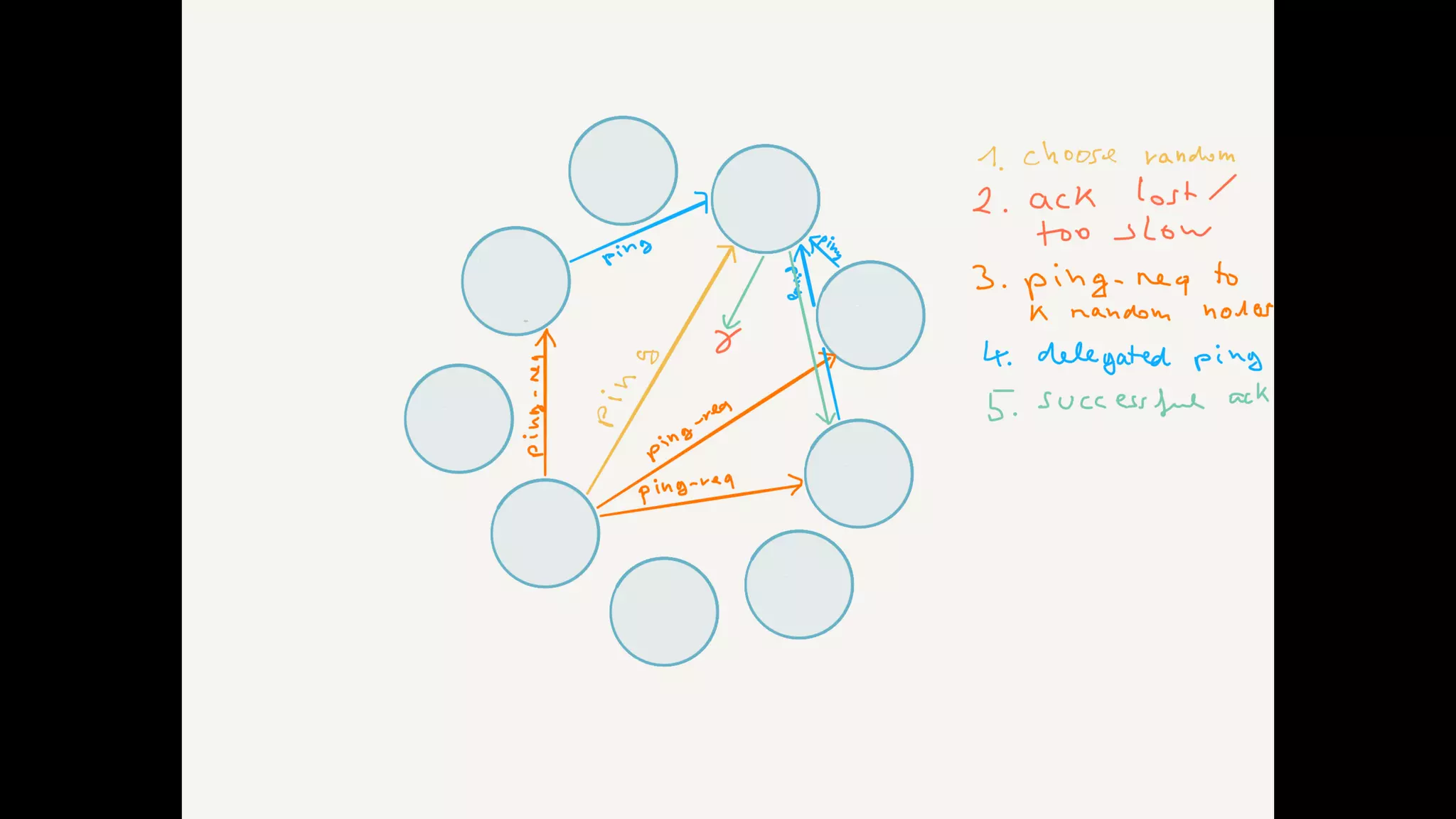
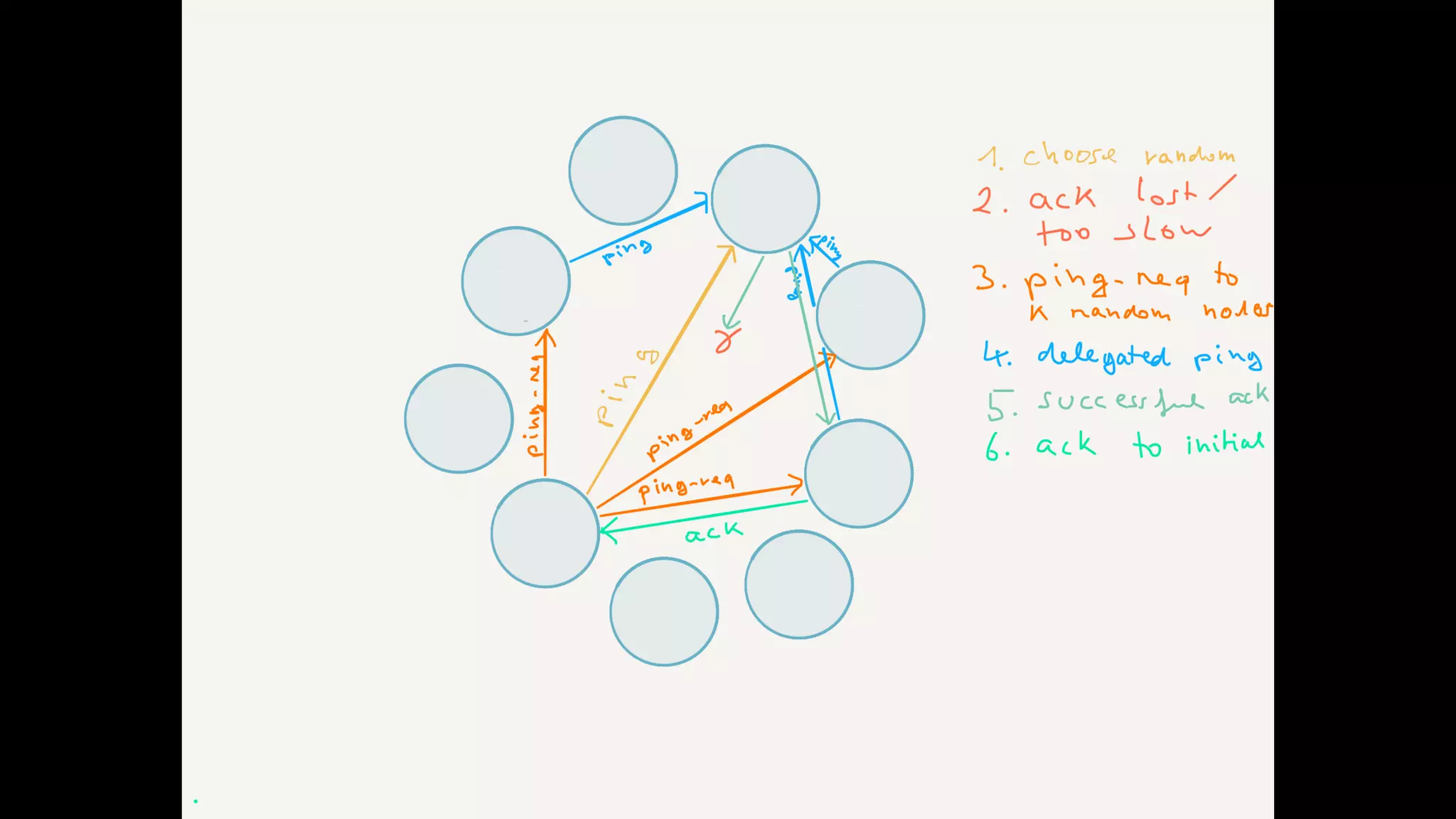
The document discusses essential components and challenges related to building reactive systems, specifically focusing on cluster management issues such as discovery, fault detection, and load balancing. It highlights various failure detector strategies and the limitations of achieving both completeness and accuracy in failure detection within distributed systems. The text also touches on the importance of consensus protocols and the role they play in ensuring reliability in distributed computing environments.































































