Download as PDF, PPTX


![Traditional & novel forms of research data: the case of social sciences
02/10/19 7Stefan Dietze
Traditional social science research data: survey & census
data, microdata, lab studies etc (lack of scale, dynamics)
Social science vision: substituting & complementing
traditional research data through data mined from the Web
Example: investigations into misinformation and opinion
forming (e.g. [Vousoughi et al. 2018])
Aims usually at investigating insights by also dealing with
methodological/computational challenges
Insights, mostly (computational) social sciences, e.g.
o Spreading of claims and misinformation
o Effect of biased and fake news on public opinions
o Reinforcement of biases and echo chambers
Methods, mostly in computer science, e.g. for
o Crawling, harvesting, scraping of data
o Extraction of structured knowledge
(entities, sentiments, stances, claims, etc)
o Claim/fact detection and verification („fake news
detection“), e.g. CLEF 2018 Fact Checking Lab
o Stance detection, e.g. Fake News Challenge (FNC)](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-7-2048.jpg)

![02/10/19 10Stefan Dietze
Research dataset markup on the Web
In Common Crawl 2017 (3.2 bn pages):
o 14.1 M statements & 3.4 M instances
related to „s:Dataset“
o Spread across 200 K pages from 2878 PLDs
(top 10% of PLDs provide 95% of data)
Studies of scholarly articles and other types
