Downloaded 15 times


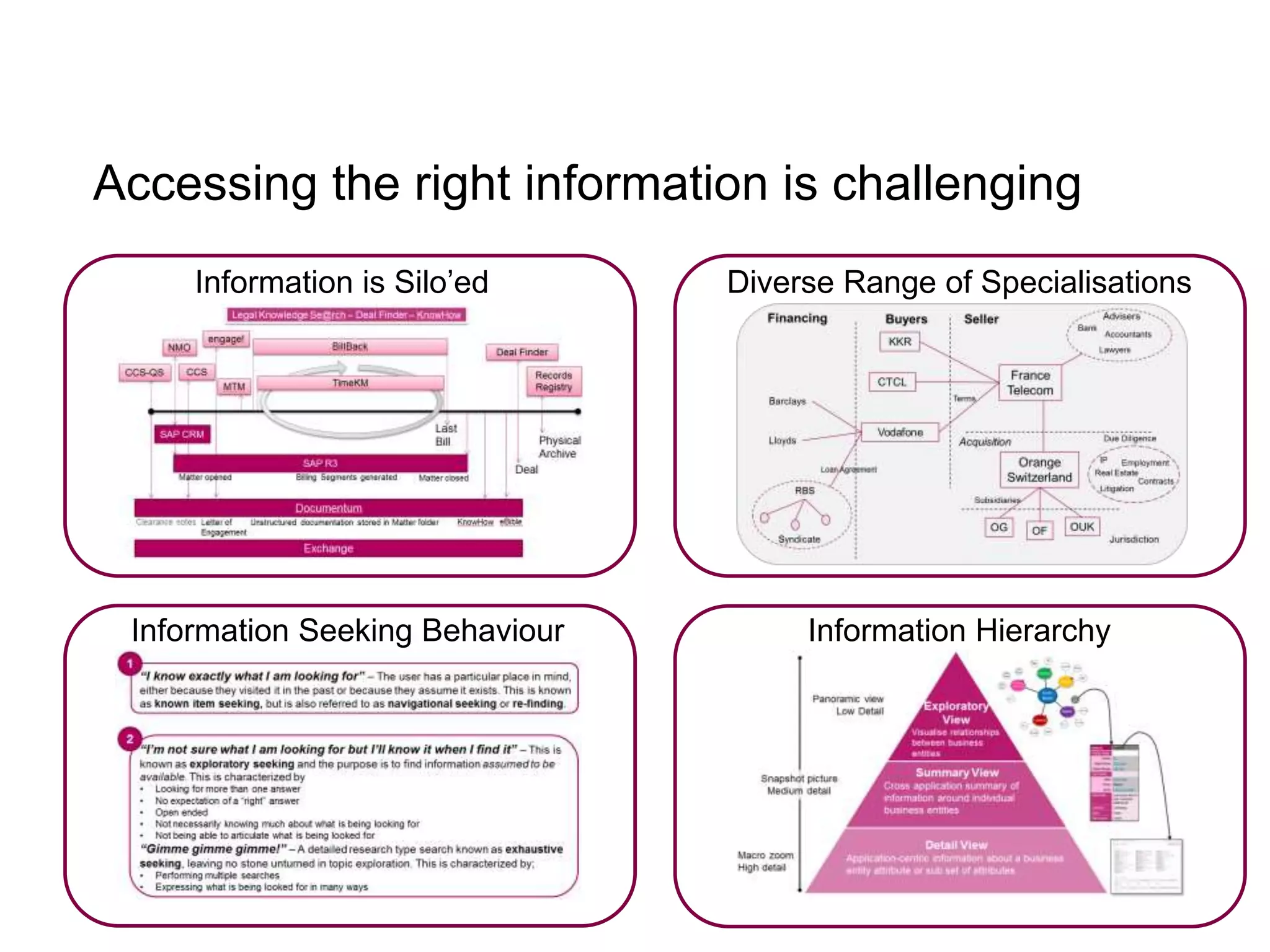

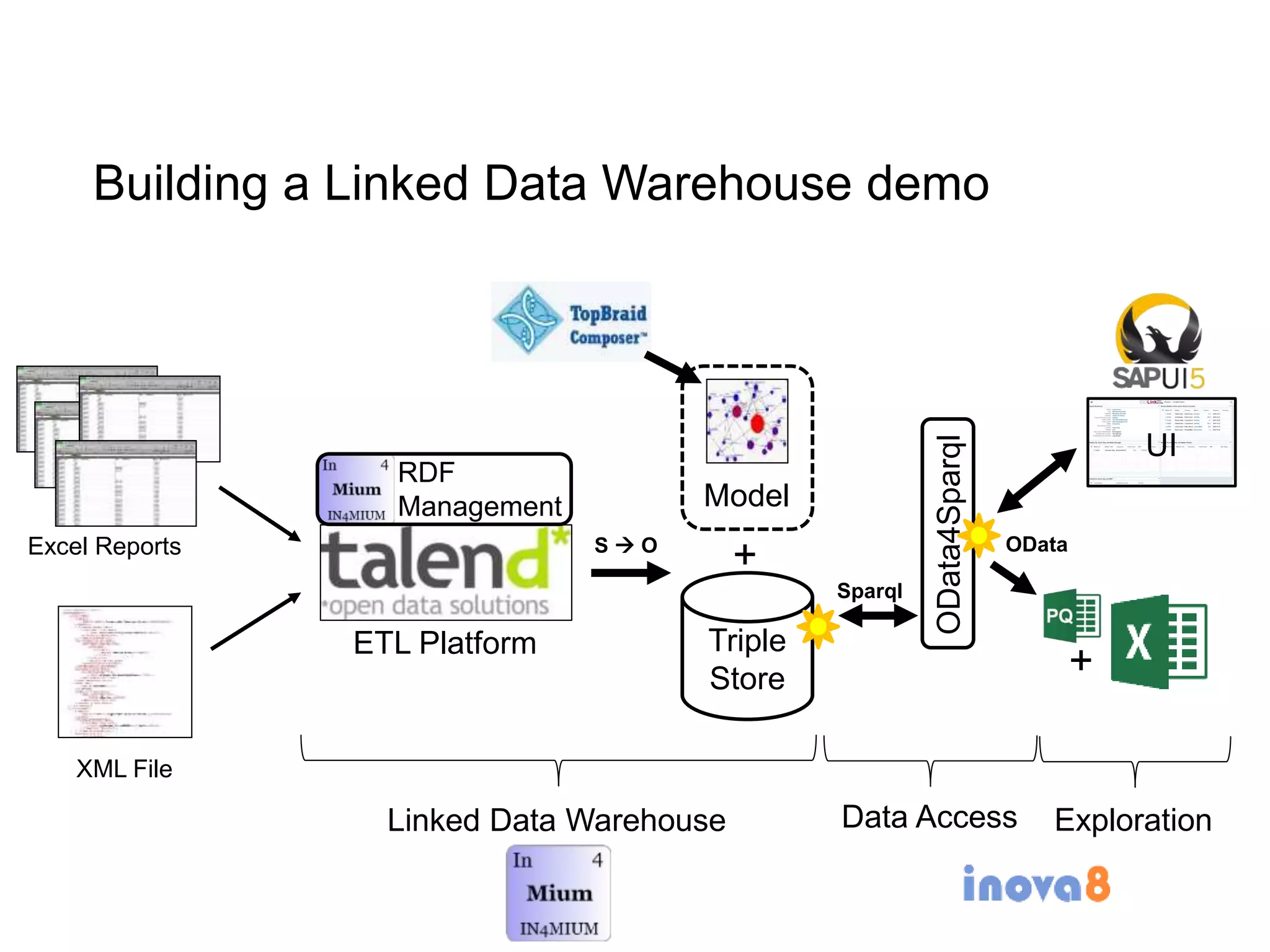

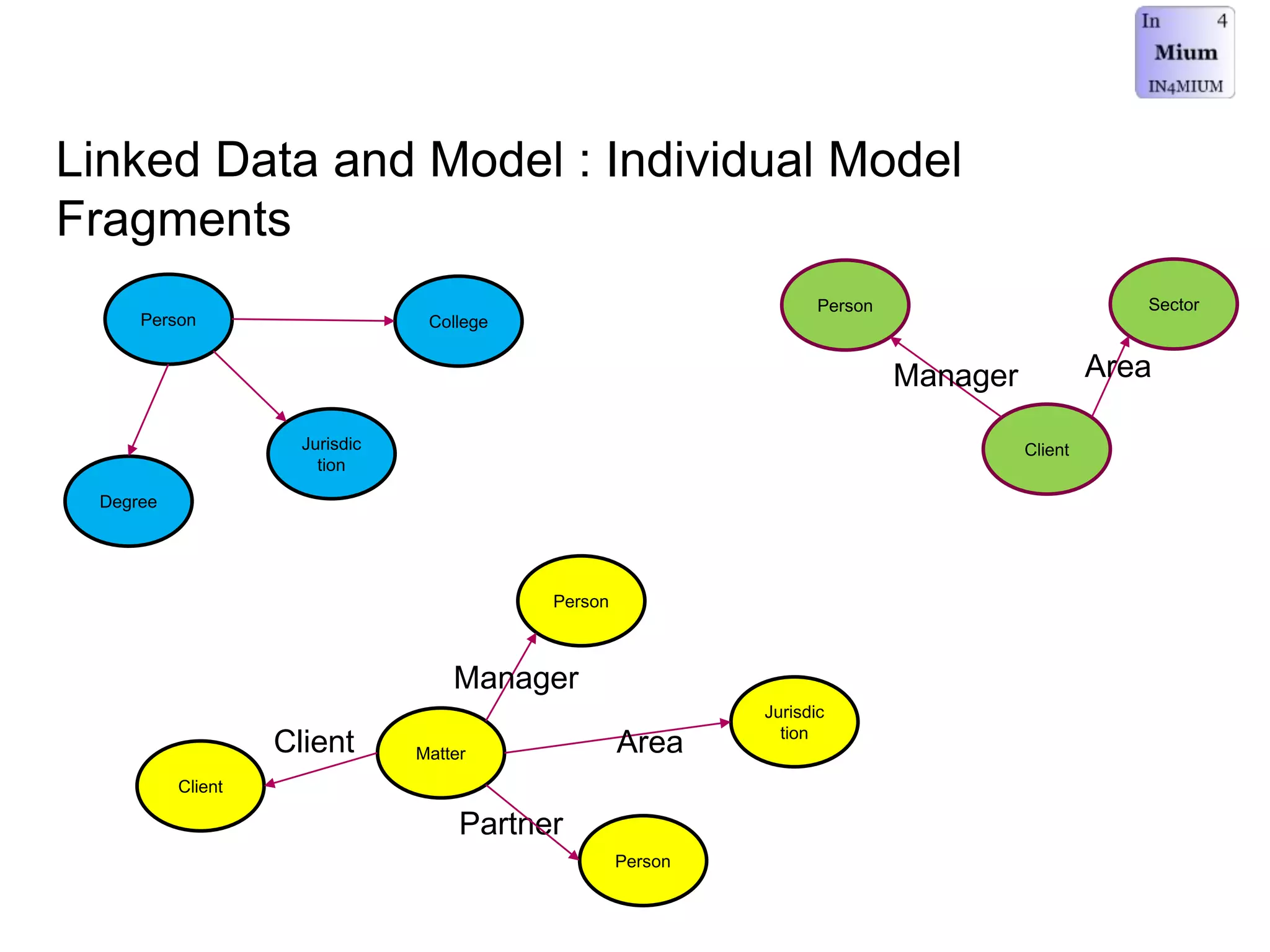
