Download as PDF, PPTX








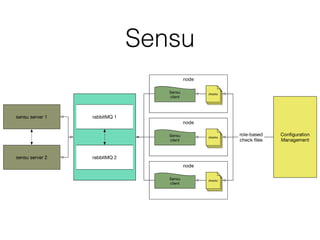

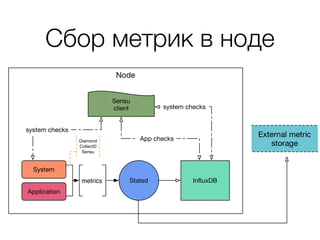
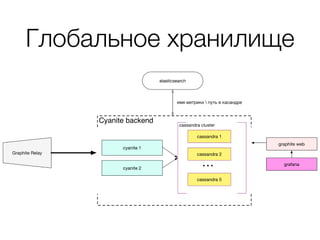





Документ описывает подход к мониторингу в среде DevOps, акцентируя внимание на модульности и гибкости системы. Обсуждаются методы сбора и хранения метрик, роль разработчиков в мониторинге своих сервисов, и необходимость упрощения процесса выявления и решения проблем. Кроме того, упоминаются используемые технологии, такие как statsd и logstash, а также требования к масштабируемости и эффективности системы.


































