[SAVESD16, WWW2017]: majority of major
publishers, data hosting sites, data registries,
libraries, research organisations respresented
power law distribution of dataset metadata across PLDs
Challenges
o Errors. Factual errors, annotation errors (see
also [Meusel et al, ESWC2015])
o Ambiguity & coreferences. e.g. 18.000 entity
descriptions of “iPhone 6” in Common Crawl
2016 & ambiguous literals (e.g. „Apple“>)
o Redundancies & conflicts vast amounts of
equivalent or conflicting statements](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-10-2048.jpg)
![ 0. Noise: data cleansing (node URIs, deduplication etc)
1.a) Scale: Blocking through BM25 entity retrieval on markup index
1.b) Relevance: supervised coreference resolution
2.) Quality & redundancy: data fusion through supervised fact classification (SVM, knn, RF, LR, NB), diverse
feature set (authority, relevance etc), considering source- (eg PageRank), entity-, & fact-level
KnowMore: data fusion on markup
02/10/19 11
1. Blocking &
coreference
resolution
2. Fusion / Fact selection
New Queries
WorldBank, type:(Organization)
Washington, type:(City)
David Malpass, type:(Person)
(supervised)
Entity Description
name
“WorldBank Commodity
Prices 2019”
distribution Worldbank (node)
releaseDate 26.04.2019
keywords „crude”, “prizes”, “market”
encodingFormat text/CSV
Query
WorldBank Commodity,
Prices 2019, type:(Dataset)
Candidate Facts
node1 name WB Commodity