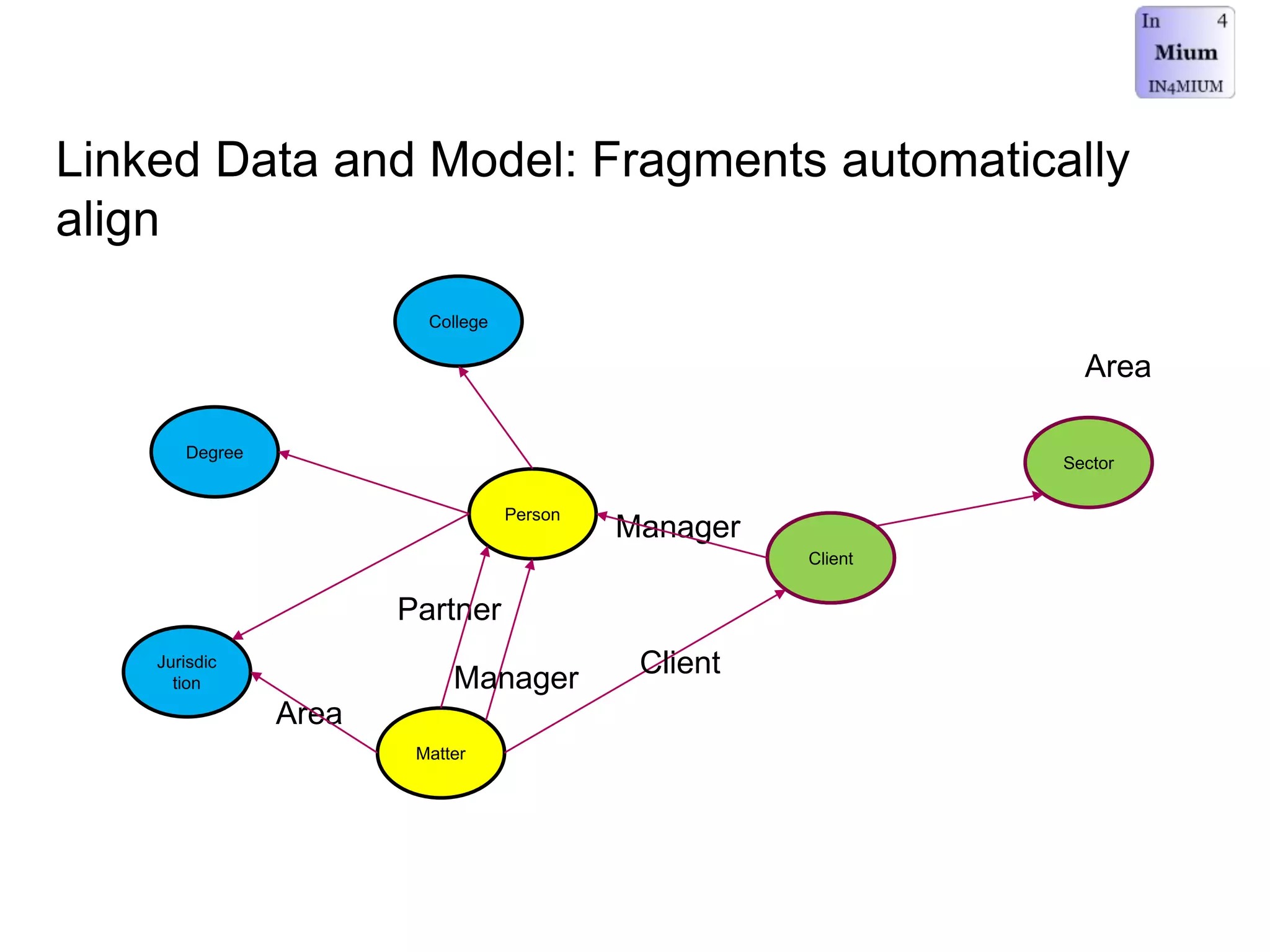
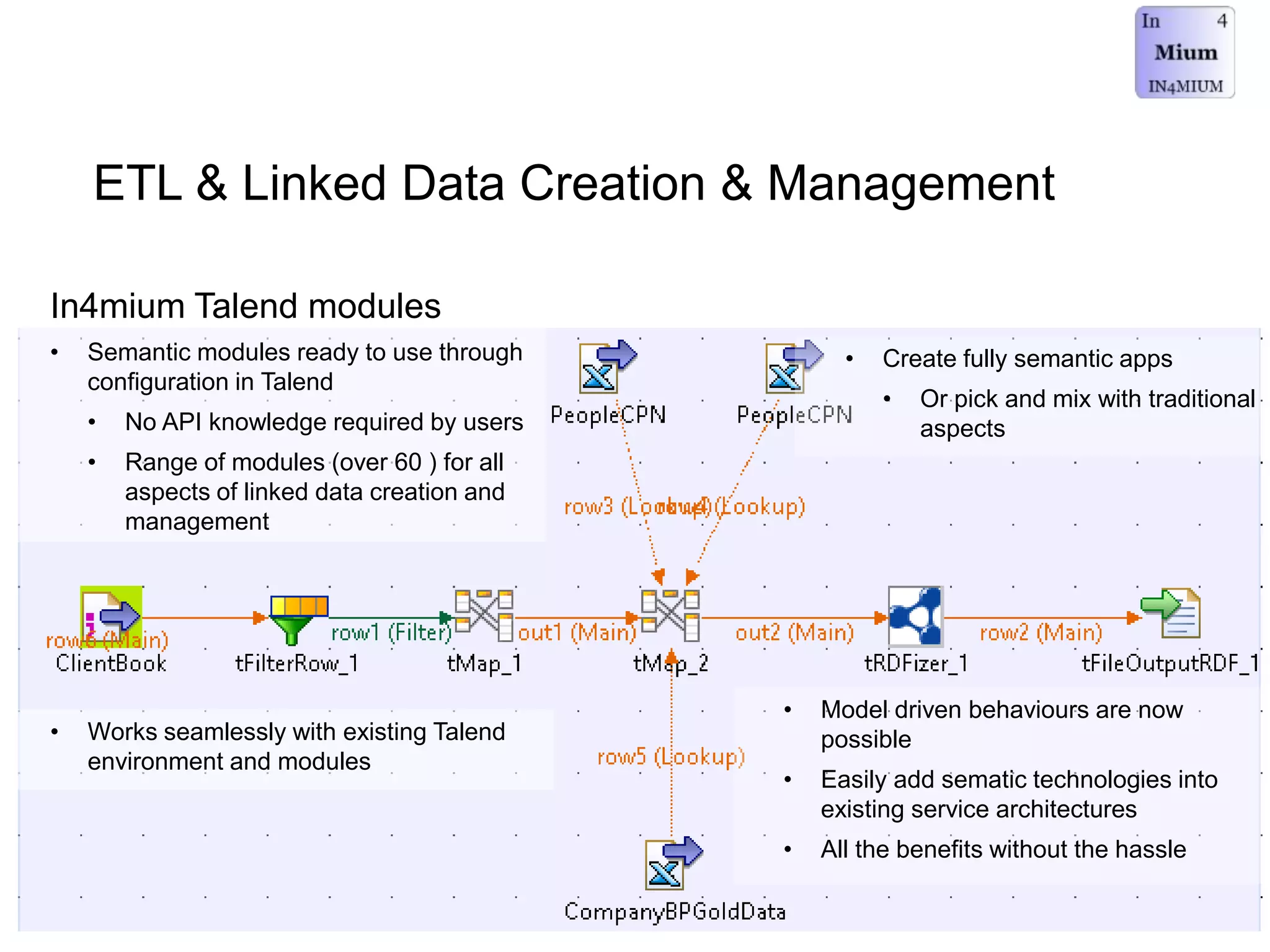
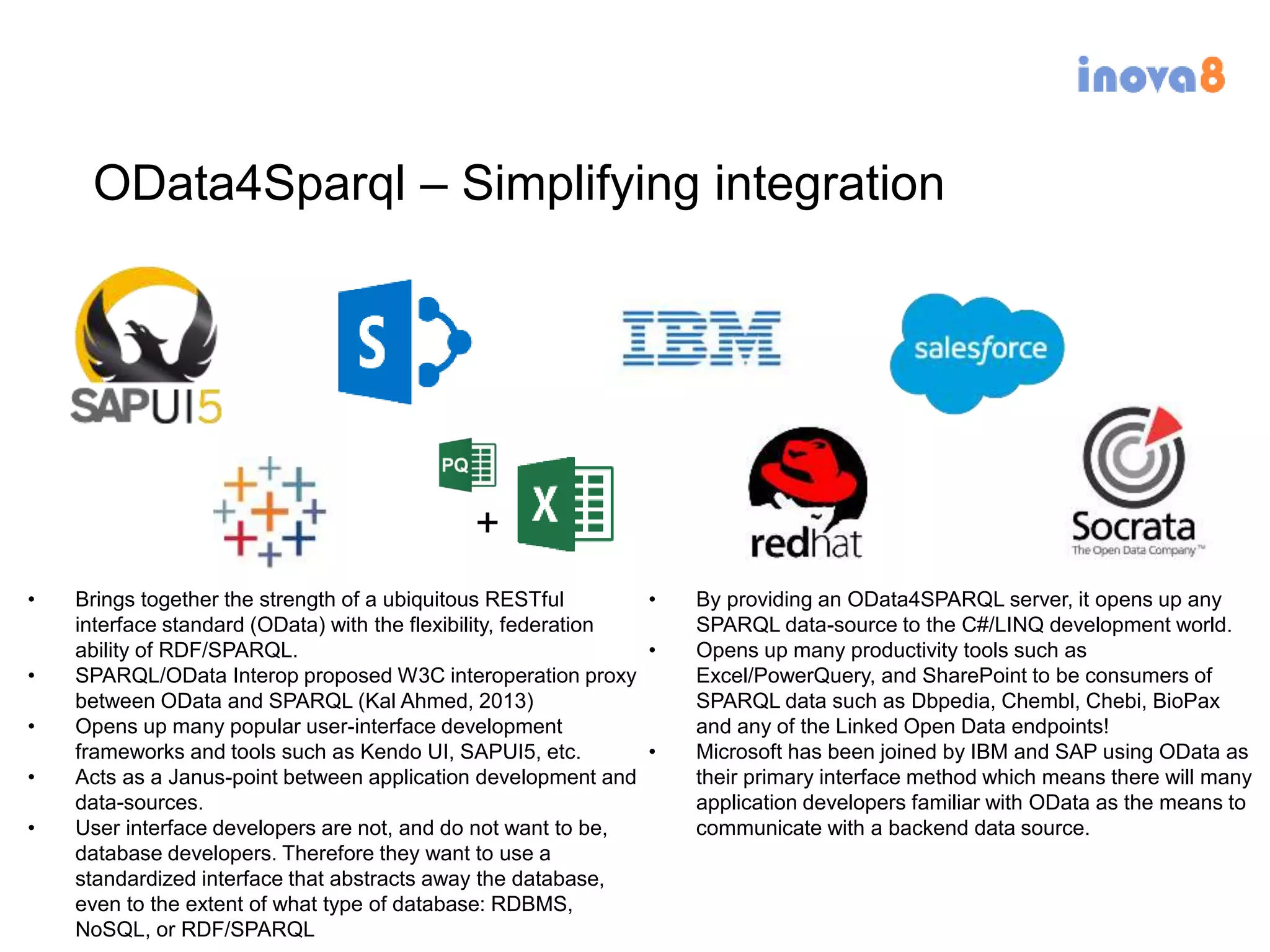
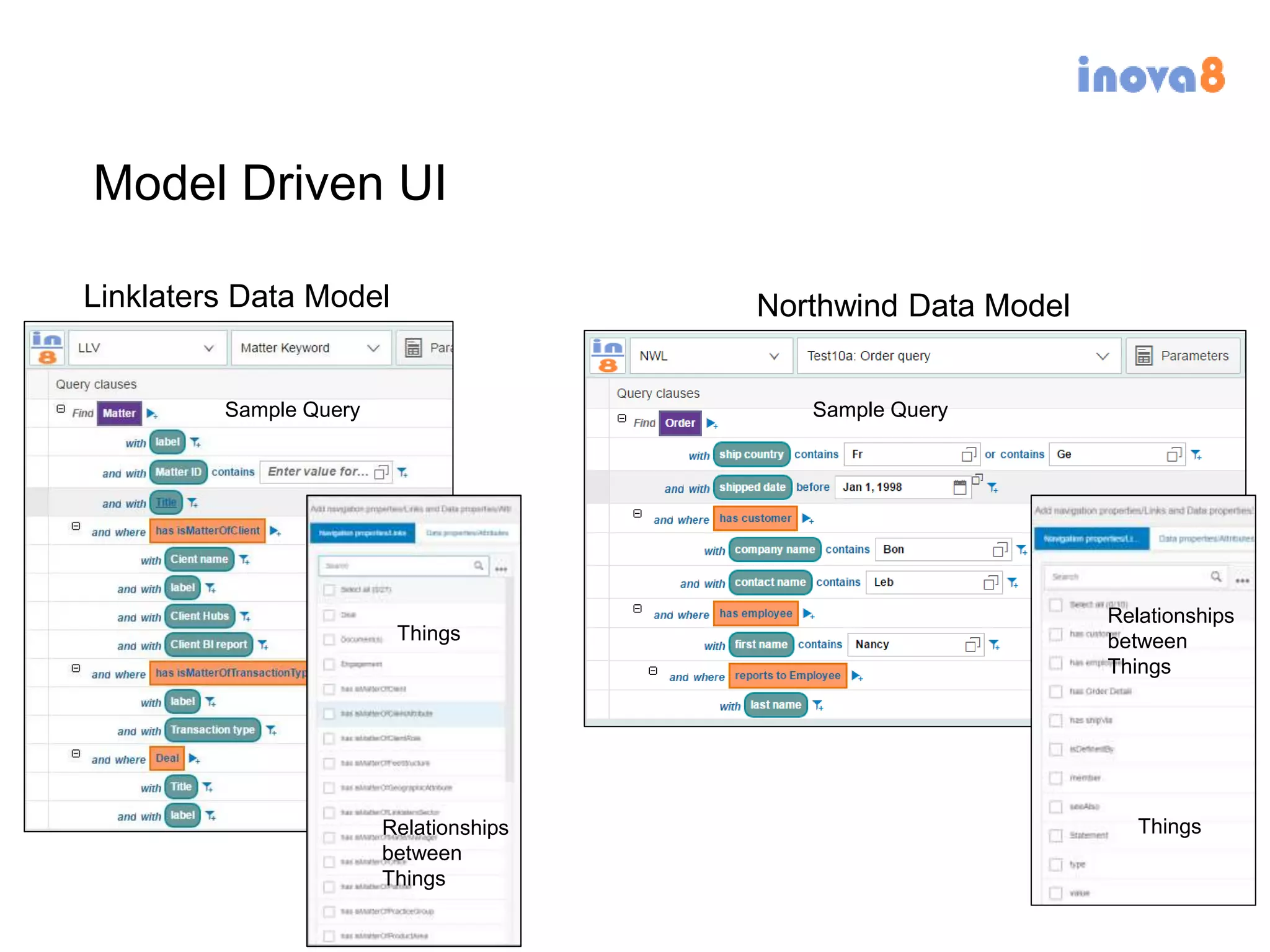

