Download as PDF, PPTX













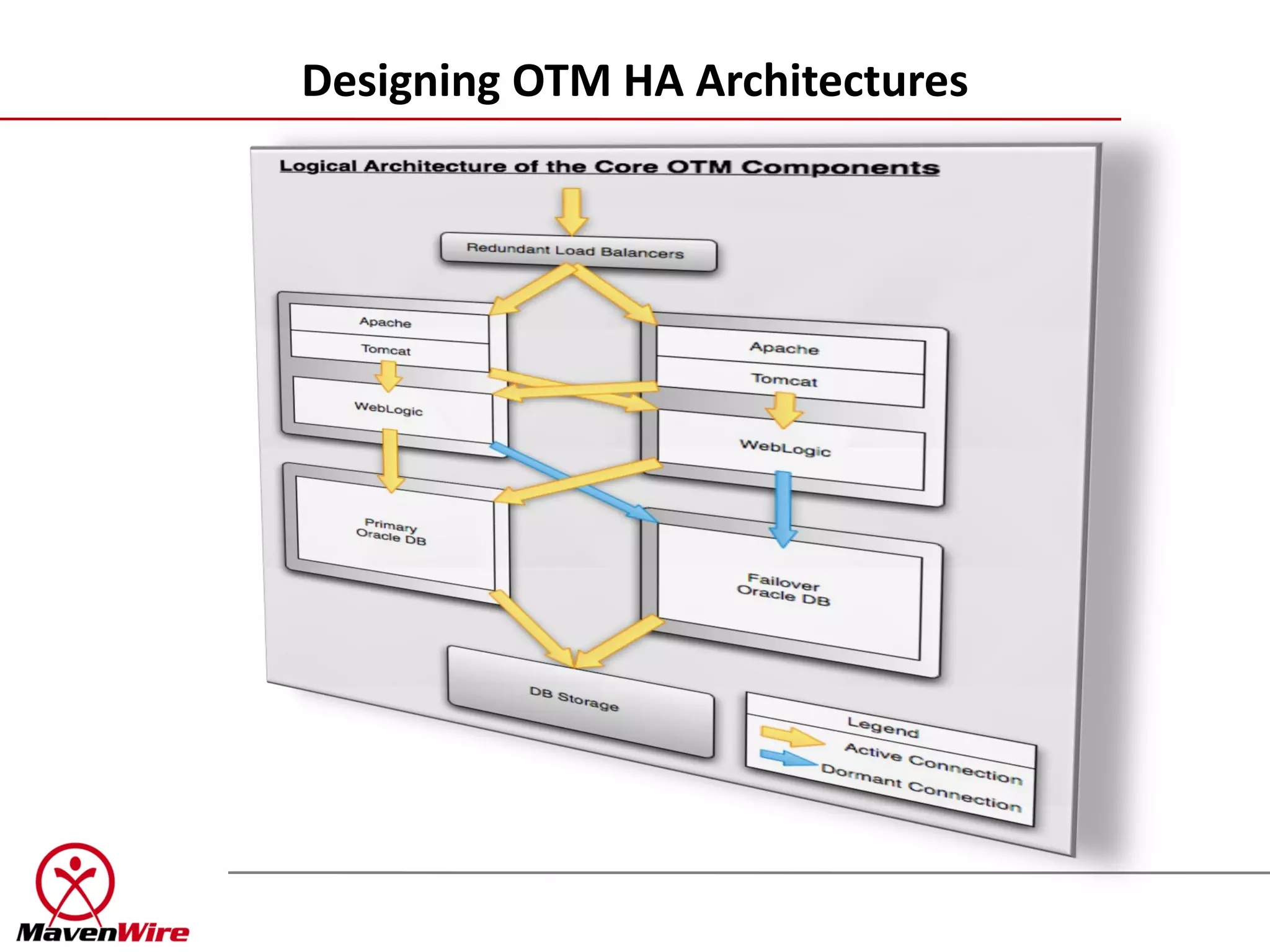

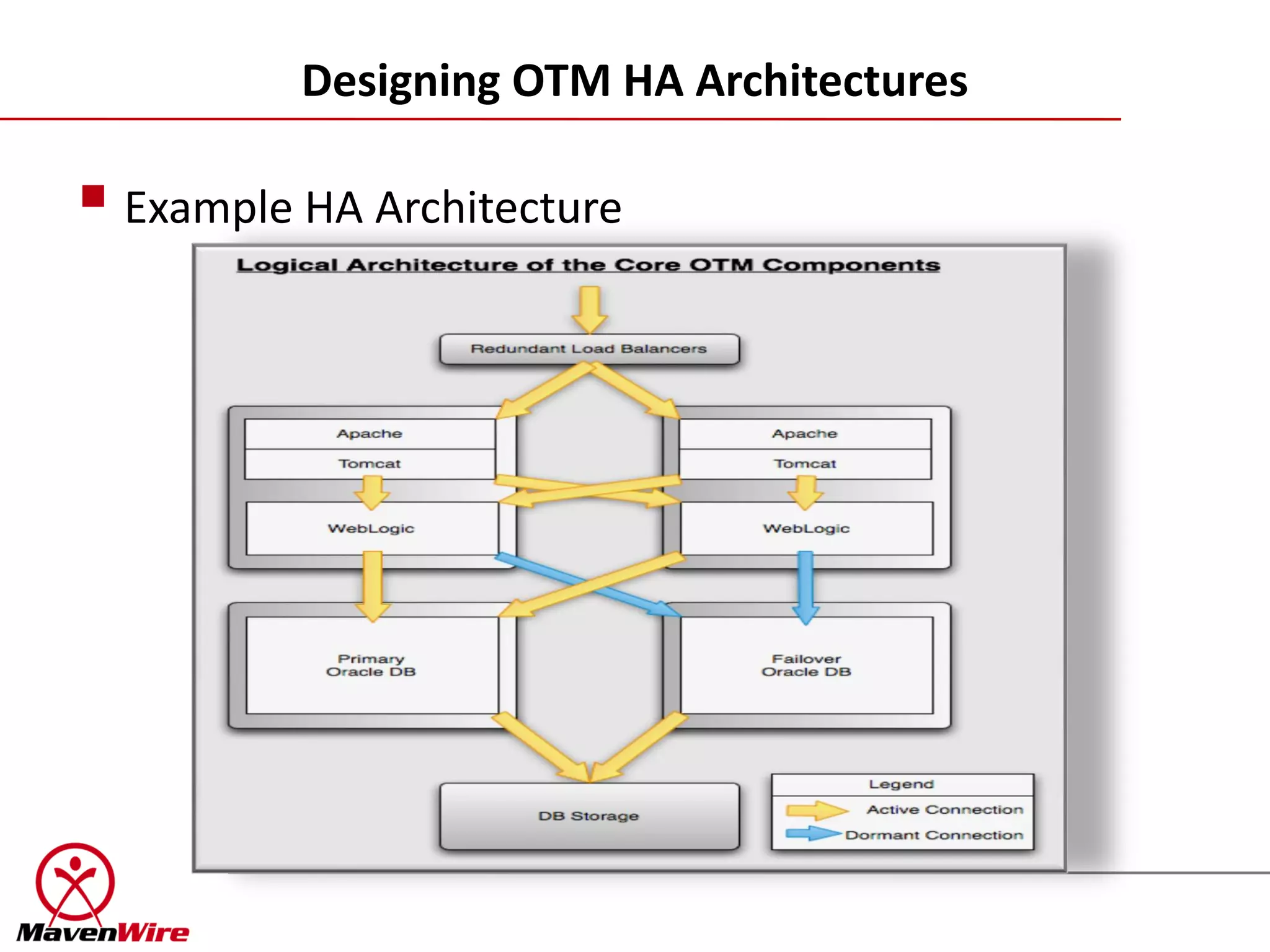








The document discusses designing highly available architectures for OTM applications. It begins by emphasizing the importance of understanding business requirements and budget constraints when designing redundancy. It then outlines some real-world risks like hardware and application failures. The presentation provides an overview of traditional HA solutions and emerging virtualization technologies. It also includes a cheat sheet on options for scaling and clustering the web, application, and database tiers based on service level agreements.



















































