node1 distribution node_xy
node1 creator Worldbank
node1 dateReleased 26 April 2019
node2 creator World Bank
node2 encodingFormat text/CSV
node3 dateCreated 26 April 2007
node4 keywords “crude”
Web page
markup
Web crawl
(Common Crawl,
44 bn facts)
approx. 125.000 facts for query [ s:Product, „iPhone6“ ]
Stefan Dietze
Yu, R., [..], Dietze, S., KnowMore-Knowledge Base
Augmentation with Structured Web Markup, Semantic
Web Journal 2019 (SWJ2019)
Tempelmeier, N., Demidova, S., Dietze, S., Inferring
Missing Categorical Information in Noisy and Sparse
Web Markup, The Web Conf. 2018 (WWW2018)](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-11-2048.jpg)
![ 0. Noise: data cleansing (node URIs, deduplication etc)
1.a) Scale: Blocking through BM25 entity retrieval on markup index
1.b) Relevance: supervised coreference resolution
2.) Quality & redundancy: data fusion through supervised fact classification (SVM, knn, RF, LR, NB), diverse
feature set (authority, relevance etc), considering source- (eg PageRank), entity-, & fact-level
KnowMore: data fusion on markup
02/10/19 12
1. Blocking &
coreference
resolution
2. Fusion / Fact selection
New Queries
WorldBank, type:(Organization)
Washington, type:(City)
David Malpass, type:(Person)
(supervised)
Entity Description
name
“WorldBank Commodity
Prices 2019”
distribution Worldbank (node)
releaseDate 26.04.2019
keywords „crude”, “prizes”, “market”