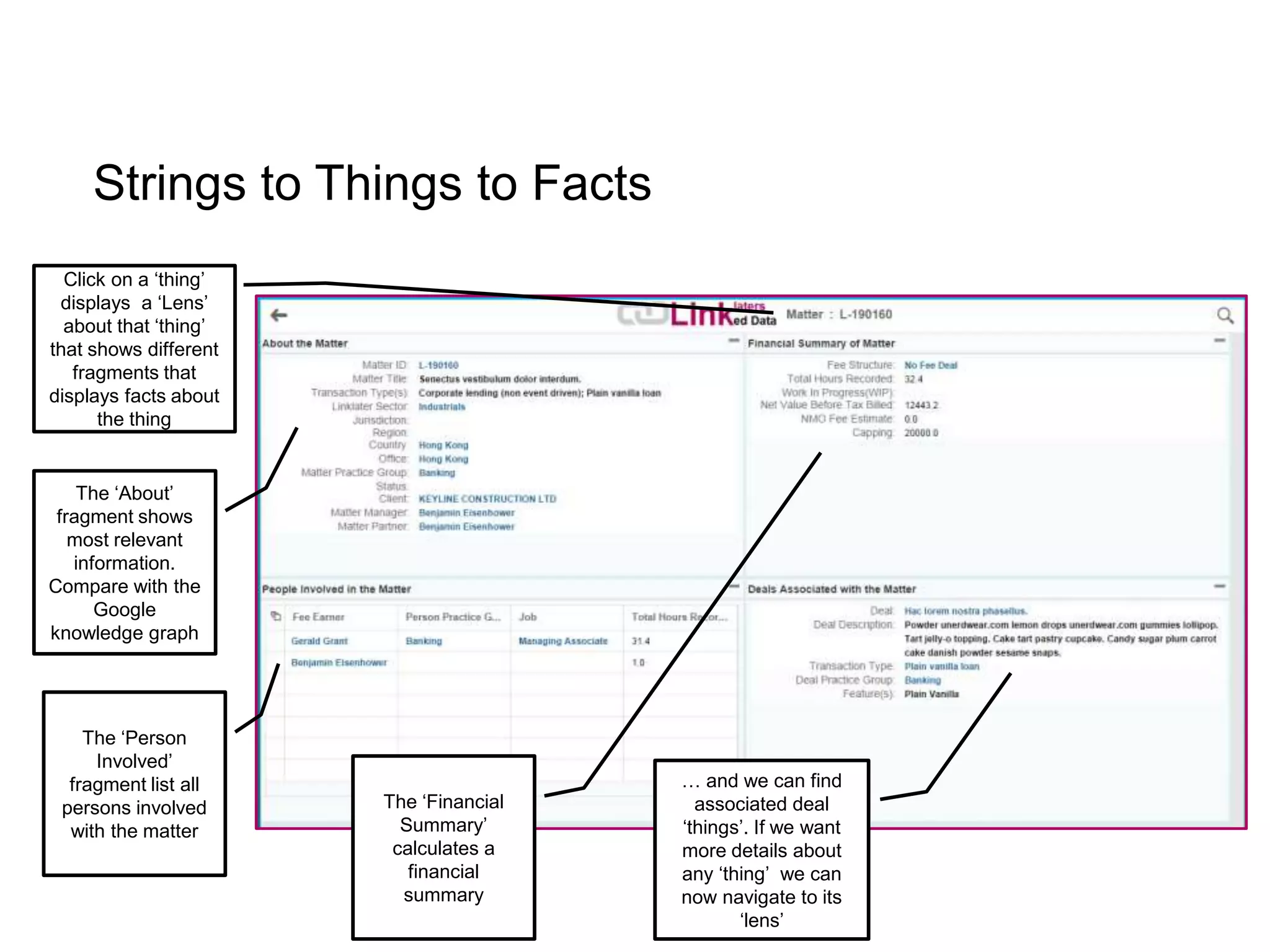

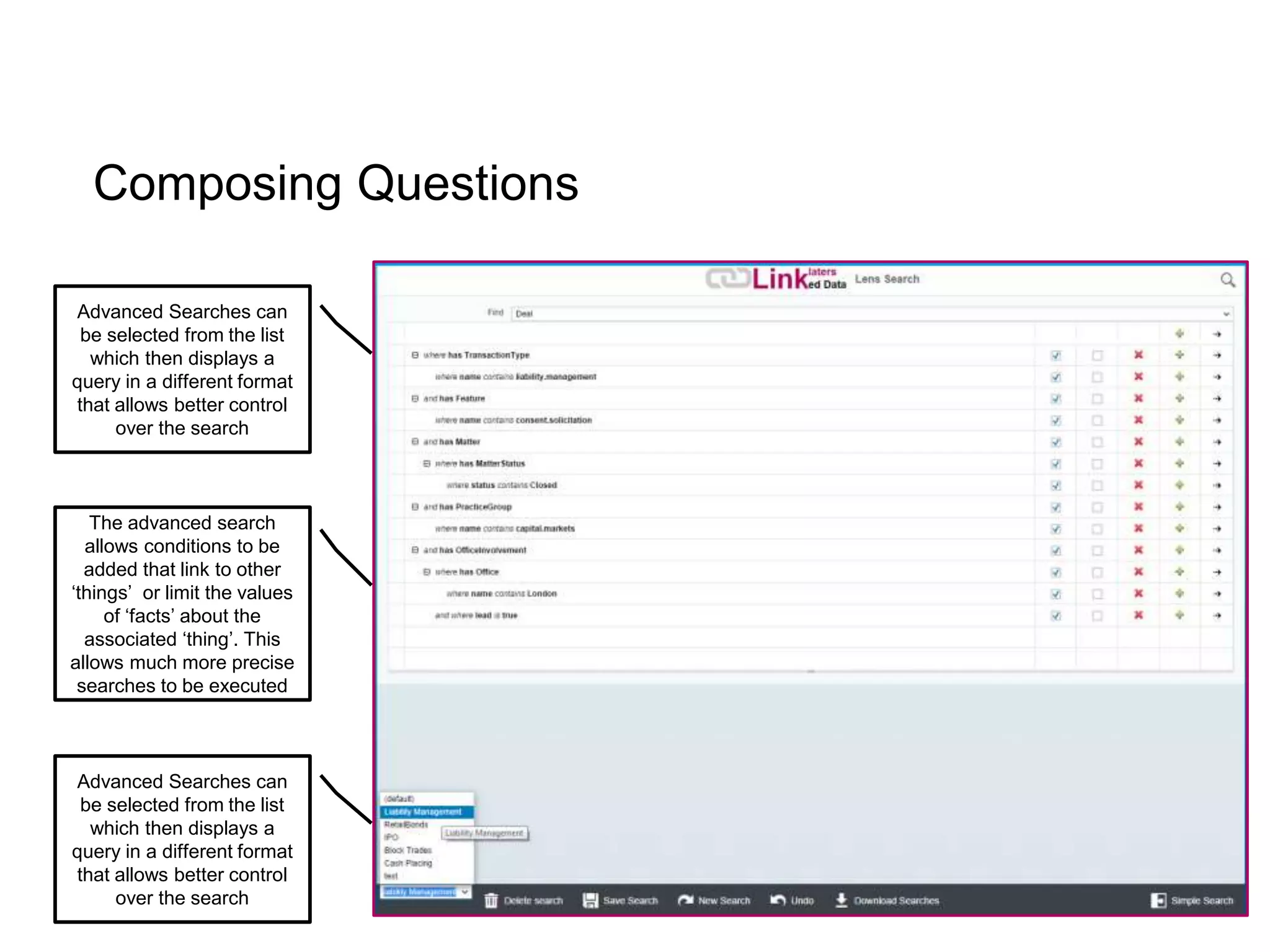
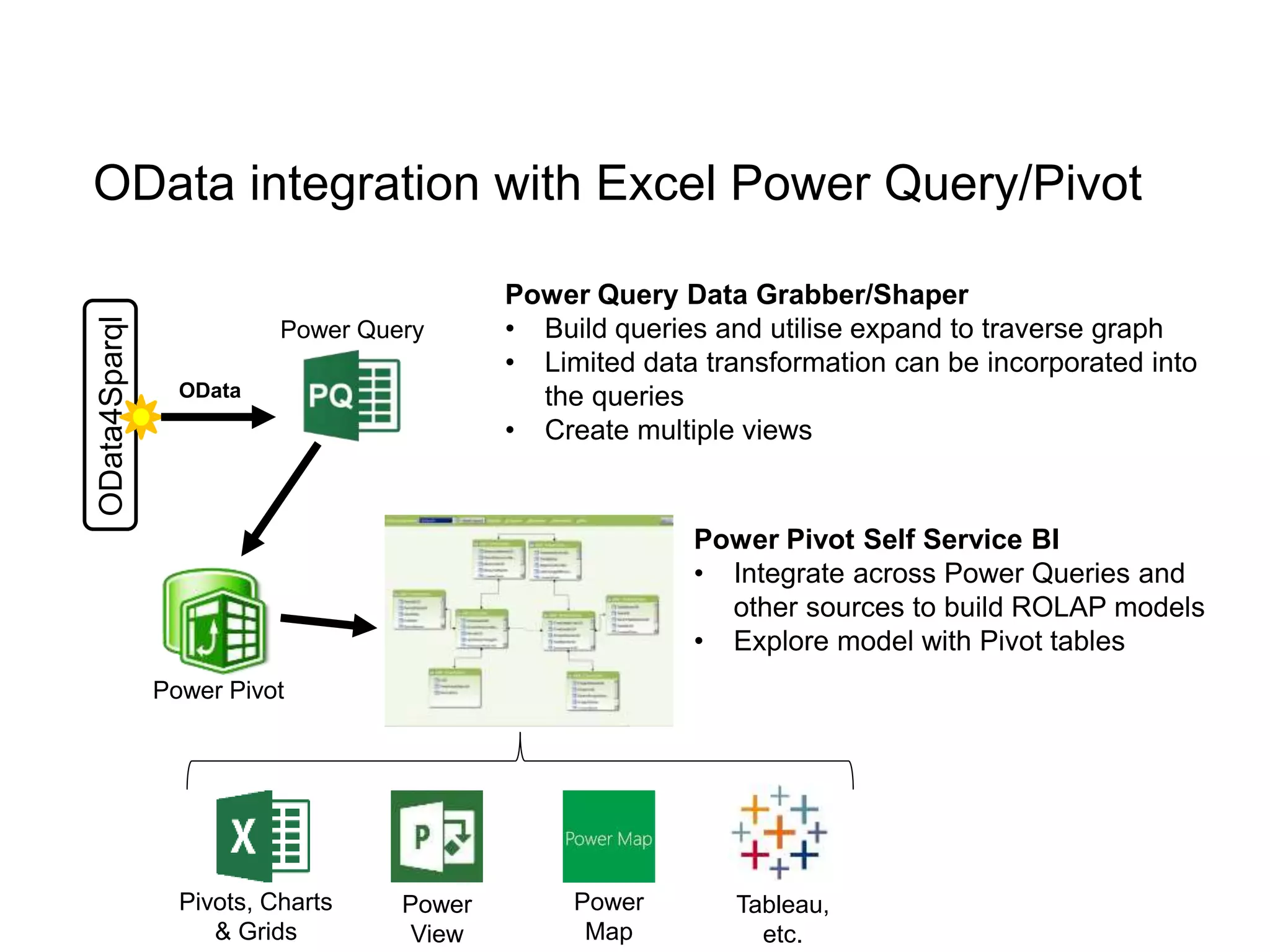

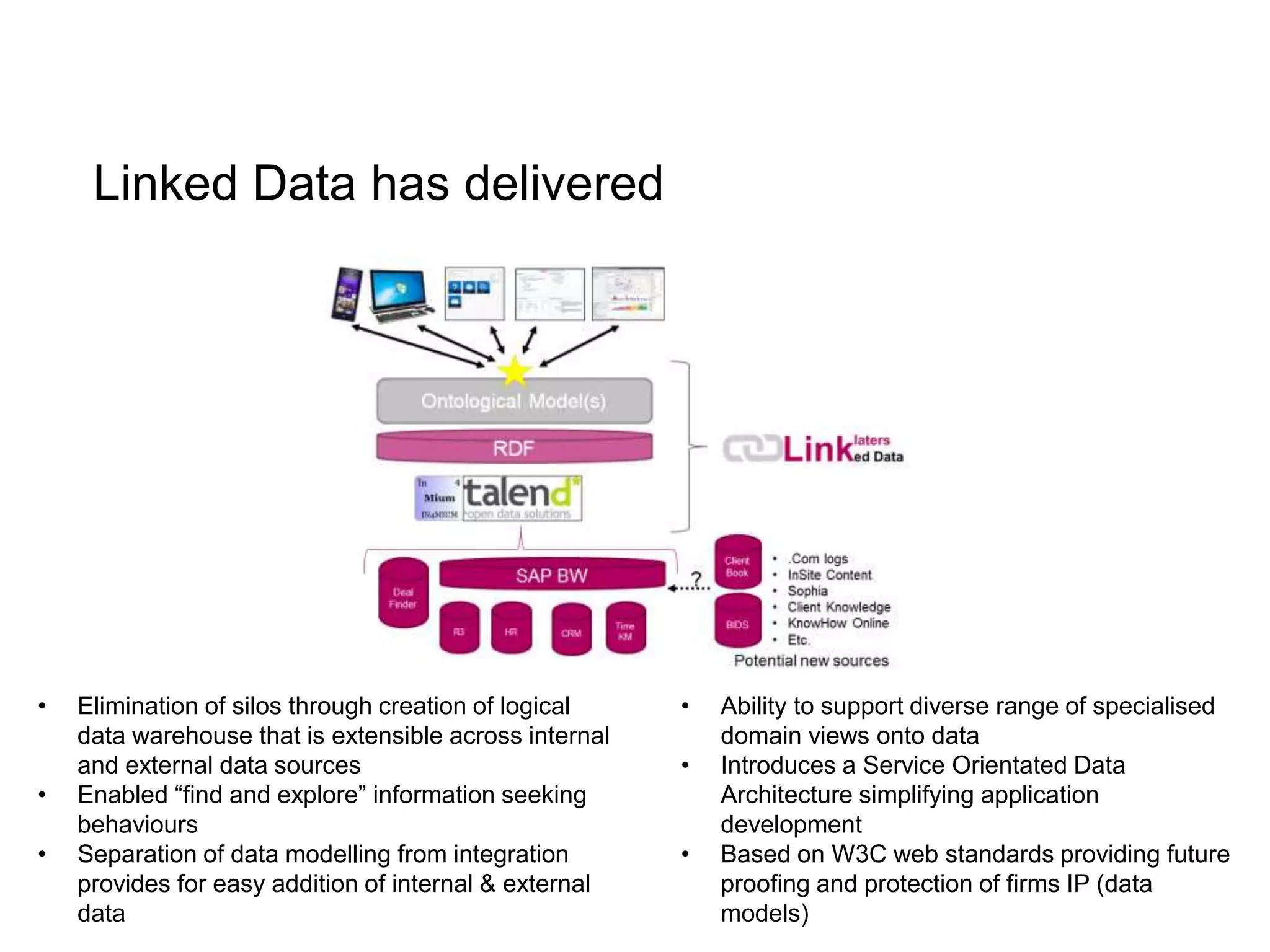
