Downloaded 23 times


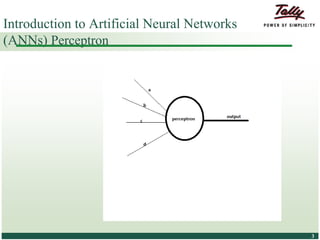
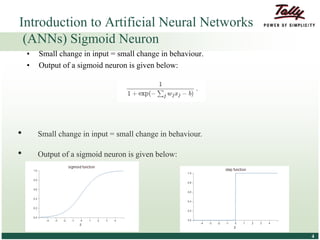
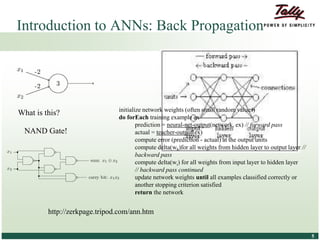
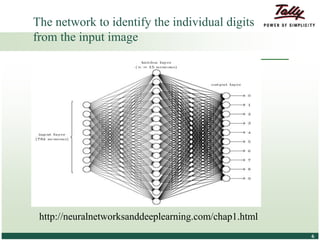
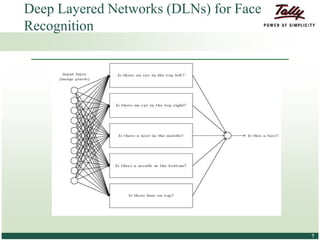
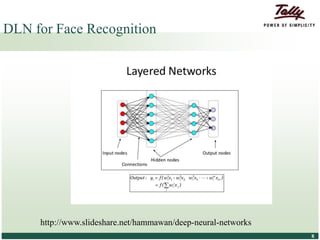
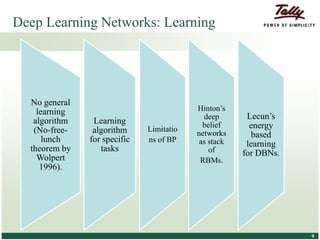


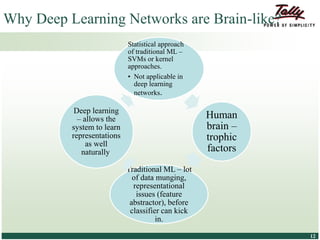




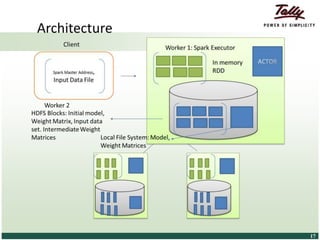




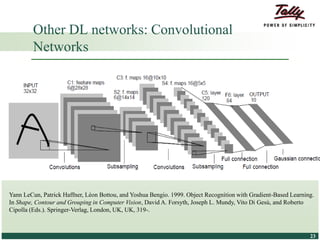




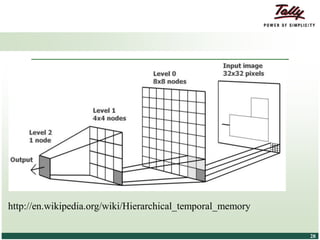


The document discusses the principles and applications of distributed deep learning networks (DLNs) in various fields including face recognition, speech analysis, and natural language processing. It highlights the architectures of artificial neural networks (ANNs), such as deep belief networks and autoencoders, along with their success stories and challenges. The potential for DLNs to enhance business data analytics within Tally solutions is also explored, indicating ongoing advancements in distributed deep learning frameworks.


























































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)