encodingFormat text/CSV
Query
WorldBank Commodity,
Prices 2019, type:(Dataset)
Candidate Facts
node1 name WB Commodity
node1 distribution node_xy
node1 creator Worldbank
node1 dateReleased 26 April 2019
node2 creator World Bank
node2 encodingFormat text/CSV
node3 dateCreated 26 April 2007
node4 keywords “crude”
Web page
markup
Web crawl
(Common Crawl,
44 bn facts)
approx. 125.000 facts for query [ s:Product, „iPhone6“ ]
Stefan Dietze
Yu, R., [..], Dietze, S., KnowMore-Knowledge Base
Augmentation with Structured Web Markup, Semantic
Web Journal 2019 (SWJ2019)
Tempelmeier, N., Demidova, S., Dietze, S., Inferring
Missing Categorical Information in Noisy and Sparse
Web Markup, The Web Conf. 2018 (WWW2018)
Fusion performance
Experiments on books, movies, products (ongoing: datasets)
Baselines: BM25, CBFS [ESWC2015], PreRecCorr [Pochampally
et. al., ACM SIGMOD 2014], strong variance across types
Knowledge Graph Augmentation
On average 60% - 70% of all facts new (across DBpedia,
Wikidata, Freebase)
Additional experiments on learning new categorical features
(e.g. product categories or movie genres) [WWW2018]](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-12-2048.jpg)

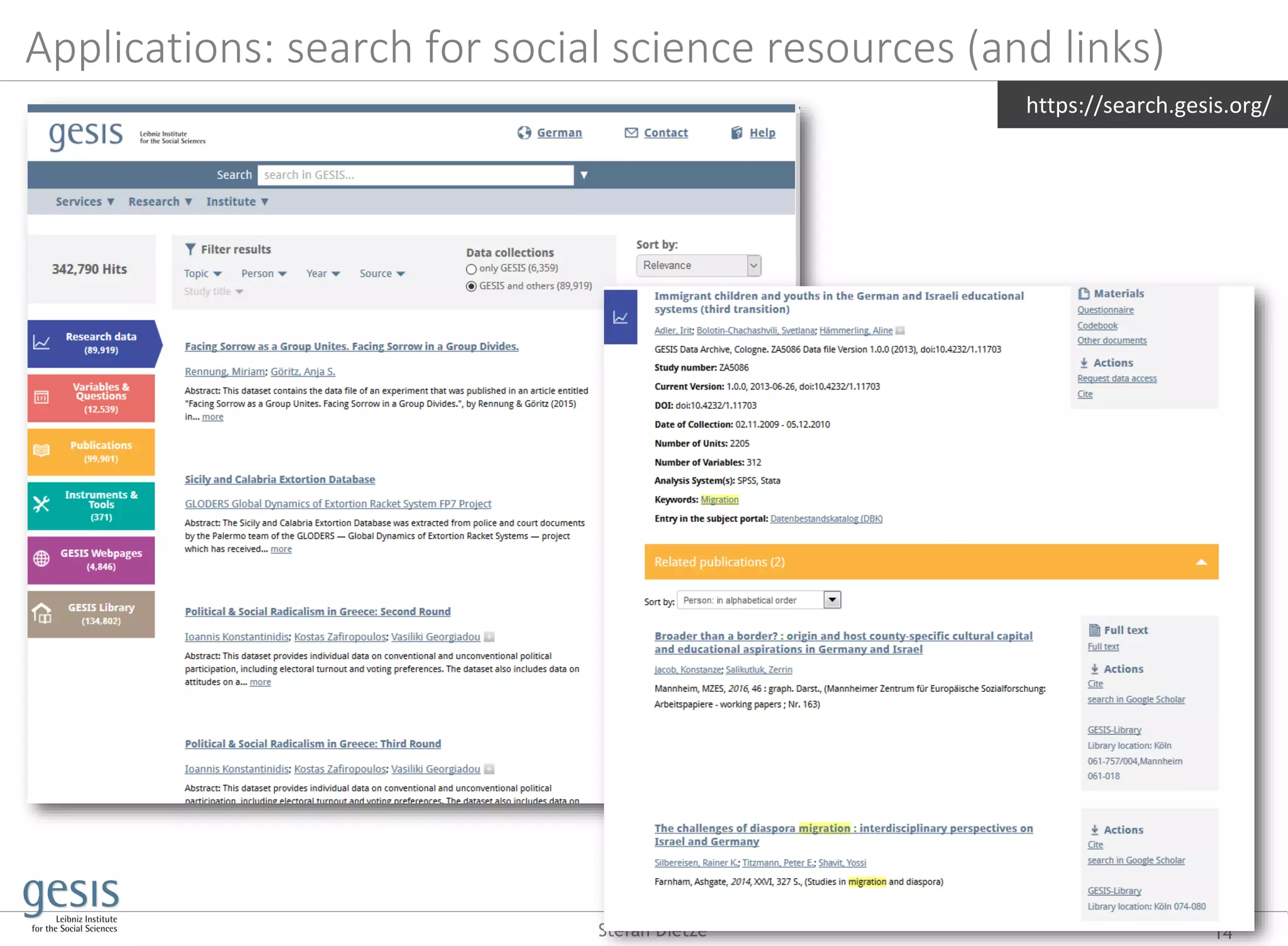
![Disambiguation of dataset citations Otto, W. et al., Knowledge Extraction from scholarly
publications – the GESIS contribution to the Rich Context
Competition, to appear, Sage Publishing, 2020