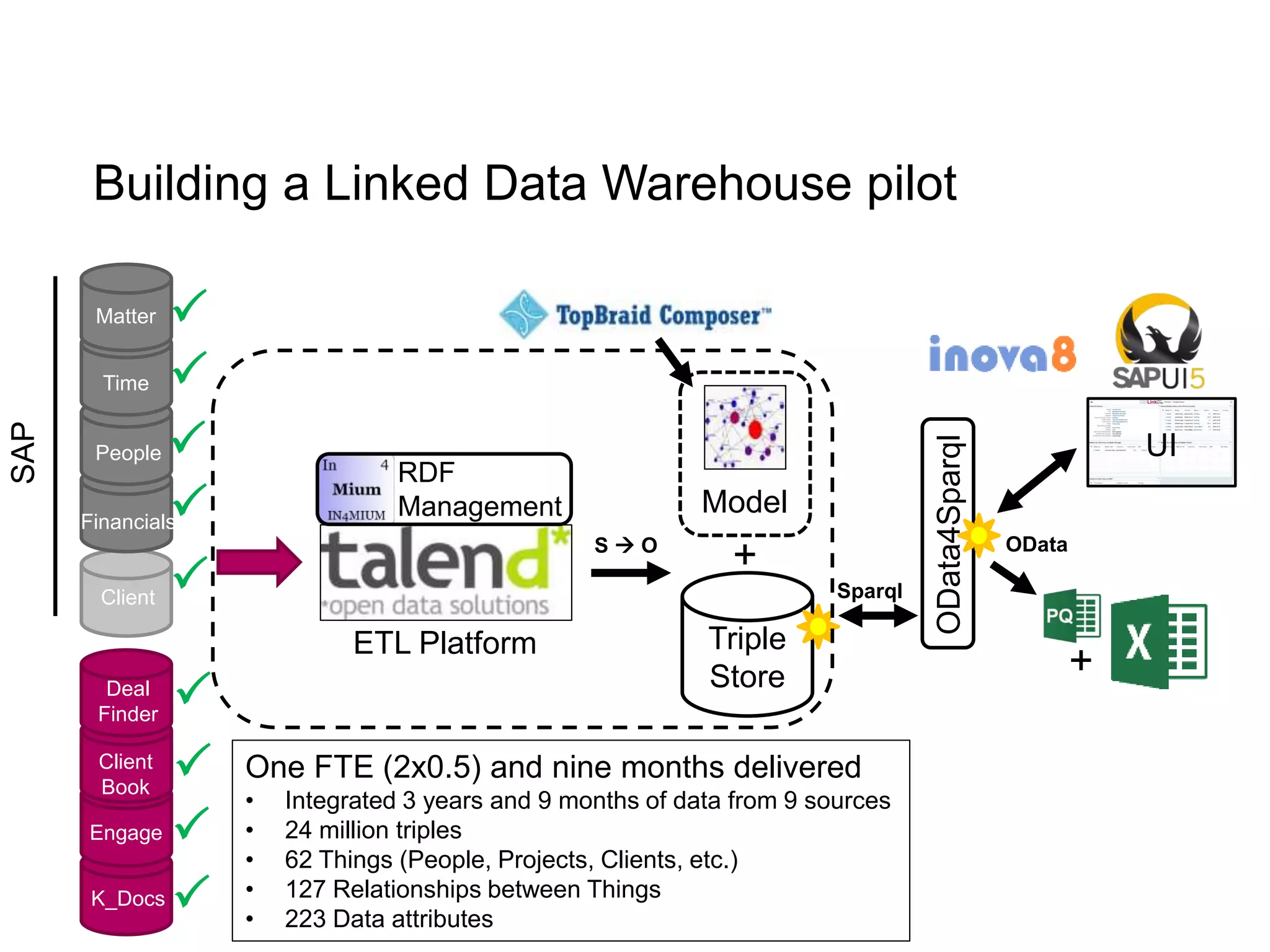


The document discusses the implementation of a linked data warehouse at Linklaters LLP, highlighting the challenges of accessing information due to silos and diverse specializations. It details the approach taken, including the use of semantic technologies and the integration of ETL processes with user-friendly interfaces like odata4sparql, enabling data exploration and discovery. The conclusion emphasizes the benefits of eliminating silos, supporting specialized domain views, and facilitating application development through a service-oriented data architecture.










































![!!!Faszination blech kapitel2[1]](https://cdn.slidesharecdn.com/ss_thumbnails/faszinationblechkapitel21-170307201744-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



