




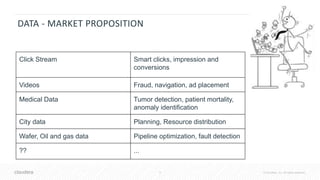
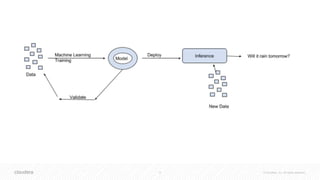

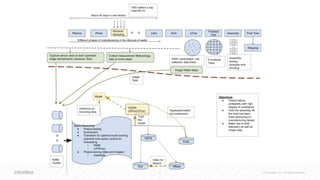
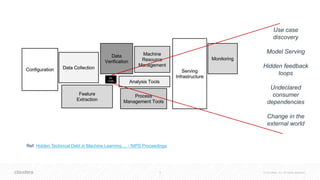
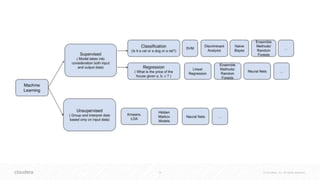

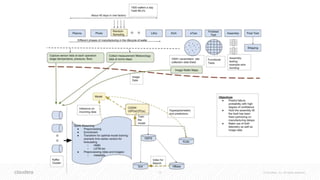

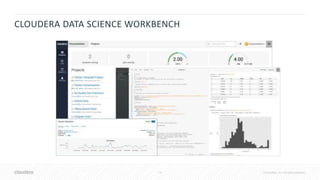
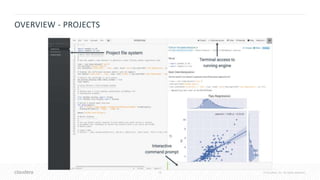
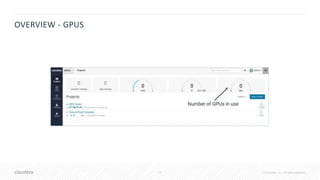
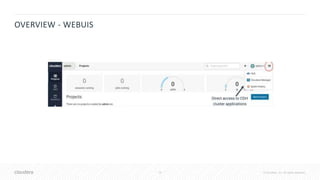
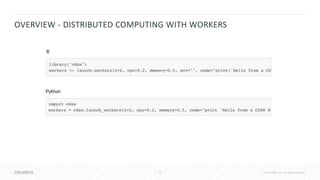
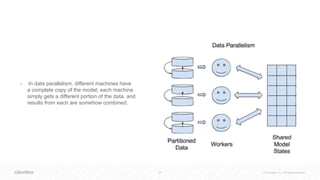




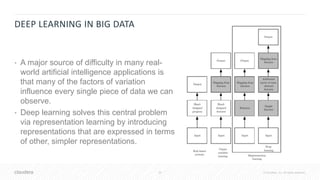





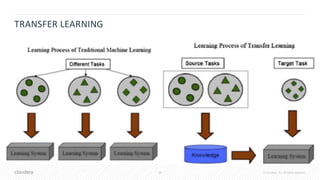
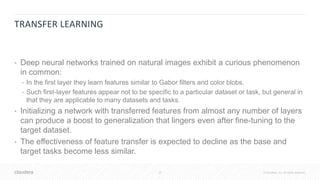



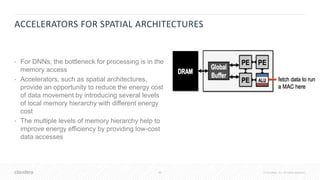
![41 © Cloudera, Inc. All rights reserved.
• Neurons and Synapses
• Computed weighted sum for
each layer
• Compute the gradient of the loss
relative to the filter inputs
• Compute the gradient of the loss
relative to the weights
M. Mohammadi, A. Al-Fuqaha, S. Sorour, and M. Guizani, “Deep Learning for IoT Big Data and Streaming Analytics: A Survey,” arXiv preprint arXiv:1712.04301v1 [cs.NI], 2017.
DNN](https://image.slidesharecdn.com/sparkanddeeplearningframeworksatscale7-180725170216/85/Spark-and-Deep-Learning-Frameworks-at-Scale-7-19-18-41-320.jpg)



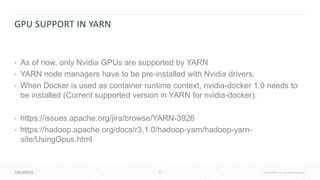
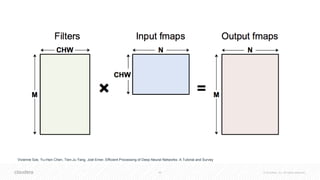
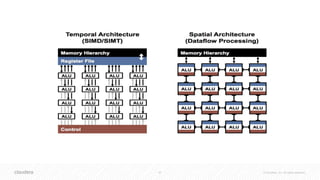

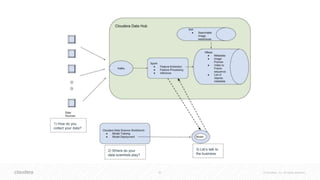


The document discusses the integration of Apache Spark and deep learning frameworks for machine learning at scale, emphasizing the importance of data architecture, use case discovery, and intelligent infrastructure. It highlights challenges in machine learning, including data underutilization and inefficiencies in processing, and presents various applications in fields such as bioinformatics and IoT. The document also explores technical considerations for deep learning, including model training strategies and hardware requirements for optimal performance.















































