15Stefan Dietze
All these issues are addressed in the current report,
which is based on analysis of data obtained in the
National Comorbidity Survey (NCS) (15). The NCS is
a nationally representative survey of the US household
population that includes retrospective reports about the
ages at onset and lifetime occurrences of suicidal
ideation, plans, and attempts along with information
about the occurrences of mental disorders, substance
use, substance abuse, and substance dependence.
National Comorbidity Survey (NCS) NCS
Challenges
Ambiguous (incomplete) citations
Lack of high-quality and representative training
data (usually: weak labels, domain bias)
Approaches & results
Prior work: supervised pattern induction
[Boland et al, TPDL2012]
Current approach:
o neural NER based on spaCy (CRF-based
approach for research method detection)
o Training (testing) on 12.000 (3.000) paragraphs
(distribution of negative/positive differs,
training batch size=25, dropout=0.4)
o Results approx. P = .50, R= .90 (weakly labelled
test data)
o On small set of manually labelled test data:
P= .52; R= .21)](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-15-2048.jpg)
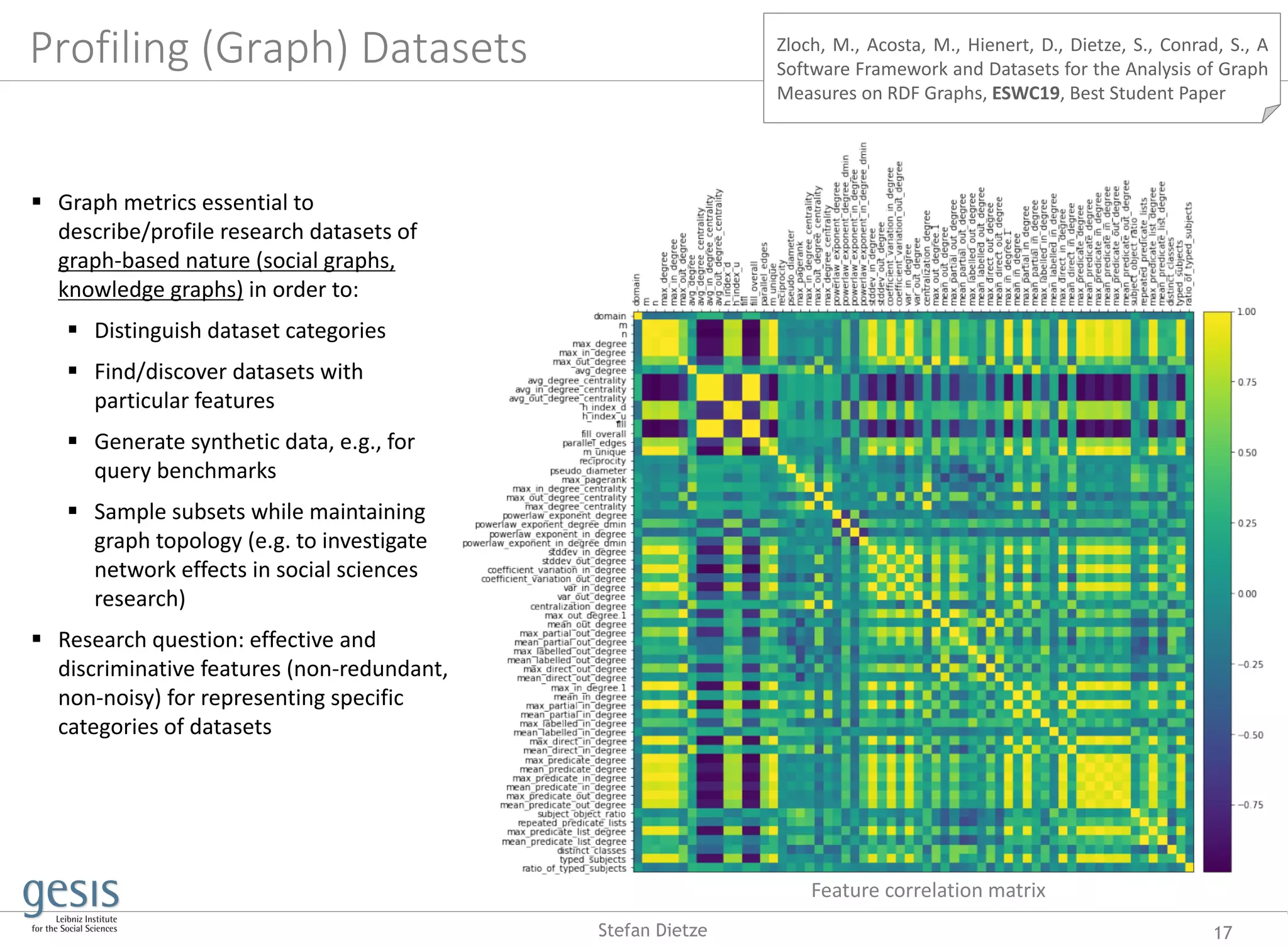
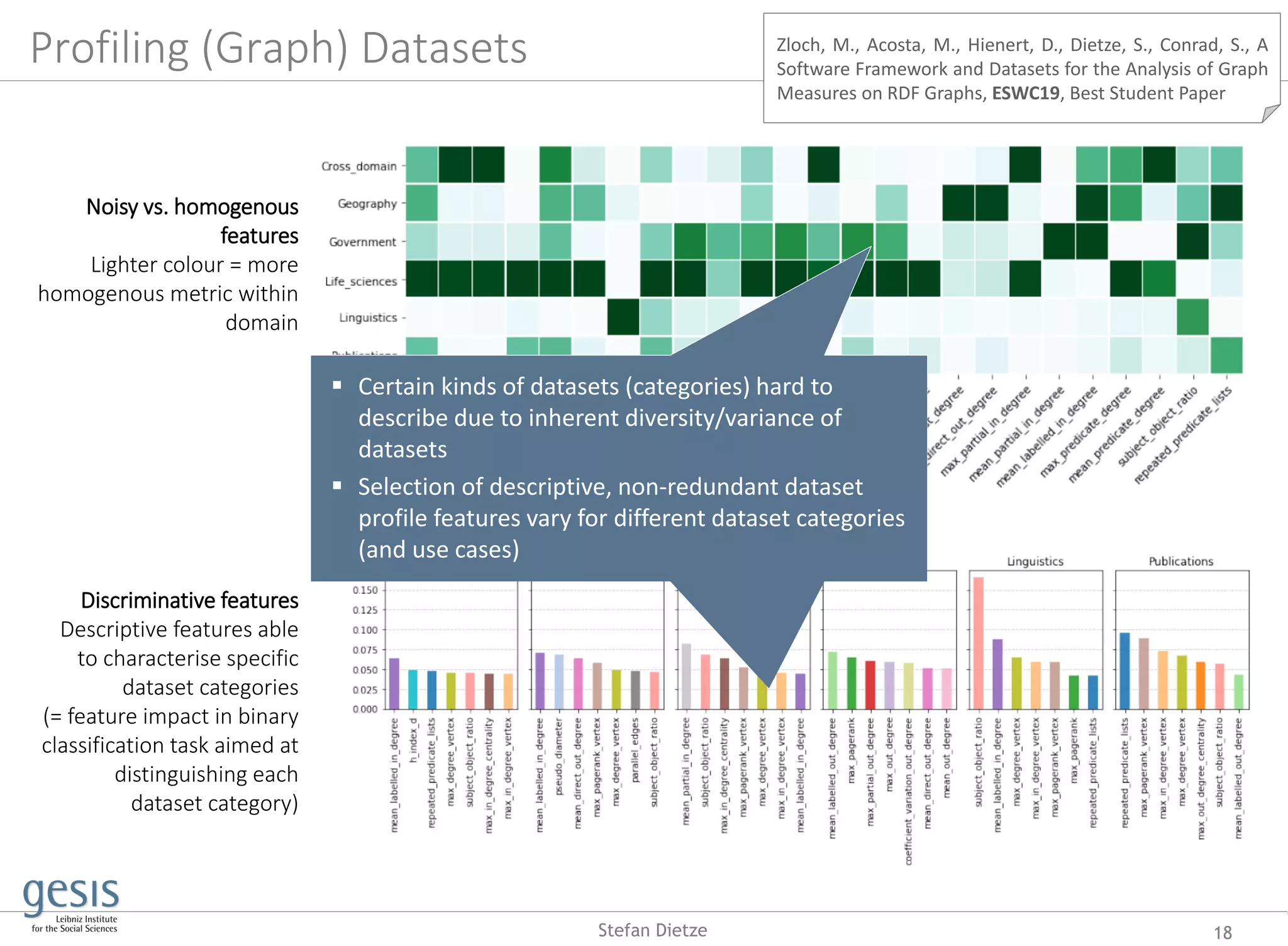
![Profiling datasets
for dataset search
16Stefan Dietze
Dataset metadata is crucial for search,
discovery, reuse
But: dataset metadata is sparse,
