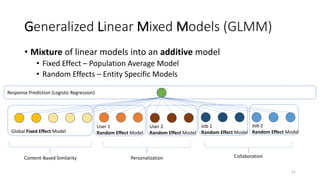
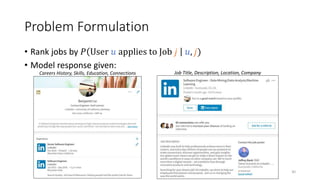
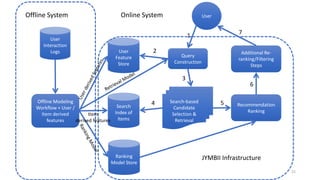
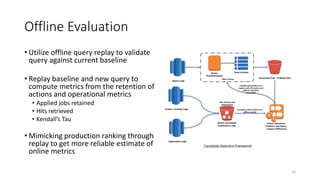
The document summarizes the practical challenges faced and lessons learned from building a personalized job recommendation system at LinkedIn. It discusses 3 key challenges - candidate selection using decision trees to generate queries, training personalized relevance models at scale using generalized linear mixed models, and realizing an ideal jobs marketplace through early intervention to redistribute job applications. The summary provides an overview while hitting the main points discussed in the document in 3 sentences or less.





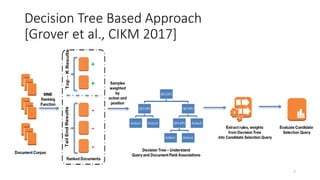
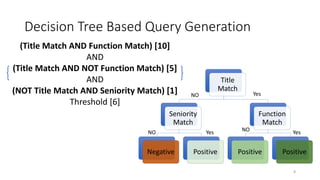
![Decision Tree Based Approach
[Grover et al., CIKM 2017]
• Train on top-k ranked documents
as positives and tail end as
negatives.
• Extract combinations of clauses
decision tree by traversing root
to leaf paths.
• Do a weighted combination of
the clauses.
6](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-6-320.jpg)


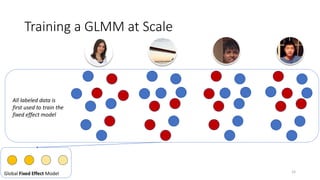
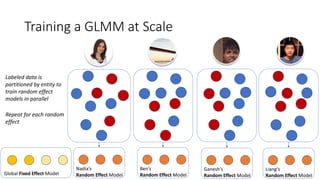
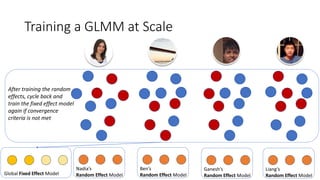
![Parallel Block-wise Coordinate Descent
[Zhang et al., KDD 2016]
13](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-13-320.jpg)

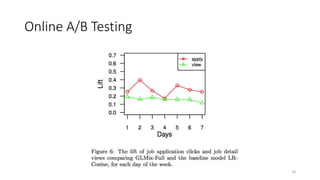




![Our High-level Idea: Early Intervention
[Borisyuk et al., KDD 2017]
• Say a job expires at time T
• At any time t < T
• Predict #applications it would receive at time T
• Given data received from time 0 to t
• If too few => Boost ranking score 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗)
• If too many => Penalize ranking score 𝑃 User 𝑢 applies to Job 𝑗 𝑢, 𝑗)
• Otherwise => No intervention
• Key: Forecasting model of #applications per Job, using signals from:
• # Applies / Impressions the job has received so far
• Other features (xjt): e.g.
• Seasonality (time of day, day of week)
• Job attributes: title, company, industry, qualifications, …
23](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-23-320.jpg)
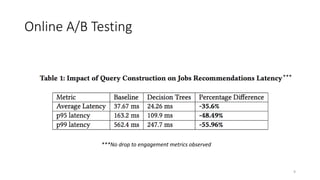
![• Control Model for Ranking : Optimize for user engagement only
• Split the jobs into 3 buckets every day:
• Bucket 1: Received <8 applications up to now
• Bucket 2: Received [8, 100] applications up to now
• Bucket 3: Received >100 applications up to now
Re-distribute
Online A/B Testing
24](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-24-320.jpg)

![References
• [Borisyuk et al., 2016] CaSMoS: A framework for learning candidate
selection models over structured queries and documents, KDD 2016
• [Borisyuk et al., 2017] LiJAR: A System for Job Application
Redistribution towards Efficient Career Marketplace, KDD 2017
• [Grover et al., 2017] Latency reduction via decision tree based query
construction, CIKM 2017
• [Zhang et al., 2016] GLMix: Generalized Linear Mixed Models For
Large-Scale Response Prediction, KDD 2016
26](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-26-320.jpg)



![Understanding WAND Query
Query : “Quality Assurance Engineer”
WAND : “(Quality[5] AND Assurance[5] AND Engineer[1]) [10]”
✅ ✅ 32](https://image.slidesharecdn.com/personalizedjobrecommendationsrecsys-170827074519/85/Personalized-Job-Recommendation-System-at-LinkedIn-Practical-Challenges-and-Lessons-Learned-32-320.jpg)


![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)

































































