Downloaded 47 times






















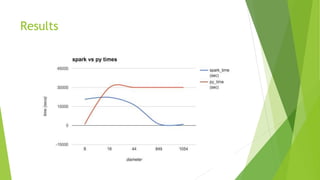



The document discusses the challenges and solutions related to distributed k-betweenness centrality computation in complex networks using technologies like Spark and GraphX. It highlights the difficulties of betweenness computation on large graphs, especially regarding node information access and graph size limitations. Key results indicate that while the implementation performs well on large diameter graphs, it struggles with small diameter graphs and requires careful tuning.








































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