incomplete, noisy, costly
Profiling datasets = generating dataset
metadata from actual data(set) at
hand
Various profiling dimensions
depending on use case (e.g. statistical
features, dynamics, topics), cf.
[SWJ18]
Works on topic profiling [ESWC14] and
profiling of graph features [ESWC19]
Ben Ellefi, M., Bellahsene, Z., Breslin, J., Demidova, E., Dietze, S., Szymanski, J.,
Todorov, K., RDF Dataset Profiling – a Survey of Features, Methods,
Vocabularies and Applications, Semantic Web Journal, IOS Press 2018
Fetahu, B., Dietze, S., Nunes, B. P., Casanova, M. A., Nejdl, W., A Scalable
Approach for Efficiently Generating Structured Dataset Topic Profiles,
ESWC2014](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-16-2048.jpg)
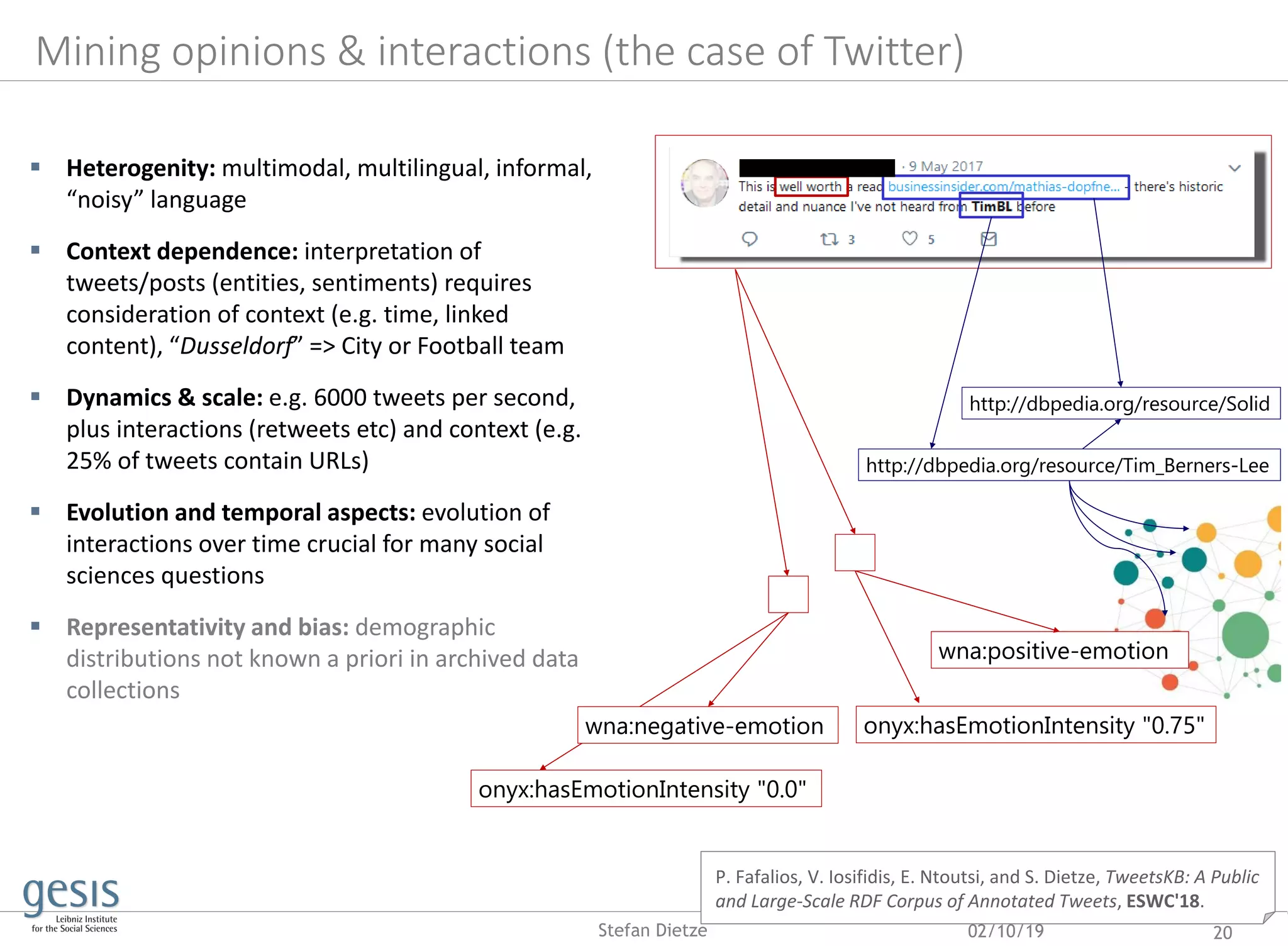
![02/10/19 21Stefan Dietze
P. Fafalios, V. Iosifidis, E. Ntoutsi, and S. Dietze, TweetsKB: A Public
and Large-Scale RDF Corpus of Annotated Tweets, ESWC'18.
TweetsKB: a knowledge graph of Web mined “opinions”
https://data.gesis.org/tweetskb/
Harvesting & archiving of 9 Bn tweets over 6 years
(permanent collection from Twitter 1% sample since
2013)
Information extraction pipeline to build a KG of entities,
interactions & sentiments
(distributed batch processing via Hadoop Map/Reduce)
o Entity linking with knowledge graph/DBpedia
(Yahoo‘s FEL [Blanco et al. 2015])
(“president”/“potus”/”trump” =>
dbp:DonaldTrump), to disambiguate text and use
background knowledge (eg US politicians?
Republicans?), high precision (.85), low recall (.39)
o Sentiment analysis/annotation using SentiStrength
[Thelwall et al., 2017], F1 approx. .80
o Extraction of metadata and lifting into established
schemas (SIOC, schema.org), publication using W3C
standards (RDF/SPARQL)](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-21-2048.jpg)
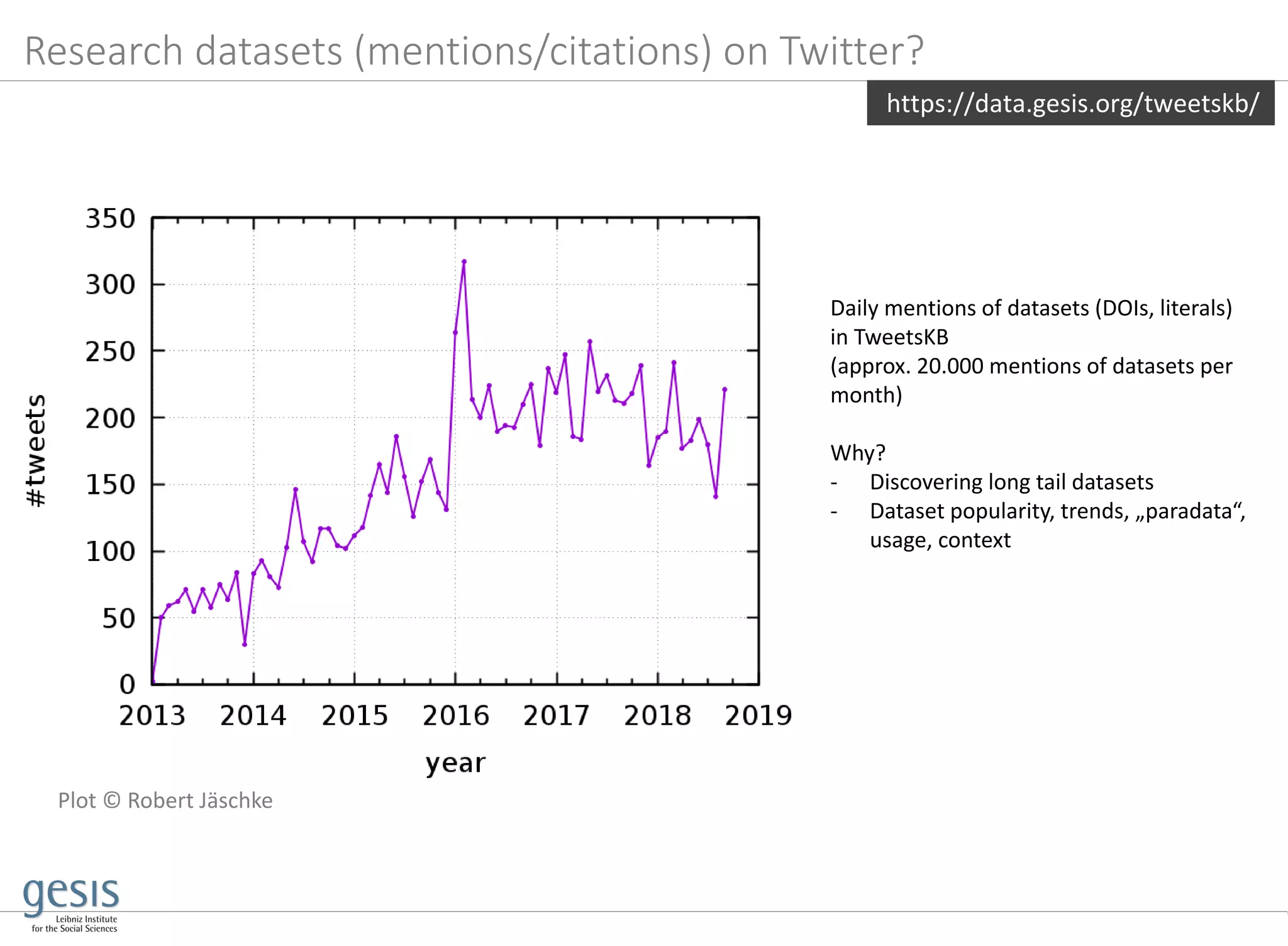
![02/10/19 22Stefan Dietze
P. Fafalios, V. Iosifidis, E. Ntoutsi, and S. Dietze, TweetsKB: A Public
and Large-Scale RDF Corpus of Annotated Tweets, ESWC'18.
Harvesting & archiving of 9 Bn tweets over 5 years
(permanent collection from Twitter 1% sample since
2013)
Information extraction pipeline (distributed via Hadoop
Map/Reduce)
o Entity linking with knowledge graph/DBpedia
(Yahoo‘s FEL [Blanco et al. 2015])
(“president”/“potus”/”trump” =>
dbp:DonaldTrump), to disambiguate text and use
background knowledge (eg US politicians?
Republicans?), high precision (.85), low recall (.39)
o Sentiment analysis/annotation using SentiStrength
[Thelwall et al., 2012], F1 approx. .80
o Extraction of metadata and lifting into established
schemas (SIOC, schema.org), publication using W3C
standards (RDF/SPARQL)
Use cases
Aggregating sentiments towards topics/entities, e.g. about
CDU vs SPD politicians in particular time period
Twitter archives as general corpus for understanding temporal
entity relatedness (e.g. “austerity” & “Greece” 2010-2015)
Investigating spreading & impact of fake news
(e.g. TweetsKB, ClaimsKG, stance detection)
Limitations
Bias & representativity: demographic distributions of users
(not known a priori and not representative)
-0.40000
-0.30000
-0.20000
-0.10000
0.00000
0.10000
0.20000
0.30000
0.40000
Cologne Düsseldorf
https://data.gesis.org/tweetskb/
TweetsKB: a knowledge graph of Web mined “opinions”](https://image.slidesharecdn.com/lwda-researchdata-2019-10-02-kg-191002100301/75/Beyond-research-data-infrastructures-exploiting-artificial-crowd-intelligence-towards-building-research-knowledge-graphs-22-2048.jpg)
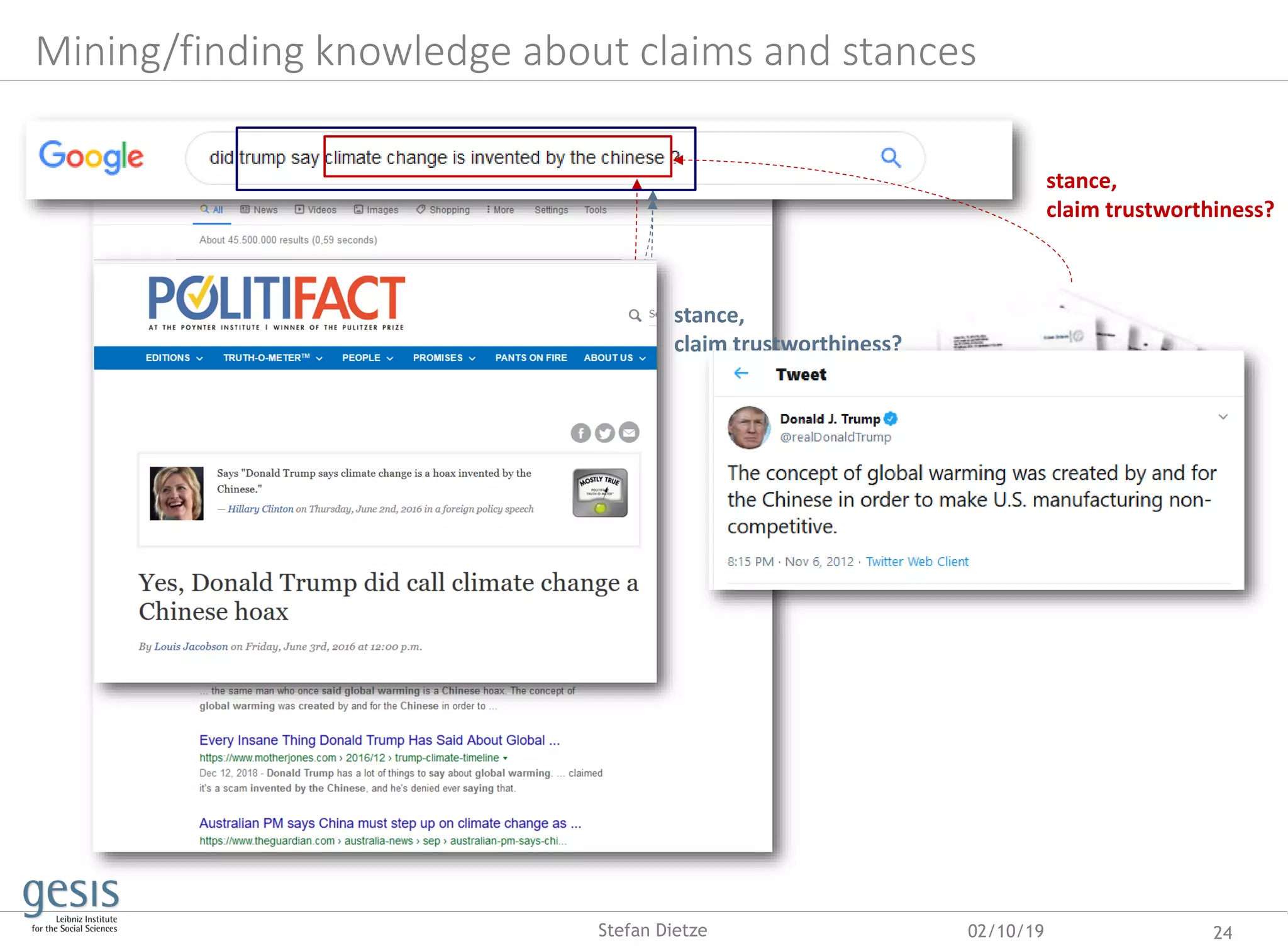




This document discusses using artificial and crowd intelligence to build research knowledge graphs from online data sources. It describes harvesting metadata about research datasets from open data portals and web pages marked up with schemas like RDFa. Machine learning techniques are used to clean and fuse the harvested metadata into a knowledge graph. The knowledge graph can be queried to provide information about research datasets and related entities. Additional methods are discussed for linking mentions of datasets in scholarly publications to real-world datasets.




































































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)








